Podręcznik
1. Wprowadzenie do grafów
Graf to jedna z podstawowych i najbardziej uniwersalnych struktur danych w informatyce i matematyce dyskretnej. Jest to zbiór wierzchołków (nazywanych również punktami lub nodami), pomiędzy którymi istnieją połączenia – zwane krawędziami. Grafy służą do modelowania relacji między obiektami, co sprawia, że mają szerokie zastosowanie w wielu dziedzinach, takich jak informatyka, logistyka, sieci komputerowe, biologia, ekonomia czy teoria baz danych.Zazwyczaj graf przedstawia się za pomocą symboli G = (V, E), gdzie V jest to zbiór wierzchołków grafu, zwanych również węzłami (ang. vertex), natomiast E to zbiór krawędzi grafu (ang. edge).
Grafy dzielimy zasadniczo na dwa rodzaje – grafy skierowane oraz nieskierowane.
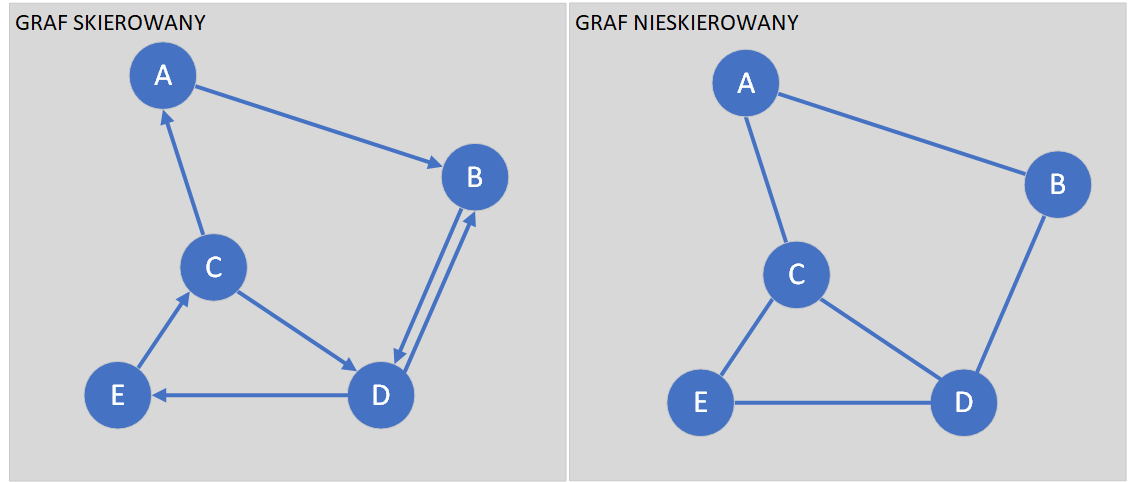
Najczęściej w pamięci grafy przechowywane są za pomocą:
- list sąsiedztwa,
- macierzy sąsiedztwa.
Dla grafu nieskierowanego przedstawionego na rysunku powyżej lista sąsiedztwa będzie wyglądała następująco:
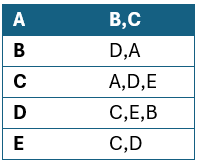
W przypadku grafu skierowanego istotne jest czy w zapisie uwzględniamy węzły skierowane od danego wierzchołka, czy odwrotnie. W przypadku grafu skierowanego nie ma to znaczenia.
Macierz sąsiedztwa natomiast to kwadratowa tablica dwuwymiarowa o rozmiarze \( nxn \), gdzie ? to liczba wierzchołków w grafie. Wartość na pozycji ( ? , ? ) w tej tablicy wskazuje, czy istnieje krawędź pomiędzy wierzchołkiem ? a ? . W grafach ważonych ta wartość może odpowiadać wagom krawędzi. Macierz sąsiedztwa umożliwia bardzo szybkie sprawdzenie istnienia połączenia między dowolnymi dwoma wierzchołkami wystarczy jedno odwołanie do elementu tablicy. Jednak jej główną wadą jest duże zużycie pamięci, zwłaszcza w przypadku grafów rzadkich, ponieważ wymaga przechowywania \( n^2 \) wartości, niezależnie od rzeczywistej liczby krawędzi.
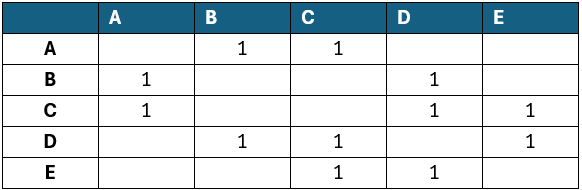
Podsumowując, reprezentacja grafu jako lista sąsiedztwa jest bardziej oszczędna pamięciowo i lepiej sprawdza się w grafach rzadkich, natomiast macierz sąsiedztwa oferuje szybszy dostęp do informacji o krawędziach, co może być korzystne w gęstych grafach lub w algorytmach często sprawdzających istnienie połączeń między wierzchołkami. Wybór reprezentacji powinien więc zależeć od charakterystyki konkretnego problemu i rodzaju wykonywanych operacji.
Przeszukiwanie grafów w głąb
Przeszukiwanie w głąb (ang. Depth-First SearchDFS) polega na eksploracji grafu „najdalej jak się da” tzn. zanim wróci się i zacznie badać inne możliwe ścieżki. Zazwyczaj jest realizowane rekurencyjnie lub przy użyciu stosu. Algorytm DFS odwiedza sąsiadów wierzchołka, następnie sąsiadów tych sąsiadów, i tak dalej, aż dotrze do punktu, w którym nie można już pójść głębiej – wtedy algorytm się cofa i kontynuuje badanie pozostałych gałęzi. Przeszukiwanie w głąb doskonale sprawdza się w przypadkach, gdy zależy nam na pełnym zbadaniu struktur rozgałęzionych, takich jak drzewa, i jest fundamentem np. algorytmu Tarjana do znajdowania punktów artykulacji czy mostów w grafie.
lgorytm przeszukiwania w głąb może być stosowany zarówno dla grafów nieskierowanych, jak i dla grafów skierowanych. Działa również poprawnie dla obu rodzajów grafów w przypadku innego podziału – dla grafów spójnych i niespójnych. Teraz jest więc już najwyższy czas na wprowadzenie ich definicji.
Przeszukiwanie grafów wszerz
BFS jest zwykle implementowany iteracyjnie i ma złożoność czasową O(V + E), gdzie V to liczba wierzchołków, a E – liczba krawędzi. To czyni go bardzo wydajnym narzędziem w analizie struktur grafowych, szczególnie wtedy, gdy zależy nam na eksploracji szerokości drzewa odwiedzin.