Podręcznik
3. Wprowadzenie do architektury oprogramowania
3.1. Rola projektowania architektonicznego
Opanowanie złożoności na poziomie samego kodu jest bardzo trudne lub wręcz niemożliwe. Moduły (klasy), procedury, instrukcje są powiązane bardzo złożoną siecią zależności. Aby system działał efektywnie oraz pozwalał na łatwą jego pielęgnację, powinniśmy stosować dobre praktyki projektowania oprogramowania. Podstawą jest tutaj projekt architektoniczny pokazujący zasadniczą strukturę systemu oraz opisujący sposób działania podstawowych jednostek funkcjonalnych. Plany architektoniczne systemu powinny zapewniać członkom zespołu deweloperskiego dobrą platformę porozumienia – powinny wyrażać najważniejsze decyzje dotyczące sposobu budowy systemu.
Architektura oprogramowania stanowi wyrażony zestaw decyzji podjętych przez architekta. Decyzje te są podejmowane na podstawie wymagań klienta oraz wiedzy na temat dostępnych technologii wytwarzania oprogramowania. Plany architektoniczne pokazują strukturę i dynamikę (działanie) budowanego (lub istniejącego) systemu. Biorą one pod uwagę ograniczenia ekonomiczne i technologiczne, a także możliwość łatwego wprowadzania zmian i rozszerzeń wynikających ze zmian wymagań i zmian technologii. Są one wyrażane w języku graficznym (wizualnym), zrozumiałym dla projektantów i wykonawców systemu (programistów).
Architekturę oprogramowania tworzymy na stosunkowo wysokim poziomie ogólności. Architekci oprogramowania nie muszą projektować wszystkich szczegółów. Pozostawiają to zadanie deweloperom pełniącym role projektantów. Współpraca między rolami w ramach dyscypliny projektowania jest zilustrowana na rysunku 3.1. Architekt tworzy ogólny model systemu, dzieląc jego funkcjonalność na poszczególne komponenty oraz definiując interfejsy i przepływ komunikatów pomiędzy komponentami. Na tym poziomie, komponenty są czarnymi skrzynkami komunikującymi się między sobą poprzez dobrze zdefiniowane i stosunkowo wąskie interfejsy. Architekt projektuje również komunikację między komponentami tworząc odpowiednie diagramy opisujące dynamikę systemu, np. diagramy sekwencji. Projektowanie systemu na takim poziomie szczegółowości powoduje, że architekt musi zapanować nad co najwyżej kilkudziesięcioma komponentami zamiast setkami lub tysiącami klas (jednostek kodu) na raz. Oprócz projektowania elementów architektury logicznej, architekt definiuje również architekturę fizyczną, czyli strukturę składająca się z węzłów wykonawczych. Ponadto, rolą architekta jest zdefiniowanie zasad projektowania poszczególnych podsystemów oraz technologii ich implementacji. Architekt może na przykład zaprojektować część modeli projektowych komponentów, jako wskazówkę dla projektantów.
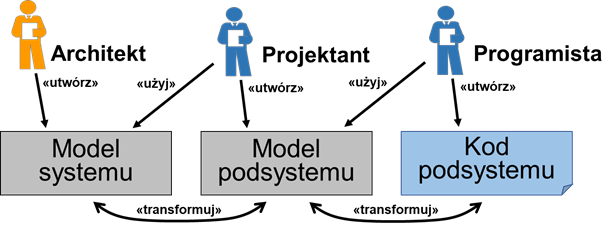
Rysunek 9.1: Projektowanie na różnych poziomach
Równolegle z architektem, projektanci tworzą szczegółowe modele
podsystemów. Często jest to bezpośrednio powiązane z tworzeniem kodu
podsystemów. Warto jednak podkreślić zasadniczą różnicę między
projektowaniem i kodowaniem (pisaniem kodu programu). Projektowanie polega na
podejmowaniu decyzji odnośnie sposobu implementacji komponentów poprzez podział
na jednostki kodu (np. klasy i atrybuty) oraz ogólne określenie ich funkcjonalności
(operacje). Kodowanie polega na realizacji projektu w formie konstrukcji
programistycznych oraz na zapisaniu kompletnej treści procedur (metod).
3.2. Architektury komponentowe i usługowe
Podział systemu na komponenty jest bardzo ważną decyzją architektoniczną. Decyzja ta powinna być podjęta na podstawie dobrze określonych przesłanek. Pierwszą przesłanką jest konieczność zapewnienia, aby komponent realizował dobrze zasadę abstrakcji. Oznacza to, że komponent powinien grupować w sobie elementy realizujące pewien zwarty podsystem. Zwartość komponentów jest bardzo istotną cechą określającą jakość architektury. Intuicja wskazuje, że dobry komponent powinien odpowiadać jakiemuś zbiorowi ściśle związanych ze sobą pojęć (klas) ze środowiska lub elementów wykonawczych (też klas!), realizujących pewne ściśle związane ze sobą przypadki użycia systemu. Ze zwartością komponentów wiąże się druga przesłanka podziału na komponenty – realizacja zasady zamykania informacji. Oznacza ona, że podsystem realizowany przez komponent powinien być ukryty dla „świata zewnętrznego”. Jednocześnie, komunikacja z pozostałymi komponentami powinna się odbywać przez jak najwęższy styk. W ten sposób, więzy między komponentami są stosunkowo słabe.
Dobrze zdefiniowane i reużywalne komponenty nazywamy usługami. Każda usługa dostarcza zestaw operacji dostępnych poprzez interfejsy. Każdy spójny zestaw operacji stanowi swego rodzaju „kontrakt”, na podstawie którego z usługi mogą korzystać inne komponenty. Taki kontrakt określa strukturę i sekwencje komunikatów odbieranych i wysyłanych przez usługę. W ramach wykonywania swoich operacji, usługa działa w sposób autonomiczny. Oznacza to, że usługa nie zakłada, że jest fragmentem jakiegoś konkretnego systemu. Zamiast tego, usługa jest zorientowana na wykonanie konkretnego zakresu funkcjonalności. Równocześnie, usługa powinna móc pracować w ramach systemów heterogenicznych, czyli złożonych z komponentów wykonanych w różnych technologiach. Dzięki temu, usługi mogą być instalowane w różnych konfiguracjach i na różnych węzłach wykonawczych. Zdecydowanie zwiększa to elastyczność architektury i łatwość rozwoju systemu zbudowanego z usług. Usługi mogą być dostępne w sieci i wtedy takie usługi nazywamy usługami webowymi (ang. web service).Zwróćmy uwagę na to, że kontrakt powinien być zgodny ze strukturą usługi, to znaczy – operacjami odpowiedniego interfejsu oraz klasami definiującymi obiekty transferu danych (ang Data Transfer Object, DTO). Obiekt transferu danych oznacza spójny pakiet danych przesyłany między komponentami w celu wykonania zadanych operacji. W naszym przykładzie na rysunku 3.2, klasy definiujące obiekty transferu danych wyróżniliśmy poprzez nadanie im przedrostka „X” (w języku angielskim skrót od X-fer = transfer). Alternatywnie, można np. zastosować przyrostek „DTO” oraz oznaczyć klasę odpowiednim stereotypem (np. «DTO»).
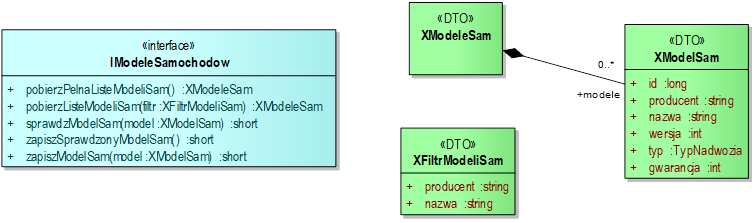
Rysunek 3.2: Przykładowy diagram definiujący interfejs usługi
Podejście architektoniczne, które bazuje na usługach nazywamy architekturą zorientowaną na usługi (ang. Service Oriented Architecture, SOA). Można również wyróżnić wariant architektury SOA – architekturę mikro-usługową (ang. microservice architecture). Wariant ten jest oparty na usługach, które dostarczają niewielkich, bardzo silnie skupionych zestawów operacji. Niezależnie od wariantu, podstawą architektur typu SOA są usługi gotowe. Spełniają one wszystkie założenia architektur komponentowych – minimalizują zależności między komponentami i ukrywają implementację zwartych wewnętrznie komponentów. Dodatkowo, w dużym stopniu oparte są na reużywalności, czyli ponownym wykorzystaniu gotowych komponentów – usług. Zadanie architekta polega na odpowiedniej „orkiestracji” takich usług, czyli połączeniu ich w spójną całość, umożliwiającą realizację zadanych wymagań. W zdecydowanej większości przypadków konieczne jest stworzenie nowych komponentów, które spajają cały system. W razie braku gotowych komponentów usługowych może być też konieczne zbudowanie nowych usług.
Systemy usługowe mogą być projektowane jako heterogeniczne. Oznacza to, że system jest budowany z usług tworzonych w różnych technologiach – na przykład, pisanych w różnych językach czy korzystających z różnych systemów zarządzania bazami danych. Dodatkowo, usługi mogą być zainstalowane na różnych węzłach wykonawczych, korzystających z różnych systemów operacyjnych i komunikujących się za pośrednictwem sieci. Aby takie usługi mogły się ze sobą efektywnie komunikować w sieci, potrzebny jest wspólny protokół wymiany danych. Interfejsy stosujące takie wspólne protokoły nazywamy interfejsami programowania aplikacji (ang. Application Programming Interface, API).
Obecnie najczęściej stosowanym stylem dla tworzenia API jest podejście REST (ang. REpresentational State Transfer), czyli „zmiana stanu poprzez reprezentację”. Jest ono oparte na idei nawigacji przez zasoby systemu poprzez wybieranie łączy webowych, co skutkuje zmianą stanu i przesłaniu reprezentacji tego stanu w celu jego udostępnienia użytkownikowi. REST korzysta ze standardowego protokołu HTTP, używanego m.in. w komunikacji WWW (ang. World Wide Web). Podstawowe zasady tworzenia systemów z API REST obejmują m.in. rozdzielenie obowiązków, bezstanowość, warstwowość, jednolitość interfejsów. Interfejsy REST są udostępniane w jednolity sposób pod odpowiednim adresem zasobu (tzw. URI, ang. Uniform Resource Identifier), np. „https://moj.adres.pl/samochody”. Możemy tutaj wyróżnić adres bazowy oraz tzw. punkt końcowy (ang. endpoint). W projekcie komponentowym, adres bazowy określa położenie całego komponentu (usługi). Punkt końcowy natomiast określa kanał dostępu do usługi reprezentowany na modelu jako port (np. o nazwie „/samochody”).
Interfejsy REST korzystają ze standardowych typów operacji HTTP (GET, PUT, POST, DELETE). Operacje zaprojektowane w ramach danego interfejsu (patrz np. interfejs na rysunku 9.2) stanowią składowe dostępne pod adresem zagnieżdżonym w stosunku do adresu punktu końcowego (np. „/samochody/sprawdz”). Wymiana danych następuje albo poprzez wartość (zapisaną w adresie), albo poprzez pliki (najczęściej w formacie JSON, czasami XML lub RSS). Wadą takiego sposobu komunikacji jest przesyłanie danych w sposób tekstowy, co zdecydowanie zwiększa objętość przesyłanych danych.
9.3. Typowe style architektoniczne
Jak już wspomnieliśmy, podział systemu na komponenty lub usługi jest najważniejszą decyzją podejmowaną przez architekta. Kluczowe w takim podziale jest odpowiednie określenie odpowiedzialności poszczególnych komponentów. Część komponentów powinna odpowiadać za komunikację z użytkownikami, część – za realizację logiki przetwarzania danych, a jeszcze inne – za przechowywanie danych. Te różne poziomy odpowiedzialności komponentów najkorzystniej jest zorganizować w warstwy. Stąd też, najpowszechniej stosowanym podziałem komponentów jest tzw. architektura warstwowa. Poszczególne warstwy określają odległość komponentów od środowiska zewnętrznego (użytkowników, systemów zewnętrznych). Istotną cechą systemów w architekturze warstwowej jest uporządkowanie komunikacji między warstwami. Komponenty mogą komunikować się w jedynie ramach danej warstwy lub z warstwą wyżej lub niżej. Nie jest dopuszczalna komunikacja przez wiele warstw.
Najprostszym stylem architektonicznym jest podział na dwie warstwy, czasami nazywany architekturą klient-serwer. Warstwa górna (klient) odpowiada za interakcję z użytkownikiem, a warstwa dolna (serwer) – za przetwarzanie i przechowywanie danych. Takie podejście można porównać do ogólnej struktury zakładu usługowego. Dla klienta widoczna jest przede wszystkim witryna (ang. frontend), a właściwe wykonanie usługi odbywa się na zapleczu (ang. backend). Tego typu metafora jest często stosowana przy określaniu warstw w systemach opartych na technologiach webowych. Komponenty zawierające interfejs użytkownika oraz logikę nawigacji między ekranami nazywa się „frontendem”. Komponenty wykonujące zadania przetwarzania danych oraz komponenty przechowujące dane nazywa się „backendem”.
Architektura dwuwarstwowa jest często zbyt ogólna, dlatego też często stosuje się architekturę wielowarstwową. Najczęściej wyróżnia się cztery zasadnicze warstwy, które ilustruje rysunek 3.3. Dwie górne warstwy najczęściej stanowią frontend systemu, a dwie dolne – jego backend. Warstwa górna – Widok – odpowiada za komunikację z użytkownikami (ludźmi). Logika całego systemu podzielona jest na dwie warstwy. Warstwa Logiki aplikacji steruje działaniem systemu poprzez realizację funkcjonalności przypadków użycia. Warstwa Logiki dziedziny odpowiada za właściwe przetwarzanie danych oraz zmiany stanu systemu. Poziom logiki dziedzinowej jest również najdogodniejszy do zorganizowania komunikacji z systemami zewnętrznymi (maszynami). Najniższą warstwą jest warstwa Przechowywania danych, która umożliwia przechowywanie stanu systemu w sposób trwały. Najczęściej korzysta ona z odpowiedniego systemu zarządzania bazą danych. Poniżej przedstawimy rolę poszczególnych warstw oraz typowy sposób ich wzajemnej komunikacji.
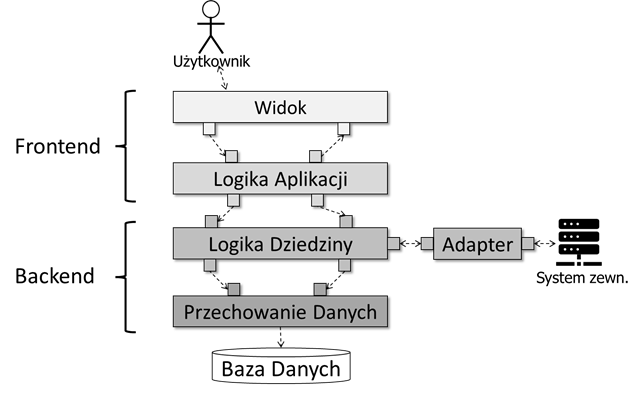
Rysunek 3.3: Schemat architektury warstwowej
Warstwa widoku obsługuje elementy interfejsu użytkownika (formularze, menu, okna multimediów, itd.) oraz umożliwia wymianę danych z użytkownikiem – wprowadzanie danych przez użytkownika oraz prezentację (wyświetlanie) danych użytkownikowi. Warstwa widoku komunikuje się z jednej strony z użytkownikiem, a z drugiej strony – z warstwą logiki aplikacji. Schemat komunikacji dla warstwy widoku ilustruje przykład na rysunku 3.4. Komponent warstwy widoku (tu: „UISprzedawcy”) reaguje na dwa rodzaje komunikatów. Z jednej strony, otrzymuje on polecenia od komponentu warstwy logiki aplikacji (tu: „AppSprzedawcy”). Dotyczą one potrzeby zaprezentowania (wyświetlenia) nowego widoku (np. okna, formularza) w ramach interfejsu użytkownika. Z drugiej strony, od użytkownika (tu: „Sprzedawca”) docierają komunikaty związane z różnego rodzaju zdarzeniami (np. przyciśnięcie przycisku, wybranie opcji). Takie komunikaty mogą również być związane z wprowadzeniem przez użytkownika odpowiednich danych.

Rysunek 3.4: Schemat komunikacji warstwy widoku
Zdarzenie oraz dane otrzymane od użytkownika są natychmiast przesyłane przez komponent warstwy widoku do komponentu warstwy logiki aplikacji. Odpowiada to realizacji kolejnej akcji (kroku) w scenariuszu interakcji aktora z systemem (np. w scenariuszu przypadku użycia). Z drugiej strony, każdy komunikat otrzymany od warstwy logiki aplikacji przekładany jest na odpowiednie polecenia wyświetlenia nowych elementów interfejsu użytkownika. Zwróćmy uwagę na to, że ten ostatni komunikat jest komunikatem poniekąd wirtualnym.
W ramach swojej implementacji, komponenty warstwy widoku zawierają odpowiedni kod (np. klasy) odpowiedzialny za rysowanie („renderowanie” od ang. render) elementów ekranowych oraz obsługę zdarzeń pochodzących od użytkownika. Bardzo istotne jest to, że w ramach swojej logiki, kod warstwy widoku odpowiada jedynie za prezentowanie oraz przyjmowanie danych.
Warstwa logiki aplikacji bezpośrednio odpowiada za realizację scenariuszy interakcji użytkowników z systemem. W tej warstwie zawarta jest implementacja logiki opisanej np. scenariuszami przypadków użycia. Warstwa logiki aplikacji komunikuje się z jednej strony z warstwą widoku, a z drugiej strony – z warstwą logiki dziedzinowej. Schemat komunikacji dla warstwy widoku ilustruje przykład na rysunku 3.5. Z warstwy widoku (tu: „UISprzedawcy”) docierają polecenia wykonania kolejnych akcji (kroków) scenariuszy wraz z danymi wprowadzonymi przez użytkownika. W rezultacie, komponent warstwy logiki aplikacji (tu: „AppSPrzedawcy”) podejmuje odpowiednie działania zgodne z odpowiednim krokiem w scenariuszu. Działania mogą być dwojakiego rodzaju. Po pierwsze, komponent może poprosić warstwę logiki dziedzinowej (tu: „Zamowienia”) o wykonanie jakiegoś zadania przetwarzania, aktualizacji lub odczytu stanu danych. Zazwyczaj zadanie jest wykonywane w sposób synchroniczny, czyli na końcu jest przesyłany komunikat zwrotny, zawierający wynik wykonania zadania (np. status lub odczytane dane). Drugi rodzaj działania polega na przesłaniu komunikatu do warstwy widoku z poleceniem wyświetlenia nowego widoku oraz ew. przesłanie danych do wyświetlenia.

Rysunek 3.5: Schemat komunikacji warstwy logiki aplikacji
Zwróćmy uwagę na to, że komunikaty między warstwą logiki aplikacji a warstwą logiki dziedzinowej przepływają w obydwie strony, lecz odpowiednia zależność na rysunku 3.5 jest skierowana w jedną stronę. Wynika to z tego, że komunikacja między tymi warstwami jest zazwyczaj synchroniczna w jednym kierunku.
Warstwa logiki dziedzinowej (często nazywana warstwą logiki biznesowej) odpowiada za wykonywanie wszystkich zadań związanych z przetwarzaniem oraz zmianą stanu danych w systemie. Warstwa logiki dziedzinowej komunikuje się z jednej strony z warstwą logiki aplikacji, a z drugiej strony – z warstwą logiki przechowywania danych. Schemat komunikacji dla warstwy logiki dziedzinowej ilustruje przykład na rysunku 3.6. Komponent tej warstwy (tu: „Zamówienia”) reaguje na komunikat zlecający wykonanie określonego zadania. Wykonanie zadania zależy od treści komunikatu oraz zawartych w nim danych. Może to być określone przetwarzanie danych, zmiana stanu systemu lub odczyt stanu systemu. Po wykonaniu zadania, komponent zwraca jego wynik komponentowi, który zadanie zlecił. Wynik może zawierać proste przekazanie sterowania, odpowiedni kod odpowiedzi lub obiekt transferu danych. W przypadku konieczności zmiany stanu lub odczytu stanu systemu, komponent warstwy logiki dziedzinowej przesyła komunikat do warstwy przechowywania danych (tu: „GlownaBazaDanych”). Komunikat taki zawiera odpowiednie zapytanie o dane lub zlecenie aktualizacji danych. W rezultacie, zwrotnie przesyłany jest komunikat z wynikiem zapytania lub rezultatem aktualizacji danych. Wynik ten może być wykorzystany np. do dalszego przetwarzania danych.

Rysunek 3.6: Schemat komunikacji warstwy logiki dziedzinowej
Warstwa przechowywania danych jest odpowiedzialna za trwały zapis oraz odczyt utrwalonych danych na odpowiednich nośnikach danych i przy wykorzystaniu odpowiednich systemów zarządzania utrwalaniem danych (np. systemy zarządzania bazami danych). Warstwa ta komunikuje się z warstwą logiki dziedzinowej, co ilustruje omawiany już rysunek 3.6. Kod w ramach tej warstwy zależny jest od konkretnej technologii przechowywania danych. Może to być relacyjna baza danych, baza danych NoSQL, repozytorium grafowe, system plików. Zapytania otrzymywane z warstwy logiki dziedzinowej dotyczą wykonania operacji na danych typu CRUD (Create / Read / Update / Delete). Są to typowe operacje związane z aktualizacją oraz odczytem danych. Komponenty w warstwie przechowywania danych mają za zadanie przetłumaczyć zapytania z formatu przyjętego w warstwach logiki (np. obiekty transferu danych) na odpowiednie zapytania w formacie przyjętym przez daną technologię przechowywania danych. Na przykład, w technologiach relacyjnych, zapytania są formułowane w języku SQL (Sequence Query Language).
Architektura warstwowa jest prawdopodobnie najczęściej spotykanym rozwiązaniem projektowym w typowych systemach interaktywnych (komunikujących się z użytkownikami – ludźmi). Istnieją jednak również inne style architektoniczne, w tym takie, które są przeznaczone np. do projektowania systemów wbudowanych (np. system sterowania samochodem), systemów automatyki (np. system sterowania produkcją) lub systemów obliczeń inżynierskich (np. obliczenia rozproszone przy wykorzystaniu superkomputerów). Omówienie wszystkich spotykanych styli architektonicznych jest poza zakresem niniejszego podręcznika.