Podręcznik
3. Zdolności generalizacyjne sieci neuronowych
3.8. Przykład metody zwiększania zdolności generalizacyjnych sieci
Jako przykład możliwości zwiększenia zdolności generalizacyjnych sieci rozważymy problem rozpoznania zmian czerniakowych skóry od innych zmian skórnych. Przykłady obrazów ilustrujących oba rodzaje zmian przedstawiono na rys. 3.5 [35].
|
Zmiany inne (nie czerniakowe) |
Czerniak |
|
|
|
|
|
|
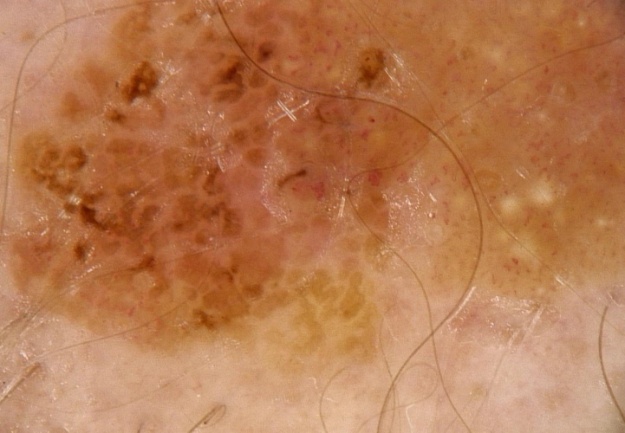
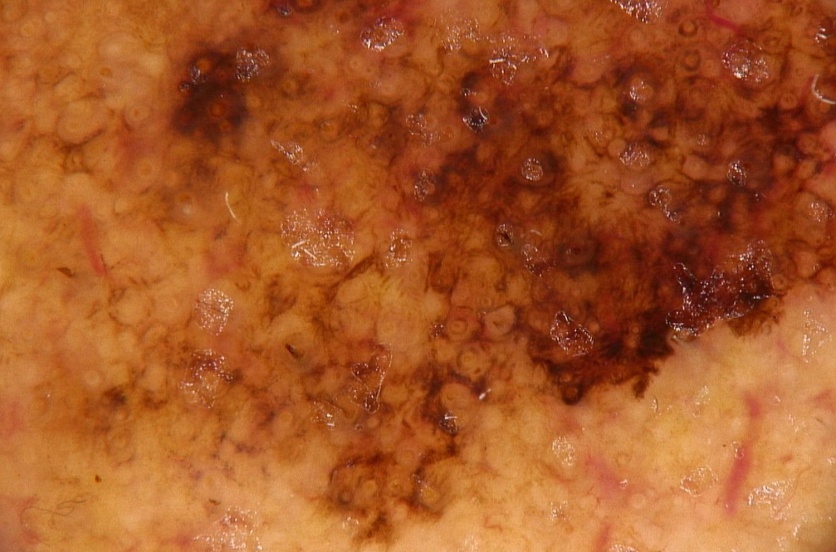
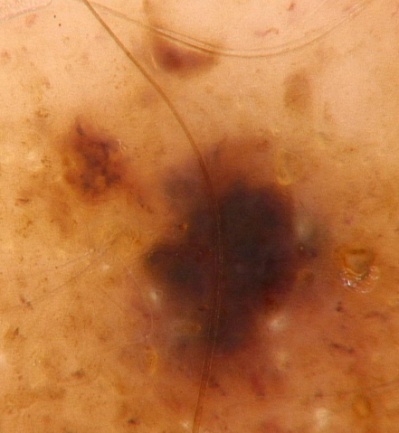
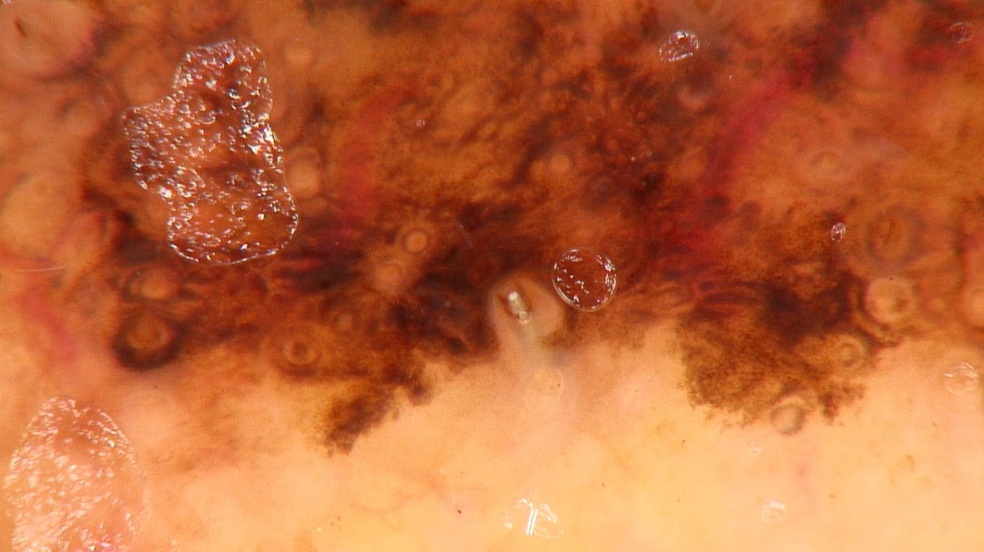
Obrazy podlegające rozpoznaniu tworzą 2 klasy: czerniak i nie czerniak). Zostały one poddane różnego rodzaju opisom tworzącym zbiór deskryptorów numerycznych obrazu (deskryptory statystyczne bazujące na teorii Kołmogorowa-Smirnowa, deskryptory perkolacyjne, teksturalne, fraktalne itp.). W sumie wygenerowano zbiór 81 deskryptorów. Jako klasyfikator zastosowano sieć SVM. Przy podaniu pełnego zbioru deskryptorów na sieć uzyskano dokładność rozpoznania obu klas równą 85.47%. Redukcja liczby deskryptorów poprzez zastosowanie selekcji cech pozwoliła zdecydowanie zwiększyć tę dokładność, przy czym różne metody selekcji prowadziły do różniących się wyników. Najlepszą okazała się metoda dyskryminacyjna Fishera, zgodnie z która każdej cesze przy rozpoznaniu 2 klas (A i B) przypisuje się wagę \( S_{AB}(f) \) określoną wzorem
| \( S_{A B}(f)=\frac{\left|c_A(f)-c_B(f)\right|}{\sigma_A(f)+\sigma_B(f)} \) | (3.15) |
Parametry \( c_A \) i \( c_B \) są wartościami średnimi cechy \( f \) dla klasy \( A \) i \( B \), natomiast \( \sigma_A \) i \( \sigma_B \) reprezentują odchylenia standardowe cechy w obu klasach. Im większa wartość wagi \( S_{AB}(f) \) tym ważniejsza jest dana cecha w rozpoznaniu obu klas. W przypadku rozpoznania czerniaka uzyskano wykres zmian wartości tej wagi dla poszczególnych deskryptorów jak na rys. 3.6.
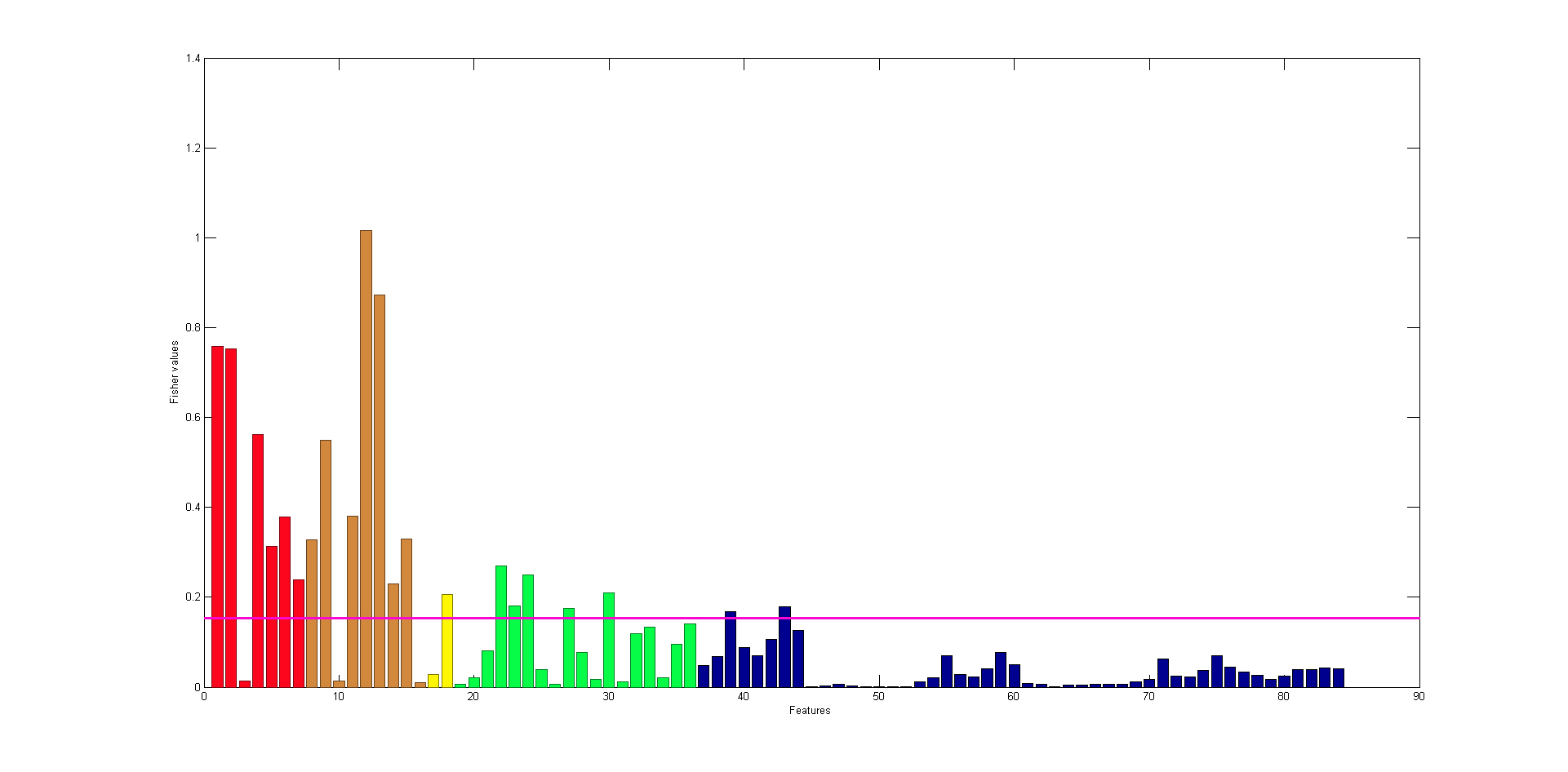
Ustanawiając próg ważności (pozioma linia różowa) można łatwo wyselekcjonować te cechy, które są powyżej tej linii jako cechy diagnostyczne procesu. W tym przypadku z 81 deskryptorów selekcjonuje się tylko zbiór 21 deskryptorów traktowanych jako cechy diagnostyczne (atrybuty wejściowe dla klasyfikatora). Przy zastosowaniu tego zbioru uzyskano podwyższoną dokładność rozpoznania obu klas równą 93.76% (wzrost dokładności o 8.27 punktów procentowych).