Podręcznik
3. Sieci neuronowe głębokie
3.5. Inne rozwiązania pre-trenowanej architektury sieci CNN
Sieci CNN ze względu na ich uniwersalność i prostotę użycia w przetwarzaniu obrazów zyskały wiele różnych rozwiązań, poprawiających działanie i ułatwiających uczenie sieci [75]. Istnieje aktualnie wiele dostępnych struktur CNN, wytrenowanych wstępnie i dostosowanych do operacji „transfer learning”. Przykładami takich rozwiązań są między innymi:
-
GoogLeNet – zaprojektowany przez zespół Google, operuje zmniejszoną liczbą parametrów podlegających uczeniu (z 61 milionów w AlexNet do 7 milionów) przez wprowadzenie modułu wstępnego przetwarzania. Poza tym stosuje Average Pooling zamiast Max Pooling, co zmniejsza utratę informacji w kolejnych etapach przetwarzania. Aktualnie programy z tej serii są stale ulepszane pod nazwą inception [63,64]].
-
ResNet ukształtowany przez zespół Kaiming He [25]. Główną nowością jest wprowadzenie dodatkowego połączenia międzywarstwowego co drugą warstwę, jak również zastosowanie tzw. batch normalization, czyli normalizacji zastosowanej do małego zbioru próbek uczących (wartość średnia zerowa i jednostkowa wariancja).
-
EfficientNet – model skalowanej sieci CNN zaproponowany przez M. Tana i Q.V. Le [66]. Cecha charakterystyczną tej architektury jest dobór odpowiednich proporcji parametrów skali dotyczących głębokości (liczba warstw), szerokości (liczba równolegle tworzonych obrazów w warstwie) oraz rozdzielczości obrazów w poszczególnych warstwach.
-
U-NET – struktura sieci CNN opracowana przez zespół Ronnebergera [56] dostosowana specjalnie do zadań segmentacji obrazów, zwłaszcza medycznych. Pozwala na odtworzenie poszczególnych rejonów obrazów w pełnej rozdzielczości.
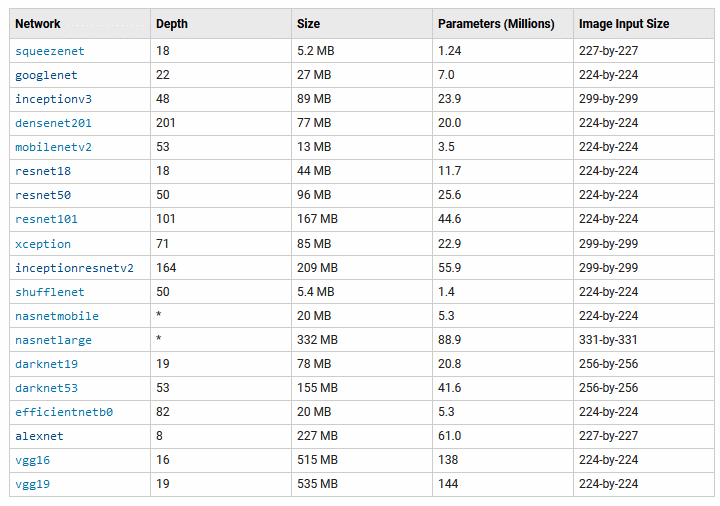
Matlab ma zaimplementowane wiele gotowych (pre-trenowanych) prototypów takich sieci. Poniżej przedstawione są dostępne aktualnie w Matlabie (Matlab 2021b) modele pre-trenowane oraz ich podstawowe parametry [43].
Jednym z problemów w sieciach wielowarstwowych jest zanikanie bądź eksplozja wartości gradientu w procesie uczenia. Przy wzrastającej liczbie warstw ukrytych obserwowany był nawet wzrost błędu dopasowania. Rozwiązanie, zwane Resnet, zaproponowane w [25] polegało na wprowadzeniu dodatkowego połączenia między-warstwowego o tym samym kierunku przepływu sygnałów. Sposób połączenia przedstawiony jest na rys. 6.6, w którym operacje sumowania dotyczą wszystkich elementów poszczególnych warstw.
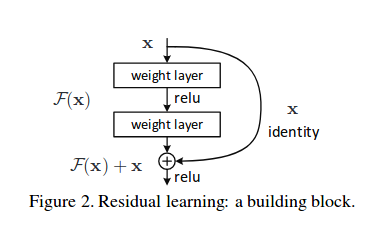
Idea rozwiązania polega a zastąpieniu odwzorowania F(x) reprezentowanego przez 2 warstwy konwolucyjne poprzez odwzorowanie F(x)+x. Oznacza to, że w rzeczywistości wagi sieci adaptowane są w procesie uczenia do odwzorowania resztkowego (residualnego) F(x)-x.
Przykładowy fragment struktury sieci Resnet przedstawiony jest na rys. 6.7. Bloki konwolucji składają się z operacji konwolucji, batch normalization oraz funkcji nieliniowej ReLU.
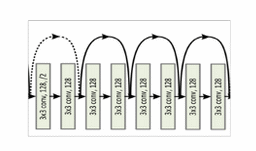
Linie ciągłe dotyczą połączeń międzywarstwowych o tych samych wymiarach macierzy. Połączenie kropkowane dotyczy przypadku, gdy wymiary warstwy startowej i docelowej różnią się (warstwa startowa 256×256, warstwa docelowa 128×128. . Zmniejszanie wymiaru między warstwami uzyskane jest dzięki parametrowi stride (przesunięcia filtra konwolucyjnego) równemu 2. W przypadku odwrotnym, gdy wymiary bloku startowego są mniejsze niż docelowego wymiary x uzupełnia się przez dodanie odpowiedniej liczby zer (tzw. zero padding).
Przykład bardziej złożonej struktury Resnet o 34 warstwach parametrycznych z powiązaniami residualnymi przedstawia rys. 6.8 (Resnet34) [43].

Ważnym problemem występującym w sieciach CNN jest ogromna liczba parametrów adaptowanych w procesie uczenia. Przykładowo, w pierwszym rozwiązaniu sieci AlexNet ich liczba sięga 61 milionów. Oznacza to duże koszty czasowe uczenia takiej sieci jak również jej implementacji scalonej. Stąd wysiłek wielu badaczy jest skierowany na zredukowanie liczby parametrów poprzez odpowiednią modyfikację struktury sieci i sposobu przetwarzania sygnałów. Stosowane są przy tym różne strategie. Jedną z nich jest częściowe zastępowanie większych filtrów, np. 5x5 poprzez filtr 1x1. Oznacza to automatycznie redukcję 25-krotną liczby parametrów w procesie przetwarzania. Innym kierunkiem jest zmniejszenie liczby kanałów (obrazów) wejściowych w poszczególnych warstwach poddanych filtracji 1x1 i 3x3. Tego typu rozwiązanie zastosowano w sieci SqueezeNet [30], wprowadzając specjalne moduły przetwarzania (tzw. Fire module), przedstawione na rys. 6.9.
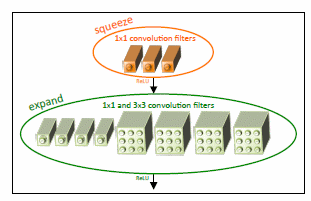
Liczba filtrów 1x1 w warstwie squeeze (a więc i liczba obrazów wyjściowych tej podwarstwy) jest mniejsza niż suma filtrów 1x1 i 3x3 w warstwie expand, co redukuje skutecznie liczbę adaptowanych parametrów. W zaproponowanej strukturze sieci SqueezeNet stosuje się 9 modułów „Fire” zakończonych warstwą conv10 o 1000 obrazów wyjściowych poddanych operacji global average pooling, tworzących 1000 sygnałów wejściowych dla warstwy softmax (brak w sieci warstw ukrytych w pełni połączonych). W sumie sieć Squeezenet zawiera 68 warstw (głębokość równa 18). Dzięki wprowadzonym modułom Fire udało się zredukować liczbę parametrów adaptowanych do 1.24 miliona uzyskując na bazie danych ImageNet tę sama dokładność co AlexNet o 61 milionach parametrów.
Inne rozwiązanie problemu zmniejszenia wymiarów sieci (liczby parametrów poddanych adaptacji) i zmniejszenia liczby operacji zmiennoprzecinkowych w procesie uczenia zostało zastosowane w sieci ShuffleNet [71]. Idea przyśpieszenia obliczeń polega na grupowaniu filtrów 1x1 (tzw. pointwise convolution) w grupy operujące na zredukowanej liczbie kanałów (obrazów) wejściowych, a nie na całym zbiorze obrazów warstwy poprzedniej. Tworzy się równolegle wiele grup operujących na wybranych losowo podgrupach obrazów wejściowych. Niestety część informacji globalnej uzyskanej z takiego grupowego przetworzenia nie wykazuje wzajemnych relacji, ponieważ przetworzeniu podlegały inne zestawy obrazów wejściowych. Stąd autorzy sieci zaproponowali w następnym etapie przetasowanie podgrup (operacja shuffle). Każda grupa wytworzona w etapie poprzednim podlega podziałowi na wiele podgrup. Podgrupy te po przetasowaniu tworzą zestawy obrazów zasilające warstwę następną. Typowy schemat przetwarzania w ramach jednej warstwy przedstawiony jest na rys. 6.10.
|
|
|
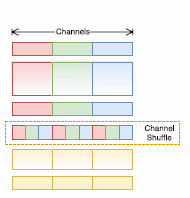
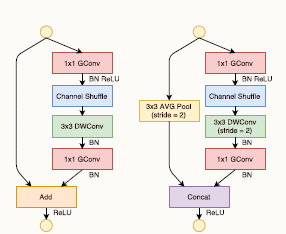
Rys. 6.10 Schemat przetwarzania grupowego punktowego (1x1) połączonego z przetasowaniem zastosowane w ShuffleNet: a) ilustracja procesu grupowania i przetasowania, b) schemat komórki podstawowej sieci: GConv oznacza konwolucję typu grupowego, BN – normalizacja danych w zbiorze MiniBatch, Concat – konkatenacja (złączenie) danych z obu kanałów.
W sumie sieć ShuffleNet ma głębokość równą 50 (liczba wszystkich podwarstw równa 203). Udało się zredukować liczbę parametrów adaptowanych do 1.4 miliona przy porównywalnej do AlexNet dokładności działania.
Inne rozwiązanie problemu przyspieszenia obliczeń poprzez zmniejszenie złożoności obliczeniowej zaproponowane zostało w sieci MobileNet [27,61] W sieci tej stosuje się 2 rodzaje konwolucji. Pierwsza z nich tzw. depthwise convolution stosuje pojedynczy filtr do każdego kanału (obrazu). Następuje po niej drugi etap tzw. pointwise convolution, operacja stosująca filtr 1x1 działający na sumie obrazów wytworzonych w etapie poprzednim. Jest to zasadnicza różnica w stosunku do klasycznego rozwiązania konwolucyjnego, w którym filtracja i sumowanie jej wyników w tworzeniu obrazów wyjściowych dotyczyło wielu obrazów wejściowych na raz i występowało dla każdego nowo tworzonego obrazu.

W efekcie organizacja przetwarzania sygnałów w warstwie może być przedstawiona jak na rys. 6.11., na którym 3x3 Depthwise Conv dotyczy działania filtru 3x3 na pojedynczym obrazie, a 1x1 Conv dotyczy konwolucji z filtrem 1x1 działającym na zbiorze wcześniej wygenerowanych obrazach. BN oznacza operację normalizacji na podzbiorze MiniBatch, a ReLU funkcję nieliniową aktywacji. W efekcie uzyskuje się dużą redukcję wymiarów sieci. Zaproponowane rozwiązanie MobileNetv2 w Matlabie zredukowało wymiar sieci do 13MB przy głębokości 53 i 3.5 miliona adaptowanych parametrów.
Ciekawym krokiem w rozwoju sieci głębokich było opracowanie struktury GoogLeNet (traktowana później jako Inception-v1) [63,64]. Idea modyfikacji polega na prowadzeniu równolegle działających filtrów o różnych wymiarach. Każdy z takich filtrów specjalizuje się w rejonach obrazu o różnej skali szczegółowości. Inną modyfikacją było rozszerzanie sieci wszerz, a nie tylko w głąb. Autorzy rozwiązania wprowadzili równolegle działające bloki konwolucyjne stosujące filtry o wymiarach 1×1, 3×3 oraz 5×5. Blok o małych wymiarach 1×1 odpowiedzialny jest za liniową redukcję wymiarowości obrazu wejściowego jednocześnie pozwalając na zmniejszenie czasu obliczeń, w stosunku do większych filtrów konwolucyjnych. Rolę taką pełni komórka zwana Inception. Struktura takiej komórki przedstawiona jest na rys. 6.12.
|
|
|
Rys. 6.12 Struktura komórki Inception [64].
|
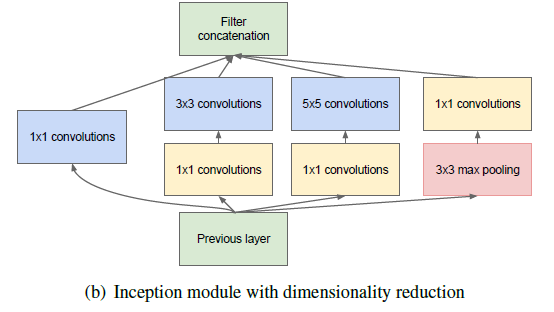
Komórka Inception zawiera 4 równolegle połączone gałęzie i w każdej z nich występuje konwolucja 1×1 jako sposób redukcji wymiarowości problemu i złożoności obliczeniowej.
 |
|
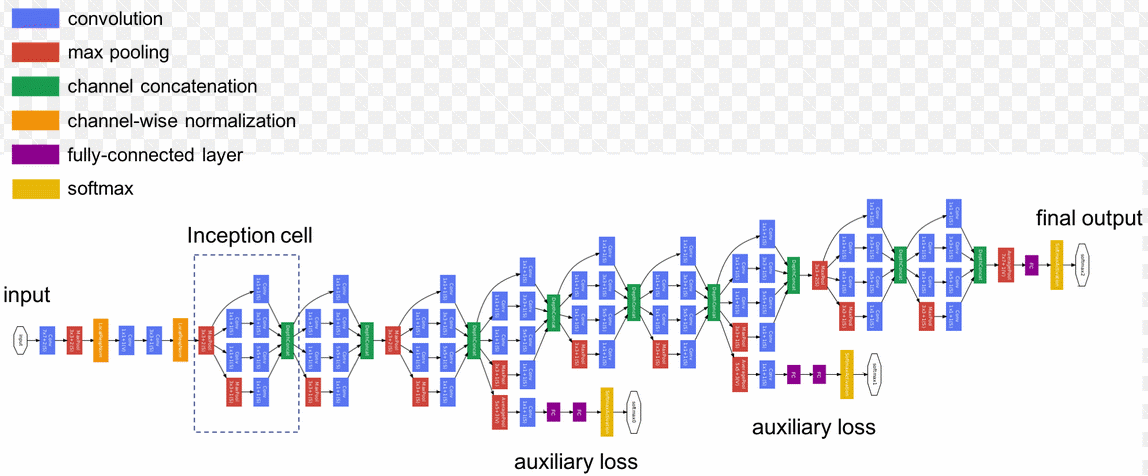
Rys. 6.13 Architektura sieci GoogLeNet [63].
|
Struktura sieci GoogLeNet składa się z 9 połączonych ze sobą komórek Inception, jak to przedstawiono na rys. 6.13. Zawiera w sumie około 100 niezależnych bloków, przy czym głębokość liczona w liczbie warstw podlegających uczeniu jest równa 22 (nie wliczając warstwy typu pooling). Jak podają autorzy uczenie takiej sieci jest bardzo czasochłonne (około tygodnia przy zastosowaniu kilku GPU pracujących w trybie równoległym).
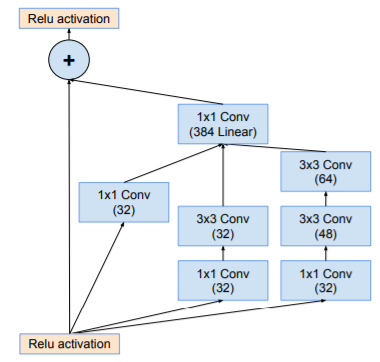
Dalsze prace zespołu rozwijały powyższy model pod zmienioną nazwą Inception. Powstało kilka kolejno ulepszanych struktur komórki Inception i połączeń warstwowych. Jedną z nich jest hybryda różnych modeli Inception i ResNet, czyli Inception-ResNet-v2, w której dodano połączenie residualne do komórek Inception. Przykład tak zmodyfikowanej struktury komórki przedstawiono na rys. 6. 14.
Badania nad skutecznością działania sieci CNN pokazały, że dużą rolę odgrywa dobór odpowiednich proporcji między głębokością (depth) architektury traktowaną jako liczba warstw konwolucyjnych, liczbą równolegle tworzonych obrazów wynikowych w poszczególnych warstwach (width) oraz rozdzielczością obrazów tworzonych w poszczególnych warstwach (resolution). Rys. 6.15 przedstawia ideę skalowania sieci Efficientnet, stworzoną przez M. Tana i Q.V. Le [66].
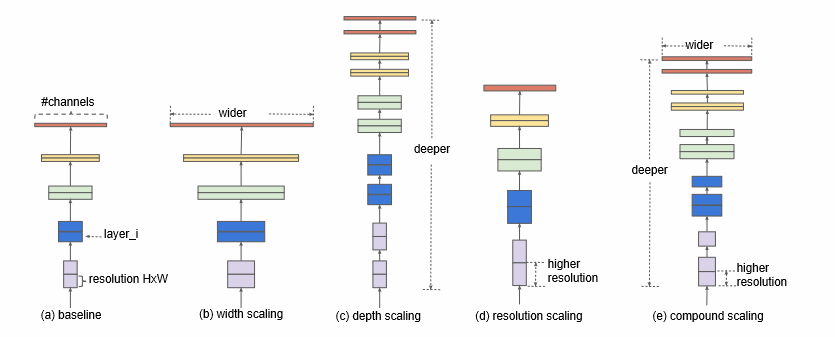
Odpowiednie zwiększenie skali dotyczącej głębokości, szerokości i rozdzielczości w stosunku do struktury konwencjonalnej (baseline) pozwala uzyskać znacznie większą dokładność klasyfikatora przy znakomicie zmniejszonej złożoności obliczeniowej. W pracy tej pokazano porównanie uzyskanej dokładności różnych rozwiązań sieciowych przy odpowiadającej sobie liczbie operacji zmiennoprzecinkowych, wykazując zdecydowaną przewagę sieci EfficientNetB6 w problemie benchmarkowym „ImageNet”.
Oryginalnym rozwiązaniem sieci konwolucyjnych jest sieć DenseNet operująca wieloma połączeniami między-warstwowymi w przód. W klasycznym rozwiązaniu CNN przekazywanie sygnałów następuje kolejno z warstwy na warstwę sąsiadującą (brak połączeń między odległymi warstwami) [17,29]. W efekcie traci się wiele informacji, co prowadzi między innymi do zanikania gradientu (skorygowane w sieci Resnet). Poza tym nie wykorzystuje się bezpośrednio oryginalnych cech wytworzonych w warstwach wcześniejszych osłabiając w efekcie ich działanie. Struktura przetwarzania sygnałów zaproponowana przez autorów [17,29] przedstawiona jest na rys. 6.16.

Sygnały wyjściowe poszczególnych warstw przekazywane są bezpośrednio nie tylko na warstwę sąsiednią, ale również na wszystkie warstwy następne. Dzięki temu możliwe stało się ograniczenie głębokości sieci (liczby warstw). Struktura sieci DenseNet przedstawiona jest na rys. 6.17.

Pomiędzy blokami typu Dense stosowane są dodatkowo operacje konwolucji i poolingu. W jej ramach wykonuje się normalizację danych w MiniBatch, konwolucję jednopunktową filtrem 1x1 oraz operacje 2x2 average pooling. Implementacja DenseNet w Matlabie pod nazwą densenet201 zawiera 20 milionów adaptowanych parametrów i głębokość równa 201. Jej skuteczność jest porównywalna z najlepszymi rozwiązaniami sieci.