Podręcznik
2. Listy jednokierunkowe
2.1. Podstawowe informacje o listach jednokierunkowych
Lista jednokierunkowa to wzajemnie połączone ze sobą liniowo elementy. Każdy element posiada jakieś dane oraz adres kolejnego elementu na liście.Dzięki temu lista może dynamicznie zmieniać swój rozmiar tzn. elementy mogą być dowolnie dodawane lub usuwane bez konieczności przesuwania pozostałych elementów, jak ma to miejsce w tablicy.Przechowywanie listy jednokierunkowej w pamięci odbywa się poprzez dynamiczną alokację. Węzły są tworzone w obszarze pamięci zwanym stertą (ang. heap), który służy do przechowywania obiektów o dynamicznie określonym czasie życia. W przeciwieństwie do tablicy, w której elementy są przechowywane w kolejnych komórkach pamięci, węzły listy mogą być rozmieszczone w dowolnych, niepowiązanych ze sobą adresach pamięci. To właśnie wskaźniki przechowywane w każdym węźle zapewniają powiązanie między nimi i pozwalają na odtworzenie logicznego porządku listy.
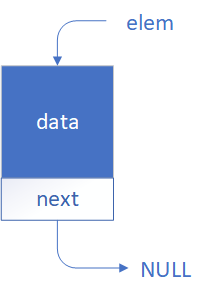
Każdy węzeł składa się z dwóch części: pola przechowującego dane użytkownika (na przykład liczby lub tekst) oraz pola przechowującego wskaźnik do kolejnego węzła. Wskaźnik ten jest adresem pamięci, pod którym znajduje się następny element listy. Ostatni węzeł w liście ma ustawiony wskaźnik na wartość pustą (NULL), co sygnalizuje koniec listy.
Na rysunku poniżej pokazano prezentację graficzną jednego elementu listy.
struct Element{
int data;
Element* next;
};
new.
Element* elem = new Element;
(*elem).data = 42; // przykładowa wartość
(*elem).next = NULL; // na razie brak następnego elementu
elem->data = 42; // przykładowa wartość
elem->next = NULL; // na razie brak następnego elementu
#include <iostream>
struct Element {
int data;
Element* next;
};
int main() {
// Utworzenie pierwszego elementu
Element* elem = new Element;
elem->data = 42;
elem->next = nullptr;
// Wyświetlenie wartości
std::cout << "Element data: " << elem->data << std::endl;
// Zwolnienie pamięci
delete elem;
return 0;
}
Adres ma taką samą wartość jak przed usunięciem obiektu.
Element* e1 = new Element;
Element* e2 = new Element;
Element* e3 = new Element;
e1->next = e2;
e2->next = e3
e3->next = NULL;
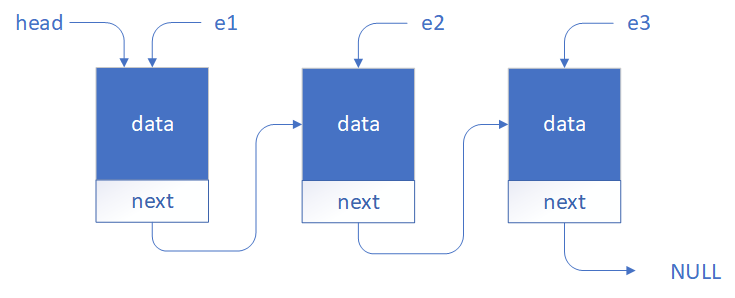
Widzimy na rysunku, że pojawił się dodatkowy wskaźnik
head. Jest to adres pierwszego elementu na liście. Posiadając adres pierwszego elementu na liście możemy uzyskać dostęp do dowolnego elementu na liście.
cout << head->data; // Wyświetla wartość w pierwszym elemencie listy
cout << head->next->data; // Wyświetla wartość w drugim elemencie listy
cout << head->next->next->data; // Wyświetla wartość w trzecim elemencie listy
head = NULL;
cout << head->data; // Jeżeli head=NULL to otrzymamy błąd dostępu do pamięci
Symulacja listy jednokierunkowej
struct Element { int data; Element* next; }; Element* current = head; while (current != nullptr) { std::cout << current << " " << current->data << " " << current->next << std::endl; current = current->next; }
#include <iostream>
using namespace std;
// Definicja elementu listy
struct Element {
int data;
Element* next;
};
// Funkcja dodająca element na koniec listy
void append(Element*& head, int value) {
Element* newElement = new Element;
newElement->data = value;
newElement->next = nullptr;
if (head == nullptr) {
head = newElement;
} else {
Element* current = head;
while (current->next != nullptr) {
current = current->next;
}
current->next = newElement;
}
}
// Funkcja drukująca listę
void printList(Element* head) {
Element* current = head;
while (current != nullptr) {
cout << "Adres: " << current << "wartość: " << current->data << " Adres następnego: " << current->next << endl;
current = current->next;
}
}
int main() {
Element* head = nullptr;
cout << "Podaj liczby do listy (0 konczy wprowadzanie):" << endl;
int value;
do {
cout << "Podaj liczbe: ";
cin >> value;
if (value != 0) {
append(head, value);
}
} while (value != 0);
cout << "\nUtworzona lista:" << endl;
printList(head);
// Zwolnienie pamięci
Element* current = head;
while (current != nullptr) {
Element* toDelete = current;
current = current->next;
delete toDelete;
}
return 0;
}
Element* current = head;
while (current != nullptr) {
\\ Tutaj mamy dostęp do kolejnych elementów znajdujących się na liście
current = current->next; \\ Przejście do kolejnego elementu na liście
}