Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | Podstawowe właściwości i zadania programowania liniowego; Metoda SIMPLEX |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | poniedziałek, 27 lipca 2026, 20:31 |
1. Wprowadzenie.
Podstawowe informacje
Klasą zadań, dla których najwcześniej podano algorytm prosty i skuteczny (i w zasadzie do dzisiaj najlepszy) są zadania liniowe optymalizacji. Zajmiemy się teraz krótko tymi zadaniami.
Zapisując te zadania i przedstawiając ich podstawowe własności będziemy posługiwać się notacją wektorowo macierzową, w której duże litery, np. A, oznaczają macierze, małe litery np. b, to w zasadzie wektory kolumnowe, małe litery z indeksami, np. xi oraz litery greckie to liczby, a znak T oznacza transpozycję.
Określmy formalnie przedmiot rozważań tego modułu.
Funkcja oceny jest tu liniowa, a nie afiniczna, bo jest oczywiste, że dodanie do niej dowolnej liczby nie zmienia rozważań (zmienia wartość funkcji wyboru w punkcie minimalizującym, która jest oczywiście od tej liczby zależna, ale rozwiązaniem zadania jest punkt minimalizujący, który się nie zmienia!).
Wprowadzenie
Narysujmy zbiór dopuszczalny i wykres poziomicowy funkcji wyboru dla prostego zadania liniowego (zapiszemy go w trochę inny sposób niż dotychczas, aby oswoić się z różnymi wariantami zapisu stosowanymi w literaturze).
\(f(x,y)=50x+100y →\mathrm{max}_{(x,y)}\)
przy ograniczeniach (p.o.)
\(10x + 5y \leq 2 500\) (a)
\(4x + 10y \leq 2 000\) (b)
\(x + 1.5y \leq 450 \) (c)
\(x \geq 0, \, y \geq 0. \)
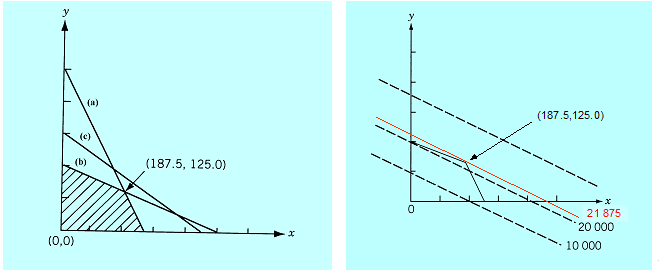
Z rysunku wynika, że ograniczenie (c) nie jest potrzebne, oraz że zbiór dopuszczalny jest wielokątem Linie poziomicowe funkcji liniowej to proste, zatem rozwiązanie leży w wierzchołku wielokąta (albo rozwiązań jest wiele i leżą na brzegu wielokąta, gdy poziomice są równoległe do stosownego ograniczenia).
Te wnioski można uogólnić na dowolne zadanie liniowe. Trzeba tylko wielokąt zastąpić wielościanem, a prostą – płaszczyzną. Zatem:
Wróćmy do naszego opowiadania o Algorytmie. Przyjmijmy, że przekazaliśmy mu powyższą wiedzę. Co Algorytm może wymyślić? Odpowiedź jest oczywista:
Musi znaleźć jakiś wierzchołek,
potem sprawdzić jego sąsiadów (dla minimalizacji, sprawdzić czy funkcja celu maleje),
wybrać najkorzystniejszy, i procedurę powtórzyć.
Na płaszczyźnie taki algorytm będzie działać, bo każdy wierzchołek ma tylko dwu sąsiadów, ale przy większej liczbie wymiarów będzie to bardzo powolne i nie wiadomo, czy algorytm się nie zapętli.
Pierwsze zadania optymalizacji, które obecnie zaliczamy do zadań liniowych sformułowano pod koniec lat trzydziestych XX w. (matematycy J. von Neumann z Princeton i L. Kantorowicz, wtedy z Leningradu). Różne zadania związane z optymalnym przydziałem zasobów sformułowano na potrzeby armii amerykańskiej w czasie drugiej wojny światowej. Wtedy też zaczęto intensywne prace nad opracowaniem metod pozwalających na znalezienie rozwiązań, jak wtedy zaczęto mówić, zadań programowania liniowego. W roku 1947 G.B. Dantzig opublikował swój algorytm znajdowania rozwiązania zadania liniowego optymalizacji. Nazwał go metodą SIMPLEX. W Polsce, nie bardzo wiadomo dlaczego, algorytm Dantziga nazywa się metodą sympleks, simpleksową, a nawet metodą sympleksów.
Nie będziemy szczegółowo prezentowali tego algorytmu, odsyłając Czytelnika do literatury (np. podręczników: A. Stachurski: Wprowadzenie do optymalizacji, Oficyna Wydawnicza PW 2009, rozdział 2, lub W. Findeisen, J. Szymanowski, A. Wierzbicki: Teoria i metody obliczeniowe optymalizacji, PWN 1977 (część I rozdział 4)). Przedstawimy tylko główną ideę jego działania.
Ponieważ w metodzie Simplex wykorzystuje się pojęcia i metody, które powstały dla rozwiązywania układu równań liniowych, pierwszą czynnością jaką trzeba wykonać jest przekształcenie otrzymanego zadania liniowego do tzw. postaci kanonicznej (standardowej). Zbiór dopuszczalny w postaci kanonicznej jest określony tylko przez ograniczenia równościowe i ograniczenia znaku.
Jeżeli oznaczymy
\(A=\begin{bmatrix}a_1^T \\\vdots \\a_p^T \end{bmatrix},\,\mathrm{oraz}\,b=\begin{bmatrix}\beta _1^T \\\vdots \\\beta _p^T\end{bmatrix},\)
a także przyjmiemy skrócony zapis \(x \geq 0\) na ograniczenia znaku, to określenie zbioru dopuszczalnego zadania w postaci kanonicznej możemy zapisać następująco
\(DK={x∈\mathbb{R}^n |x≥0∧Ax=b}, \,b≥0. \qquad (2.1)\)
Pokażemy teraz jak przejść z postaci ogólnej do kanonicznej.
- Ograniczenia nierównościowe przekształcamy wprowadzając zmienne dopełniające \(x_q+j\)
\([a_j^T w≤β_j∧w∈\mathbb{R}^q]⇔[a_j^T w+x_(q+j)=β_j∧x_(q+j)≥0].\)
- Nie w każdym zadaniu PLin konieczne jest ograniczenie znaku zmiennych. Ponieważ zmienne zadania w postaci kanonicznej muszą mieć ograniczony znak, to warunek ten spełnia się przez następujące podwojenie zmiennych:
\(w_i∈ \mathbb{R}⇔(w_i=x_i^+-x_i^-∧x_i^+≥0∧x_i^-≥0).\)
Omówimy teraz podstawowe zasady konstrukcji algorytmu Simplex.
2. Idea działania algorytmu Simplex
Zacznę od przedstawienia podstawowych definicji i faktów teoretycznych. Najpierw przypomnę definicję macierzy bazowej.
Oznaczmy przez \(x^{e(l)}\) l-ty punkt wierzchołkowy zbioru DK określonego wzorem (2.1). Można pokazać, że każdy wierzchołek tego zbioru, przy stosownym przenumerowaniu zmiennych, musi mieć postać
\(x^{e(l)}= (\underbrace{x_1^{\mathbf{B}(l)},\cdots x_p^{\mathbf{B}(l)}},0\cdots ,0). \qquad (2.2)\)
Wektor \(x^{\mathbf{B}(l)}\geq 0 \) wyróżniony we wzorze (2.2) nazywamy dopuszczalnym wektorem bazowym. Ponadto dla każdego punktu wierzchołkowego istnieje związana z nim macierz \(\mathbf{B}(l)\), taka że \(x^{\mathbf{B}(l)}=(\mathbf{B}^{(l)})^{-1} b\). Każda macierz \(\mathbf{B}(l)\) jest taką macierzą bazową równania liniowego \(Ax = b\), dla której \((\mathbf{B}^{(l)})^{-1} b \geq 0\), dlatego jest nazywana dopuszczalną macierzą bazową.
Zatem, aby znaleźć wierzchołek wystarczy znaleźć dopuszczalną macierz bazową, a następnie poprzez odwracanie macierzy i mnożenie policzyć wektor bazowy \(x^{\mathbf{B} }\in ℝ^p\) i uzupełnić go w stosownych miejscach zerami do wektora z przestrzeni \(ℝ^n\) .
Jak więc znaleźć dopuszczalne macierze bazowe związane z wierzchołkami?
W pierwszej połowie XIX w. K. Gauss przedstawił sposób postępowania, nazwany potem algorytmem eliminacji Gaussa, pozwalający znajdować kolejne macierze bazowe układu równań liniowych, jeżeli znamy pierwszą. Pierwsza część pomysłu G.B. Dantziga polegała na wzbogaceniu algorytmu eliminacji Gaussa tak, że nowy algorytm wychodząc od znanej dopuszczalnej macierzy bazowej, generuje dopuszczalne macierze bazowe, a ponadto wybiera je w taki sposób, że kolejny punkt wierzchołkowy jest nie gorszy niż poprzedni (wartość funkcji celu w kolejnym punkcie wierzchołkowym jest nie większa niż w punkcie poprzednim). Dantzig wprowadził też pierwsze wersje stosownych zabezpieczeń przeciwko pętleniu się algorytmu (o tym zjawisku szczegółowiej piszę dalej) i pokazał, że znajdzie on rozwiązanie w skończonej liczbie kroków jeżeli tylko ono istnieje, albo w skończonej liczbie kroków wykaże, że zadanie nie ma rozwiązania (zbiór dopuszczalny jest pusty albo nie jest ograniczony i funkcja celu ucieka na nim (w naszym przypadku minimalizacji) do minus nieskończoności.
Wiadomo już jak znaleźć kolejne dopuszczalne macierze bazowe gdy znamy pierwszą. Do rozwiązania pozostał więc problem: skąd wziąć pierwszą dopuszczalną macierz bazową?
Rozwiązano ten problem drogą posłużenia się następującym zadaniem pomocniczym.
\\y
\end{bmatrix}→\mathrm{min }\)
\\v
\end{bmatrix}=b, \qquad (2.3)\)
W zadaniu wprowadzono p zmiennych pomocniczych vj , tzn. tyle ile w postaci kanonicznej jest ograniczeń równościowych. Zauważmy też, że \((∀(x,v))f(x,v)≥0.\)
Jest to zadanie optymalizacji w postaci kanonicznej i do jego rozwiązania możemy posłużyć się metodą Simplex, o ile będziemy znali początkową dopuszczalna macierzą bazową równania (2.3).
Łatwo jest pokazać, że
Macierz jednostkowa o wymiarach \(p\times p\) :
- jest macierzą bazową równania (2.3),
- wektor jest dopuszczalny ponieważ w postaci kanonicznej \(b\geq 0\), zatem jest ona dopuszczalną macierzą bazową dla zadania PLin_P.
Zadanie PLin_P zostało tak sformułowane, aby jego rozwiązanie miało potrzebne własności. Można, zatem pokazać, że
\(f(x ̃,v ̃)>0⇒DK=∅⇒D=∅,\)
co oznacza, że zadanie pomocnicze i wyjściowe zadanie PLin nie mają rozwiązania;
\(f(x ̃,v ̃)=∑_{j=1}^pv ̃_j=[0\,⋮\,⋯\,⋮\,0\,⋮\,1\,⋮\,⋯\,⋮\,1]\begin{bmatrix}x ̃
\\v ̃
\end{bmatrix}=0⇒(x ̃\, \mathrm{ jest\, wierzchołkiem\, zbioru}\,DK \wedge v ̃=0 )\).
Jeżeli wiemy, że \( f(x ̃,v ̃)=0\), co oznacza że zadanie PLin_P ma rozwiązanie, to można pokazać, że dopuszczalna macierz bazowa ma postać:
\(\mathbf{B}=[A_{k∈K} ], \) gdzie K to zbiór indeksów niezerowych składowych wektora x ̃,(liczba elementów tego zbioru jest oczywiście równa p), a \(A_k\) to kolejne kolumny macierzy \(A,A=[A_1⋮...⋮A_k⋮...⋮A_n].\) (2.4)
Na podstawie przeprowadzonych powyżej rozważań możemy teraz przedstawić ogólny schemat znajdowania rozwiązania zadania liniowego optymalizacji (zadania programowania liniowego).
Jest to schemat dwufazowy:
- z fazą wstępną (faza I), w której szuka się punktu wierzchołkowego, albo stwierdza się, że układ ograniczeń jest sprzeczny, a następnie
- z fazą zasadniczą (faza II) kończącą się znalezieniem rozwiązania.
Faza I
– Przekształcamy zadanie wyjściowe do postaci kanonicznej.
– Formułujemy i rozwiązujemy metodą Simplex zadanie pomocnicze PLin_P otrzymując dopuszczalny wierzchołek i związaną z nim dopuszczalną macierz bazową albo przekonujemy się ze zbiór dopuszczalny jest pusty (na Rys. 2.3 faza ta została zaznaczona szarą strzałą).
Faza II
– Metodą Simplex rozwiązujemy zadanie w postaci kanonicznej startując z wyznaczonej dopuszczalnej macierzy bazowej. W skończonej liczbie kroków albo stwierdzamy, że zadanie nie ma rozwiązania (funkcja na zbiorze dopuszczalnym ucieka do minus nieskończoności), albo znajdujemy rozwiązanie (na rys. 2.3 faza ta została zaznaczona naprzemiennie strzałkami niebieskimi i czerwonymi).
– Znalezione rozwiązanie oczyszczamy z niepotrzebnych składowych i przenumerowujemy zmienne tak aby otrzymać rozwiązania zadania wyjściowego.
3. Algorytm metody Simplex – zapis algebraiczny
Przedstawimy teraz formalny zapis przedstawionego wyżej dwufazowego schematu rozwiązywania zadania programowania liniowego w postaci kanonicznej (zadania PLin_K).
\(c^T x→\mathrm{min}\)
p.o. \(Ax=b\)
\(x≥0.\)
Przypominamy, że \(b ≥ 0\), a elementy macierzy \(A\) oznaczmy \(A_{sr}\), tak że \(A=[A_{sr} ]_{s∈\overline{1,p},r∈\overline{1,n}}.\)
Podobnie: \(A_k\) to k-ta kolumna macierzy A, zatem \(A=[A_1\,⋮...⋮\,A_k\,⋮...⋮\,A_n]; \)
a dla wektorów \(c_k\) to k-ty element wektora c, tak że \(c=\begin{bmatrix}
c_1\\ \vdots
\\ c_n
\end{bmatrix}=[c_k]_{k\in \overline{1,n}}..\)
Algebraiczny opis algorytmu Simplex
Faza I (Obliczenia wstępne)
- Przekształć zadanie do postaci kanonicznej PLin_K.
- Utwórz zadanie pomocnicze PLin_P.
- Używając algorytmu opisanego w fazie II z macierzą jednostkową jako pierwszą macierzą bazową, rozwiąż zadanie PLin_P. Jeżeli wartość optymalna funkcji minimalizowanej w tym zadaniu jest większa od zera to ograniczenia są sprzeczne i stop. Jeżeli nie, przejdź do 4.
- Wyznacz zbiór indeksów początkowych zmiennych bazowych \(Ind\mathbf{B}^{(0)} = K\), gdzie zbiór K jest określony wzorem (2.4), oraz początkową macierz bazową \(\mathbf{B}^{(0)}=[A_{k∈Ind\mathbf{B}^{(0)} }]\). Przejdź do fazy II.
Faza II (Zasadnicza)
Informacja początkowa
Znamy zbiór indeksów początkowych zmiennych bazowych \(Ind\mathbf{B}^{(0)}=K⊂\overline{1,n}\)
0. Podstaw l: = 0.
1. Wylicz tzw. wektor cen zredukowanych: \(\mathbf{Δ}^{(l)}=[(\mathbf{B}^{(l)} )^{-1} A]^T \mathbf{c}_{Ind\mathbf{B}}^{(l)}-c∈\mathbb{R}^n,\)
gdzie: \(\mathbf{B}^{(l)}=[A_{k∈Ind\mathbf{B}^{(l)} }]=[A_r^{(l)} ]_{r∈\overline{1,p}}\) oraz \(\mathbf{c}_{Ind\mathbf{B}}^{(l)}=[c_k ]_{k∈Ind\mathbf{B}^{(l)}}).\)
2. Sprawdź czy \(\mathbf{Δ}^{(l)}\leq 0\) ?
Jeżeli tak – znaleziono rozwiązanie, którego niezerowe elementy są równe: \([x_k]_{k \in Ind\mathbf{B}^{(l)}}=(\mathbf{B}^{(l)})^{-1}b\)
i stop. Jeżeli nie, przejdź do 3 Fazy II.
3. (Wybór indeksu kolumny wprowadzanej do bazy) Wyznacz \( r ̂= \mathrm{argmax}_{k∈\overline{1,n}}\mathbf{Δ}_k^{(l)} .\)
4. (Sprawdzenie warunku braku rozwiązania) Sprawdź czy \((\mathbf{B}^{(l)})^{-1} A_{r ̂ }=A_{r ̂}^{(l)} ≤0 \) ?
Jeżeli tak – to zadanie nie ma rozwiązania (jest nieograniczone) i stop. Gdy nie, przejdź do 5 Fazy II.
5. (Wybór indeksu kolumny usuwanej z bazy)
\(s ̂=\mathrm{argmin}_{s∈S^{(l)} (r ̂)} \dfrac{<strong><strong>((<strong>\mathbf{B}^{(l)})^{-1}b)_s}{(A_{sr ̂}^{(l)} }\) ,
gdzie \(S^{(l)} (r ̂)=s∈Ind\mathbf{B}^{(l)} |A_(sr ̂)^{(l)}>0,\) a \(A_{sr ̂}^{(l)}\) to s-ty element kolumny (wektora)\(A_{r ̂}^{(l)}\).
6. Wylicz nową bazę
\(B^{(l+1)}=B^{(l)}+(A_{r ̂ }-A_{s ̂ }([0⋮...⋮0⋮1⋮0⋮...⋮0]),\) ,
podstaw \(l:= l+1\) i przejdź do 1 Fazy II.
Omówimy krótko kroki kluczowej II fazy algorytmu.
- Poszukiwanie największego (krok 3) albo najmniejszego (krok 5) elementu to przeglądanie tablicy o n albo nie więcej niż \(p < n\) elementach, nie jest więc zadaniem skomplikowanym.
- W kroku 5 może się zdarzyć tzw. degeneracja. Algorytmowi to nie przeszkodzi w wykonywaniu dalszych kroków, ale gdy degeneracja nastąpiła w iteracji l-tej, to w iteracji \(l+2\) może nastąpić zerowe zmalenie funkcji celu. Stwarza to potencjalną możliwość powrotu algorytmy do tego samego wierzchołka po liczbie iteracji większej od pięciu (możliwość wystąpienia cyklu – pętlenia). Określono sposoby zabezpieczenia się przed tym zjawiskiem, por. wspomniany podręcznik A. Stachurskiego (podrozdział 2.3), i z praktycznego punktu widzenia można go pominąć.
- Krok 6 to przejście do nowego wierzchołka, przy czym wybór kolumny wprowadzonej do bazy w kroku 3 daje największe możliwe zmalenie funkcji celu.
- Główne problemy implementacyjne związane są z szybkością i dokładnością tego algorytmu. Najwięcej kłopotów jest w nim z opracowaniem procedur, które nie odwracając wprost macierzy będą dawały takie same wyniki jak odwracanie macierzy bazowych.
W ciągu tych lat, które upłynęły od pierwszej publikacji G.B. Dantziga poprawiano i ulepszano metodę Simplex w różnych kierunkach, tak że współczesne implementacje tej metody potrafią znaleźć w rozsądnym czasie rozwiązania zadań o setkach tysięcy zmiennych i kilkudziesięciu tysiącach ograniczeń (praktyczne zadania o takich wymiarach mają dużo zer w macierzy A, macierz A jest rzadka, zatem przy zastosowaniu odpowiednich metod można takie zadania „zmieścić” w pamięci komputerów).
4. Algorytm lepszy niż Simplex?
Prawie, że od początku powstania algorytmu Simplex starano się wymyślać algorytmy lepsze, najczęściej rozumiejąc pod tym pojęciem szybsze. Uzasadnienie przeświadczenia, że można skonstruować algorytm szybszy jest oczywiste.
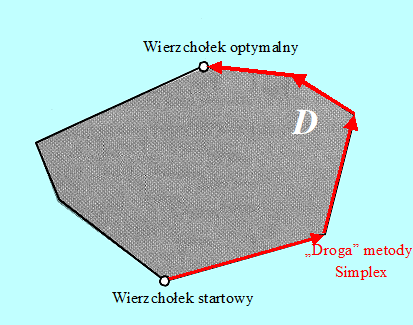
Algorytm Simplex „odwiedzając” kolejne wierzchołki idzie do celu długą drogą, co mu zajmuje wiele czasu. Najprostszy pomysł – to skrócenie drogi. Trzeba zarzucić przeglądanie wierzchołków i z dopuszczalnego punktu startowego poruszając się wewnątrz zbioru dopuszczalnego dotrzeć szybko do wierzchołka optymalnego jak na Rys. 2.5.
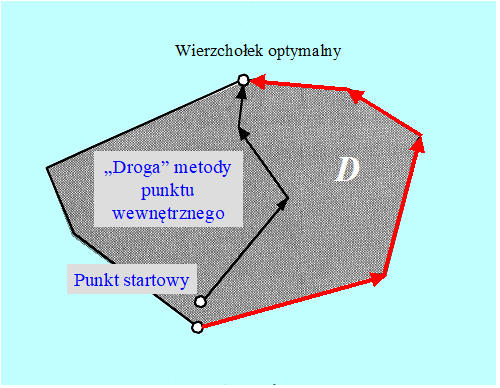
Poruszanie się wewnątrz zbioru dopuszczalnego dało nazwę algorytmom tej grupy – metody punktu wewnętrznego (interior point methods). Pierwszym efektywnym algorytmem tego typu był przedstawiony w 1984 r. przez N. Karmarkara algorytm, który teraz powszechnie nazywa się jego imieniem. Od tego czasu opublikowano wiele różnych algorytmów szukających rozwiązania zdania programowania liniowego wewnątrz zbioru dopuszczalnego. Najnowsze implementacje pozwalają rozwiązywać zadania prawie tak samo duże jak komercyjne pakiety oparte na metodzie Simplex, ale wciąż te metody cieszą się większym zaufaniem u naukowców niż menedżerów muszących rozwiązywać ogromne zadania optymalizacji. Wprowadzenie do problematyki związanej z metodami punktu wewnętrznego zainteresowany Czytelnik znajdzie we wspomnianym podręczniku A. Stachurskiego, podrozdział 4.8.
5. Zakończenie
Podsumujmy rozważania tego krótkiego rozdziału.
- Nie da się stworzyć dobrego algorytmu rozwiązywania zadań optymalizacji bez inspiracji głębokich rozważań teoretycznych (por. wzory w algebraicznym opisie algorytmu Simplex).
- Kłopotliwym zagadnieniem przy konstruowaniu algorytmów mających znajdować rozwiązanie zadania z ograniczeniami jest fakt, że często trzeba je wzbogacać o sposób znajdowania początkowego rozwiązania dopuszczalnego, co prowadzi do algorytmu dwufazowego.
- Budując algorytm, który ma mieć praktyczne zastosowanie, trzeba pamiętać o tym, że powinien on wiarygodnie przedstawiać właściwą informację o sprzecznych ograniczeniach (zasygnalizować, że zbiór dopuszczalny jest pusty), albo że rozwiązanie ucieka do nieskończoności.