Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | 2. Obiekty i klasy |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | poniedziałek, 6 października 2025, 07:24 |
1. Programowanie obiektowe
Skoro mówimy o programowaniu zorientowanym obiektowo, potrzebna jest jakaś definicja obiektu. Zamieszczę Wam jedną:
Straszne .... to może inna?
Ładniejsza? Może ... a która z nich jest prawidłowa?
Obie. W zależności od punktu widzenia klasy i obiekty możemy traktować zarówno jak elementy inżynierii oprogramowania (definicja 1) jak i jako elementy języka programowania (definicja 2). W poprzednim rozdziale raczej niewiele zajmowaliśmy się inżynierią, i tłumaczeniem zasad działania pewnych konstrukcji językowych. Teraz to się zmieni. Postaram się przedstawić Wam w miarę kompletne wprowadzenie do programowania obiektowego i zorientowanego obiektowo.
Na początek chciałbym wyraźnie wprowadzić rozróżnienie pomiędzy dwoma określeniami uważanymi za fundamentalne przy programowaniu obiektowym.
1.1. Obiekty i klasy
Zacznijmy od tego, że w przypadku programowania obiektowego program składa się z obiektów, które wchodzą w interakcje, przesyłając sobie nawzajem komunikaty / wykonując pewne działania.
Na początek zwykle najłatwiej jest wyobrazić sobie obiekt jako żywą istotę. Obiekty mają coś, co wiedzą (atrybuty, pola), oraz coś, co mogą zrobić (zachowania lub operacje). Wartości atrybutów obiektu określają jego stan, poprzez wywoływanie zachowań obiekty przechodzą od stanu do stanu.
Tutaj warto byśmy na chwilę zatrzymali się przy terminologii. W programowaniu strukturalnym mówiliśmy zazwyczaj o zmiennych - jako o czymś, w czym można przechowywać wartość jakiegoś typu. W przypadku programowania obiektowego - sam obiekt jest zmienną złożoną. Natomiast zazwyczaj nie mówimy że składa się ze zmiennych - tylko używamy tu pojęcia pola lub (zamiennnie) atrybuty - czyli nazwaną część obiektu która może przechowywać wartości jakiegoś typu. W programowaniu strukturalnym mówiliśmy także o funkcjach. Jeśli funkcję powiążemy z obiektami określonego typu, i jeden z nich przypiszemy do niej jako kontekst wykonania - to nazwiemy ją metodą.
Klasy to "plany" obiektów. Klasa łączy atrybuty (pola) oraz zachowania (metody lub funkcje) w jedną odrębną jednostkę, opisuje ją syntaktycznie i definiuje zachowania. Z tego punktu widzenia obiekty są egzemplarzami (instancjami) klas.
Obiekt
Mówiąc bardziej formalnie, obiekt jest strukturą danych, występującą łącznie z operacjami dozwolonymi do wykonania na niej (do tej pory zajmowaliście się strukturami, definiowanymi przez struct które nie miały bezpośredniej łączności składniowej z dozwolonymi operacjami). Obiekt może być złożony, a więc może składać się z innych obiektów. Każdy obiekt ma przypisany typ, tj. wyrażenie językowe, które określa jego budowę (poprzez specyfikację pól) oraz ogranicza kontekst, w którym odwołanie do obiektu może być użyte w programie.
Obiekt może być powiązany z innymi obiektami związkami skojarzeniowymi, odpowiadającymi relacjom zachodzącym między odpowiednimi bytami w dziedzinie problemowej. Inaczej mówiąc – obiekty mogą wiedzieć o innych obiektach, korzystać z nich czy też zarządzać nimi (składać się z nich). Zazwyczaj dąży się do tego, by relacje między obiektami w kodzie programu odpowiadały naturalnym relacjom między obiektami w świecie rzeczywistym, np. pisząc symulator samochodu, i tworząc obiekt typu samochód i obiekt typu silnik, dbamy o to, by to samochód zawierał silnik.
Dodatkowo, sam obiekt można charakteryzować korzystając z następujących pojęć:
- Każdy obiekt ma stan – czyli komplet aktualnych wartości wszystkich jego pól. Stan obiektu zmienia się w czasie – bo można zmieniać wartości jego pól, można też modyfikować powiązania obiektu z innymi obiektami.
- Oprócz stanu – każdy obiekt jest charakteryzowany przez tożsamość, która odróżnia go od innych obiektów. W praktyce tożsamości odpowiada adres w pamięci w którym obiekt jest przechowywany, lecz z funkcjonalnego punktu widzenia tożsamość odróżnia nam obiekty identyczne (będące w tym samym stanie) – tak jak w przypadku jednojajowych bliźniaków – są identyczni, lecz każdy z nich jest inną osobą. Podobnie jest z obiektami – mogą mieć wszystkie wartości swoich atrybutów równe sobie, lecz nie być tym samym obiektem.
Klasa
Klasa to szablon obiektu - jest miejscem przechowywania tych własności grupy obiektów, które są niezmienne dla wszystkich członków grupy. W klasach zdefiniowane są ciała metod - bo metody są wspólne dla wszystkch obiektów. Zdefiniowane są także typy pól -bo wszystkie obiekty tej samej klasy mają takie same pola. Natomiast w klasach nie ma wartości pól - wartości są stanem przypisanym do konkretnego obiektu. Klasa też nie mia tożsamości w sensie takim jak ma ją obiekt - nie ma swojej reprezentacji jako zmienna w pamięci.
Dobrze zbudowana klasa jest starannie wydzieloną abstrakcją pochodzącą ze słownictwa dziedziny danego problemu lub rozwiązania. Zazwyczaj klasa powinna opisywać coś, co w pełni rozumiemy, i rzeczywiście pojawia się w opisie problemu, najczęściej jako rzeczownik. Klasa obejmuje pewien mały, dobrze określony zbiór zobowiązań, z których jest w stanie się w pełni wywiązać, doświadczeni programiści czasami twierdzą, że jeśli odpowiedzialności danej klasy nie da się zapisać na małej, żółtej karteczce – to znaczy że powinna być ona podzielona na mniejsze części. Mówiąc dalej językiem teorii informatyki – klasa zapewnia oddzielenie specyfikacji abstrakcji od jej implementacji. Jest zrozumiała i prosta, a przy tym rozszerzalna i dająca się łatwo dostosować do potrzeb (ech ... piękna idea ;) ).
To wszystko brzmi ciągle nieco abstrakcyjnie, więc może prosty przykład: Wyobraźcie sobie prostokąt:
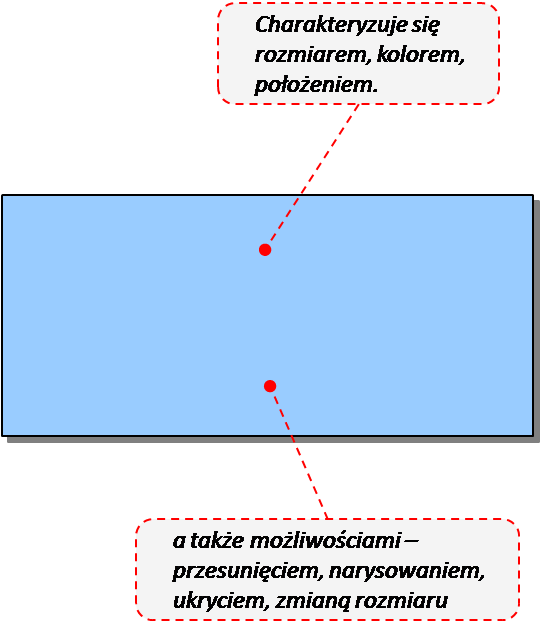
Prostokąt ma pola różnego typu logicznie powiązane ze sobą – rozmiar, kolor położenie. Powiązaniem logicznym jest to, że i rozmiar, i położenie opisują jeden konkretny prostokąt. W programie komputerowym prostokąt może również pewne czynności “wykonać” - narysować się, przesunąć, zmienić rozmiar. I to jest właśnie obiekt.
Jeśli natomiast weźmiemy pod uwagę wiele prostokątów:
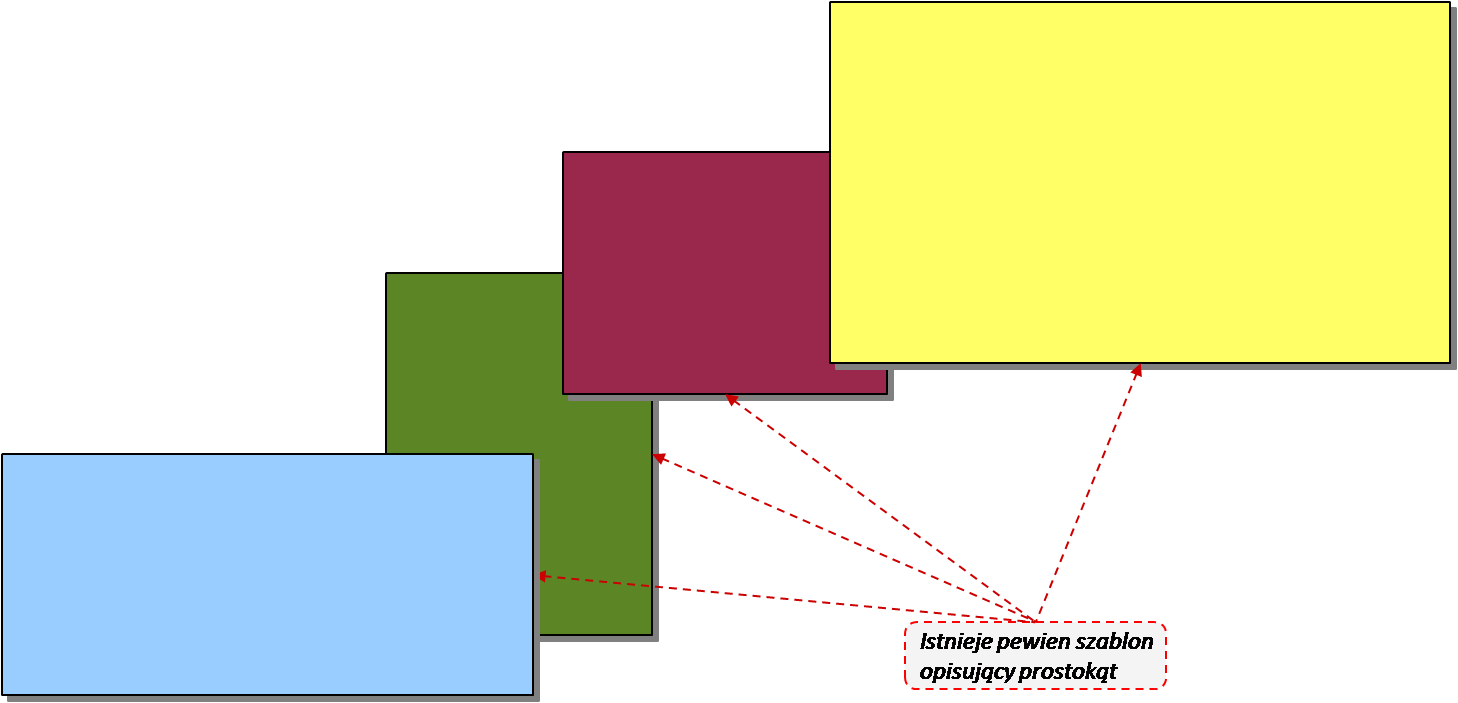
Możemy zauważyć, że każdy z nich ma kolor (inny co do wartości, lecz tego samego typu), każdy ma rozmiar (podobnie – typ ten sam, różne wartości), każdy możemy narysować (mechanizm jest ten sam, różni się jedynie kolor, pozycja gdzie jest rysowany, rozmiar, itp.). Czyli istnieje pewien szablon, pozbawiony tożsamości i stanu opis prostokąta, nie jednego konkretnego, lecz każdego możliwego prostokąta. I to jest klasa, w dodatku dobrze zdefiniowana. Reprezentuje byt z dziedziny problemu, i jest zrozumiała. Jej odpowiedzialność także da się streścić w jednym zdaniu – odpowiada za przechowywanie wszystkich danych oraz operacji pozwalających na narysowanie na ekranie prostokąta.
1.2. Deklaracje i definicje klas
W przypadku programowania obiektowego będziemy tworzyli własne typy, korzystając z udostępniania tylko niezbędnych informacji do korzystania z nich. W C++ definicja nowego typu to definicja klasy - a więc zarówno jej pól, jak i metod. O samych definicjach i deklaracjach czytaliście już w pierwszej części podręcznika. W przypadku klas jest podobnie. Deklaracja zawiera wszystkie informacje niezbędne do korzystania z obiektów danej klasy, definicja natomiast zawiera to, co jest niezbędne do wygenerowania kodu ją obsługującego. Tak więc deklaracja będzie informacją o tym, jakie klasa ma metody i pola, natomiast definicja - sprowadza się głównie do implementacji metod.
W przypadku C++ deklaracja klasy jest podobna do deklaracjistruktury, rozszerzając ją o metody. Przy czym możemy do tego celu wykorzystywać poznane już przez Was słowo kluczowe struct lub używać go zamiennie ze słowem class - różnica między nimi sprowadza się do domyślnego zakresu widoczności składowych klasy (wspomniałem, że struktura jest zdegenerowaną klasą w C++ ...). Jednak w programowaniu ważna jest także ekspresja zamiarów programisty - więc, jak chcecie tworzyć klasy, używajcie słowa kluczowego class.
Na początek prosty przykład: załóżmy, że chcemy zdefiniować klasę będącą bardzo prostą komputerową reprezentację diody. Przyjmijmy, że dioda, traktowana jako ogólne pojęcie, będzie określona przez dwie właściwości (dwa pola):
- ma jakiś kolor (ponieważ będziemy opierali się na programie z interfejsem tekstowym, kolor będzie reprezentowany jako napis, czyli pole typu string)
- jest zapalona albo nie (pole typu bool)
Na polach tych chcemy móc wykonywać następujące operacje (metody):
- zapalenie diody
- zgaszenie diody
- obserwacja diody (jej stanu: czy świeci i w jakim kolorze).
Klasę opisującą pojęcie diody nazwiemy CDioda, i połączymy deklarację z definicją (podamy od razu kod metod w deklaracji klasy):
#include <iostream>
#include "cstdlib"
using namespace std;
/** Definicja typu obiektowego - klasy CDioda*/
class CDioda {
public:
/// kolor diody – pamiętany jako napis
string kolor;
/** stan diody – pamiętany jako zmienna logiczna. Wartość
true odpowiada zapalonej diodzie */
bool zapalona;
/** Metoda pozwalająca na zmianę stanu diody – włączająca ją */
void zapal() {
zapalona = true;
}
/** Metoda pozwalająca na zmianę stanu diody – wyłączająca ją */
void zgas() {
zapalona = false;
}
/** Metoda wyświetlająca stan diody */
void pokaz() {
if (zapalona)
cout << "Swieci w kolorze " << kolor << endl;
else
cout << "Nie swieci\n";
}
};
// przykładowy program korzystający z klasy CDioda
int main(int argc, char *argv[])
{
cout << "Diody ..." << endl;
// utworzenie dwóch obiektów typu CDdioda, o nazwach d1 i d2
CDioda d1, d2;
// ustawienie wartości ich pól
d1.kolor = "zielony";
d2.kolor = "czerwony";
d1.zapalona = false;
d2.zapalona = false;
// główna pętla progamu - będzie prosić użytkownika
// o podanie działania - i po każdym poleceniu wyświetlać
// stan diod
char zn;
do {
cout << "Stan diod:\n";
d1.pokaz();
d2.pokaz();
cout << "\nCo chcesz zrobic?\n1 - zapal diode 1\n";
cout << "2 - zgas diode 1\n";
cout << "3 - zapal diode 2\n";
cout << "4 - zgas diode 2\n";
cout << "0 - zakoncz program\n";
cin >> zn;
switch (zn) {
case '1' : d1.zapal(); break;
case '2' : d1.zgas(); break;
case '3' : d2.zapal(); break;
case '4' : d2.zgas(); break;
};
} while (zn != '0');
return 0;
}
</iostream>No tak ... uważny czytelnik może stwierdzić - tyle pisania, tyle teorii, tyle hałasu, a jedyny zysk to fakt, że zamiast pisać pokaz(d1) piszemy d1.pokaz(). I będzie miał rację - jak na razie ...
Tymczasem przyjrzyjcie się pierwszemu zaprojektowanemu w tym podręczniku typowi - jest to typ konkretny:
Składnia
Przykład podany przed chwilą jest prawidłowy, lecz nie do końca elegancki. Prawidłowy – czyli zgodny ze składnią, którą można podać następująco:
class nazwa_klasy
{
// część publiczna
public:
// pola różnych typów
typ_pola nazwa_pola, ...nazwa_pola;
...
// metody (z parametrami lub bez) operujące na tych polach
typ_zwracany nazwa_metody(lista_parametrów);
...
// znowu mogą być inne pola
typ_pola nazwa_pola, ...nazwa_pola;
...
// i inne metody
typ_zwracany nazwa_metody(lista_parametrów);
// metody z definicją:
typ_zwracany nazwa_metody(lista_parametrów) {
// instrukcje (ciało) metody;
}
// i tak dalej...
// część chroniona
protected:
// to samo co w public
...
// część prywatna
private:
// to samo co w public
...
}; // koniec deklaracji
...
//definicje metod:
typ_zwracany nazwa_klasy::nazwa_metody(lista_parametrów) {
...
};
W C++, mimo że możliwa jest jednoczesna definicja i deklaracja klasy - zwykle postępuje się inaczej. Każdą klasę rozbija się na dwa pliki:
- plik z deklaracją klasy – czyli to, co jest zamieszczone od słówka kluczowego class aż do końcowego nawiasu klamrowego. Deklaracja informuje kompilator i korzystających z niej, jakie klasa będzie miała pola i metody, i umożliwia po pierwsze – sprawdzenie składniowe wszelkich odwołań do klasy i jej instancji, a po drugie – obliczenie rozmiaru pamięci na stosie niezbędnej do zapamiętania obiektu będącego instancją klasy (co nie musi być całkowitą pamięcią wymaganą przez instancję klasy - klasa może alokować pamięć na stosie).
- plik definicji zawierający implementację jej metod oraz definicje pól statycznych.
Klasę deklaruje się w pliku nagłówka (*.h), natomiast definicje metod wchodzących w jej skład umieszcza w implementacji (*.cpp).
Implementacje (definicje) kolejnych metod tworzą tzw. wnętrze obiektu, i należą w całości do przestrzeni nazw danej klasy. W implementacji metody konieczne jest więc zastosowanie desygnatora (oznacznika), określającego, do jakiej klasy należy dana metoda. Za desygnatorem umieszcza się podwójny dwukropek, a dopiero po nim nazwę metody. Pisząc ciało (treść) funkcji będącej metodą jakiejś klasy, możemy odwoływać się do jej pól bezpośrednio, nie podając nazwy klasy, do której dane pole należy - wewnątrz klasy wszystkie pola są znane i bezpośrednio dostępne (to tak jak my - na polecenie "rusz swoją ręką" - wiemy, która ręka jest nasza). Inaczej mówiąc - wewnątrz metody wszystkie pola obiektu danej klasy można traktować jak zdefiniowane zmienne lokalne.
To może klasa z przykładu wprowadzającego, tym razem rozbita już na poszczególne pliki. Zaczniemy od nagłówka:
#ifndef cdiodaH
#define cdiodaH
#include "string"
using namespace std;
/** Deklaracja klasy Cdioda, będącej reprezentacją eletronicznej diody
w przykładowych programach. */
class CDioda {
public:
/// pole pamiętające stan diody
bool zapalona;
/// pole zawierające kolor diody
string kolor;
/// informacja, że dioda ma metodę zapal – deklaracja metody
void zapal();
/// informacja, że dioda ma metodę zgas
void zgas();
/// informacja, że dioda ma metodę pokaz
void pokaz();
};
#endif
I następnie definicja metod klasy (przykładowe wykorzystanie sobie darujemy – niczym się nie różni od kodu wykorzystanego w programie wprowadzającym):
#include "iostream"
/// dołączenie nagłówka, zawierającego deklarację klasy
#include "cdioda.h"
using namespace std;
// definicje metod
void CDioda::zapal() {
zapalona = true;
}
void CDioda::zgas() {
zapalona = false;
}
void CDioda::pokaz() {
if (zapalona)
cout << "Swieci w kolorze " << kolor << endl;
else
cout << "Nie swieci\n";
}
Teraz wreszcie mamy klasę zakodowaną zgodnie ze wszystkimi zasadami składniowymi .... choć nie na wiele przydatną ;> No i nie do końca elegancją - nasza klasa ma wszystko na wierzchu - czyli cechuje się nadmiernym ekshibicjonizmem ... Pora przejść do hermetyzacji danych.
1.3. Ochrona danych w klasach
Najczęściej do korzystania z obiektów nie potrzebujemy głębokiej wiedzy i wszystkich tajników ich implementacji – by jeździć samochodem nie muszę znać i rozumieć procesu spalania paliwa w cylindrach, zasad działania skrzyni biegów czy też nie muszę wiedzieć z ilu kół zębatych wspomniana skrzynia jest zbudowana. Popatrzcie na klasę CDioda – co prawda ciężko w tym przypadku mówić o jakichkolwiek tajnikach implementacji, lecz w praktyce do jej wykorzystania wystarczy nam wiedza, jak wywołać trzy metody. Wartości pól nie musimy znać, co więcej – nawet nie musimy wiedzieć że jakieś pola istnieją. Ponoć obciążanie sobie głowy niepotrzebną wiedzą jest niezdrowe – więc po co mamy wiedzieć, jak działa obiekt danej klasy, skoro wystarczy nam wiedzieć jak z niego skorzystać?
Mówiąc bardziej poważnie – ochrona danych to nie tylko wygoda, to także technika, która pozwala nam tak przygotować klasę, by żaden obiekt będący jej instancją w żadnym momencie swojego życia nie znalazł się w stanie niedozwolonym. Przykładowo – jeśli twierdzimy, że czarny kot nie ma prawa bytu, możemy zdefiniować klasę kota, w której będzie pole kolor. I dla tego pola wartość „czarny” będzie niedozwolona, a mechanizmy klasy zapewnią, że nigdy żaden jej użytkownik nie będzie mógł przypisać wartości „czarny” polu kolor.
Fachowo takie mechanizmy nazywa się ochroną pól lub metod. Ochrona oznacza, że autor danej klasy ma możliwość zdefiniowania obszaru widoczności jej pól, i idąc dalej tym tropem – zdefiniować możliwe wartości pola, a poprzez to – zdefiniować możliwe stany obiektu. Standard programowania obiektowego (o ile można o czymś takim mówić) przewiduje występowanie trzech typów ochrony zmiennych:
- Pola i metody mogą być publiczne (ang. public), co oznacza, że są one dostępne z dowolnego miejsca w programie – nie są chronione. W C++ jest to zachowanie domyślne dla klasy definiowanej przy pomocy słowa kluczowego struct.
- Jeśli chcemy uniemożliwić jakikolwiek dostęp do zmiennej lub metody spoza implementacji metod wchodzących w jej skład, deklarujemy ją jako prywatną (ang. private). W C++ jest to zachowanie domyślnie dla klasy definiowanej przy pomocy słowa kluczowego class (jeśli nie zadeklarujemy inaczej, wszystkie pola i metody będą prywatne).
- Trzecim typem są pola i metody chronione (ang. protected) - dostępne podczas implementacji danego obiektu i wszystkich obiektów pochodnych, dla których zastosowano dziedziczenie publiczne lub chronione.
Do sekcji chronionej wrócimy nieco później, na razie zajmiemy się dokładniejszą interpretacją tego, co oznacza część publiczna i część prywatna. Odpuśćmy sobie na chwilę naszą diodę, i zajmijmy się innym przykładem. Napiszemy klasę wektor, która będzie służyła do przechowywania pewnej zadanej ilości liczb. Dla większej jasności kodu - nie będziemy go rozbijali na deklarację i definicję, dodatkowo definiując w nim własną postać operatora indeksowania - o czym dokładniej napiszę w dalszej części podręcznika.
#include "iostream"
class Wektor {
public:
int rozmiar{0};
double* dane{nullptr};
double ustawRozmiar(int r) {
dane = new double[r];
rozmiar=r;
};
void drukuj() {
std::cout << "[";
if (rozmiar>0) {
std::cout << dane[0];
}
for (int i=0; i<rozmiar; i++) {
std::cout << " " << dane[i];
}
std::cout << "]\n";
}
double sumuj() {
double rval{0};
for (int i=0; i<rozmiar; i++) {
rval += dane[i];
}
return rval;
}
double& operator[](int idx) {
return dane[idx];
}
};
int main() {
Wektor w1, w2;
w1.ustawRozmiar(10);
for (int i{0}; i<10; i++) {
w1[i] = 10.0* rand()/RAND_MAX;
}
w1.drukuj();
std::cout << "Średnia: " << w1.sumuj()/10.0 << "\n";
w1.rozmiar = 100; // problem - drukuj przestanie działać
w2.rozmiar = 10; // problem - w2 jest niespójne, nie ma przyznanej pamięci
return 0;
}
Jeśli dostęp do pól nie jest blokowany - to od dobrej woli korzystającego z naszej klasy zależy, czy wykona on prawidłową inicjalizację, oraz - czy nie zmieni wartości pól na niepasujące do siebie (pomijając już ten szczegół, iż prosto mógłby podać wartość ujemną w rozmiarze, i nikt by nie protestował).
W praktyce powinniście unikać jak ognia eksponowania stanu klasy w jej części publicznej bez ochrony.
Błędów z powyższego kodu popełnicie jeśli przeniesiecie pola rozmiar i dane do części chronionej. A dokładniej - możecie je popełnić, ale kompilator to wychwyci i zgłosi błąd kompilacji.
#include "iostream"
class Wektor {
public:
double ustawRozmiar(int r) {
dane = new double[r];
rozmiar=r;
};
void drukuj() {
std::cout << "[";
if (rozmiar>0) {
std::cout << dane[0];
}
for (int i=0; i<rozmiar; i++) {
std::cout << " " << dane[i];
}
std::cout << "]\n";
}
double sumuj() {
double rval{0};
for (int i=0; i<rozmiar; i++) {
rval += dane[i];
}
return rval;
}
double& operator[](int idx) {
return dane[idx];
}
private:
int rozmiar{0};
double* dane{nullptr};
};
int main() {
Wektor w1, w2;
w1.ustawRozmiar(10);
for (int i{0}; i<10; i++) {
w1[i] = 10.0* rand()/RAND_MAX;
}
w1.drukuj();
std::cout << "Średnia: " << w1.sumuj()/10.0 << "\n";
// teraz poniższe linie powodują błąd kompilacji.
w1.rozmiar = 100; // problem - drukuj przestanie działać
w2.rozmiar = 10; // problem - w2 jest niespójne, nie ma przyznanej pamięci
return 0;
}
Teraz moja klasa wektora jest odrobinę lepsza. Ciągle jej daleko do ideału - m. inn. brakuje domyślnej alokacji i zwalniania zasobów, przenoszenia i kopiowania, zmiany rozmiaru bez utraty zawartości, itp ... ale pamiętajcie - to tylko ilustracja. W praktyce pisanie własnych klas wektorów nie ma sensu. Ich implementacje w bibliotece standardowej, czy w dodatkowych bibliotekach typu Qt są dopracowane do perfekcji, uwzględniając zarówno wydajność, jak i bezpieczeństwo stosowania.
Ochrona danych między obiektami tej samej klasy
Po tym co przeczytaliście wyżej niektórzy dochodzą do wniosku, że część prywatna jest częścią prywatną obiektu. Nie jest to prawda. Ochrona dotyczy klasy - a nie jej instancji, tak więc metody tej klasy mogą spokojnie odwoływać się do prywatnych części innych obiektów tej samej klasy - a nie tylko tego, dla którego metoda została wywołana. Ilustruje to poniższy przykład:
#include "iostream"
class Wektor {
public:
double ustawRozmiar(int r);
void drukuj();
double sumuj();
double& operator[](int idx);
void kopiuj(const Wektor& vs) {
// można odwołać się do pól prywatnych vs
dane = new double[vs.rozmiar];
rozmiar = vs.rozmiar;
for (int i=0; i!=rozmiar; ++i)
dane[i]=vs.dane[i];
}
private:
int rozmiar{0};
double* dane{nullptr};
};
1.4. Deklaracje pól
Pola są właściwą treścią każdego obiektu klasy, to one stanowią jego reprezentację w pamięci operacyjnej. Pod tym względem nie różnią się niczym od znanych ci już pól w strukturach i są po prostu zwykłymi zmiennymi, zgrupowanymi w jedną, kompleksową całość. Jako miejsce na przechowywanie wszelkiego rodzaju danych, pola mają kluczowe znaczenie dla obiektów i dlatego powinny być chronione przez niepowołanym dostępem z zewnątrz. Przyjęło się więc, że w zasadzie wszystkie pola w klasie powinny być prywatne i chronione. Wspominałem o tym już wcześniej, teraz przypominam, tym bardziej że to będzie sprawdzane w Waszych projektach ;>
By jakoś odróżnić pola od zmiennych lokalnych, stosuje się różne konwencje nazywania jednych i drugich. Konwencji jest wiele – jedni za konwencją stosowaną w Qt wszystkie pola w klasie nazywają zaczynając od litery m_, inni zaczynają nazwę pola dużą literą a zmiennej lokalnej małą, jeszcze inni stosują podkreślenie na końcu nazwy... wybrać można co chcecie – ważne by konsekwentnie trzymać się swojego wyboru.
Skoro pola nie są dostępne spoza klasy - to dostęp do danych w nich zawartych musi się odbywać za pomocą dedykowanych metod. Rozwiązanie to ma wiele rozlicznych zalet: pozwala chociażby na tworzenie pól, które można jedynie odczytywać, daje sposobność wykrywania niedozwolonych wartości (np. indeksów przekraczających rozmiary tablic itp.) czy też podejmowania dodatkowych akcji podczas operacji zmiany wartości pola (zmiany stanu obiektu). Takie funkcje zwyczajowo nazywa się setterami / getterami, i też oznacza w jakiś sposób. Mi osobiście najbardziej odpowiada konwencja nazwania funkcji zwracającej tak samo jak brzmi podstawowa nazwa pola, natomiast metody ustawiającej znów nazwą pola, lecz tym razem poprzedzonej przedrostkiem set.
Ponieważ jednak dla większej czytelności przekazu w podręczniku posługuję się polskimi nazwami klas, metod, zmiennych, itp - to przedrostek także będzie polski - zmień.
Przykład:
class CMoja {
public:
double wartosc() { return m_wartosc; }
void zmienWartosc(double _v) { m_wartosc = _v; }
private:
double m_wartosc;
};Domyślnie wartości pól nie są inicjowane - podobnie jak zmienne lokalne. Natomiast zawsze istnieje możliwość inicjacji pól - albo w konstruktorze, albo bezpośrednio w deklaracji klasy, analogicznie jak to ma miejsce w przypadku zmiennych.
Pola statyczne
Omawiane dotychczas pola są ściśle powiązane z konkretnym obiektem, przy czym dla każdego z nich mogą mieć różną wartość. Tak jak to wspominaliśmy we wstępie – pola reprezentują stan obiektu. Jak nie ma obiektu – nie ma i pól. Pamięć na pola jest przyznawana w momencie tworzenia obiektu, i zwalniana w momencie gdy obiekt jest kasowany.
Wszystkie powyższe uwagi są prawdziwe, z jednym wyjątkiem – pól statycznych. W przeciwieństwie do zwykłych pól – pola statyczne nie są powiązane z jakimkolwiek obiektem będącym instancją klasy. Pola statyczne istnieją od momentu uruchomienia programu, i są kasowane dopiero po jego zakończeniu. Ich czas życia jest analogiczny do czasu życia zmiennych globalnych. Tak naprawdę pola statyczne to są zmienne globalne – specyficzne, bo zdefiniowane w przestrzeni nazw jakiejś klasy.
Zasady składniowe ich definiowania i deklarowania są proste – wystarczy w definicji klasy dodać dodatkowe słowo kluczowe static przed polem które ma być statyczne, i następnie dodatkowo zdefiniować gdzieś instancję tego pola. Przy czym owe nieostre gdzieś oznacza poza nagłówkiem (bo inaczej mielibyśmy do czynienia z redefinicją pola przy każdym dołączeniu go do następnej jednostki kompilacji - pliku źródłowego), w dowolnym module włączonym do aplikacji. Zazwyczaj robi się to w pliku implementacji klasy. Przykład tworzenia pola statycznego jest zamieszczony poniżej:
#include "iostream"
using namespace std;
/** Przykładowa klasa wykorzystująca pola statyczne */
class CStatMoja {
public:
/** metoda drukująca */
void drukujInfo() { cout << "Pole: " << m_statPole << "\n"; }
static int m_statPole;
};
/// dodatkowa definicja zmiennej - niezbędna w przypadku pól statycznych
int CStatMoja::m_statPole = 0;
// przykład korzystania
int main(int argc, char **argv) {
CStatMoja o1, o2;
// wydrukujmy zawartość pola statycznego korzystając z obu obiektów
o1.drukujInfo();
o2.drukujInfo();
// zmieńmy wartość pola - odwołując się do niego przez nazwę klasy
CStatMoja::m_statPole = 10;
// wydrukujmy zawartość pola statycznego korzystając z obu obiektów
o1.drukujInfo();
o2.drukujInfo();
// pole statyczne można zmieniać z dowolnego obiektu - i tak jest
// to jeden obszar w pamięci, więc jakiekolwiek zmiany będą widoczne
// zawsze tak samo
o1.m_statPole = 15;
o2.drukujInfo();
cout << CStatMoja::m_statPole << endl;
return 0;
}
Powyższy przykład ma zdefiniowane pole statyczne w części publicznej klasy. Jednakże nic nie stoi na przeszkodzie by to pole znalazło się w części prywatnej lub chronionej – wtedy stracilibyśmy jedynie możliwość dostępu do niego poprzez nazwę klasy:
#include "iostream"
using namespace std;
/** Przykładowa klasa wykorzystująca pola statyczne */
class CStatMoja {
public:
/** metoda drukująca */
void drukujInfo() { cout << "Pole: " << m_statPole << "\n"; }
/** metoda zmieniająca zawartość pola statycznego */
void zmienStatPole(int _v) {
m_statPole = _v;
}
private:
static int m_statPole;
};
/// dodatkowa definicja zmiennej - niezbędna w przypadku pól statycznych
int CStatMoja::m_statPole = 0;
// przykład korzystania
int main(int argc, char **argv) {
CStatMoja o1, o2;
// wydrukujmy zawartość pola statycznego korzystając z obu obiektów
o1.drukujInfo();
o2.drukujInfo();
// zmieńmy wartość pola - odwołując się do niego przez nazwę klasy
o1.zmienStatPole(10);
// wydrukujmy zawartość pola statycznego korzystając z obu obiektów
o1.drukujInfo();
o2.drukujInfo();
return 0;
}
Zasady dostępu do pól statycznych są także takie same jak dla zmiennej globalnej w jakiejś przestrzeni nazw. Pole statyczne istnieje zawsze – więc można się odwołać do niego nawet jeśli nie istnieje instancja obiektu danej klasy. Dodatkowo – można się do takich pól odwoływać bezpośrednio z metod należących do danej klasy – bo wtedy jesteśmy w jej przestrzeni nazw.
1.5. Metody
Metody nadają klasom charakter. Typowa struktura danych (rekord) - pochodząca jeszcze z dawnego programowania strukturalnego - dzięki metodom przekształca się z pasywnego worka łączącego pola różnego typu - w aktywny obiekt.
Z praktycznego punktu widzenia metody nie różnią się znacznie od standardowych funkcji. Podstawową różnicą jest fakt - iż definiowane są wewnątrz klasy. Przy czym należy rozróżniać deklarację metody od jej definicji (implementacji). Jak wspomniałem, zazwyczaj deklaracje metod zamieszcza się w deklaracji klasy (w pliku nagłówkowym), natomiast kod implementujący je (realne ciało funkcji) jest umieszczany w pliku implementacji.
Warto jednak wiedzieć, że umieszczenie kodu metod bezpośrednio w bloku definicji klasy (w nagłówku, po słowie class) sprawi, że kompilator potraktuje je jako metody inline, czyli rozwinięte w miejscu wywołania, i wstawi cały kod przy każdym odwołaniu się do nich. Dla krótkich, jednolinijkowych metod jest to korzystne rozwiązanie, przyspieszające działanie programu. Jednak dla dłuższych metod może prowadzić do znacznego zwiększenia rozmiaru pliku wykonywalnego.
Istnieje także szereg modyfikatorów deklaracji funkcji - zazwyczaj wprowadzanych po to, by zmodyfikować ich zachowanie. Na przykład, wybrane metody można uczynić stałymi. Taka metoda może modyfikować żadnego z pól klasy, do której należy – nie zmienia jej stanu. Może jedynie odczytywać wartości, dokonywać ich przekształceń i zwracać wyniki.
Dlaczego zdecydować się na taki zabieg? Z jednej strony - jest to wskazówka dla kompilatora pomagająca w optymalizacji kodu wynikowego. Ważniejszym zastosowaniem jest zabezpieczanie przed przypadkową modyfikacją stanu obiektu w metodzie, która nie miała tego dokonywać. Sztandarowym przykładem jest tutaj getter - metoda odczytująca wartość jednego z pól zazwyczaj nie powinna zmieniać ani odczytywanego, ani żadnego innego pola. Lecz prawdziwą przydatność odkryjecie w momencie przekazywania parametrow do funkcji. Jeśli parametrem jest obiekt jakiejś klasy, i jest przekazany jako stały (oznaczony słowem kluczowym const) - to można dla takiego obiektu wywołać tylko stałe metody.
Sugerowałbym Wam stosowanie metod z postfix-em const (stałych). Technicznie zapis zmieniający metodę w stałą - jest banalnie prosty: wystarczy tylko dodać za listą jej parametrów magiczne słówko const, np.:
class CInnaMoja {
private :
int m_pole;
public :
int pole() const { return m_pole; }
};
Metoda pole() (będąca de facto getterem dla pola m_pole) będzie tutaj słusznie metodą stałą – nie ma takiej możliwości i potrzeby by odczyt pola modyfikował stan obiektu.
Czasami także spotkacie dualizm - istnieje metoda oznaczona jako const, i druga, o takiej samej nazwie, bez const. Typowy przykład:
class CMoja {
private :
int m_wartosc;
public :
int& wartosc() { return m_wartosc; }
const int& wartosc() const { return m_wartosc; }
};
Na pierwszy rzut oka - wygląda dziwnie. Ale daje nam potem większą elastyczność korzystania z tej klasy:
void f1(const CMoja& v) {
auto val = v.wartosc(); // mogę odczytać wartość
val += 10; // tu będzie błąd - nie mogę jej zmienić
// przekazana była stała referencja, można korzystać tylko
// ze stałych metod.
};
void f2(CMoja& v) {
auto val = v.wartosc(); // mogę odczytać wartość
val += 10; // teraz już błędu nie będzie, stan obiektu zmieni się
};
Dzięki kontekstowi wywołania - prawidłowo też zadziała mechanizm przesłaniania nazw, pozwalający kompilatorowi na dobranie odpowiedniej wersji metody (z const lub bez).
Implementacja metod
Zajmijmy się teraz nieco dokładniej implementacją metod dostępnych w klasach. Operację tę rozpoczynamy od dołączenia do pliku z implementacją nagłówka z definicją naszej klasy, np.:
#include "klasa.h"
Potem możemy już przystąpić do pisania kodu metod. Postępujemy tutaj bardzo podobnie, jak w przypadku zwykłych, globalnych funkcji. Składnia metody wygląda analogicznie do składni funkcji, jedyną różnicą jest podanie przed nazwą metody nazwy klasy do której owa metoda należy. Wpisanie jej jest konieczne: po pierwsze mówi ona kompilatorowi, że ma do czynienia z metodą klasy, a nie zwyczajną funkcją; po drugie zaś pozwala bezbłędnie zidentyfikować macierzystą klasę danej metody. Między nazwą klasy a nazwą metody widoczny jest operator zasięgu ::
Zazwyczaj zamieszczamy w pliku implementacji kod kolejnych metod należących do tej samej klasy kolejno, jedną po drugiej - tak łatwiej zapanować nad wszystkimi metodami.
Pamiętajcie także, że w przypadku metod stałych - w implementacji należy także powtórzyć postfix const. Inaczej wystąpi błąd kompilacji.
Blok instrukcji metody tradycyjnie jest zawarty między nawiasami klamrowymi. Cóż ciekawego można o nim powiedzieć? Niewiele: nie różni się prawie wcale od analogicznych bloków zwykłych funkcji. W zasadzie jedyną istotną różnicą jest bezpośredni i niejawny dostęp do wszystkich pól i metod swojej klasy - tak, jakby były one jego zmiennymi albo funkcjami lokalnymi.
Magiczne słówko this
Z poziomu metody mamy dostęp do jeszcze jednej, bardzo ważnej i przydatnej informacji. Chodzi tutaj o obiekt, dla którego metoda jest wywoływana; mówiąc ściśle, o odwołanie się do jego tożsamości, bądź też wskaźnika do samego siebie. Ten wskaźnik uzyskujemy właśnie przy pomocy słowa this.
W niektórych językach rola this jest znacznie większa niż w C++ - to jedyna technika by odwołać się do własnych pól w klasie pisanej przykładowo w PHP. W C++ nie jest to niezbędne. this stosuje się w kilku przypadkach. Większość z nich poznacie później, natomiast teraz ... teraz przedstawię Wam dwa z nich. Pierwszy – to gdy w ciele metody zdefiniujemy zmienną lokalną nazywającą się tak samo jak pole klasy. Wtedy by do pola klasy się odwołać – potrzebujemy this. Druga – to ułatwienie działania systemowi podpowiadania wbudowanemu w nowoczesne środowiska programowania. Pisząc w ciele metody this-> ograniczamy przeszukiwanie potencjalnych symboli tylko do pól i metod danej klasy i klas nadrzędnych.
Metody statyczne
Wspomniałem wcześniej o istnieniu dodatkowego typu metod, nie omawianych do tej pory – to metody statyczne. W zasadzie nazywanie ich metodami jest działaniem nieco na wyrost - w sensie ich powiązania z konkretnym obiektem. Tak naprawdę – to nie jest metoda, lecz zwykła funkcja zdefiniowana w ciele klasy. Zwykła funkcja – czyli nie zna tożsamości obiektu ją wywołującego - nie ma w niej dostępu do tożsamości obiektu wywołującego, nie można korzystać z this. Natomiast jest zdefiniowana w ciele klasy - więc mamy pełen dostęp do wszystkich pól i metod - o ile znamy obiekt. Więc - metody statyczne mogą operować na wszystkich polach jej instancji, o ile mają przekazany taki obiekt jako parametr.
Przeładowanie (redefinicja) operatorów
W języku C++ duży nacisk położono na udostępnienie konstrukcji językowych, które pozwolą na tworzenie nowych typów danych tak, by korzystanie z nich było maksymalnie proste i podobne do typów wbudowanych. Dlatego też chcemy, by można było np. budować wyrażenia w których skład wchodzą typy użytkownika korzystając z tej samej składni, z której korzysta się budując wyrażenia ze zmiennych typów fundamentalnych.
Przykładowo - chcąc obliczyć sumę dwóch liczb rzeczywistych, wykorzystamy kod podobny do poniższego:
double x{10.5}, y{11.5};
auto z = x+y;
Co jeśli wprowadzimy własny typ - powiedzmy liczby zespolone - i dla nich będziemy chcieli napisać podobny kod?
class complex {
...
};
complex x{10.5, 2}, y{11.5, 3.1};
auto z = x+y;
Żeby to mogło zadziałać - musimy wprowadzić własną definicję operatora dodawania dla typu complex.
Przeciążanie operatorów w języku C++ stanowi ważny element programowania obiektowego, który umożliwia programistom dostosowanie zachowania wbudowanych operatorów do niestandardowych typów danych. Podstawowym założeniem tej techniki jest możliwość definiowania nowego działania dla operatorów w kontekście użytkownych klas, co pozwala na bardziej elastyczne i ekspresywne programowanie.
W języku C++, dla własnych typów danych (klas) operatory są w rzeczywistości funkcjami specjalnego rodzaju, które mogą być wywoływane za pomocą operatorów w wyrażeniach. Na przykład, operator dodawania `+` jest zamieniany przez kompilator na wywołanie metody lub funkcji o nazwie `operator+`. Przeciążanie operatorów polega więc na zdefiniowaniu tych funkcji lub metod w sposób odpowiedni dla naszych klas. Zacznijmy od podejścia funkcyjnego. Ogólnie - postać funkcji na operatora dwuargumentowego (takiego jak dodawanie) wygląda następująco:
typ operator@(typ arg1, typ arg2) {
// Kod realizujący działanie operatora @ dla typu danych typ
}
gdzie @ jest symbolem operatora (np +), a typ - nazwą klasy dla której definiujemy operator. Tak więc, by zmusić własny typ complex do posiadania operatora dodawania, wystarczy że zdefiniujemy następującą funkcję:
class complex {
...
};
complex operator+(const complex& x, const complex& y) {
/// tu powinien być kod dodwania
};
complex x{10.5, 2}, y{11.5, 3.1};
auto z = x+y;
Alternatywą jest zdefiniowanie operatora wewnątrz klasy:
class complex {
...
complex operator+(const complex& other) {
/// tu powinien być kod dodwania
}
};
complex x{10.5, 2}, y{11.5, 3.1};
auto z = x+y;
Zarówno jeden, jak i drugi sposób mają swoje zalety i wady, które należy wziąć pod uwagę w zależności od kontekstu i preferencji programisty. W przypadku stosowania funkcji - należy rozważyć stosowanie dodatkowej przestrzeni nazw w której definiujemy nasze klasy, by nnie zaśmiecać nadmiernie globalnej przestrzeni nazw. Stosowanie funkcji daje nam:
- Większą elastyczność: Funkcje mogą być zdefiniowane niezależnie od klas, po ich definicji, oraz bez dostępu do ich implementacji - co pozwala nam na stosowanie przeciążania różnych operatorów dla różnych, w tym nie naszych, typów danych.
- Symetrię: Funkcje operatorowe mogą być przeciążane dla różnych typów danych w sposób symetryczny, co ułatwia czytelność kodu.
Podejście takie nie jest jednak pozbawione wad, z których podstawową jest brak dostępu do prywatnych składowych klasy. Funkcje zewnętrzne do klasy nie mają dostępu do jej prywatnych składowych, co może prowadzić do konieczności wykorzystania metod publicznych, i w konsekwencji niższej wydajności kodu.
To co jest wadą w przypadku funkcji, staje się zaletą w przypadku metody. Metoda operatorowa ma dostęp do prywatnych składowych klasy, co ułatwia jej efektywną implementację. Ponadto podejście oparte na metodach sprawia, że operatory mogą być dziedziczone, i wirtualne - co w przypadku skomplikowanych hierarchii klas stanowi znaczący zysk.
W praktyce wybór między tymi dwoma podejściami zależy od kontekstu, preferencji programisty oraz struktury klasy i hierarchii dziedziczenia, oraz operatora. Wykorzystany przeze mnie wcześniej w klasie wektor operator indeksowania zazwyczaj jest implementowany jako metoda klasy. Z drugiej strony - operatory wejścia / wyjścia (<< i >>), czy dwuargumentowe operatory arytmetyczne - częściej implementowane są poza klasami.
Pamiętajcie - przeciążanie operatorów to nie bajer, a użyteczna technika. Dzięki niemu kod wykorzystujący Wasze typy staje się bardziej zwięzły i czytelny. Operatory mogą być używane w naturalny sposób, co ułatwia zrozumienie intencji kodu. Programiści mogą tworzyć niestandardowe typy danych, które zachowują się podobnie do wbudowanych typów. Przeciążanie operatorów pozwala na definiowanie spójnych interfejsów dla tych typów. Użycie przeciążonych operatorów jest zgodne z konwencjami języka C++, co sprawia, że kod jest łatwiejszy do zrozumienia dla innych programistów.
Uwagi dotyczące przeciążania operatorów
Nie wszystkie operatory mogą być przeciążone w dowolny sposób. Istnieją pewne ograniczenia dotyczące liczby argumentów oraz ich typów dla poszczególnych operatorów. Nie można zmieniać znaczenia operatorów które mają postać tekstową (np. sizeof), nie można zmieniać operatorów rzutowań (np. static_cast), oraz wybranych pozostałych operatorów:. (kropka) .* :: ?:
Przeciążanie operatorów powinno być używane w sposób spójny z semantyką danego operatora. Działanie przeciążonego operatora powinno być zgodne z intuicją programisty - dodawanie powinno zostać dodawaniem. Nie można też wprowadzić własnych operatorów, oraz zmienić działania istniejących dla typów fundamentalnych.
1.6. Tworzenie i usuwanie obiektów
Wiecie już, że obiekty mają swój stan - czyli wartości wszystkich pól w jakiejś chwili. Wiecie też, że zmiany tego stanu można kontrolować - przenosząc pola do części prywatnej klasy, oraz zapewniając odpowiednie metody. To pierwszy krok na drodze do uzyskania pewności, że dany obiekt nigdy nie będzie w nieprawidłowym stanie - ale tylko pierwszy krok. Do pełni szczęścia brakuje nam jeszcze zapewnienia, że po utworzeniu obiektu będzie on w prawidłowym stanie. Ale pełnia szczęścia jest w zasięgu ręki - w przypadku klas możemy mieć pełną kontrolę nad procesem tworzenia i niszczenia obiektów. Do tego celu wykorzystywane są specjalne metody - konstruktor (może mieć kilka wersji) oraz destruktor (zawsze jest dokładnie jeden).
Zanim je jednak omówimy - warto byście poznali jedną z technik (konwencji - programming idioms) - które dobrze jest stosować we własnym kodzie. Tą techniką jest RAII (Resource Acquisition is Initialization). Możecie ją potraktować albo jako wytyczne, albo coś w rodzaju wzorca projektowego, który mówi w skrócie:
przy czym zasoby mogą być różnego rodzaju - może to być uchwyt do pliku, gniazdo sieciowe, czy też - pamięć ręcznie alokowana na stosie. Wg tego idiomu przygotowano większość klas z biblioteki standardowej (np. strumienie wejścia / wyjścia plikowego). W przypadku prostych klas, kiedy zasobem zazwyczaj jest pamięć, RAII sprowadza się do takiego projektowania klasy, by alokacja pamięci odbywała się już w konstruktorze, a jej zwolnienie - w destruktorze. Dzięki temu, jeśli stosować będziecie typy konkretne - zminimalizujecie ryzyko wycieków pamięci.
Wsparcie dla RAII macie także w formie inteligentnych wskaźników - omówionych w module 3. Na razie jednak wróćmy do tworzenia obiektów.
Konstruktor to specyficzna funkcja składowa klasy, wywoływana zawsze podczas tworzenia należącego doń obiektu. Typowym zadaniem konstruktora jest zainicjowanie pól ich początkowymi wartościami, przydzielenie pamięci na stercie (alokowanej dynamicznie) wykorzystywanej przez obiekt, wykonanie inicjalizacji pól złożonych, czy przeprowadzenie czynności niezbędnych do dalszej pracy z obiektem (doprowadzenie go do prawidłowego stanu). Deklaracja konstruktora jest w C++ bardzo prosta. Deklaracja tej metody nie precyzuje żadnej wartości zwracanej (w ogóle nie oznacza się jej słowem kluczowym void), a jej nazwa odpowiada nazwie zawierającej ją klasy.
Konstruktor może nie przyjmować żadnych parametrów, może też mieć ich dowolną liczbę dowolnego rodzaju. Przykładowo – parametrami często są początkowe wartości przypisywane do pól. Co więcej, możliwe są różne postacie konstruktora (przeciążanie), co daje nam możliwość przygotowania różnych, specjalizowanych wersji konstruktorów, np. do wykonania kopii obiektu przekazanego jako wzorzec, do wykonania przeniesienia obiektu, czy zainicjowania obiektem innego typu. Poniżej mamy przykład kilku konstruktorów, oraz przykłady ich jawnego i niejawnego wywołania:
class CProstokat {
public:
/** Domyślny konstruktor. Nie przyjmuje jakichkolwiek parametrów */
CProstokat();
/** Typowy konstruktor kopiujący. Przyjmuje referencję do wzorca, który
ma zostać skopiowany */
CProstokat(const CProstokat& wzor);
// destruktor
~CProstokat();
...
};
CProstokat::CProstokat()
{
x1 = y1 = 0;
x2 = 1;
...
}
CProstokat::CProstokat(const CProstokat& wzor)
{
x1 = wzor.x1;
y1 = wzor.y1;
...
}
CProstokat::~CProstokat()
{
}
void f(CProstokat p) { ... }
// konstr. 1 przed uruchomieniem programu
CProstokat pr;
// konstr. 1 przed uruchomieniem programu
CProstokat pr2;
// konstr. 2
pr2 = pr;
// konstr. 1 po dojściu do tej linii
CProstokat *pr3 = new CProstokat();
// konstr. 2 po dojściu do tej linii
CProstokat *pr3 = new CProstokat(pr);
// wywołany zostanie destruktor
delete pr3
// konstr. 2 przed wejściem do f
f(pr);
// destruktor
// konstr. 2 po przed wejściem do f
f(*pr);
// destruktor
Obiekty typów definiowanych przez użytkownika zawsze są tworzone przy wykorzystaniu konstruktora. Nawet jeśli nie wywoła się go jawnie, w C++ zostanie wywołany w sposób niejawny (widzicie to w kodzie powyżej). I analogicznie - jeśli nie zostanie w klasie zdefiniowany żaden konstruktor, kompilator wygeneruje sam jego domyślną wersję - która nic nie robi. Podobnie wygeneruje trywialny płytki konstruktor kopiujący – który skopiuje zawartości wszystkich pól statycznych, lecz niestety – w przypadku tablic i zmiennych dynamicznych – wykona jedynie kopiowanie adresów, oraz trywialny konstruktor przenoszący.
Z wiadomych względów konstruktory czynimy prawie zawsze metodami publicznymi. Umieszczenie ich w sekcji private daje bowiem dość dziwny efekt: niemożliwe jest utworzenie z niej obiektu w zwykły sposób. Czasem to ma sens (przykład zobaczycie dalej) - ale zazwyczaj jednak chcemy mieć możliwość tworzenia obiektów.
OK, konstruktory mają zatem niebagatelną rolą, jaką jest powoływania do życia nowych obiektów. Doskonale jednak wiemy, że nic nie jest wieczne i nawet najdłużej działający program kiedyś będzie musiał być zakończony, a jego obiekty zniszczone. Tą niechlubną robotą zajmuje się kolejny, wyspecjalizowany rodzaj metod – destruktor. Destruktor jest metodą, wywoływaną podczas niszczenia obiektu zawierającej ją klasy.
W naszych przykładowych klasach destruktor nie miałby wiele do zrobienia - zgoła nic, ponieważ żaden z prezentowanych obiektów nie wykonywał czynności, po których należałoby sprzątać. Lecz w przypadku nietrywialnych obiektów - często sprzątanie jest potrzebne. Przykładowo - jeśli klasa alokowała pamięć na stercie - wypadałoby ją zwolnić. Jeśli otwierała pliki - warto je pozamykać, jeśli obsługiwała połączenie sieciowe - można się upewnić że zostało zamknięte. Jak widać - destruktor jest przydatny.
Destruktor tworzymy definiując metodę bez parametrów, nic nie zwracającą - podobnie jak konstruktor. Nazwą metody jest nazwa klasy poprzedzona znakiem tyldy ( ~ ).
W C++ nie istnieje formalny wymóg definicji konstruktorów czy destruktorów dla każdego typu obiektu. Często je jednak stosujemy.
W przypadku konstruktorów generowanych automatycznie - kompilator, nawet nieproszony - wygeneruje dla nas następujące wersje:
class A {
A(); /// pusty, domyślny konstruktor
A(const A& src); /// konstruktor kopiujący
A(A&& src); /// konstruktor przenoszący
A& operator=(const A& src); /// operator przypisania kopiujący
A& operator=(A&& src); /// operator przypisania przenoszący
Dodatkowo, wygenerowane automatycznie zostaną operatory przypisania w wersji kopiującej i przenoszącej. Możemy jawnie definiować, które z automatycznie generowanych konstruktorów powinny być dostępne, a których zabraniamy. Jeśli któregoś z nich nie chcecie - możecie dodać =delete po deklaracji. Jeśli chcecie którąś z wersji domyślnych jawnie wskazać - piszecie =default
- jeśli nie zdefiniujemy żadnej z wymienionych funkcji składowych, wszystkie zostaną wygenerowane przez kompilator
- jeśli zdefiniujemy konstruktor kopiujący lub operator przypisania kopiujący, lub destruktor - - kompilator nie wygeneruje konstruktora przenoszącego i przenoszącego operatora przypisania
- jeśli zdefiniujemy konstruktor przenoszący lub przenoszący operator przypisania, żaden z pozostałych elementów nie zostanie automatycznie wygenerowany
Ciężko to zapamiętać, więc dobra rada:
class A {
public:
A() = default;
A(A&& src) = delete;
};
void f(A x);
int main() {
A a, b; // ok - można utworzyć obiekt A
b = a; // błąd - zaczęliśmy jawnie zarządzać listą konstruktorów, więc nie mamy wygenerowanego
// ani operatora przypisania, ani konstuktora kopiującego.
f(a); // tu też będzie błąd - przekazanie parametru przez wartość wymaga kopiowania
return 0;
}
Dzięki temu możemy uniknąć generowania błędnego kodu. Przykładowo - kopiowanie jest płytkie – kopiowany jest wskaźnik a nie wskazywana wartość. Co w praktyce oznacza, że poniższy programik spowoduje ulubiony błąd programisty C++ - access violation ;->
class CMoja
{
public:
CMoja() {
tbl = new char[255];
};
~CMoja() {
delete[] tbl;
}
private:
char* tbl;
};
void ff(CMoja m) {
...
}
int main() {
CMoja obiekt;
ff(obiekt);
CMoja *po = new CMoja();
ff(*po);
delete po;
return 0;
}
Dlaczego? Mam nadzieję że się domyślacie ...
Jeśli zabronicie generowania konstruktora domyślnego - w trakcie kompilacji funkcji przyjmującej obiekt przez referencję - wystąpi błąd kompilacji.
class CMoja
{
public:
CMoja() {
tbl = new char[255];
};
CMoja(const CMoja&) = delete;
~CMoja() {
delete[] tbl;
}
private:
char* tbl;
};
void ff(CMoja m) {
...
}
int main() {
CMoja obiekt;
ff(obiekt);
CMoja *po = new CMoja();
ff(*po);
delete po;
return 0;
}
Pola, zwykłe metody oraz konstruktory i destruktory to zdecydowanie najczęściej spotykane i chyba najważniejsze elementy klas. Można jeszcze wspomnieć, że wewnątrz klasy (a także struktury i unii) możemy zdefiniować kolejną klasę. Taką definicję nazywamy wtedy zagnieżdżoną. Technika ta nie jest stosowana zbyt często, ale jest dostępna. Podobnie zresztą jest z definicjami innych zagnieżdżonych typów - możecie zdefiniować wewnątrz klasy enumerację, możecie wykorzystywać typedef.
Na koniec rozważań o konstruktorach - mała rozrywka. Przygotujemy klasę, która ma tylko jedną instancję - singleton. By to uzyskać - musimy skorzystać ze składowych statycznych, prywatnego konstruktora, oraz statycznej zmiennej lokalnej w metodzie. Działanie natomiast polega na prostym spostrzeżeniu - statyczne zmienne lokalne są tworzone przy pierwszym wywołaniu funkcji, i przechowywane na stosie pomiędzy wywołaniami aż do zakończenia programu.
#include <iostream>
class CSingleton {
public:
CSingleton(const CSingleton& c) = delete;
static CSingleton* instancja() {
static CSingleton jedynak;
return &jedynak;
}
void akcja() {
std::cout << ++licznik << " akcja\n";
}
private:
CSingleton() {
std::cout << "Tworzenie obiektu\n";
}
~CSingleton() {
std::cout << "Niszczenie obiektu\n";
}
int licznik{0};
};
void f() {
auto& s = *CSingleton::instancja();
std::cout << "W funkcji:\n";
s.akcja();
}
int main() {
std::cout << "Zaczynamy, jeszcze bez instancji\n";
auto s = CSingleton::instancja();
s->akcja();
auto s2 = CSingleton::instancja();
s->akcja();
// CSingleton s3; // błąd - nie można tworzyć kopii na stosie
// CSingleton s4{*s}; // błąd - nie można kopiować
f();
return 0;
}
Semantyka przeniesienia
Semantyka przeniesienia jest jedną z nowszych koncepcji, wprowadzoną do C++ wraz ze standardem C++11. Jej celem było wyeliminowanie zbędnego kopiowania danych - dając w to miejsce możliwość przenoszenia zawartości obiektu. Wprowadzenie tej idei do języka wymagało rozszerzenia jego funkcjonalności, bez którego nie dałoby się wprowadzić ich w życie. Clou tego rozszerzenia to referencje do r-wartości (r-value references).
Referencja do r-wartości przypomina tradycyjne referencje, które możemy nazwać referencjami do l-wartości. Ale zanim zagłębimy się w szczegóły, warto przejść przez podstawy...
Mam nadzieję, ż rozróżniacie l-wartości od r-wartości:
- l-wartość to obiekt zdefiniowany z nazwą, który możemy umieścić po lewej stronie operatora przypisania (ale także po prawej) i pobrać jego adres za pomocą operatora &
- r-wartość to obiekt bez zdefiniowanej nazwy – jest to obiekt tymczasowy, który można umieścić tylko i wyłącznie po prawej stronie operatora przypisania (nie można pobrać jego adresu za pomocą operatora &)
int x = 4; // x to l-wartość, 4 to r-wartość
MojaKlasa mc = MojaKlasa(); // mc to l-wartość, MojaKlasa() to r-wartość
Tworzenie referencji do obu typów wartości wygląda tak:
int x;
int& ref1 = x; // ref1 to referencja do l-wartości
int&& ref2 = 7; // ref2 to referencja do r-wartości
Referencję do r-wartości definiuje się przy użyciu podwójnego ampersandu (&&).
Jaka jest więc różnica między tymi dwoma rodzajami referencji?
Referencja do r-wartości może być przypisana do obiektu tymczasowego (r-wartości):
MojaKlasa&& ref1 = MojaKlasa(); // OK
MojaKlasa& ref2 = MojaKlasa(); // Błąd !
Daje nam to możliwość działania pozornie pozbawionego sensu: dzięki r-referencji możemy modyfikować oryginalny obiekt – w tym przypadku r-wartość, a więc np. literał - czyli coś, co potencjalnie jest niezmienne. Po co? Po to by mieć możliwość zniszczenia tego "niezmiennego" - jeśli wiemy że już nie będzie nam potrzebne. To kluczowe spostrzeżenie w kontekście semantyki przeniesienia.
Kopiowanie obiektów może być kosztowne. W przypadku niewielkich klas - zawierających pola typu podstawowego - problem nie jest duży. Jednakże, gdy mamy do czynienia z kolekcjami zawierającymi setki lub tysiące elementów, zaczynamy zauważać różnicę. A z kopiowaniem mamy często do czynienia. Czasem łatwo go uniknąć (np. przekazując parametr do funkcji przez referencję zamiast przez wartość), czasem pomoże nam kompilator (np. zamieniając operator przypisania na inicjację w przypadku prostego kodu typu string s = "Mała Megi"s), czasem jednak uniknąć go jest trudno np. jak zwracamy zmienną lokalną z funkcji przez return (tu też czasem pomoże kompilator) lub zamieniamy wartości dwóch zmiennych (tu musimy dać sobie radę sami).
Podobne sytuacje często wynikają wprost z definicji języka - więc jest to problem strukturalny.
W C++ od C++11 wprowadzono możliwość przeniesienia obiektu zamiast jego kopiowania, i przeprojektowano bibliotekę standardową po to, aby skutecznie wyeliminować sytuacje, w których zachodzi zupełnie niepotrzebne kopiowanie danych. Semantyka przeniesienia daje kompilatorowi możliwość zastąpienia kosztownych operacji kopiowania czymś, co jest (zazwyczaj) o wiele mniej kosztowne – tzw. operacjami przeniesienia. Jeśli kompilator wie, że kopiowany obiekt źródłowy nie będzie już używany, może po prostu zrezygnować z kopiowania ( tworzenia nowego obiektu, przenoszenia do niego danych i ewentualnego niszczenia niepotrzebnego obiektu źródłowego) na rzecz uznania obiektu źródłowego za obiekt docelowy. Co ważniejsze – programista może teraz jawnie poinformować kompilator o tym, że obiekt źródłowy może być w ten sposób użyty.
Stosując r-referencję informujemy kompilator - oto obiekt, który możesz wykorzystać i zmodyfikować – skorzystaj z tego w celu optymalizacji.
Pierwszą operacją, która na tym zyska - jest klasyczna zamiana wartości dwóch zmiennych. W klasycznym podejściu - mamy kopiowanie, w nowym - kopiowanie nie wystąpi. Popatrzcie na kod poniżej:
#include <iostream>
class CWektor {
public:
CWektor(int rozmiar = 10, double wartosc = 0.0) : m_rozmiar{rozmiar}, m_dane{new double[rozmiar]} {
std::cout << "Domyślny konstruktor\n";
std::fill(m_dane, m_dane+m_rozmiar, wartosc);
};
CWektor(const CWektor& w) : m_rozmiar{w.m_rozmiar}, m_dane{new double[w.m_rozmiar]} {
std::cout << "Konstruktor kopiujący\n";
for (int i{0}; i<m_rozmiar; i++)
m_dane[i] = w.m_dane[i];
};
CWektor(CWektor&& w) : m_rozmiar{w.m_rozmiar}, m_dane{w.m_dane} {
std::cout << "Konstruktor przenoszący\n";
w.m_dane = nullptr;
};
CWektor& operator=(const CWektor& w) {
std::cout << "Przypisanie kopiujące\n";
if (this != &w) {
if (m_dane)
delete[] m_dane;
m_dane = new double[w.m_rozmiar];
m_rozmiar = w.m_rozmiar;
for (int i{0}; i < m_rozmiar; i++)
m_dane[i] = w.m_dane[i];
}
return *this;
};
CWektor& operator=(CWektor&& w) {
std::cout << "Przypisanie przenoszące\n";
if (this != &w) {
if (m_dane)
delete[] m_dane;
m_rozmiar = w.m_rozmiar;
m_dane = w.m_dane;
w.m_dane = nullptr;
}
return *this;
};
virtual ~CWektor() {
if (m_dane)
delete[] m_dane;
}
private:
int m_rozmiar{0};
double* m_dane{nullptr};
};
void zamien(CWektor& a, CWektor& b) {
auto t = a;
a = b;
b = t;
}
void noweZamien(CWektor& a, CWektor& b) {
auto t = std::move(a);
a = std::move(b);
b = std::move(t);
}
int main() {
CWektor x{1000, 1.0}, y{1000, 2.0};
std::cout << "Klasycznie:\n";
zamien(x, y);
std::cout << "Bez kopiowania:\n";
noweZamien(x, y);
return 0;
}
W podejściu klasycznym - musieliśmy trzy razy kopiować bloki pamięci po 1000 elementów (funkcja zamien). Wykorzystując przeniesienie - nie kopiowaliśmy dużych bloków wcale - fajnie, nie?
W przeniesieniu pomógł nam szablon std::move. Jest on sposobem na to, by poinformował kompilator, by spróbował przekształcić parametr na r-wartość. Wewnętrznie jest to po prostu bezwarunkowe rzutowanie podanego argumentu na referencję do r-wartości i zwrócenie jej jako wyniku.
Oczywiście - po wykorzystaniu r-wartości do przeniesienia zawartości jednego obiektu do drugiego - nie można już korzystać z oryginału, i o to musi zadbać programista:
CWektor x{1000, 1.0};
auto z = std::move(x);
// od tego momentu nie można już korzystać z x
1.7. Korzystanie z obiektów
Nawet dziesiątki wyśmienitych klas nie stanowią jeszcze gotowego programu, a jedynie pewien rodzaj reguł, wedle których będzie on realizowany. Wprowadzenie tych reguł w życie wymaga utworzenia obiektów na podstawie zdefiniowanych klas, oraz wykonanie przy ich pomocy zadań stawianych przed programem. W C++ mamy dwa główne sposoby "obchodzenia" się z obiektami; różnią się one pod wieloma względami, inne jest też zastosowanie każdego z nich. Naturalną i rozsądną koleją rzeczy będzie więc przyjrzenie się im obu
Pierwszą strategię znamy już bardzo dobrze, używaliśmy jej bowiem niejednokrotnie nie tylko dla samych obiektów, lecz także dla wszystkich innych zmiennych – tworzymy statyczne zmienne obiektowe. W tym trybie korzystamy z klasy dokładnie tak samo, jak ze wszystkich innych typów w C++ - czy to wbudowanych, czy też definiowanych przez nas samych (jak enum 'y, struktury itd.). Każde pojawienie się definicji nowej zmiennej, np takiej:
CMoja obiekt;
Wykonuje jednak znacznie więcej czynności, niż jest to widoczne na pierwszy czy nawet drugi rzut oka. Pisząc tą jedną linijkę wykonuję następujące czynności:
- wprowadzam nową zmienną obiekt typu CMoja. Nie jest to rzecz jasna żadna nowość, ale dla porządku warto o tym przypomnieć.
- tworzę w pamięci operacyjnej obszar, w którym będą przechowywane pola obiektu. To także nie jest zaskoczeniem: pola, jako bądź co bądź zmienne, muszą rezydować gdzieś w pamięci, więc robią to w identyczny sposób jak pola struktur.
- wywołuję domyślny konstruktor klasy CMoja (czyli metodę CMoja::CMoja() ), by dokończył aktu kreacji obiektu. Po jego zakończeniu możemy uznać nasz obiekt za ostatecznie stworzony i gotowy do użycia.
Te trzy etapy są niezbędne, abyśmy mogli bez problemu korzystać z obiektu. W tym przypadku są one jednak realizowane całkowicie automatycznie i nie wymagają od nas żadnej uwagi. Przekonamy się później, że nie zawsze tak jest i, co ciekawe, wcale nie będziemy tym zmartwieni. Muszę jeszcze wspomnieć o pewnym drobnym wymaganiu, stawianym nam przez kompilator, któremu chcemy podać wiersz kodu umieszczony na początku paragrafu. Otóż klasa CMoja musi tutaj posiadać bezparametrowy konstruktor - utworzony jawnie w definicji klasy, lub też wygenerowany domyślnie.
W innym przypadku potrzebne jest jeszcze przekazanie odpowiednich parametrów konstruktorowi, który takowych wymaga. Konieczność tą realizujemy podobną metodą, co wywołanie zwyczajnej funkcji. Zakładając, że CMoja posiada konstruktor przyjmujący jedną liczbę całkowitą, oraz napis, możliwe jest wywołanie:
CMoja moja( 10 , "jakiś tekst" );
Zadeklarowane przed chwilą zmienne obiektowe są w istocie takimi samymi zmiennymi, jak wszystkie inne w programach C++. Możliwe jest przeprowadzanie na takich zmiennych operacji, którym podlegają na przykład liczby całkowite, napisy czy tablice. Nie mam tu wcale na myśli jakichś złożonych manipulacji, wymagających skomplikowanych algorytmów, lecz całkiem zwyczajnych i codziennych - przypisanie czy przekazywanie do funkcji. Czy można powiedzieć cokolwiek ciekawego o tak trywialnych czynnościach? Okazuje się, że tak. Zwrócimy wprawdzie uwagę na dość oczywiste fakty z nimi związane, lecz znajomość owych "banałów" okaże się później niezwykle przydatna.
Na użytek dalszych wyjaśnień wróćmy i nieco rozszerzmy początkową definicję diody:
#ifndef cdiodaH
#define cdiodaH
#include "string"
using namespace std;
/* Deklaracja klasy CDioda*/
class CDioda {
public:
/// konstruktor podstawowy
CDioda();
/// konstruktor z ustawieniem koloru
CDioda(string _kolor);
/// metoda włączająca diodę
void zapal();
/// metoda wyłączająca diodę
void zgas();
/// metoda wyświetlająca stan diody
void pokaz();
private:
string kolor;
bool zapalona;
};
#endif
#include "iostream"
#include "cdioda.h"
using namespace std;
CDioda::CDioda() {
kolor = "bialy";
zapalona = false;
}
CDioda::CDioda(string _kolor) {
kolor = _kolor;
zapalona = false;
}
void CDioda::zapal() {
zapalona = true;
}
void CDioda::zgas() {
zapalona = false;
}
void CDioda::pokaz() {
if (zapalona)
cout << "Swieci w kolorze " << kolor << endl;
else
cout << "Nie swieci\n";
}
Natychmiast też zadeklarujemy i stworzymy dwa obiekty należące do naszej klasy:
CDioda dioda1("czerwona”), dioda2("zielona”);
Tym sposobem mamy więc diody, sztuk dwie, w kolorze czerwonym oraz zielonym. Moglibyśmy użyć ich metod, aby je obie włączyć; zrobimy jednak coś dziwniejszego - przypiszemy jedną lampę do drugiej:
dioda1=dioda2;
Co to oznacza? By dobrze zrozumieć powyższą operację - musimy pamiętać, że dioda1 oraz dioda2 są to przede wszystkim zmienne , które przechowują pewne wartości. Fakt, że tymi wartościami są obiekty, nie ma większego znaczenia. Pomyślmy zatem, jaki efekt spowodowałby ten kod, gdybyśmy zamiast klasy CDioda użyli jakiegoś zwykłego, fundamentalnego typu zmiennej? Dawna wartość zmiennej, do której nastąpiło przypisanie, zostałaby zapomniana i obie zmienne zawierałyby tę samą liczbę.
Dla obiektów rzecz ma się identycznie: po wykonaniu przypisania zarówno Lampa1 , jak i Lampa2 reprezentować będą obiekty zielonych lamp. Czerwona lampa, pierwotnie zawarta w zmiennej Lampa1 , zostanie zniszczona, a w jej miejsce pojawi się kopia zawartości zmiennej Lampa2. Nie bez powodu zaakcentowałem wyżej słowo "kopia". Obydwa obiekty są bowiem od siebie całkowicie niezależne - ich tożsamości są inne. Jeżeli włączylibyśmy jeden z nich:
dioda1.zapal();
drugi nie zmieniłby się wcale i nie obdarzył nas swym własnym światłem. Możemy więc podsumować nasz wywód krótką uwagą na temat zmiennych obiektowych:
Wspominałem, że wszystko to może wydawać się naturalne, oczywiste i niepodważalne - warto na to jednak zwrócić uwagę zanim zaczniemy ręcznie zarządzać czasem życia obiektów.
Korzystając z obiektu zazwyczaj odwołujemy się do jego części składowych - metod lub pól. Tu z pomocą przychodzi nam zawsze operator wyłuskania - kropka ( . ). Stawiamy więc go po nazwie obiektu, by potem wpisać nazwę metody / pola, do którego chcemy się odwołać. Pamiętajmy, że posiadamy wtedy dostęp jedynie do składowych publicznych klasy, do której należy obiekt.
Dalsze postępowanie zależy już od tego, czy naszą uwagę zwróciliśmy na pole, czy na metodę. W tym pierwszym, rzadszym przypadku nie odczujemy żadnej różnicy w stosunku do pól w strukturach - i nic dziwnego, gdyż nie ma tu rzeczywiście najmniejszej rozbieżności. Wywołanie metody jest natomiast łudząco zbliżone do uruchomienia zwyczajnej funkcji - tyle że w grę wchodzą tutaj nie tylko jej parametry, ale także obiekt, dla którego daną metodę wywołujemy.
Każdy stworzony obiekt musi prędzej czy później zostać zniszczony, aby móc odzyskać zajmowaną przez niego pamięć i spokojnie zakończyć program. Dotyczy to także zmiennych obiektowych, lecz dzieje się to trochę jakby za plecami programisty. Zauważmy bowiem, iż w żadnym z naszych dotychczasowych programów, wykorzystujących techniki obiektowe, nie pojawiły się instrukcje, które jawnie odpowiadałyby za niszczenie stworzonych obiektów. Nie oznacza to bynajmniej, że zalegają one w pamięci operacyjnej, zajmując ją niepotrzebnie. Po prostu kompilator sam dba o to, by ich destrukcja nastąpiła w stosownej chwili - analogicznie do typów prostych. Omawialiśmy już zasięg zmiennej - czyli w uproszczeniu fragment kodu, w którym dana zmienna jest dostępna. Dostępna - to znaczy zadeklarowana, z przydzieloną dla siebie pamięcią. Moment opuszczenia zasięgu zmiennej przez program jest więc kresem jej istnienia. Jeśli nieszczęsna zmienna była obiektową, do akcji wkracza destruktor klasy (jeżeli został określony), sprzątając ewentualny bałagan po obiekcie i niszcząc go. Dalej następuje już tylko zwolnienie pamięci zajmowanej przez zmienną i jej kariera kończy się w niebycie
Wskaźniki do obiektów
O wskaźnikach pisałem już wcześniej. Teraz pokażę kilka przykładów zastosowania wskaźników do pracy z obiektami. Zacznijmy więc ... Hem, od czegóż to mielibyśmy zacząć, jeżeli nie od jakiejś zmiennej? W końcu bez zmiennych nie ma obiektów, a bez obiektów nie ma programowania (obiektowego :D). Na początek trywialny przykład:
CDioda *pDioda1 = new CDioda();
CDioda *pDioda2 = pDioda1;
pDioda2->pokaz();
pDioda1->zapal();
pDioda2->pokaz();
/// niszczenie diody
delete pDioda1;
pDioda2->pokaz() /// Błąd !! - nie ma już diody ...
delete pDioda2; /// Błąd !! - nie ma już czego niszczyć
To chyba oczywiste – mamy teraz tylko jeden obiekt, i dwie metody dostępu do niego. Wyjaśnienie należy się jednak odnośnie operatora wyłuskania – teraz ma on nieco inną postać, nie jest nim kropka, ale strzałka ( -> ). Otrzymujemy ją, wpisując kolejno dwa znaki: myślnika oraz symbolu większości. Oczywiście, możemy ciągle wykorzystywać kropkę, ale - ze względu na priorytety operatorów - składnia wtedy wygląda nieco dziwacznie:
(*pDioda1).pokaz();
Wszelkie obiekty kiedyś należy zniszczyć; czynność ta, oprócz wyrabiania dobrego nawyku sprzątania po sobie, zwalnia pamięć operacyjną, które te obiekty zajmowały. Po zniszczeniu wszystkich możliwe jest bezpieczne zakończenie programu. Podobnie jak tworzenie, tak i niszczenie obiektów dostępnych poprzez wskaźniki nie jest wykonywane automatycznie. Wymagana jest do tego odrębna instrukcja delete – widzicie ją w kodzie powyżej. Delete wywołuje destruktor obiektu, a następnie zwalnia pamięć zajętą przez obiekt, który kończy wtedy definitywnie swoje istnienie. To tyle jeśli chodzi o życiorys obiektu. Co się jednak dzieje z samym wskaźnikiem? Otóż nadal wskazuje on na miejsce w pamięci , w którym jeszcze niedawno egzystował nasz obiekt. Teraz jednak już go tam nie ma; wszelkie próby odwołania się do tego obszaru skończą się więc błędem, zwanym naruszeniem zasad dostępu (ang. access violation ).
Ręczne zarządzanie pamięcią wiąże się zawsze ze zwiększonym ryzykiem wycieków pamięci - dlatego też wspomniałem wcześniej o RAII - technice zmniejszającej to ryzyko. W przypadku obiektów RAII implemetuje się korzystając z inteligentnych wskaźników. Popatrzcie na poniższy przykład:
void mrugaj(int x) {
CDioda *pDioda1 = new CDioda();
if (x < 0) {
std::cout << "Błędny parametr - nie wiem ile razy mrugnąć";
return;
}
for (int i=0; i<x; i++) {
pDioda->zapal();
pDioda->pokaz();
pDioda->zgas();
pDioda->pokaz();
}
/// niszczenie diody
delete pDioda1;
}
Niby jest ok na pierwszy rzut oka - ale istnieje ryzyko wycieku pamięci. Jeśli wywołamy tą funkcję z parametrem ujemnym - zaalokowany obiekt pDioda nie zostanie nigdy skasowany. Natomiast inteligentny wskaźnik sam zniszczy obiekt wskazywany po opuszczeniu zasięgu:
void mrugaj(int x) {
std::unique_pointer<CDioda>{new CDioda()};
if (x < 0) {
std::cout << "Błędny parametr - nie wiem ile razy mrugnąć";
return;
}
for (int i=0; i<x; i++) {
pDioda->zapal();
pDioda->pokaz();
pDioda->zgas();
pDioda->pokaz();
}
}
Tu już wycieku pamięci nie będzie.
2. Związki pomiędzy obiektami
W inżynierii oprogramowania zazwyczaj wyróżnia się pięć zasadniczych rodzajów powiązań:
- Zależność (dependency)
- Aasocjacja (associacton)
- Agregacja (aggregation)
- Kompozycja (composition)
- Dziedziczenie (inheritance)
Zazwyczaj na początku swojej kariery młodzi programiści niespecjalnie je rozróżniają, potem - jak już poznają polimorfizm - to starają się stosować dziedziczenie w każdym możliwym przypadku. Ja w tym momencie chciałbym zwrócić Waszą uwagę na 4 pozostałe związki, i pokazać, że też mogą one mieć swoje odbicie w kodzie który tworzycie.
2.1. Zależność
Zależność to najsłabszy z omawianych związków. W ogólności zależność mówi, że jeden z obiektów wpływa na drugim, przy czym to wpływanie może mieć różny charakter. Może to być wywołanie metody, może to być utworzenie obiektu A przez obiekt B, itp...
Zależność zazwyczaj jest jednokierunkowa, po polsku opisuje się je frazą "...korzysta z...", "...oddziałuje na...", "...ma wpływ na...", "...tworzy...".
Najczęściej zależność oznacza, że klasa A używa klasy B jako parametru dla jakiejś operacji. Z tego względu zależność ma trywialną implementację:
#include <iostream>
class A {
public:
void dajGlos() const { std::cout << "Mówi A...\n"; }
void robCos(const B& dawca) {dawca->dajGlos();}
};
class B {
public:
void dajGlos() const { std::cout << "Mówi B...\n"; }
void robCos(const A& dawca) { dawca->dajGlos(); }
};
int main() {
A obA;
B obB;
obA.robCos(obB);
obB.robCos(obA);
return EXIT_SUCCESS;
}
2.2. Asocjacja
Asocjacje są silniejszymi relacjami niż zależności. Wskazują, że jeden obiekt jest związany z innym przez określony czas. Jednak czas życia obu obiektów nie jest od siebie zależny, usunięcie jednego nie powoduje usunięcia drugiego. Nie można też powiedzieć, że jeden obiekt jest częścią drugiego.
W języku polskim asocjacje zazwyczaj opisuje się słowami posiada, należy do, itp ... lecz uważajcie by ich nie mylić z agregacjami. W relacji asocjacji żaden z obiektów nie jest właścicielem drugiego, nie zarządza jego czasem życia, także samo zerwanie powiązania nie wpływa na czas życia obu obiektów. Potraktujcie ich jako partnerów - w ziązku asocjaci są ludzie którzy występują w jednej drużynie lub zapisali się do tego samego stowarzyszenia. Obiekty powiązane asocjacją mogą posiadać wzajemne referencje, jeden może się odwołać do drugiego, etc.
Z formalnego punktu widzenia, obiekty będące w związku asocjacji charakteryzują następujące cechy:
- Powiązany obiekt może istnieć bez związku z drugim obiektem
- Powiązany obiekt może należeć do więcej niż jednego obiektu jednocześnie
- Czasem życia powiązanego obiektu nie zarządza drugi obiekt z którym pozostaje on w relacji asocjacji.
- Powiązany obiekt może ale nie musi wiedzieć o istnieniu obiektu - związek może być jedno-, lub dwukierunkowy.
W języku polskim asocjację oddaje się słowami "należy do", "używa", czasem także "posiada" - ale nie w rozumieniu omówionej później agregacji. W przypadku wykładowcy i studenta - wykładowca "używa" studentów w celu realizacji swojej pracy (niesie kaganek oświaty). Student "używa" wykładowcy do zdobycia wiedzy.
Ponieważ asocjacje są szerokim typem relacji, mogą być implementowane na wiele różnych sposobów. Jednak jak chcecie jasno wyrazić swoją intencję - w C++ najlepiej implementować asocjacje użyciu wskaźników, gdzie obiekt wskazuje na powiązany obiekt.
W tym przykładzie zaimplementujemy relację dwukierunkową student/wykładowca - ma to sens jeśli wiecie kto Was jako studentów uczy, i ma też sens jeśli uczący wie kogo uczy ... ;)
Jako ciekawostki - zamiast czystych wskaźników (których stosowanie jest nieeleganckie) w poniższym przykładzie użyliśmy klasy reference_wrapper - miłego dodatku z STL który pozwala nam łatwo kopiować i przypisywać referencje, co w efekcie pozwala na przechowywanie ich w wektorze. Oczywiście równie dobrze można użyć klasy std::shared_ptr, w połączeniu z std::weak_ptr.
#include <iostream>
#include <functional>
#include <iostream>
#include <string>
#include <string_view>
#include <vector>
using namespace std::literals;
// ponieważ mamy zależność dwustronną - potrzebna nam jest wstępna deklaracja
// celowo nie wprowadzamy dziedziczenia i duplikujemy część pól w klasach
// by skupić się na asocjacji.
class CStudent;
class CWykladowca
{
public:
CWykladowca(std::string_view imie, std::string_view nazwisko) : m_imie{imie}, m_nazwisko{nazwisko} { }
void dodajStudenta(CStudent& student);
friend std::ostream& operator<<(std::ostream& out, const CWykladowca& w);
std::string nazwa() const { return m_imie+" "s+m_nazwisko; }
private:
std::string m_imie, m_nazwisko;
std::vector<std::reference_wrapper<const CStudent>> m_studenci;
};
class CStudent
{
public:
CStudent(std::string_view imie, std::string_view nazwisko) : m_imie{imie}, m_nazwisko{nazwisko} { }
friend std::ostream& operator<<(std::ostream& out, const CStudent& s);
std::string nazwa() const { return m_imie+" "s+m_nazwisko; }
// Metoda jest zaprzyjaźniona by mogła wywołać dodajWykladowce
friend void CWykladowca::dodajStudenta(CStudent &student);
private:
std::string m_imie, m_nazwisko;
std::vector<std::reference_wrapper<const CWykladowca>> m_wykladowcy;
// Mimo iż związek jest dwustronny - celowo ukryliśmy możliwość dodawania wykładowców u studentów,
// wyuszając by związek był nawiązywany zawsze przez CWykladowca::dodajStudenta
void dodajWykladowce(const CWykladowca& w)
{
m_wykladowcy.push_back(w);
}
};
void CWykladowca::dodajStudenta(CStudent &student)
{
m_studenci.push_back(student);
student.dodajWykladowce(*this);
}
std::ostream& operator<<(std::ostream& out, const CWykladowca& w)
{
if (w.m_studenci.empty()) {
out << w.nazwa() << " nie ma jeszcze studentów";
return out;
}
out << w.nazwa() << " wykłada dla: ";
for (const auto& student : w.m_studenci)
out << student.get().nazwa() << ' ';
return out;
}
std::ostream& operator<<(std::ostream& out, const CStudent& student)
{
if (student.m_wykladowcy.empty()) {
out << student.nazwa() << " do nikogo nie uczęszcza";
return out;
}
out << student.nazwa() << " uczęszcza na wykłady do: ";
for (const auto& wykladowca : student.m_wykladowcy)
out << wykladowca.get().nazwa() << ' ';
return out;
}
int main()
{
// Studenci powstają niezależnie od wykładowców, i w dowolnej kolejności
CStudent janek{ "Janek", "Konieczny" };
CStudent basia{ "Basia", "Niespodziana" };
CStudent stasio{ "Stasio", "Przypadkowy" };
CWykladowca mikolaj{ "Mikołaj", "Kopernik" };
CWykladowca maria{ "Maria", "Skłodowska-Curie" };
CStudent zosia{ "Zosia", "Drążąca" };
mikolaj.dodajStudenta(janek);
maria.dodajStudenta(janek);
maria.dodajStudenta(basia);
maria.dodajStudenta(zosia);
std::cout << "Wykładowcy:\n";
std::cout << mikolaj << '\n';
std::cout << maria << '\n';
std::cout << "Studenci:\n";
std::cout << janek << '\n';
std::cout << basia << '\n';
std::cout << stasio << '\n';
std::cout << zosia << '\n';
return 0;
}
2.3. Agregacja
O związku agregacji mówimy, jeśli obiekt agregowany jest częścią obiektu agregującego. Pełny opis zależności dla agregacji wygląda następująco:
- obiekt agregowany jest częścią obiektu agregującego
- obiekt agregowany może należeć do więcej niż jednego obiektu agregującego jednocześnie
- obiekt agregujący nie zarządza czasem życia obiektu agregowanego
- obiekt agregowany zazwyczaj nie wie o istnieniu obiektu agregującego
W przeciwieństwie do asocjacji, agregacja jest relacją całość-część, gdzie części zawarte są w całości, i jest to relacja jednokierunkowa.
Jednak, w przeciwieństwie do kompozycji, części mogą należeć do więcej niż jednego obiektu jednocześnie, a cały obiekt nie ponosi odpowiedzialności za istnienie i czas życia części. Kiedy tworzona jest obiekt agregujący, nie jest on odpowiedzialny za tworzenie obiektów agregowanych. Podobnie kiedy obiekt agregowany jest niszczony, nie niszczy swoich części (obiektów agregowanych).
Na przykład, rozważmy relację między osobą a jej adresem zamieszkania. W tym przykładzie, dla uproszczenia, przyjmujemy, że każda osoba ma swój adres. Jednakże ten adres może należeć do więcej niż jednej osoby jednocześnie: na przykład do ciebie i twojego współlokatora lub partnera życiowego. Jednak ten adres nie jest zarządzany przez osobę - adres prawdopodobnie istniał wcześniej, zanim osoba się tam pojawiła, i będzie istnieć po tym, jak osoba odejdzie. Dodatkowo, osoba wie, pod jaki adresem mieszka, ale adresy nie wiedzą, kto tam mieszka. Dlatego ta relacja jest agregatem.
Inny przykład to budowa typowych maszyn - np. samochodu. Samochód ma silnik, a silnik jest częścią samochodu. Jednocześnie jest jakiś właściciel. Ten właściciel ma samochód. Ale można też powiedzieć że ma silnik - więc silnik pozostaje w związku agregacji zarówno z samochodem, jak i z właścicielem.Dodatkowo - można wyjąć z samochodu silnik, można zdjąć koła z jednego auta i założyć je do drugiego.
Jeszcze innym przykładem jest zależność Student - Grupa. Student należy do grupy - ale to nie grupa go stworzyła, i nie grupa go unicestwi ... ;)
Z technicznego punktu widzenia - agregacja jest implementowana podobnie do asocjacji - znów mamy pole w klasie, znów jest to wskaźnik lub referencja. Nowością jest to, że nie implementuje się zależności odwrotnej. Poniżej przykład z wykorzystaniem inteligentnych wskaźników:
#include <iostream>
#include <string>
#include <string_view>
#include <vector>
#include <memory>
using namespace std::literals;
class CStudent
{
public:
CStudent(std::string_view imie, std::string_view nazwisko) : m_imie{imie}, m_nazwisko{nazwisko} { }
std::string nazwa() const { return m_imie+" "s+m_nazwisko; }
private:
std::string m_imie, m_nazwisko;
};
class CGrupa
{
public:
CGrupa(std::string_view nazwa) : m_nazwa{nazwa} { }
void dodajStudenta(std::shared_ptr<CStudent> student) {
m_studenci.push_back(student);
}
friend std::ostream& operator<<(std::ostream& out, const CGrupa& w);
std::string nazwa() const { return m_nazwa; }
private:
std::string m_nazwa;
std::vector<std::shared_ptr<CStudent>> m_studenci;
};
std::ostream& operator<<(std::ostream& out, const CGrupa& w)
{
if (w.m_studenci.empty()) {
out << w.nazwa() << " nie ma jeszcze studentów";
return out;
}
out << w.nazwa() << " składa się z: ";
for (auto& student : w.m_studenci)
out << student->nazwa() << ' ';
return out;
}
int main()
{
// Studenci powstają niezależnie od wykładowców, i w dowolnej kolejności
std::shared_ptr<CStudent> janek{ new CStudent{"Janek", "Konieczny" }};
std::shared_ptr<CStudent> basia{ new CStudent{ "Basia", "Niespodziana" }};
std::shared_ptr<CStudent> stasio{ new CStudent{ "Stasio", "Przypadkowy" }};
std::shared_ptr<CStudent> zosia{ new CStudent{ "Zosia", "Drążąca" }};
CGrupa mistrzowie{"Mistrzowie"};
CGrupa alfa{"Alfa"};
mistrzowie.dodajStudenta(janek);
mistrzowie.dodajStudenta(zosia);
alfa.dodajStudenta(janek);
alfa.dodajStudenta(basia);
alfa.dodajStudenta(zosia);
alfa.dodajStudenta(stasio);
std::cout << "Grupy:\n";
std::cout << mistrzowie << '\n';
std::cout << alfa << '\n';
return 0;
}
2.4. Kompozycja
W rzeczywistości, złożone obiekty często są budowane z mniejszych, prostszych obiektów. Na przykład samochód jest budowany z karoserii, silnika, czterech kół, skrzyni biegów, kierownicy, i jeszcze długo można by było wymieniać. Tak samo można powiedzieć o wielu wytworach techniki (toster zbudowany jest z obudowy, grzałek i mechanizmu wyrzutowego, smartfon ma CPU, pamięć, ekra, akumulator, itd...) czy biologii - człowiek ma głowę, tułów, serce, wątrobę, itd.... Taki typ relacji nazywa się kompozycją.
Mówiąc ogólnie, kompozycja obiektów modeluje relację "ma" pomiędzy dwoma obiektami. Samochód "ma" skrzynię biegów. Twój smartfon"ma" CPU, a człowiek "ma" serce (przynajmniej w sensie biologicznym). Złożony obiekt czasami jest nazywany całością. Prostszy obiekt jest często nazywany częścią lub składnikiem.
W C++ już widzieliście, że struktury i klasy mogą mieć składowe danych różnych typów (takich jak typy podstawowe lub inne klasy). Kiedy budujemy klasy które mają pola - to de facto konstruujemy złożony obiekt z prostszych części, co jest kompozycją. Z tego powodu, struktury i klasy są czasami nazywane typami złożonymi.
Kompozycja obiektów jest użyteczna w kontekście C++, ponieważ pozwala nam tworzyć złożone klasy, łącząc prostsze, łatwiej zarządzalne części. To redukuje złożoność i pozwala nam pisać kod szybciej i z mniejszą liczbą błędów, ponieważ możemy ponownie użyć kodu, który został już napisany, przetestowany i zweryfikowany jako działający.
Czasem występuje problem z rozróżnieniem agregacji i kompozycji. W obu przypadkach prawidłowe określenia to "należy do" czy też "ma" - więc na analizie leksykalnej nie możemy się w pełni oprzeć. Raczej powinniście sprawdzić dwa założenia:
- Składnik może należeć tylko do jednego obiektu jednocześnie.
- Czasem życia składnika zarządza obiekt nadrzędny.
Dobrym przykładem kompozycji w życiu codziennym jest relacja między człowiekiem a wątrobą. Dana wątroba może być tylko częścią jednego człowieka - nie można jej współdzielić. Nie powstała także sama z siebie - tylko wraz z człowiekiem, i z nim zginie.
Zauważcie, że kompozycja nie ma nic do powiedzenia na temat przenośności części. Wątroba może być przeszczepiane z jednego ciała do drugiego - jednak nawet po przeszczepieniu, nadal spełnia wymagania kompozycji (jest teraz własnością innego człowieka - ale ciągle funkcjonuje tylko jako jego część - a nie samodzielny byt).
Kompozycje w C++ implementuje się prosto i naturalnie - dając zwykłe pole w klasie. Kompozycje, które z wymagają dynamicznej alokacji / dealokacji pamięci (np składowa jest zbyt duża by mieścić się na stosie), mogą być implementowane przy użyciu wskaźników. W tym przypadku obiekt nadrzędny powinien być odpowiedzialny za wszystkie niezbędne wywołania new i delete (najlepiej zgodnie z RAII).
Kompozycja to częsty i preferowany związek. W ogólności - jeśli można zaprojektować klasę przy użyciu kompozycji, to powinna być tak zaprojektowana - pozwala to nie zaprzątać sobie głowy zarządzaniem czasem życia części składowych.
2.5. Podsumowanie
Pozostał nam do omówienia jeszcze jeden rodzaj związku - dziedziczenie. Dziedziczenie jest bardziej skomplikowane niż inne związki, szczególnie w sensie implementacji - dlatego poświęcimy mu osobny rozdział.
Zanim jednak przejdziemy do dziedziczenia - chciałbym byście nauczyli się wykorzystywać pozostałe związki. Często agregacja czy kompozycja może być wykorzystana alternatywnie do dziedziczenia. Te związki pokazujemy także na diagramach UML.
W trakcie zajęć, podczas realizacji projektów - będziecie mieli obowiązek prawidłowo pokazać i nazwać związki między waszymi klasami / obiektami.
3. Dziedziczenie i polimorfizm
Samo korzystanie z obiektów jeszcze nie daje Wam pełnych możliwości ekspresji udostępnianych przez programowanie zorientowane obiektowo. By go w pełni wykorzystywać - musicie jeszcze poznać i stosować pozostałe elementy udostępniane w tej technice: dziedziczenie, polimorfizm oraz abstrakcję.
3.1. Dziedziczenie
Jednym z głównych powodów, dla których obiektowe techniki programowania zyskały taką popularność, jest znaczący postęp w kwestii ponownego wykorzystania kodu oraz możliwość jego rozszerzania i dostosowania do indywidualnych potrzeb. Ta cecha leży u samych podstaw programowania zorientowanego obiektowo: program konstruowany jako zbiór współdziałających obiektów przestaje być pojedynczą całością, gdzie dane są ściśle powiązane z operacjami na nich wykonywanymi (jeden z pierwszych szeroko znanych podręczników IT miał tytuł "Algorytmy + struktury danych = programy" ;). Współcześnie dążymy do czegoś innego - program wewnętrznie powinien mieć jak najmniej powiązań o możliwie najlepiej zaprojektowanej semantyce. Staramy się wyodrębniać podsystemy i biblioteki do ponownego wykorzystania w kolejnych projektach. To ułatwia i przyspiesza tworzenie nowych aplikacji.
Sporo tu zależy od umiejętności i doświadczenia programisty - programowanie zorientowane obiektowo nie sprawi, że napisany przy jego użyciu program nie będzie miał wewnętrznych zależności na tyle silnych, iż nie będzie możliwości ponownego wykorzystania jego kodu w innym projekcie.
Elementem, który ułatwia podział odpowiedzialności, jasne definiowanie interfejsów między klasami, czy też dostosowywanie jednego kodu do wielu zastosowań - jest dziedziczenie. Korzyści płynące z jego stosowania nie ograniczają się jednakże tylko do powtórnego wykorzystania istniejącego kodu. - jest ich znacznie więcej. Jeśli dodamy do dziedziczenia polimorfizm - pojawią się nowe możliwości, niezmiernie przydatne przy tworzeniu każdej niebanalnej aplikacji.
Czymże jest więc owo dziedziczenie?
Nasz świat opisujemy stosując różnego rodzaju schematy, ontologie, metodyki. Spośród nich - podejście oparte na hierarchii jest chyba najpopularniejsze i najczęściej spotykane. Wyraźnie to widać w różnych naukach - biologia zbudowała całe wielkie drzewo klasyfikujące wszystkie organizmy żywe. Co ciekawe i charakterystyczne w tym drzewie - to fakt, iż relację łączącą jego elementy określa słowo "jest". Człowiek jest naczelnym, i jest ssakiem, i jest zwierzęciem, i jest organizmem żywym. VW Golf jest samochodem osobowym, a samochód osobowy jest pojazdem, i takich przykładów można podać wiele. Co charakterystyczne - na każdym z poziomów opisu (abstrakcji) możemy wydzielić wspólne cechy i funkcjonalność (wszystkie ssaki są żyworodne i stałocieplne, i w początkowym okresie życia żywią się mlekiem matki - i jest to prawda niezależnie od tego czy mówimy o myszy, słoniu czy człowieku).
Tyle ze w obiektowym podejściu do programowania pojawia nam się problem - jak przygotować taką klasę, która opisze np lwa? Jeśli będzie to tylko jedna klasa - to wszystkie cechy muszą się w niej znaleźć. Jeśli będziemy tylko lwem się zajmowali - to jest rozwiązanie ok. Lecz wprowadzając do programu następne pojęcie - powiedzmy pawiana - jak powinniśmy postąpić? Powtórzyć całość opisu? Przecież większość cech jest wspólna dla wszystkich ssaków - w tym i dla lwa, i dla pawiana. To może warto utworzyć klasę zwierzę gdzie wrzucę te cechy wspólne? Tylko potem nie bardzo wiadomo jak utworzyć obiekt z takiej klasy - musiałby on być tworzony na podstawie dwóch klas - dwóch przepisów. Programowanie obiektowe nie dopuszcza tego - nie może być typ który jest jednocześnie liczbą całkowitą i zmiennoprzecinkową. Pewnym rozwiązaniem jest kompozycja - ale ona nie oddaje w pełni związku który istnieje w realnym świecie. Pawian nie "ma" zwierzę lecz po prostu jest zwierzęciem - jest to część jego tożsamości, a zwierzę w nim - nie ma jej oddzielnej.
I tu rozwiązaniem będzie dziedziczenie.
Za każdym razem definiując klasę pochodną, definiujemy tylko to czym ona się różni od klasy bazowej - człowiek to jest takie zwierzę, które potrafi mówić, czy używać narzędzi, i ma iloraz inteligencji.
Dziedziczenie to główny mechanizm wyróżniający programowanie zorientowane obiektowo od programowania obiektowego. Opieramy się na cechach wspólnych grupy klas – zarówno jeśli chodzi o pola jak i metody. Wspólne cechy lądują w klasie bazowej, cechy szczególne – w klasach pochodnych.
Popatrzmy na pierwszy przykład:
Pokazany powyżej diagram pokazuje nam hierarchię dziedziczenia dla figur. Mamy prostokąt, który jest taką figurą nieobrotową, która ma szerokość i wysokość. Tyle że z faktu, iż jest figurą nieobrotową - wynika to że ma także kont obrotu. A ponieważ figura nieobrotowa jest figurą (dziedziczy po figurze) - to prostokąt ma także jej cechy, w tym kolor czy położenie środka.
W dziedziczeniu istotny jest fakt, iż klasy pochodne jednak powinny różnić się czymś - albo polami, albo zachowaniem - od klasy podstawowej. Złym przykładem dziedziczenia jest klasa "Żółty prostokąt" - bo od prostokąta różni się jedynie wartością koloru - więc stanem. I tworząc obiekt prostokąt możemy polu kolor przypisać wartość żółty - nie musimy do tego definiować klasy. Co gorsza - prostokąt można by było "przemalować" na inny kolor - ale jak powstanie już konkretny obiekt - to w C++ nie da się zmienić klasy z której powstał.
Jeśli natomiast prawidłowo zdefiniujecie hierarchę - to można nie tylko ograniczyć ilość kodu (wyeliminować powtarzające się fragmenty dla różnych klas) - ale także korzystać z różnych typów na ich poziomie abstrakcji. Możemy mieć funkcję która przesuwa figurę o zadany wektor - i do tego nie jest potrzebna wiedza odnośnie tego czy jest to koło, czy prostokąt, czy figura ma promień czy wysokość - każdą figurę można przesunąć, vide- funkcja mogłaby przyjmować jako parametr wskaźnik / referencję na obiekt klasy CFigura.
W C++ mechanizm dziedziczenia jest niezwykle rozbudowany, przewyższając często możliwości dziedziczenia w innych językach wspierających programowanie zorientowane obiektowo. Zapewnia on wiele zaawansowanych funkcji, które mogą być nie zawsze niezbędne, ale pozwalają na dużą elastyczność w definiowaniu hierarchii klas. Znajomość wszystkich tych możliwości nie jest konieczna do efektywnego korzystania z programowania obiektowego - lecz na pewno nie przeszkodzi. W sumie, jak mawiają, dodatkowa wiedza jeszcze nikomu nie zaszkodziła! 😊
Zacznijmy zatem przegląd możliwości od postaw:
Zasady dostępu do pól i metod w hierarchii
Jak pamiętamy, deklarując klasę podajemy listę jej pól oraz metod, podzielonych na kilka części wedle specyfikatorów praw dostępu. W przypadku dziedziczenia pojawia się nowe określenie – protected. Same zasady dostępu wyglądają następująco:
- Pola prywatne pozostają prywatne
- Pola publiczne nadal są publiczne
- Pola chronione – dostępne dla danej klasy i wszystkich klas pochodnych – dla reszty nie.
- Obowiązują reguły przykrywania nazw
- Nie obowiązują zasady przeciążania nazw funkcji w dziedziczeniu!
Możecie to zobaczyć na poniższym przykładzie:
class CMojObiekt {
public:
int zmienna_publiczna;
void metoda_publiczna();
protected:
int zmienna_chroniona;
void metoda_chroniona();
private:
int zmienna_prywatna;
void metoda_prywatna();
};
class CMojNastepca : public CMojObiekt {
public:
...
void metoda_publiczna_nastepcy();
protected:
...
private:
void metoda_prywatna_nastepcy;
};
void CMojNastepca::metoda_prywatna_nastepcy {
// tak mozna
zmienna_chroniona = 1;
metoda_chroniona();
// tak natomiast nie da rady
zmienna_prywatna = 1;
metoda_prywatna();
};
void CMojObiekt::metoda_publiczna_nastepcy {
// tak mozna
zmienna_chroniona = 1;
metoda_chroniona();
// tak natomiast nie da rady
zmienna_prywatna = 1;
metoda_prywatna();
};
CMojNastepca mn;
...
// ponizszy kod jest nieprawidłowy
mn.zmienna_chroniona = 1;
mn.metoda_chroniona();
Należy używać specyfikatora protected , kiedy chcemy uchronić składowe przed dostępem z zewnątrz, ale jednocześnie mieć je do dyspozycji w klasach pochodnych. Przy czym nie nadużywajcie tego dostępu , wspomniana wcześniej zasada hermetyzacji ciągle obowiązuje. Preferowaną sekcją dla pól zawsze powinna być sekcja private - a umieszczanie pól w sekcji protected powinno mieć jakieś uzasadnienie.
Dopiero posiadając zdefiniowaną klasę bazową możemy przystąpić do określania dziedziczącej z niej klasy pochodnej. Jest to konieczne, bo w przeciwnym wypadku kazalibyśmy kompilatorowi korzystać z czegoś, o czym nie miałby wystarczających informacji.
Samo dziedziczenie może być wykonane wg trzech różnych schematów. Tak więc mamy dziedziczenie:
- Publiczne - Wszystkie odziedziczone pola i metody mają taki zasięg jak zdefiniowano w klasie bazowej. Klasa pochodna i jej pochodne mają dostęp do części chronionej i publicznej, korzystający z obiektów pochodnych mają dostęp do części publicznej.
- Chronione - Odziedziczone pola i metody publiczne i chronione stają się chronione w klasie pochodnej i jej pochodnych. Klasa pochodna i jej pochodne mają dostęp do części chronionej i publicznej, korzystający z obiektów pochodnych nie mają dostępu do żadnych pól i metod klasy bazowej.
- Prywatne - Odziedziczone pola i metody publiczne i chronione stają się prywatne w klasie pochodne. Klasa pochodna ma do nich dostęp, klasy wyprowadzone z pochodnej, oraz korzystający z obiektów pochodnych nie mają dostępu do żadnych pól i metod klasy bazowej. Dziedziczenie prywatne przerywa w zasadzie hierarchię dziedziczenia.
Najczęściej stosowane jest dziedziczenie publiczne -ponieważ w większości przypadków nie ma potrzeby zmiany praw dostępu do składowych odziedziczonych po klasie bazowej. Jeżeli więc któreś z nich zostały tam zadeklarowane jako protected , a inne jako public , to prawie zawsze życzymy sobie, aby w klasie pochodnej zachowały te same prawa. Pozostałe dwa kwalifikatory są stosunkowo rzadko stosowane.
class CMojObiekt {
public:
int zmienna_publiczna;
void metoda_publiczna();
protected:
int zmienna_chroniona;
void metoda_chroniona();
private:
int zmienna_prywatna;
void metoda_prywatna();
};
class CMojNastepca : public CMojObiekt {
public:
...
void metoda_publiczna_nastepcy();
protected:
...
private:
void metoda_prywatna_nastepcy();
};
void CMojNastepca::metoda_prywatna_nastepcy {
// tak mozna
zmienna_chroniona = 1;
metoda_chroniona();
// tak natomiast nie da rady
zmienna_prywatna = 1;
metoda_prywatna();
};
void CMojObiekt::metoda_publiczna_nastepcy {
// tak mozna
zmienna_chroniona = 1;
metoda_chroniona();
// tak natomiast nie da rady
zmienna_prywatna = 1;
metoda_prywatna();
};
CMojNastepca mn;
...
// ponizszy kod jest nieprawid³owy
mn.zmienna_chroniona = 1;
mn.metoda_chroniona();
W przypadku dziedziczenia mamy do dyspozycji ten sam mechanizm co w przypadku przestrzeni nazw - czyli przesłanianie. Jeśli w kodzie klasy pochodnej zdefiniujemy pola o tych samych nazwach co już istniejące pola w klasie bazowej - to nie jest błąd. To co się stanie - to stracimy bezpośredni dostęp od pola odziedziczonego (o ile go w ogóle mieliśmy), w to miejsce uzyskując dostęp do nowego pola. Ilustruje to poniższy przykład:
class CBaza {
public:
CBaza() : a(0), b(0), c(0) {};
int a;
void fa() {cout <<"Baza fa: "<< a <<" "<< b <<" "<< c << endl; }
void fb() {cout <<"Baza fb\n";}
protected:
int b;
private:
int c;
};
class CPoch : public CBaza {
public:
CPoch() : a(1), c(1) {};
int a, c;
void fa() {cout <<"Poch fa: "<< a <<" "<< b <<" "<< c << endl; }
void fb(int i) {cout <<"Poch fb\n";}
void fc() { CBaza::fa(); }
};
int main(int argc, char *argv[])
{
CPoch t;
t.fa();
// t.fb();
t.fb(0);
t.fc();
return EXIT_SUCCESS;
}
Dziedziczenie wielokrotne
Skoro możliwe jest dziedziczenie z wykorzystaniem jednej klasy bazowej, to raczej naturalne jest rozszerzenie tego zjawiska także na przypadki, w której z kilku klas bazowych tworzymy jedną klasę pochodną.
Niestety - wiąże się to z problemem, który może się pojawić - tzw problemem diamentu. Problem diamentu dotyczy głównie konfliktów związanych z polami klas bazowych. Przyjrzyjmy się przykładowi, w którym problem diamentu występuje w kontekście pól:
#include "iostream"
class A {
public:
int value;
A() : value(0) {}
};
class B : public A {
public:
// Dziedziczy pole value z klasy A
};
class C : public A {
public:
// Dziedziczy pole value z klasy A
};
class D : public B, public C {
public:
// Dziedziczy pole value z klas B i C, ale także ma własne pole value
};
int main() {
D d;
// Konflikt, ponieważ D dziedziczy pole value z B i C
// d.value = 10; // To spowoduje błąd kompilacji
// Musimy jawnie określić, z której klasy dziedziczone jest pole value
d.B::value = 5;
d.C::value = 7;
// Wartość pola value w klasie D
std::cout << "D.value: " << d.value << std::endl;
return 0;
}
W tym przykładzie klasa `D` dziedziczy zarówno po klasie `B`, jak i `C`, a obie te klasy dziedziczą po klasie `A`. Problem pojawia się, gdy chcemy korzystać z pola value w klasie `D`, ponieważ istnieją dwie kopie tego pola (jedna z klasy `B`, druga z klasy `C`), co powoduje konflikt nazw. A nawet nie tylko konflikt nazw - zazwyczaj w ogóle nie chcemy by klasa `D` Zawierała dwie kopie pól klasy `A`
Aby rozwiązać ten problem, możemy jawnie określić, z której klasy dziedziczone są pola value, używając operatora zakresu. Jednakże, w przypadku bardziej złożonych hierarchii dziedziczenia, zarządzanie takimi konfliktami może stać się bardziej skomplikowane. Wirtualne dziedziczenie może być jednym ze sposobów radzenia sobie z problemem diamentu w kontekście pól.
Ze względu na ten problem zazwyczaj unika się udostępniania wielodziedziczenia, wprowadzając w to miejsce koncepcję interfejsu - czyli w uproszeniu - klasy która nie ma pól, a wszystkie jej metody są czysto wirtualne Jak nie ma pól - nie ma problemu ... Ale C++ jest jednym z niewielu języków, które udostępniają wielodziedziczenie. Nie świadczy to jednak o jego niebotycznej wyższości nad innymi. Tak naprawdę technika dziedziczenia wielokrotnego nie daje żadnych nadzwyczajnych korzyści, a jej użycie jest przy tym dość skomplikowane. Decydując się na jej wykorzystanie należy więc posiadać całkiem spore doświadczenie w programowaniu, choć w niektórych wzorcach programistycznych jej stosowanie jest wskazane.
Może jeszcze przykład bardziej "źyciowy" - mamy pojazd, po którym dziedziczy samochód i łódka, no i chcemy wyprowadzić klasę amfibia

No i pytanie - jaką prędkość ma amfibia? Problem można rozwiązać korzystając z wirtualnego dziedziczenia:
class CPojazd {
public:
CPojazd() {}
protected:
int m_vMax{200};
};
class CSamochod : virtual public CPojazd {
protected:
int m_iloscKol{4};
};
class CLodz : virtual public CPojazd {
protected:
int m_wypornosc{50};
};
class CAmfibia: public CSamochod, public CLodz {
public:
void jedziemy() {
std::cout << "Zasuwam z prędkością " << m_vMax;
}
};
Teraz jest tylko jedno pole m_vMax. Jest jeszcze problem związany z niejednoznacznością inicjacji tego odziedziczonego pola. Załóżmy że mamy konstruktor, który wymaga podania parametru - pytanie, która wersja tego konstruktora będzie wywołana w klasie CAmfibia?
class CPojazd {
public:
CPojazd(int v) : m_vMax(v) {}
protected:
int m_vMax;
};
class CSamochod : virtual public CPojazd {
public:
CSamochod() : CPojazd(200) {}
protected:
int m_iloscKol{4};
};
class CLodz : virtual public CPojazd {
public:
CLodz() : CPojazd(50) {}
protected:
int m_wypornosc{50};
};
class CAmfibia: public CSamochod, public CLodz {
public:
void jedziemy() {
// 200 czy 50?
std::cout << "Zasuwam z prędkością " << m_vMax;
}
};
Ciężko powiedzieć ... a skoro ciężko powiedzieć - to kompilator się podda i oznajmi że w kodzie jest błąd. Należy jawnie pokazać, którą wersję konstruktora klasy bazowej należy wykorzystać:
class CAmfibia: public CSamochod, public CLodz {
public:
CAmfibia() : CPojazd(150) {}
void jedziemy() {
// moje własne - 150
std::cout << "Zasuwam z prędkością " << m_vMax;
}
};
Pułapki dziedziczenia
Pomimo że idea dziedziczenia może wydawać się prosta, w praktyce jej zastosowanie może przynieść pewne trudności. Problemy te są często specyficzne dla konkretnego języka programowania - w naszym podręczniku skupimy się na aspektach związanych z dziedziczeniem w języku C++. Przykłady takich problemów obejmują m.in. zarządzanie pamięcią dla obiektów dziedziczących, rozstrzyganie konfliktów nazw i przysłanianie / polimorfizm (o którym w następnym rozdziale), czy mechanizm wielokrotnego dziedziczenia (omówiony wyżej).
Napisałem wcześniej, że klasa pochodna ma wszystkie składowe klasy z której dziedziczy. W zasadzie jest to prawda, nie wpadnijcie w pułapkę części prywatnej!. To, że klasie pochodnej tracimy dostęp do pewnych pól i metod - wcale nie oznacza że ich nie ma. Oznacza jedynie, że tracimy dostęp. Jeśli pole prywatne ma getter - to możemy jego wartość odczytać poprzez wywołanie gettera. Podobnie pośrednio możemy wywoływać metody prywatne - jeśli skorzystamy z tych metod w klasie bazowej, które prywatne nie są, ale w swojej implementacji wywołują metody prywatne.
Sposób, w jaki C++ realizuje pomysł dziedziczenia, jest sam w sobie dosyć interesujący. Większość programistów na początku całkiem logicznie przypuszcza, że kompilator tworząc obiekt i mapując jego metody, zwyczajnie pobiera deklaracje z klasy bazowej i wstawia je do pochodnej, ewentualne powtórzenia rozwiązując na korzyść tej drugiej.
W rzeczywistości wewnętrznie używana przez kompilator definicja klasy pochodnej jest identyczna z tą, którą wpisujemy do kodu; nie zawiera żadnych pól i metod pochodzących z klas bazowych. Sztuczka polega na budowaniu z klocków - podczas tworzenia obiektu klasy pochodnej tworzony jest także obiektu klasy bazowej - i łączony z obiektem pochodnym. Mają tą samą tożsamość, lecz tworzone są etapami.
W C++ obowiązuje zasada, iż najpierw wywoływany jest konstruktor klasy najwyższej w hierarchii, a potem następne, zgodnie z kolejnością dziedziczenia. Dlatego sam proces budowy obiektu jest wieloetapowy, i po drodze występuje wiele wywołań różnych konstruktorów. To dodatkowo pokazuje, że konstruktor jest specyficzną metodą - nie może być wirtualny, i nie działają na nim mechanizmy przysłaniania.
3.2. Polimorfizm
Podejście do dziedziczenia zaprezentowane w poprzednim rozdziale pozwala nam na uzupełnianie definicji klas bazowych o nowe elementy - w ten sposób tworzymy nowe byty, różniące się od wcześniej zdefiniowanych cechami (polami). Czasem jednak można stwierdzić, że istotą różnicy między dwoma bytami (klasami) jest zmiana zachowania, przykładowo: człowiek to jest taka małpa, która umie mówić. Tą różnicę można zinterpretować na dwa sposoby - w literalnym podejściu zakładamy, że człowiek ma dodatkową metodę - mów - która rozszerza listę metod małpy. Tak więc możemy w dziedziczeniu rozszerzać katalog zachowań obiektów definiując dla nich nowe metody - to też w zasadzie wynika z poprzedniego rozdziału. Możemy także stwierdzić, że dźwięk wydawany przez człowieka to mowa - a w przypadku małpy niekoniecznie. Czyli - mamy tą samą metodę (dajGłos), która ma inną implementację (inne działanie) u różnych klas. Taką sytuację nazywa się polimorfizmem:
Ktoś kto korzysta z obiektu klasy człowiek czy też małpa – nie musi wiedzieć którego typu jest dany osobnik by zmusić go do wydania głosu – wystarczy że wie że osobnik wydaje głosy. Wywołaniem odpowiedniej wersji metody zajmie się kompilator.
class CMalpa {
public:
virtual void dajGlos() {
cout << "Hyyyhmyyym\n";
}
};
class CCzlowiek : public CMalpa {
public:
virtual void dajGlos() {
cout << "Auuu, boli\n";
}
};
int main(int argc, char *argv[])
{
CMalpa m;
CCzlowiek c;
CMalpa *cm;
m.dajGlos();
c.dajGlos();
cm = &m;
cm->dajGlos();
cm = &c;
cm->dajGlos();
}
Technicznie - zachowania polimorficzne w C++ mogą, ale nie muszą wystąpić. Wcześniej omawialiśmy mechanizm przesłaniania nazw (pól, ale też metod). Jeśli z powyższego kodu usunęlibyście wystąpienia słowa virtual zamiast polimorfizmu wprowadzilibyśmy właśnie przesłanianie. Wtedy, w powyższym kodzie każde odwołanie przez wskaźnik na małpę (cm) będzie powodowało wywołanie metody dla małpy.
Jeśli w definicji klasy użyjecie słowa virtual - to obsługa takiej metody zmieni się. W miejsce bezpośredniego wywołania zostanie przeszukana tablica funkcji wirtualnych przynależąca do danego obiektu – i wyszukana wersja najbliższa w hierarchii dziedziczenia. Przy czym - co stanowi clou polimorfizmu - nie jest istotne poprzez wskaźnik na który z typów bazowych odwołujemy się do danego obiektu - wersja metody wirtualnej, która zostanie wywołana - jest determinowana tożsamością obiektu.
Technikalia implementacji polimorfizmu w C++ są następujące: Po pierwsze - nie może zmieniać się liczba parametrów (sygnatura) metody wirtualnej. Po drugie - metoda zaczyna zachowywać się jak wirtualna w momencie pierwszego pojawienia się słowa virtual. Zachowanie wirtualne dla metody już zdefiniowanej jako wirtualna trwa - i nie zmienia tego fakt występowania (lub nie występowania) słowa virtual w kolejnych definicjach metod w klasach pochodnych. Rodzaj dziedziczenia nie wpływa na zachowanie się funkcji wirtualnych (zmienia się jedynie zasięg ich widoczności). No i na koniec – metody statyczne nie mogą być wirtualne (metoda statyczna może zostać wywołana bez obiektu - vide nie ma tożsamości, i nie ma na jakiej podstawie podjąć decyzji o wersji metody do wywołania).
Przykład jak to działa w praktyce?
#include <iostream>
class A {
public:
virtual void f1() { std::cout << "A f1\n"; }
void f2() { std::cout << "A f2\n"; }
};
class B : public A {
public:
void f1() { std::cout << "B f1\n"; }
virtual void f2() { std::cout << "B f2\n"; }
};
class C : public B {
public:
void f1() { std::cout << "C f1\n"; }
virtual void f2() { std::cout << "C f2\n"; }
};
int main(int argc, char *argv[]) {
A a; B b; C c;
A* pab, *pac;
B* pbc;
pab = &b;
pac = &c;
pbc = &c;
std::cout << "Klasa A:\n";
a.f1();
a.f2();
std::cout << "Klasa B:\n";
b.f1();
b.f2();
std::cout << "Klasa B jako A:\n";
pab->f1();
pab->f2();
std::cout << "Klasa C:\n";
c.f1();
c.f2();
std::cout << "Klasa C jako A:\n";
pac->f1();
pac->f2();
std::cout << "Klasa C jako B:\n";
pbc->f1();
pbc->f2();
return 0;
}
Jak widzicie, metoda f2 nie zawsze jest wirtualna - metoda f1 zawsze będzie. Ponieważ zachowanie takie potrafi być nieczytelne - w prawdziwych aplikacjach rzadko definiujemy klasy bezpośrednio jedna pod drugą, więc łatwo się pogubić które metody są wirtualne a które nie - to C++ pozwala nam na opcjonalne jawne wyrażenie chęci nadpisania metody. Jest nią słowo kluczowe override - jeśli zamieścimy je na końcu jej deklaracji, to kompilator sprawdzi, czy metoda jest gdzieś wcześniej w hierarchii oznaczona jako wirtualna, i - jeśli nie - zgłosi błąd. Gorąco zachęcam Was do stosowania override we własnych kodach.
Drugim potencjalnym ułatwieniem jest słowo kluczowe final - które mówi nam, że dana metoda już osiągnęła doskonałość, i nie może być dalej nadpisywana ani przysłaniana. Próba redefinicji metody oznaczonej jako final w klasie pochodnej spowoduje błąd kompilacji.
Popatrzcie na wcześniejszy przykład, uzupełniony o override i final, oraz - dla przykładu - z zamienionym stosowaniem wskaźników na referencję.
#include <iostream>
class A {
public:
virtual void f1() { std::cout << "A f1\n"; }
void f2() { std::cout << "A f2\n"; }
virtual void f3() { std::cout << "A f3\n"; }
};
class B : public A {
public:
void f1() override { std::cout << "B f1\n"; }
virtual void f2() { std::cout << "B f2\n"; }
void f3() override final { std::cout << "A f3\n"; }
};
class C : public B {
public:
void f1() override { std::cout << "C f1\n"; }
void f2() override { std::cout << "C f2\n"; }
// próba redefinicji f3 skończy się błędem:
// void f3() override {}
};
int main(int argc, char *argv[]) {
A a; B b; C c;
A& ab{b};
A& ac{c};
B& bc{c};
std::cout << "Klasa A:\n";
a.f1();
a.f2();
std::cout << "Klasa B:\n";
b.f1();
b.f2();
std::cout << "Klasa B jako A:\n";
ab.f1();
ab.f2();
std::cout << "Klasa C:\n";
c.f1();
c.f2();
std::cout << "Klasa C jako A:\n";
ac.f1();
ac.f2();
std::cout << "Klasa C jako B:\n";
bc.f1();
bc.f2();
return 0;
}
Metody wirtualne mogą być wywoływane także bezpośrednio w implementacji innych metod w klasach bazowych – zostanie wtedy automatycznie wybrana odpowiednia wersja danej metody, odpowiadająca tożsamości obiektu wywołującego. W ten sposób możemy wykorzystywać przy tworzeniu kodu zachowanie jeszcze niezdefiniowane, i zależne od typu obiektu z którym pracujemy. Przykładowo - możemy wykorzystać fakt, że można narysować figurę, mimo że nie wiemy jeszcze jak:
class CFigura {
public:
virtual void rysuj() { }
void przesun(int _x, int _y) {
m_x = _x;
m_y = _y;
rysuj();
};
private:
int m_x{0};
int m_y{0};
};
class CKolo :public CFigura {
public:
virtual void rysuj() {
// kod rysowania
}
};
Jawne wywołanie metody bazowej w określonej wersji jest możliwe poprzez podanie poprzedzonej dwukropkiem nazwy jej klasy. Nie ma w C++ możliwości niejawnego wywołania odziedziczonej instancji. Ogólnie – zasięg widoczności poszczególnych pól i metod w klasach może być traktowany jako zagnieżdżony z punktu widzenia dziedziczenia:
class A {
public:
virtual void f() { cout << "A f1\n"; }
};
class B : public A {
public:
void f() override {
A::f();
cout << "B f1\n";
}
};
class C : public B {
public:
void f() override {
A::f();
B::f();
cout << "C f1\n";
}
};
3.3. Abstrakcje / interfejsy
Metoda zadeklarowana w klasie jako wirtualna, która nie ma definicji – jest metodą abstrakcyjną. W C++ oznaczamy ten fakt pisząc =0 po deklaracji metody. Klasa która ma choć jedną metodę abstrakcyjną – jest klasą abstrakcyjną. Nie można tworzyć obiektów typu klas abstrakcyjnych. Klasa która ma wszystkie metody abstrakcyjne i nie posiada pól – jest interfejsem.
W praktyce stosuje się często jako interfejsy klasy, które zawierają kilka metod z implementacjami. Jednakże, te metody, które mają być częścią interfejsu, powinny być oznaczone jako czysto wirtualne. Dodatkowo - by być zgodnym z semantycznym znaczeniem interfejsu - klasa taka nie powinna mieć pól.
class CFiguraBaza {
public:
virtual void rysuj() = 0;
};
class CFigura : public CFiguraBaza {
public:
void przesun(int _x, int _y) {
m_x = _x;
m_y = _y;
rysuj();
};
private:
int m_x;
int m_y;
};
class CKolo :public CFigura {
public:
virtual void rysuj() {
// kod rysowania
}
};
Zmodyfikowany przykład dziedziczenia figur, z uwzględnioną koncepcją interfejsu możecie zobaczyć poniżej:
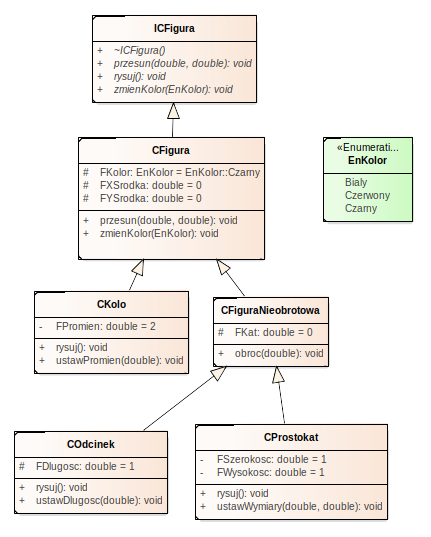
Wprowadzenie tutaj koncepcji interfejsów ściśle wiąże się z pojęciem typów abstrakcyjnych. Typy abstrakcyjne w założeniu mają izolować użytkownika od ich implementacji. Z typów abstrakcyjnych korzystamy tylko przez referencje / wskaźniki. Nie można tworzyć bezpośrednio obiektów typów abstrakcyjnych - próba utworzenia instancji ICFigura albo CFiguraBaza zakończy się błędem kompilacji. Typy takie możemy tworzyć jedynie jako typy konkretne - i potem przekazywać interfejsy do nich.
Typowa klasa abstrakcyjna zazwyczaj nie ma konstruktora - bo i tak nie ma pól do inicjowania. Natomiast prawie zawsze powinna mieć wirtualny destruktor - dzięki czemu kasowanie obiektu przy wykorzystaniu wskaźnika na klasę bazową i tak spowoduje wywołanie odpowiedniej postaci destruktora.
Nie da się także ich prosto kopiować ani klonować.
Klonowanie obiektów
W przypadku obiektów będących w hierarchii dziedziczenia, kopiowanie ich nie da się prosto wykonać korzystając jedynie z mechanizmów polimorfizmu – przecież konstruktor nie jest wirtualny i nie jest dziedziczony. Dlatego też rozwiązanie poniżej raczej nie zadziała:
class A {
public:
A() {};
A(const A& _s) { };
virtual void f() {
cout<<"A nadaje\n";
}
};
class B : public A {
public:
B() {};
B(const B& _s) : A(_s) { };
virtual void f() {
cout<<"B nadaje\n";
}
};
int main(int argc, char *argv[])
{
B *b = new B;
A *a1 = b;
A *a2 = new A(*a1);
//A *a3 = new B(*a1);
a1->f();
a2->f();
}
Możecie sami się przekonać, uruchamiając powyższy przykład. Mimo że a2 zostało utworzone jako kopia a1 – które jest typu B, to i tak wywołany został konstruktor A, a nie B. Jeśli znamy typ obiektu pochodnego przed kopiowaniem – to możemy jawnie wywołać konstruktor B. Ale przecież cała zabawa z polimorfizmem polega na tym, by móc korzystać z obiektu jedynie w oparciu o jego interfejs – a więc nie znając docelowego typu obiektu. Czy da się kopiować elementy w taki sposób? Da ... wystarczy odpowiednio wykorzystać mechanizm funkcji wirtualnych.
class A {
public:
A() { };
A(const A& _s) {};
virtual void f() { cout<<"A " << FMyNum << " nadaje\n"; }
virtual A* clone() { return new A(*this); };
protected:
static int m_cnt;
int m_myNum;
};
int A::m_cnt = 0;
class B : public A {
public:
B() {};
B(const B& _s) : A(_s) { };
virtual void f() { cout<<"B " << FMyNum << " nadaje\n"; }
virtual A* clone() { return new B(*this); };
};
int main(int argc, char *argv[])
{
B *b = new B;
A *a1 = b;
A *a2 = new A(*a1);
A *a4 = a1->clone();
a1->f();
a2->f();
a4->f();
}
Kod powyżej jest jeszcze uzupełniony o dodatkową informację – wykorzystując pole statyczne, zliczamy wszystkie egzemplarze danej klasy.
Ogólnie - z pojęciem tworzenia instancji typów abstrakcyjnych jest związane kilka wzorców programistycznych, z fabryką abstrakcyjną na czele.
3.4. Hierarchia klas
Dzięki hierarchii można zapisać w kodzie hierarchiczne zależności między bytami. Typowe przykłady już widzieliście wcześniej: "Prostokąt jest rodzajem figury nieobrotowej, która jest rodzajem figury", czy też „Wóz strażacki jest rodzajem ciężarówki, która jest rodzajem pojazdu”. Realnie spotykane hierarchie są ogromne, i rozbudowane zarówno wszerz (wiele typów na tym samym poziomie), jak i w głąb (wiele poziomów dziedziczenia).
Jeśli budujecie własną hierarchię - często na jej szczycie warto umieścić interfejsy - ułatwi to minimalizację zależności między korzystającymi z obiektów w hierarchii a ich implementacją.
W zasadzie w dobrze zaprojektowanych hierarchiach rzadko spotyka się sytuacje, w których chcemy poznać rzeczywisty typ wskazywanego obiektu. Czasem jest to jednak konieczne. Popatrzcie raz jeszcze na przykład figur z poprzedniego rozdziału. Jeśli chcielibyśmy obrócić figurę, korzystając ze wskaźnika na klasę bazową, to nie mamy takiej możliwości:
void przesunIObroc(ICFigura* co, int gdzieX, int gdzieY, int oIle) {
co->przesun(gdzieX, gdzieY);
// nie da się wywołać obróć - nie ma takiej metody w def. interfejsu
// co->obroc(oIle);
}
Możemy natomiast zauważyć, że obracanie figury obrotowej nie ma większego sensu - o ile byśmy jej nie obrócili, i tak będzie wyglądała tak samo. Więc - implementacja tej metody ma sens, jeśli jesteśmy w stanie sprawdzić, czy co wskazuje na CFiguraNieobrotowa lub jej pochodną. Możemy to zrobić korzystając z dynamic_cast:
void przesunIObroc(ICFigura* co, int gdzieX, int gdzieY, int oIle) {
co->przesun(gdzieX, gdzieY);
// nie da się wywołać obróć - nie ma takiej metody w def. interfejsu
if (auto nco=dynamic_cast<CFiguraNieobrotowa*>(co)) {
// tu już wiemy że jest to figura nieobrotowa
nco->obroc(oIle);
}
}
Operator rzutowania dynamic_cast sprawdza, czy dany obiekt jest jednocześnie obiektem typu na który rzutujemy, i - jeśli tak, zwraca wskaźnik na ten obiekt. Jeśli nie jest - zwraca wartość nullptr.
W przypadku chęci wykorzystania dynamic_cast do uzyskania referencji do obiektu - to także jest możliwe - tyle że w tym wypadku nie bardzo wiadomo jak odebrać informację o tym że rzutowanie nie powiodło się. C++ w takim wypadku rzuci wyjątek:
CKolo k;
// poniższa linijka rzuci wyjątek std::bad_cast
CFiguraNieobrotowa& f = dynamic_cast<CFiguraNieobrotowa&>(k);
Tyle że przekazywanie informacji w normalnym toku wykonania przez wyjątki nie powinno następować - dlatego też nie jest to przykład sensownego wykorzystania rzutowania na referencję
Przechowywanie obiektów z hierarchii w kontenerach STL
Pozostało mi w tym rozdziale zwrócić Wam uwagę na jeszcze jeden szczegół. Mamy pewien problem. Skoro z jednej strony typów abstrakcyjnych nie powinienem bezpośrednio kopiować (bo kopia może być niepełna), a z drugiej strony - kontenery STL przejmują obiekty na własność, a więc wykonują albo kopię, albo przeniesienie obiektu do kontenera - to jak umieszczać niejednorodny typ bazowy w kontenerze?
Rozwiązania są dwa. Mało eleganckie jest umieszczanie w kontenerze wskaźników na typ bazowy:
std::vector<ICFigura*> figury;
Wadą takiego podejścia jest konieczność ręcznego usuwania obiektów, które są usuwane z wektora. Łatwo się pomylić, i łatwo doprowadzić do wycieków pamięci. Lepsze jest stosowanie inteligentnych wskaźników:
std::vector<std::unique_ptr<ICFigura> > figury;
teraz - po usunięciu obiektu z wektora, zostanie on także skasowany.