Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | 3. Szablony |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | piątek, 9 stycznia 2026, 03:28 |
1. Algorytmy uogólnione
Zaczynamy omawiać nowy paradygmat programowania - programowanie generyczne (uogólnione), gdzie typ danych może być wykorzystany jako parametr. Do wsparcia programowania generycznego w C++ przeznaczono szablony. Język C++ ma silną kontrolę typów - a więc wymaga, aby wszystkie zmienne miały określony typ, jawnie zadeklarowany przez programistę lub wydedukowany przez kompilator. Jednak wiele struktur danych i algorytmów wygląda tak samo niezależnie od typu, na jakim działają. Szablony umożliwiają zdefiniowanie operacji klasy lub funkcji i umożliwienie użytkownikowi określenia konkretnych typów, na których te operacje powinny działać.
1.1. Funkcje uogólnione bez szablonów
W praktyce programowania często spotykamy się z funkcjami (algorytmami), które można zastosować do szerokiej klasy typów i struktur danych. Typowym przykładem jest funkcja obliczająca maksimum dwu wartości. Ten trywialny, aczkolwiek przydatny kod można zapisać np. w postaci:
int max(int a,int b) {
return (a>b)?a:b;
};
Funkcja max wybiera większy z dwu int-ów, ale widać, że kod będzie identyczny dla argumentów dowolnego innego typu pod warunkiem, iż istnieje dla niego operator porównania i konstruktor kopiujący. W językach programowania z silną kontrolą typów, takich jak C, C++ czy Java definiując funkcję musimy jednak podać typy przekazywanych parametrów oraz typ wartości zwracanej. Oznacza to, że dla każdego typu argumentów musimy definiować nową funkcję max:
int max(int a, int b) {return (a>b)?a:b;};
double max(double a,double b) {return (a>b)?a:b;};
string max(string a,string b) {return (a>b)?a:b;};
// skorzystaliśmy tu z dostępnej w C++ możliwości przeładowywania funkcji
main() {
cout<< max(7,5)<< end;
cout<< max(3.1415,2.71)<< endl;
cout<< max("Ania","Basia")<< endl;
}
Takie powtarzanie kodu, poza oczywistym zwiększeniem nakładu pracy, ma inne niepożądane efekty, związane z trudnością zapewnienia synchronizacji kodu każdej z funkcji. Jeśli np. zauważymy błąd w kodzie, to musimy go poprawić w kilku miejscach. To samo dotyczy optymalizacji kodu. W powyższym przykładzie kod jest wyjątkowo prosty, ale nie jest trudno znaleźć przykłady, gdzie już taki prosty nie będzie.
Funkcje uogólnione bez szablonów
Jak radzili, a właściwie jak radzą sobie programiści bez możliwości skorzystania z szablonów? Tradycyjne sposoby rozwiązywania tego typu problemów to między innymi makra lub używanie wskaźników typów ogólnych, takich jak void *, jak np. w funkcji qsort ze standardowej biblioteki C:
#define max(a,b) ( (a>b)?a:b) )
void qsort(void *base, size_t nmemb, size_t size,
int(*compar)(const void *, const void *));
Mimo iż użyteczne, żadne z tych rozwiązań nie może zostać uznane za wystarczająco ogólne i bezpieczne.
Stosowanie makr sprowadza się w dużej mierze do prostego mechanizmu "znajdź i zamień" - ze wszelkimi tego konsekwencjami, w tym niedostrzegalnym na pierwszy rzut oka problemem z priorytetami operatorów. Popatrzcie na poniższy przykład:
#define SQR(a) a*a
int y = SQR(x+2); // tzn x+2*x+2 !!!
Stosowanie rzutowania na void jest rozwiązaniem lepszym - ale tylko odrobinę. Zobaczcie że nawet w przykładzie qsort - zupełnie niepotrzebnie przekazuję pewne informacje (jak porównać dwie liczby, jaki jest rozmiar elementu tablicy, ile tablica ma elementów). No i pozbawiam się wsparcia ze strony kompilatora / środowiska w kontroli poprawności typów, argumentów, ip... ,
Można się również pokusić o próbę rozwiązania tego problemu za pomocą mechanizmów programowania obiektowego. W sumie jest to bardziej wyrafinowana odmiana rzutowania na void *. Polega na zdefiniowaniu ogólnego typu dla obiektów, które mogą być porównywane, i następnie korzystanie z obiektów pochodnych do nich.
class GreaterThenComparable {
public:
virtual bool operator>( const GreaterThenComparable &b) const = 0;
} ;
const GreaterThenComparable &max(const GreaterThenComparable &a,
const GreaterThenComparable &b) {
return (a>b)? a:b;
}
class Int:public GreaterThenComparable {
int val;
public:
Int(int i = 0):val(i){};
operator int() {return val;};
virtual bool operator>(const GreaterThenComparable &b) const {
return val > static_cast< const Int& >(b).val;}
};
main() {
Int a(3),b(2);
Int c;
c = (const Int &)::max(a,b);
cout<< (int)c << endl;
}
Widać więc wyraźnie, że to podejście wymaga sporego nakładu pracy, a więc w szczególności w przypadku tak prostej funkcji jak max jest wysoce niepraktyczne. Ogólnie rzecz biorąc ma ono następujące wady:
- Wymaga dziedziczenia z abstrakcyjnej klasy bazowej GreaterThanComparable, czyli może być zastosowane tylko do typów zdefiniowanych przez nas. Inne typy, w tym typy wbudowane, wymagają kopertowania w klasie opakowującej, takiej jak klasa Int w powyższym przykładzie.
- Ponieważ potrzebujemy polimorfizmu funkcja operator>() musi być funkcją wirtualną, a więc musi być funkcją składową klasy i nie może być typu inline. W przypadku tak prostych funkcji niemożność rozwinięcia ich w miejscu wywołania może prowadzić do dużych narzutów w czasie wykonania.
- Funkcja max zwraca zawsze referencje do GreaterThanComparable, więc konieczne jest rzutowanie na typ wynikowy (tu Int).
1.2. Szablony funkcji
Widać, że podejście obiektowe nie nadaje się najlepiej do rozwiązywania tego szczególnego problemu powielania kodu. Dlatego w C++ wprowadzono nowy mechanizm: szablony. Szablony zezwalają na definiowanie całych rodzin funkcji, które następnie mogą być używane dla różnych typów argumentów. Definicja szablonu funkcji max wygląda następująco:
template<typename T> T max(T a,T b) {return (a>b)?a:b;};
Przyjrzyjmy się bliżej temu zagadnieniu. Wyrażenie template < typename T > wskazuje na obecność szablonu, który posiada jeden parametr formalny nazwany T. Użycie słowa kluczowego `typename` oznacza, że ten parametr reprezentuje typ (nazwę typu). Alternatywnie, można użyć słowa kluczowego `class` zamiast `typename`. Nazwa tego parametru może być później wykorzystywana w definicji funkcji w miejscach, gdzie oczekiwane jest podanie nazwy typu.
Przedstawione wyrażenie definiuje funkcję `max`, która przyjmuje dwa argumenty typu T i zwraca wartość typu T, będącą większą z dwóch podanych wartości. Typ T jest obecnie nieokreślony, co oznacza, że ten szablon definiuje całą rodzinę funkcji. Wybieramy konkretną funkcję z tej rodziny, podstawiając konkretne typy jako argumenty szablonu. Ten proces nazywamy konkretyzacją szablonu. Argumenty szablonu umieszczamy w nawiasach ostrych za nazwą szablonu (w praktyce można uniknąć konieczności jawnej specyfikacji argumentów szablonu, opiszę to później).
int i,j,k;
k=max<int>(i,j);
Takie użycie szablonu spowoduje wygenerowanie identycznej funkcji jak pisana wcześniej. W powyższym przypadku za T podstawiamy int. Oczywiście możemy podstawić za T dowolny typ i używając szablonów program można zapisać następująco:
template<typename T> T max(T a,T b) {return (a>b)?a:b;}
main() {
cout<<::max<int>(7,5) << endl;
cout<<::max<double>(3.1415,2.71) << endl;
cout<<::max<string>("Ania","Basia") << endl;
}
W powyższym kodzie użyliśmy konstrukcji ::max(a,b). Dwa dwukropki oznaczają, że używamy funkcji max zdefiniowanej w ogólnej przestrzeni nazw. Jest to konieczne aby kod się skompilował, ponieważ szablon max istnieje już w standardowej przestrzeni nazw std. W dalszej części wykładu będę te podwójne dwukropki pomijać.
Oczywiście istnieją typy których podstawienie spowoduje błędy kompilacji, np.
complex<double> c1,c2;
max<complex<double> >(c1,c2); //brak operatora >
class X {
private:
X(const X &){};
};
X a,b;
max<X>(a,b); //prywatny (niewidoczny) konstruktor kopiujący
Ogólnie rzecz biorąc, każdy szablon definiuje pewną klasę typów, które mogą zostać podstawione jako jego argumenty.
Dedukcja argumentów szablonu
Użyteczność szablonów funkcji zwiększa istotnie fakt, że argumenty szablonu nie muszą być podawane jawnie. Kompilator może je wydedukować z argumentów funkcji. Tak więc zamiast kodu jawnie specyfikującego typ dla funkcji max, można napisać;
int i,j,k;
k=max(i,j);
i kompilator zauważy, że tylko podstawienie int-a za T umożliwi dopasowanie sygnatury funkcji do parametrów jej wywołania i automatycznie dokona odpowiedniej konkretyzacji. Może się zdarzyć, że podamy takie argumenty funkcji, że dopasowanie argumentów wzorca będzie niemożliwe, otrzymamy wtedy błąd kompilacji. Trzeba pamiętać, że mechanizm automatycznego dopasowywania argumentów szablonu powoduje wyłączenie automatycznej konwersji argumentów funkcji. Podanie jawnie argumentów szablonu (w nawiasach ostrych za nazwą szablonu) jednoznacznie określa sygnaturę funkcji, a więc umożliwia automatyczną konwersję typów. Ilustruje to poniższy kod:
template<typename T> T max(T a,T b) {return (a>b)?a:b;}
main() {
cout<<::max(3.14,2)<<endl;
// błąd: kompilator nie jest w stanie wydedukowac argumentu szablonu, bo typy
// argumentów (double,int) nie pasują do (T,T)
cout<<::max<int>(3.14,2)<<endl;
// podając argument jawnie wymuszamy sygnaturę int max(int,int), a co za tym
// idzie automatyczną konwersję argumentu 1 do int-a
cout<<::max<double>(3.14,2)<<endl;
// podając argument szablonu jawnie wymuszamy sygnaturę
// double max(double,double)
// a co za tym idzie automatyczną konwersję argumentu 2 do double-a
int i;
cout<<::max<int *>(&i,i)<<endl;
//błąd: nie istnieje konwersja z typu int na int*
}
Warto zaznaczyć, że automatyczna dedukcja parametrów szablonu jest możliwa tylko w przypadku, gdy parametry wywołania funkcji w pewien sposób zależą od parametrów szablonu. Jeżeli brak tej zależności, dedukcja nie jest możliwa z oczywistych powodów, co zmusza do jawnego podawania parametrów. W takim przypadku istotna jest również kolejność parametrów na liście. Umieszczenie parametrów, które nie mogą zostać wydedukowane, jako pierwszych, pozwala jedynie na ich jawną specyfikację, pozostawiając resztę do automatycznej dedukcji przez kompilator. Poniższy kod ilustruje tę koncepcję:
template<typename T,typename U> T convert(U u) {
return (T)u;
};
template<typename U,typename T> T inv_convert(U u) {
return (T)u;
};
// fukcje różnią się tylko kolejnością parametrów szablonu
main() {
cout<<convert(33)<<endl;
// błąd: kompilator nie jest w stanie wydedukować pierwszego parametru
// szablonu, bo nie zależy on od parametru wywołania funkcji
cout<<convert<char>(33)<<endl;
// w porządku: podajemy jawnie argument T, kompilator sam dedukuje
// argument U z typu argumentu wywołania funkcji
cout<<inv_convert<char>('a')<<endl;
// błąd: podajemy jawnie argument odpowiadający parametrowi U.
// Kompilator nie jest w stanie wydedukować argumentu T, bo nie zależy on od argumentu
// wywołania funkcji
cout<<inv_convert<int,char>(33)<<endl;
// w porządku: podajemy jawnie oba argumenty szablonu
}
Korzystanie z szablonów
Z użyciem szablonów wiąże się parę zagadnień niewidocznych w prostych przykładach. W językach C i C++ zwykle rozdzielamy deklarację funkcji od jej definicji i zwyczajowo umieszczamy deklarację w plikach nagłówkowych *.h, a definicję w plikach źródłowych *.c, *.cpp itp. Pliki nagłówkowe są w czasie kompilacji włączane do plików, w których chcemy korzystać z danej funkcji, a pliki źródłowe są pojedynczo kompilowane do plików “obiektowych” *.o. Następnie pliki obiektowe są łączone w jeden plik wynikowy (zob. rysunek 1.1). W pliku korzystającym z danej funkcji nie musimy więc znać jej definicji, a tylko deklarację. Na podstawie nazwy funkcji konsolidator powiąże wywołanie funkcji z jej implementacją znajdującą się w innym pliku obiektowym. W ten sposób tylko zmiana deklaracji funkcji wymaga rekompilacji plików, w których z niej korzystamy, a zmiana definicji wymaga jedynie rekompilacji pliku, w którym dana funkcja jest zdefiniowana. Zobaczcie na poniższą ilustrację, pochodzącą z http://wazniak.mimuw.edu.pl
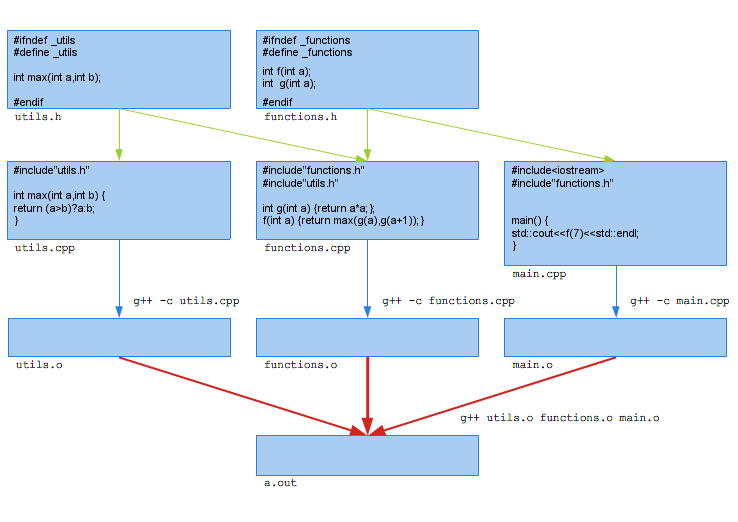
organizacja umożliwia przestrzeganie "reguły jednej definicji" (one definition rule), wymaganej przez C++. To po to w nagłówkach pojawia się fragment uniemożliwiający podwójne włączenie tego pliku do jednej jednostki translacyjnej:
#ifndef _nazwa_pliku_
#define _nazwa_pliku_
...
#endif
W nowszych kompilatorach, można wykorzystać prostszą i krótszą dyrektywę once
#pragma once
...
Podobne podejście do kompilacje szablonów się nie powiedzie. Powodem jest fakt, że w trakcie kompilacji pliku utils.cpp kompilator nie wie jeszcze, że potrzebna będzie funkcja max<int>, wobec czego nie generuje kodu żadnej funkcji, a jedynie sprawdza poprawność gramatyczną szablonu. Z kolei podczas kompilacji pliku main.cpp kompilator już wie, że ma skonkretyzować szablon dla T = int, ale nie ma dostępu do kodu szablonu.
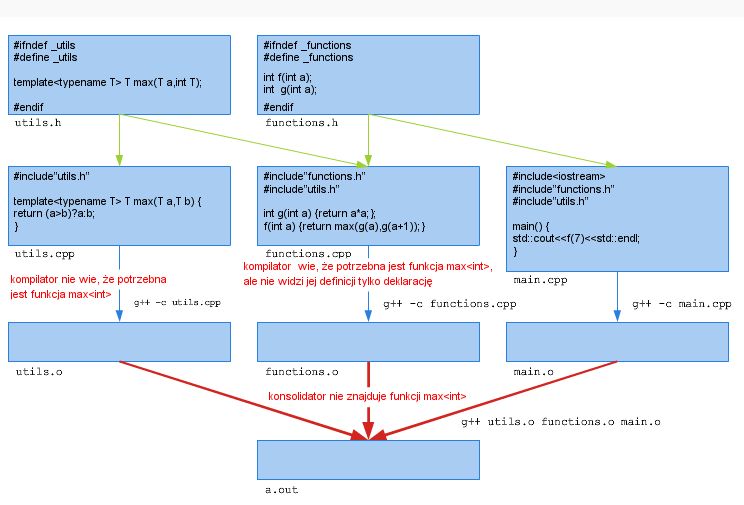
Istnieją różne rozwiązania tego problemu. Najprościej chyba jest zauważyć, że opisane zachowanie jest analogiczne do zachowania podczas kompilacji funkcji rozwijanych w miejscu wywołania (inline), których definicja również musi być dostępna w czasie kompilacji. Podobnie więc jak w tym przypadku możemy zamieścić wszystkie deklaracje i definicje szablonów w pliku nagłówkowym, włączanym do plików, w których z tych szablonów korzystamy. Podobnie jak w przypadku funkcji inline reguła jednej definicji zezwala na powtarzanie definicji/deklaracji szablonów w różnych jednostkach translacyjnych, pod warunkiem, że są one identyczne. Stąd konieczność umieszczania ich w plikach nagłówkowych.
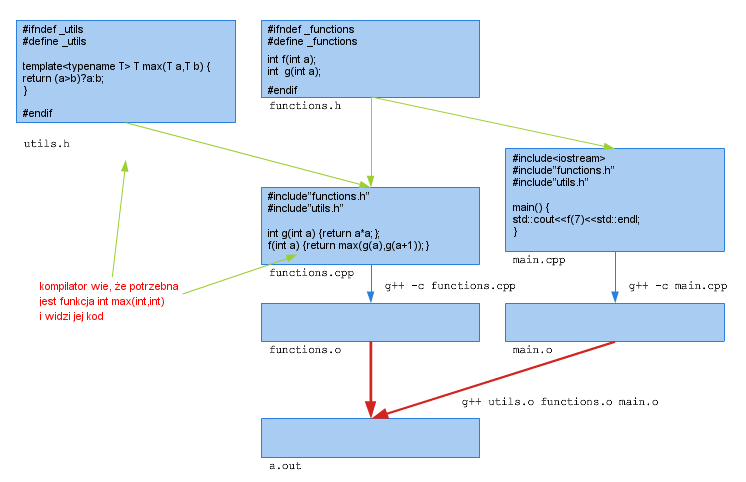
Ten sposób organizacji pracy z szablonami, nazywany modelem włączenia, jest najbardziej uniwersalny. Jego główną wadą jest konieczność rekompilacji całego kodu korzystającego z szablonów przy każdej zmianie definicji szablonu. Również jeśli zmienimy coś w pliku, w którym korzystamy z szablonu, to musimy rekompilować cały kod szablonu włączony do tego pliku, nawet jeśli nie uległ on zmianie. Jeśli się uwzględni fakt, że kompilacja szablonu jest bardziej skomplikowana od kompilacji "zwykłego" kodu, to duży projekt intensywnie korzystający z szablonów może wymagać bardzo długich czasów kompilacji.
Możemy też w jakiś sposób dać znać kompilatorowi, że podczas kompilacji pliku utils.cpp powinien wygenerować kod dla funkcji max<int>. Można to zrobić dodając jawne żądanie konkretyzacji szablonu.
template<typename T> T max(T a,T b) {return (a>b)?a:b;}
template int max<int>(int ,int) ; // konkretyzacja jawna
Używając konkretyzacji jawnej musimy pamiętać o dokonaniu konkretyzacji każdej używanej funkcji, tak że to podejście nie skaluje się zbyt dobrze. Ponadto w przypadku szablonów klas (omawianych w następnym rozdziale) konkretyzacja jawna pociąga za sobą konkretyzację wszystkich metod danej klasy, a konkretyzacja “na żądanie” - jedynie tych używanych w programie.
Pozatypowe parametry szablonów
Poza parametrami określającymi typ, takimi jak parametr T w dotychczasowych przykładach, szablony funkcji mogą przyjmować również parametry innego rodzaju. Obecnie mogą to być inne szablony, co omówię w następnym podrozdziale lub parametry określające nie typ, ale wartości. Jak na razie (w obecnym standardzie) te wartości nie mogą być dowolne, ale muszą mieć jeden z poniższych typów:
- typ całkowitoliczbowy bądź typ wyliczeniowy
- typ wskaźnikowy
- typ referencyjny.
Takie parametry określające wartość nazywamy parametrami pozatypowymi. W praktyce z parametrów pozatypowych najczęściej używa się parametrów typu całkowitoliczbowego. Np.
template<size_t N,typename T> T dot_product(T *a,T *b) {
T total=0.0;
for(size_t i=0;i<N;++i)
total += a[i]*b[i] ;
return total;
};
int main() {
double x[3],y[3];
dot_product<3>(x,y);
}
Podkreślam ponownie znaczenie kolejności parametrów szablonu na liście. Poprzez umieszczenie niededukowalnego parametru N na pierwszym miejscu, wystarczy jedynie jawnie podać wartość tego parametru, a drugi parametr typu T zostanie automatycznie wydedukowany na podstawie przekazanych argumentów wywołania funkcji.
Pozatypowe parametry są zazwyczaj trudniejsze do automatycznej dedukcji. W rzeczywistości, jedynym sposobem przekazania wartości stałej poprzez argument typu jest skorzystanie z parametrów będących szablonami klas.
W przypadku używania pozatypowych parametrów szablonów, istotne jest pamiętanie, że odpowiadające im argumenty muszą być stałymi wyrażeniami czasu kompilacji. Dlatego, jeśli korzystamy z typów wskaźnikowych, muszą to być wskaźniki do obiektów łączonych zewnętrznie, a nie lokalnych. Warto jednak zauważyć, że autor nie przedstawił jeszcze żadnych przykładów użycia pozatypowych parametrów szablonów, poza typami całkowitymi, na tym etapie wykładu.
Szablony parametrów szablonu
Parametrami szablonu funkcji mogą być również szablony klas (za chwilę o nich poczytacie). Szablony parametrów szablonu, znane również jako "szablony szablonów" (template template parameters), pozwalają przekazywać same szablony jako argumenty do innych szablonów funkcji. Oznacza to, że zamiast przekazywać konkretny typ do szablonu funkcji, możemy przekazać inny szablon jako argument. Więcej o nich napiszę podczas omawiania szablonów klas. Tutaj tylko pokażę jako ciekawostkę w jaki sposób można dedukować wartości pozatypowych argumentów szablonu:
template< template<int N> class C,int K>
/* taka definicja oznacza, że parametr C określa szablon klasy
posiadający jeden parametr typu int. Parametr N służy tylko
do definicji szablonu C i nie może być użyty nigdzie indziej */
void f(C<K>){
cout<<K<<endl;
};
template<int N> struct SomeClass {};
main() {
SomeClass<1> c1;
SomeClass<2> c2;
f(c1); C=SomeClass K=1
f(c2); C=SomeClass K=2
}
2. Szablony klas
Uwagi na początku poprzedniego rozdziału odnoszą się w tej samej mierze do klas, jak i do funkcji. I tutaj mamy do czynienia z kodem, który w niezmienionej postaci musimy powielać dla różnych typów.
Dlatego też - oprócz uogólnionych algorytmów (szablonów funkcji) - mamy także uogólnione klasy (szablony klas). Są one nawet popularniejsze, i częściej spotykane niż funkcje uogólnione, choćby ze względu na popularność kontenerów biblioteki STL.
Przejdźmy zatem do opisu typów uogólnionych
2.1. Typy uogólnione
Sztandarowym przykładem typów uogólnionych są różnego rodzaju kontenery (pojemniki), czyli obiekty służące do przechowywania innych obiektów. Jest oczywiste, że kod kontenera jest w dużej mierze niezależny od typu obiektów w nim przechowywanych. Jako przykład weźmy sobie stos liczb całkowitych. Możliwa definicja klasy stos może wyglądać następująco, choć nie polecam jej jako wzoru do naśladowania w prawdziwych aplikacjach:
class Stos {
private:
int m_elementy[N];
size_t m_szczyt;
public:
static const size_t N=100;
Stos():m_szczyt(0) {};
void wstaw(int val) {m_elementy[m_szczyt++]=val;}
int zdejm() {return m_elementy[--m_szczyt];}
bool czyPusty() {return (m_szczyt==0);}
};
Ewidentnie ten kod będzie identyczny dla stosu obiektów dowolnego innego typu, pod warunkiem, że typ ten posiada zdefiniowany operator=() i konstruktor kopiujący.
W celu zaimplementowania kontenerów bez pomocy szablonów możemy próbować podobnych sztuczek jak te opisane w poprzednim rozdziale. W językach takich jak Java czy Smalltalk, które posiadają uniwersalną klasę Object, z której są dziedziczone wszystkie inne klasy, a nie posiadają (Java już posiada) szablonów, uniwersalne kontenery są implementowane właśnie poprzez rzutowanie na ten ogólny typ. W przypadku C++ nawet to rozwiązanie nie jest praktyczne, bo C++ nie posiada pojedynczej hierarchii klas.
2.2. Szablony klas
Rozwiązaniem są znów szablony, tym razem szablony klas. Podobnie jak w przypadku szablonów funkcji, szablon klasy definiuje nam w rzeczywistości całą rodzinę klas. Szablon klasy TCStos możemy zapisać następująco:
template<typename T> class TCStos {
public:
static const size_t N=100;
private:
T m_elementy[N];
size_t m_szczyt{0};
public:
TCStos():m_szczyt(0) {};
void wstaw(T val) {m_elementy[m_szczyt++]=val;}
T zdejm() {return m_elementy[--m_szczyt];}
bool czyPusty() {return (m_szczyt==0);}
};
int main() {
// Tak zdefiniowanego szablonu możemy używać podając jawnie jego argumenty:
TCStos<string> st ;
st.wstaw("ania");
st.wstaw("asia");
st.wstaw(("basia");
while(!st.czyPusty() ) {
cout << st.zdejm() << endl;
}
return 0;
}
Dla szablonów klas nie ma możliwości automatycznej dedukcji argumentów szablonu, ponieważ klasy nie posiadają argumentów wywołania, które mogłyby do tej dedukcji posłużyć. Jest natomiast możliwość podania argumentów domyślnych, wtedy możemy korzystać ze stosu bez podawania argumentów szablonu i wyrażenie poniżej będzie prawidłowe.
template<typename T=int> class TCStos {
public:
...
};
int main() {
TCStos st; // równoważne TCStos<int> st;
...
}
Dla domyślnych argumentów szablonów klas obowiązują te same reguły, co dla domyślnych argumentów wywołania funkcji. Należy pamiętać, że każda konkretyzacja szablonu klasy dla różniących się zestawów argumentów jest osobną klasą.
2.3. Pozatypowe parametry szablonów klas
Zestaw możliwych parametrów szablonów klas jest taki sam jak dla szablonów funkcji. Podobnie najczęściej wykorzystywane są wyrażenia całkowitoliczbowe. W naszym przykładzie ze stosem możemy ich użyć do przekazania rozmiaru stosu:
template<typename T, size_t N=100> class TCStos {
private:
T m_elementy[N];
size_t m_szczyt{0};
public:
TCStos():m_szczyt(0) {};
void wstaw(T val) {m_elementy[m_szczyt++]=val;}
T zdejm() {return m_elementy[--m_szczyt];}
bool czyPusty() {return (m_szczyt==0);}
};
Zauważcie, że teraz możemy korzystać ze stosu jak do tej pory - podając jedynie typ. Wtedy dostaniemy stos o 100 elementach. Jeśli natomiast podamy i typ, i wartość liczbową - utworzymy stos o dowolnym rozmiarze.
int main() {
TCStos<string, 2500> st ; // mamy stos na 2500 elementów
...
}
Przy definicji wartości pozatypowych - zazwyczaj te umieszczane są na końcu, a nie na początku listy definicji, gdyż to one częściej mają sensowną wartość domyślną.
2.4. Szablony parametrów szablonu
Stos to nie tylko struktura danych, ale również sposób dostępu do niej. Realizuje on regułę LIFO (Last In First Out), co oznacza, że ostatni dodany element jest pierwszy, który zostaje usunięty. W tym kontekście, sposób przechowywania danych na stosie nie jest istotny. Mogą to być na przykład tablice, jak w powyższych przykładach, ale równie dobrze mogą to być różne inne kontenery. W Standardowej Bibliotece Szablonów C++ stos jest zazwyczaj zaimplementowany jako adapter do jednego z już istniejących kontenerów. Ponieważ kontenery STL są szablonami, adapter stosu również może być zdefiniowany jako szablon, jak przedstawiono poniżej:
template<typename T, template<typename X > class Sequence=std::deque > class TCStos {
private:
Sequence<T> m_elementy;
public:
TCStos() {};
void wstaw(T val) {m_elementy.push_back(val);}
T zdejm() {
auto rv = m_elementy.back();
m_elementy.pop_back();
return rv;
}
bool czyPusty() {return m_elementy.empty();}
};
Dzięki temu elastycznemu podejściu stos może być łatwo dostosowywany do różnych potrzeb przechowywania danych. Oczywiście nie jest to jedyna możliwość. Można też użyć zwykłego parametru typu:
template<typename T, typename C> class TCStos {
private:
C m_elementy;
public:
...
};
I dalej wykorzystywać następująco:
TCStos<string, std::deque<double> > st ;
W przypadku użycia szablonu jako parametru szablonu zapewniamy konsystencję pomiędzy typem T i kontenerem C, uniemożliwiając pomyłkę podstawienia niepasujących parametrów. Uczciwość nakazuje jednak w tym miejscu stwierdzić, że właśnie takie rozwiązanie jest zastosowane w STL-u. Ma ono tę zaletę, że możemy adaptować na stos dowolny kontener, niekoniecznie będący szablonem.
2.5. Konkretyzacja na żądanie
Jak już wcześniej wspomniano, konkretyzacja szablonów w C++ może odbywać się "na żądanie", co oznacza, że kompilator będzie generować konkretne implementacje tylko dla tych części szablonu, które są faktycznie używane w kodzie. Jeśli, na przykład, nie używamy w kodzie funkcji TCStos<int>::zdejm(), to ta funkcja nie zostanie wygenerowana.
To zachowanie może być wykorzystane do konkretyzowania klas szablonów za pomocą typów, które nie spełniają wszystkich ograniczeń nałożonych na parametry szablonu. Warto jednak pamiętać, że wszystko będzie działać poprawnie tylko do momentu, gdy nie będziemy używać funkcji, które łamią te ograniczenia.
Przykładowo, załóżmy, że rozszerzamy szablon TCStos, dodając do niego możliwość sortowania (choć to może być sprzeczne z konceptem stosu, który tradycyjnie nie posiada operacji sortowania). Poniżej znajduje się uproszczony przykład:
template<typename T, template<typename X > class Sequence=std::deque > class TCStos {
...
void sortuj() {
std::bubble_sort(m_elementy,N);
};
};
int main() {
// Możemy teraz np. używać
TCStos<std::complex<double> > sc;
sc.wstaw( std::complex<double>(0,1));
sc.zdejm();
// ale nie można użyć
sc.sortuj();
// konkretyzacja jawna nie powiedzie się, bo kompilator będzie się
// starał skonkretyzować wszystkie składowe klasy Stack, w tym metodę sort().
template TCStos<std::complex<double> >;
...
}
W powyższym przykładzie, funkcja `sortuj()` została dodana do szablonu TCStos. Chociaż sortowanie nie jest operacją stosu, to nadal możemy skompilować i uruchomić program, o ile nie używamy funkcji, które naruszają ograniczenia logiczne stosu. Jednak taka praktyka może prowadzić do kodu, który jest trudny do zrozumienia i utrzymania, dlatego zawsze warto zachować ostrożność i stosować zasady projektowania w zgodzie z intencjami danego komponentu.
2.6. Typy stowarzyszone
W klasach poza metodami i polami możemy definiować również typy, które będziemy nazywali stowarzyszonymi z daną klasą. Jest to szczególnie przydatne w przypadku szablonów. Rozważmy następujący przykład:
template<typename T, template<typename X > class Sequence=std::deque > class TCStos {
...
public:
typedef T value_type;
...
};
Możemy teraz używać jej w innych szablonach:
template<typename S> void f(S s) {
typename S::value_type total = 0;
// słowo typename jest wymagane, inaczej kompilator założy, że
// S::value_type odnosi się do statycznej składowej klasy
while(!s.is_empty() ) {
total+=s.pop();
}
return total;
}
Bez takich możliwości musielibyśmy przekazać typ elementów stosu w osobnym argumencie. Mechanizm typów stowarzyszonych jest bardzo często używany w uogólnionym kodzie.
3. Koncepty
Szablony okazały się być niezwykle potężnym narzędziem, którego zastosowanie daleko przekracza implementację prostych kontenerów. Można śmiało stwierdzić, że ich prawdziwy potencjał jest ciągle odkrywany. Szablony doskonale wspierają styl programowania nazywany programowaniem uogólnionym, który opiera się na generalizowaniu algorytmów i struktur danych, aby były w dużej mierze niezależne od typów danych, na których działają lub z których się składają.
Przykłady zastosowań szablonów są liczne i wpływowe. Jednym z najważniejszych i powszechnie stosowanych przykładów programowania uogólnionego jest Standardowa Biblioteka Szablonów (STL). STL oferuje szeroką gamę szablonów, w tym kontenery, algorytmy, oraz inne komponenty, które pozwalają programistom pisać ogólnokształtne i efektywne kody.
Innym znaczącym przykładem jest repozytorium bibliotek boost, które stanowi zbiór narzędzi i rozszerzeń do C++, również opartych na zaawansowanym użyciu szablonów. Biblioteka boost rozszerza możliwości programowania C++, dostarczając nowoczesne i efektywne rozwiązania dla wielu problemów programistycznych.
Ogólnie rzecz biorąc, szablony są kluczowym elementem w rozwoju programowania uogólnionego, umożliwiając programistom pisanie elastycznego, generycznego kodu, który może być łatwo dostosowywany do różnych typów danych i problemów programistycznych.
W kontekście programowania uogólnionego, kluczową rolę odgrywa pojęcie konceptu. Koncept jest abstrakcyjną definicją rodziny typów, pełniącą analogiczną funkcję do interfejsu. Koncept obejmuje typy, które spełniają określone wymagania. Innymi słowy, jeśli coś "kwacze" jak kaczka, to jest to kaczka, zamiast warunku "jest kaczką, jeśli należy do rodziny 'kaczowatych'".
3.1. Obiektowość a szablony
Programowanie uogólnione i obiektowe to dwa różne podejścia. Samo programowanie uogólnione niekoniecznie jest silnie obiektowe.
W programowaniu obiektowym kluczowym jest projektowanie klas i ich wzajemnych relacji, włączając w to kluczową z nich - dziedziczenie, które w połączeniu z polimorfizmem daje nam naprawdę wielkie możliwości. Ale - w życiu zazwyczaj warto wystrzegać się różnych ekstremizmów, w tym także i tych związanych z nadmiernym stosowaniem jakiejś techniki w połączeniu z bezgranicznym zaufaniem co do jej doskonałości. Programowanie obiektowe kładzie nacisk na struktury danych reprezentujące obiekty w rzeczywistym świecie, a operacje są związane z tymi obiektami, ale nie jest jedynym podejściem.
Wystrzegajcie się postrzegania problemów przez filtr narzędzi które macie do dyspozycji. Jeśli jedynym waszym narzędziem jest młotek - to każdy problem będzie wyglądał jak gwóźdź...
Rozważmy przykład wcześniej wspomnianego polimorfizmu. Omówiliśmy już jedną jego odmianę - polimorfizm dynamiczny.
Polimorfizm dynamiczny to zdolność programu do decydowania o tym, która funkcja zostanie wywołana pod daną nazwą nie w momencie kompilacji, ale w trakcie działania programu. W obiektowości, polimorfizm dynamiczny jest często realizowany poprzez wykorzystanie wskaźników i referencji do klas bazowych oraz stosowania mechanizmu wirtualnych funkcji.
Opierając się na tożsamości obiektu, oraz - na jego klasie i hierarchii klas do których należy - podejmowana jest decyzja odnośnie postaci metody którą należy wywołać. Ale może nie zawsze jest to najlepsze rozwiązanie?
Polimorfizm statyczny
Może nie warto zastanawiać się, jakiego typu jest obiekt w trakcie wykonania programu, tylko w trakcie jego kompilacji sprawdzić, czy obiekt dla którego chcemy jakąś metodę wywołać - ma tą metodę? I to jest właśnie clou polimorfizmu statycznego.
Polimorfizm statyczny daje nam możliwość zrezygnowania z wymuszania typu argumentu podczas wywoływania funkcji. Szablony funkcji w C++ pozwalają na tworzenie funkcji, które działają na różnych typach danych, pod warunkiem, że te typy spełniają określone wymagania.
Przykładowo, funkcja draw_template pozwala na rysowanie obiektów przechowywanych w tablicy dla różnych typów danych, o ile posiadają one metodę `draw`.
template<typename T> void draw_template(T table[], size_t n) {
for(size_t i = 0; i < n; ++i)
table[i].draw();
}
Jaka jest postać metody draw? Pisząc funkcję - nie wiemy. Ale wiemy że zostanie wykonana - więc uzyskaliśmy "zmiennopostaciowość" - tyle że innymi środkami
Polimorfizm dynamiczny umożliwia operowanie na zbiorze obiektów o różnych typach, korzystając z mechanizmu dziedziczenia. Kluczową koncepcją jest wspólna hierarchia dziedziczenia, co oznacza, że obiekty muszą pochodzić z tych samych klas bazowych. Wymaga to użycia wskaźników lub referencji do obiektów oraz zastosowania funkcji wirtualnych. Pomimo tego, że generuje większy kod, pozwala na elastyczne korzystanie z różnych typów obiektów w czasie wykonania programu.
W przeciwieństwie do polimorfizmu dynamicznego, szablony implementują polimorfizm statyczny. Działają one na jednorodnych zbiorach obiektów, co oznacza, że obiekty nie muszą pochodzić z tej samej hierarchii dziedziczenia. Szablony umożliwiają operowanie na różnych typach obiektów bez konieczności korzystania ze wskaźników, referencji czy funkcji wirtualnych. W efekcie otrzymanego kodu jest zazwyczaj mniejszy i może działać szybciej, co stanowi istotną korzyść w kontekście optymalizacji wydajnościowej.
Podsumowując, oba rodzaje polimorfizmu są potężnymi narzędziami, ale wybór między nimi zależy od konkretnych potrzeb i charakteru programu. Polimorfizm dynamiczny jest przydatny, gdy mamy do czynienia z niejednorodnymi zbiorami obiektów, natomiast polimorfizm statyczny w kontekście szablonów pozwala na efektywną pracę z jednorodnymi zbiorami, co może przekładać się na lepszą wydajność kodu.
3.2. Koncepty
W kontekście programowania z użyciem szablonów, koncepty stają się niezbędnym narzędziem, umożliwiającym programiście narzucanie oczekiwań co do funkcjonalności i zachowań dla typów, które są używane z danym szablonem. Koncepty pozwalają na wyraźne i zwięzłe zdefiniowanie warunków, które muszą być spełnione przez dany typ, aby mógł być użyty z danym szablonem.
Abstrakcyjne Definicje Poprzez Koncepty
Koncepcja konceptów umożliwia tworzenie abstrakcyjnych definicji, zwanych konceptami, które są niezależne od konkretnego szablonu. W praktyce, koncept to zestaw warunków, które muszą być spełnione przez dany typ, aby był uznany za model konceptu. Ten model konceptu może być potem używany z różnymi szablonami, co pozwala na tworzenie generycznych algorytmów i struktur danych.
Podobnie jak w hierarchii dziedziczenia, koncepty mogą tworzyć hierarchie. To oznacza, że jeden koncept może być bardziej ogólny, obejmując szeroki zakres typów, podczas gdy inny może być bardziej szczegółowy, zdefiniowany dla konkretnego podzbioru typów. Takie hierarchie konceptów pozwalają na elastyczne korzystanie z ogólnych definicji i jednocześnie narzucanie bardziej konkretnej specyfikacji, gdy jest to konieczne.
Ograniczenia konceptów: prawidłowe wyrażenia, typy stowarzyszone i semantyka
Ograniczenia konceptów są zbiorem warunków, które muszą być spełnione przez dany typ. Obejmują one różnorodne aspekty:
- Prawidłowe wyrażenia: Określenie, jakie operacje i wyrażenia muszą być poprawnie obsługiwane przez dany typ w ramach danego konceptu.
- Typy stowarzyszone: Dodatkowe typy, które występują w kontekście prawidłowych wyrażeń i operacji na danym typie.
- Semantyka: Definicje znaczenia wyrażeń, które są zawsze prawdziwe dla danego konceptu. To pozwala na określenie oczekiwanego zachowania typów związanych z danym konceptem.
Ograniczenia konceptów mogą również obejmować informacje dotyczące złożoności algorytmów. Gwarancje co do czasu i innych zasobów potrzebnych do wykonania danego wyrażenia są istotne w kontekście efektywności i optymalizacji. Programiści, korzystając z konceptów, mogą wybierać takie, które są zarówno ogólne, jak i wydajne, co pozwala na tworzenie generycznych rozwiązań, które są jednocześnie efektywne dla różnych typów danych.
W skrócie, koncepty w programowaniu uogólnionym stanowią koncepcję kluczową dla definiowania oczekiwań i ograniczeń dla typów używanych z szablonami. Odpowiednie zastosowanie konceptów pozwala na tworzenie generycznych i elastycznych rozwiązań, które jednocześnie pozostają efektywne i zgodne z oczekiwaniami programisty.
Przykład
Przyjrzyjmy się omawianemu wcześniej szablonowi funkcji max
template<typename T> max(T a,T b) {return (a>b)?a:b;}
Jakie koncepty możemy tu odkryć?
Gramatyka
Jakie warunki musi spełniać typ T, aby podstawienie go jako argument szablonu max dawało poprawne wyrażenie? Musi mieć zdefiniowany operator porównania bool operator>(...). Nie jest ważna sygnatura tego operatora. Nie ma znaczenia jak parametry są przekazywane, czy operator jest w klasie, czy jako funkcja, itp... jedno co ważne to że jeśli x i y są obiektami typu T to wyrażenie:
x>y
jest poprawne (skompiluje się).
Łatwiej jest przeoczyć fakt, że ponieważ argumenty wywołania są zwracane i przekazywane przez wartość, to typ T musi posiadać konstruktor kopiujący. Oznacza to, że jeśli x i y są obiektami typu T to wyrażenia:
T(x);
T x(y);
T x = y;
są poprawne.
Spełnienie obydwu tych warunków zapewni nam poprawność gramatyczną wywołania szablonu z danym typem, tzn. kod się skompiluje.
Semantyka
Mogłoby się wydawać, że jest bez znaczenia jak zdefiniujemy operator>(...). Koncept typu T jest jednak częścią kontraktu dla funkcji max. Kontrakt stanowi, że jeżeli użytkownik dostarczy do funkcji argumenty o typach zgodnych z konceptem i o wartościach spełniających być może inne warunki wstępne, to twórca funkcji gwarantuje, że zwróci ona poprawny wynik.
Z definicji maksimum żaden element argument funkcji max nie może być większy od wyniku, czyli wyrażenie
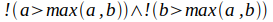
musi być zawsze prawdziwe. Jasne jest, że jeśli dla jakiegoś typu X zdefiniujemy operator porównania tak, aby zwracał zawsze prawdę lub aby był równoważny operatorowi równości to wyrażenie nie może być prawdziwe dla żadnej wartości a i b. Musimy narzucić pewne ograniczenia semantyczne na operator>() - żądanie, aby relacja większości definiowana przez ten operator była relacją porządku częściowego:
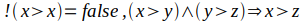
To rozumowanie można by ciągnąć dalej i zauważyć, że nawet z tym ograniczeniem uzyskamy nieintuicyjne wyniki w przypadku, gdy obiekty a i b będą nieporównywalne, tzn. !(a>b) i !(b>a).
Dostaliśmy zbiór warunków, które musi spełniać typ T, aby móc go podstawić do szablonu funkcji max. Jak go nazwać?
Comparable - ale istnienie konstruktora kopiującego nie ma z tym nic wspólnego. Próbujemy upchnąć dwa niezależne pojęcia do jednego worka. Co więcej bardzo łatwo jest zrezygnować z konieczności posiadania konstruktora kopiującego, zmieniając deklarację max na:
template<typename T> const T& max(const T&,const T&);
Teraz argumenty i wartość zwracana przekazywane są przez referencję i nie ma potrzeby kopiowania obiektów. Logiczne jest wydzielenie dwu konceptów: jednego definiującego typy porównywalne, drugiego - typy "kopiowalne". Dalej możemy zauważyć, że istnienie operatora > automatycznie pozwala na zdefiniowanie operatora < poprzez:
bool operator<(const T& a,const T&b) {return b>a;};
Podobnie istnienie konstruktora kopiującego jest blisko związane z istnieniem operatora przypisania.
Finalnie - najlepiej zapewne będzie wydzielić dwa koncepty:
- Comparable - obiekty można porównywać za pomocą operatorów < i >
- Assignable - obiekty możemy kopiować i przypisywać do siebie.