Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | 2. Modelowanie oprogramowania |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | czwartek, 11 czerwca 2026, 06:20 |
Opis
Model jest reprezentacją określonej rzeczywistości, która pomaga w zrozumieniu tej rzeczywistości. Konkretne przyczyny tworzenia modeli są tak różnorodne jak dziedziny w których modele są stosowane. Modelowanie obecne jest w większości dziedzin działalności człowieka, np. nauce, technice, edukacji czy sztuce.
1. Wprowadzenie do modelowania obiektowego
1.1. Podstawowe zasady modelowania
Model jest reprezentacją określonej rzeczywistości, która pomaga w zrozumieniu tej rzeczywistości. Konkretne przyczyny tworzenia modeli są tak różnorodne jak dziedziny w których modele są stosowane. Modelowanie obecne jest w większości dziedzin działalności człowieka, np. nauce, technice, edukacji czy sztuce. Rysunek 1.1 przedstawia przykłady różnych modeli: model kryształu żelaza zbudowany w powiększeniu, model numeryczny ludzkiego ciała dla potrzeb analizy pola elektromagnetycznego, model nadwozia samochodu oraz model budynku

Rysunek 1.1: Przykładowe modele w różnych dziedzinach
Budowa modeli może mieć różne cele, z których najważniejsze to:
- Testowanie właściwości fizycznych obiektów przed ich wykonaniem.
- Wizualizacja i komunikacja z klientami.
- Redukcja złożoności.
Z punktu widzenia inżynierii oprogramowania najbardziej interesuje nas ten ostatni z wymienionych celów, czyli radzenie sobie ze złożonością otaczającej nas rzeczywistości. Wspomniana wyżej zasada koncentracji na elementach najważniejszych w danym kontekście jest jedną z podstawowych technik stosowanych przez ludzki umysł. Technika ta nazywa się abstrakcją. Żeby ją zastosować, w pierwszej kolejności należy sobie uświadomić jak bardzo istotne są poszczególne charakterystyki modelowanego przez nas w danym momencie tematu z punktu widzenia naszego aktualnego celu. Wyróżniamy zatem cechy danego systemu stosownie do ich wagi, wyróżniając istotne, a odpowiednio mniej eksponując lub wręcz pomijając te o mniejszym znaczeniu. Daje nam to podstawę do zastosowania trzech technik realizujących zasadę abstrakcji, czyli generalizacji, klasyfikacji i enkapsulacji.
Klasyfikacja polega na grupowaniu elementów świata rzeczywistego w kategorie, zgodnie z przyjętymi kryteriami, najczęściej nawiązującymi do jakichś ich wspólnych charakterystyk. Przykłady takiej klasyfikacji został pokazany na rysunku 4.2. Rysunek ten ilustruje również technikę enkapsulacji. Polega ona na grupowaniu elementów w większe całości, które nazywamy i prowadzimy analizę systemu na poziomie tych całości.
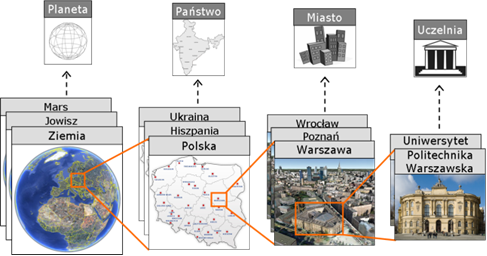
Rysunek 1.2: Przykład zastosowania zasady abstrakcji
Generalizacja polega na tworzeniu pojęć ogólnych poprzez wyodrębnienie pewnego zbioru cech wspólnych dla szeregu pojęć bardziej szczegółowych. Im mniejszy zbiór cech wspólnych, tym bardziej ogólne pojęcie i tym większy zakres konkretnych obiektów, do których pojęcie może być zastosowane. W miarę powiększania zbioru cech wspólnych, pojęcie staje się coraz bardziej szczegółowe, obejmując coraz mniejszy zakres konkretnych obiektów. Generalizacja pozwala tworzyć hierarchię pojęć.
Budując abstrakcyjne modele nie szukamy prawdy absolutnej o otaczającej nas rzeczywistości. Zamiast tego z reguły skupiamy się na wybranym jej fragmencie, który jest najbardziej adekwatny dla celu, jaki przyświeca nam podczas budowy danego modelu. Może zatem istnieć wiele poprawnych, choć mocno różniących się między sobą modeli, które ukazują różne aspekty modelowanego obiektu czy zjawiska.
Oprogramowanie również można potraktować jako model określonego fragmentu świata rzeczywistego. Co ważniejsze jest ono również samo w sobie wysoce skomplikowanym jego elementem. Duże systemy oprogramowania muszą więc odzwierciedlać ogromne ilości obiektów i mechanizmów zachodzących w danym środowisku, które system ma realizować.
Kodowanie w językach programowania nie jest jednak dobrym sposobem modelowania. Często bywa tak, że dana dziedzina nie jest dobrze znana twórcom przystępującym do budowy systemu oprogramowania a wymagania zamawiającego system zmieniają się w trakcie jego realizacji. Trudno byłoby sobie wyobrazić przystąpienie do pisania kodu dużego systemu jedynie na podstawie przekazanego przez zamawiającego, nieformalnego opisu problemu.
Zanim przystąpimy do tego etapu, musimy stworzyć szereg modeli pośrednich, które opisują budowany system oraz jego środowisko z różnych punktów widzenia oraz na różnym poziomie szczegółowości. Wyróżniamy modele struktury, które uwypuklają statyczną budowę systemu, oraz modele zachowania, które opisują aspekty dynamiczne. Modele te mają istotne znaczenie dla właściwego zrozumienia funkcjonalności, jaką system ma zrealizować, jak również pozwalają stworzyć architekturę systemu, którą można elastycznie modyfikować w przypadku zmieniających się wymagań.
Szczegółowe modele projektowe pozwalają stworzenie dobrego, przejrzystego kodu oprogramowania. Model abstrahuje od szczegółów kodu (np. treści metod) i pokazuje np. tylko strukturę powiązań między klasami. Programista może dzięki temu łatwiej zorientować się w strukturze kodu i odpowiedzialności poszczególnych klas.
Dzięki modelowaniu możemy osiągnąć następujące korzyści:
- Zrozumienie celu budowy systemu oraz sposobu jego realizacji,
- Ułatwienie komunikacji pomiędzy twórcami systemu oraz zamawiającym,
- Ułatwienie zarządzania realizacją systemu oraz zarządzanie ryzykiem,
- Ułatwienie dokumentowania systemu.
Modele powinny być podstawowym produktem każdego projektu wytwarzania oprogramowania. Im większy i bardziej złożony system, tym większe znaczenie modelowania.
1.2. Uniwersalny język modelowania
W związku z rosnącą popularnością obiektowych języków programowania zaczęły również pojawiać się obiektowe języki modelowania. W latach 90-tych nastąpił proces unifikacji, co doprowadziło do powstania ujednoliconego języka modelowania – UML (ang. Unified Modelling Language). Twórcami języka byli Grady Booch, James Rumbaugh i Ivar Jacobson, którzy połączyli stosowane wcześniej różne notacje w jeden uniwersalny język. UML jest obecnie najpowszechniej stosowanym językiem modelowania, który jednocześnie został zdefiniowany jako standard (m.in. jako standard ISO/IEC 19505). UML jest językiem graficznym, za pomocą którego można tworzyć modele niezbędne w całym procesie budowy systemu informatycznego. Można go również wykorzystywać do modelowania rzeczywistości niekoniecznie powiązanej z systemem informatycznym. W dalszej części książki będziemy sukcesywnie przedstawiać składnię i semantykę języka UML w wersji 2. Pełną specyfikację języka znaleźć można na stronach internetowych organizacji Object Management Group (www.omg.org), która zajmuje się rozwojem i standaryzacją języka.
1.3. Obiekty jako podstawa modelowania
Jak już wspomnieliśmy, najbardziej rozpowszechnionym współcześnie paradygmatem modelowania jest modelowanie obiektowe. Zgodnie z nazwą, opiera się ono na obiektach, czyli wyodrębnionych elementach rzeczywistości istotnych z perspektywy tworzonego modelu. Każdy obiekt stanowi osobny byt wyraźnie wyodrębniony z całości modelowanej dziedziny. Obiekty mogą zatem reprezentować różnego rodzaju przedmioty, osoby, zdarzenia, procesy lub inne twory niematerialne występujące w danym środowisku.
Z punktu widzenia zamawiającego system, obiekty odpowiadają rzeczywistym elementom modelowanego środowiska (przedmiotom, osobom itd.). Z punktu widzenia programistów, obiekty są podstawowymi jednostkami implementacji oprogramowania w obiektowych językach programowania. Obiekty będące elementami oprogramowania nie zawsze odzwierciedlają w pełni obiekty rzeczywiste z określonego środowiska – często są ich uproszczeniem lub modyfikacją. Ponadto, w systemach oprogramowania występuje szereg dodatkowych obiektów związanych nie ze środowiskiem, lecz z techniczną stroną oprogramowania, jak np. okienka interfejsu użytkownika, formularze wprowadzania danych, interfejsy programistyczne, bazy danych, obiekty sterujące działaniem systemu, itp. Na podstawie obiektów z danej dziedziny świata rzeczywistego, analitycy i projektanci tworzą modele obiektowe, które z kolei są podstawą do stworzenia kodu oprogramowania. Modele te powinny odzwierciedlać różne aspekty modelowanej dziedziny. Możemy zatem określić, że modelowanie obiektowe polega na:
- znajdowaniu interesujących nas konkretnych obiektów w danej dziedzinie,
- opisywaniu struktury i sposobu działania tych obiektów,
- klasyfikacji i generalizacji obiektów,
- znajdowaniu powiązań między nimi,
- opisywaniu dynamicznych aspektów współpracy pomiędzy obiektami.
Zgodnie z paradygmatem obiektowości, obiekt (ang. object) posiada trzy główne cechy: tożsamość, stan i zachowanie.
Zdefiniujmy zatem czym są wspomniane wcześniej trzy cechy obiektu.
Tożsamość (ang. identity) obiektu jest cechą umożliwiającą jego identyfikację i odróżnienie od innych obiektów. Tożsamość jest cechą unikalną wśród wszystkich obiektów i pozostaje niezmienna przez cały czas życia obiektu. W przypadku obiektów w systemie oprogramowania, cechą określająca tożsamość obiektu może być adres obszaru pamięci komputera, w którym dany obiekt się znajduje lub specjalna, ukryta właściwość obiektu, której unikalna wartość jest nadawana automatycznie.
Stan (ang. state) obiektu jest określany przez aktualne wartości wszystkich jego właściwości. Każdy obiekt posiada zbiór właściwości, które go charakteryzują. Zbiór ten nie ulega zmianie przez całe życie obiektu. Zmianie mogą ulegać jedynie wartości tych właściwości. Wartości mogą być np. liczbami, napisami czy innymi obiektami.
Zachowanie (ang. behaviour) obiektu to zbiór usług, które obiekt potrafi wykonać na rzecz innych obiektów. Zachowanie obiektów określa dynamikę systemu – sposób komunikacji pomiędzy obiektami. Efektem wykonania usługi może być jakaś wartość zwracana obiektowi, który poprosił o wykonanie usługi. Wartość ta może zależeć od aktualnego stanu obiektu wykonującego usługę. Podczas wykonywania usługi, obiekt może operować na swoim zbiorze wartości, w wyniku czego może ulec zmianie jego stan.
Język UML dostarcza nam odpowiedniej notacji do reprezentowania obiektów – ich stanu i tożsamości. Przykład tej notacji przedstawia rysunek 1.3. Podstawową ikoną obiektu jest prostokąt zawierający podkreśloną jego nazwę. Po nazwie obiektu można zapisać oddzieloną dwukropkiem nazwę typu (klasy) obiektu (o klasach obiektów będzie mowa w dalszej części rozdziału). W przykładzie na rysunku widzimy np. dwa obiekty o nazwach „Zenek” i „Bogdan”, dla których określony został typ – „Kierowca”. W razie potrzeby możemy również przedstawić aktualny stanu obiektu (w tym również tych właściwości, które określają stan obiektu). Listę właściwości obiektu umieszczamy poniżej jego nazwy. Aktualne wartości poszczególnych właściwości mogą być umieszczone po ich nazwie, oddzielone znakiem „=”. Przykładami obiektów, dla których określono stan są „samochód Zenka” i „samochód Bogdana”.
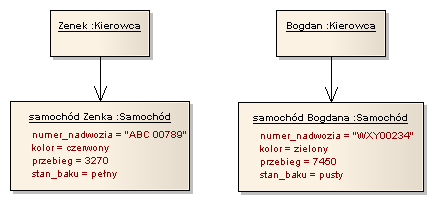
Rysunek 1.3: Notacja dla obiektów w języku UML
Obiekty na diagramie mogą być połączone łącznikami (ang. link), które odzwierciedlają relacje między obiektami. Powiązane obiekty mogą komunikować się między sobą, na przykład poprzez wywoływanie swoich usług. Powiązania mogą być ukierunkowane, wskazując kierunek komunikacji pomiędzy obiektami. Przykładowo, na rysunku 1.3 obiekt „Bogdan” jest powiązany z obiektem „samochód Bogdana”. Kierunek powiązania wskazuje na to, że obiekt „Bogdan” może poprosić obiekt „samochód Bogdana” o wykonanie jakiejś usługi lub poznać jego stan. Odwrotna komunikacja nie jest natomiast dostępna. To, jakie usługi „samochód Bogdana” może wykonać, określa jego zachowanie. Zachowania obiektów nie przedstawia się na diagramach obiektów. Zachowanie jest takie samo dla wszystkich obiektów danej klasy, co omawiamy poniżej.
1.4. Klasy obiektów
Typowe dziedziny problemów składają się z tysięcy czy nawet milionów współistniejących obiektów. Konieczne jest opanowanie tej złożoności. Jak już wiemy, jednym ze sposobów radzenia sobie ze złożonością jest stosowanie zasady abstrakcji poprzez klasyfikację. W modelowaniu obiektowym podstawowym elementem modelowanie nie będzie zatem obiekt, lecz jego uogólnienie, czyli klasa obiektów. Klasa powinna stanowić opis grupy na tyle podobnych obiektów, że z punktu widzenia perspektywy, dla której tworzymy dany model można je potraktować wspólnie.
W skrócie, możemy formalnie zdefiniować klasę w następujący sposób: „Klasa (ang. class) to opis grupy obiektów, które mają taki sam zestaw właściwości oraz sposób zachowania”. Każda klasa ma przypisaną nazwę, która wyróżnia ją spośród innych klas w danym kontekście. Właściwości obiektów reprezentowanych przez klasę zwane są atrybutami (ang. attribute). Klasa może mieć dowolną liczbę atrybutów (w szczególności – nie mieć żadnych atrybutów). Sposób zachowania obiektów danej klasy nazywamy operacjami (ang. operation). Każda operacja określa konkretną usługę, którą obiekty danej klasy mogą wykonywać, np. na rzecz obiektów innych klas. Podobnie jak w przypadku atrybutów, klasa może mieć dowolną liczbę operacji.
Rysunek 1.4 przedstawia przykładowy diagram reprezentujący klasy w języku UML, odpowiadający wcześniej omawianym przykładom. Bardziej szczegółowe objaśnienia języka UML w ogólności, a diagramów klas w szczególności, przedstawiamy w kolejnych rozdziałach. Na razie zwróćmy tylko uwagę, że klasy są reprezentowane poprzez prostokąty opatrzone ich nazwami. Poniżej w odpowiednich przegródkach wymienione są ich atrybuty i operacje. Dodatkowo wszelkie zależności pomiędzy klasami, nazywane ogólnie relacjami, odzwierciedlane są w postaci łączących klas linii. W naszym przykładzie mamy więc klasy reprezentujące samochód i kierowcę połączone odpowiednią relację. Posiadają one zdefiniowane odpowiednie atrybuty i operacje, zgodne z wcześniejszymi przykładami dotyczącymi obiektów.
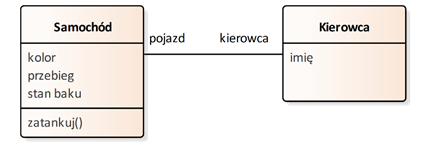
Rysunek 1.4: Przykładowy diagram klas
W języku UML obiekty przypisane do danej klasy, nazywane są instancjami (ang. Instance) klasy. Rysunek 1.5 przedstawia dwa obiekty będące instancjami klasy „Samochód”, na co wskazuje zarówno typ obiektów pokazany w ich nazwie, jak również relacje «instanceOf» łączące obiekty z klasą.
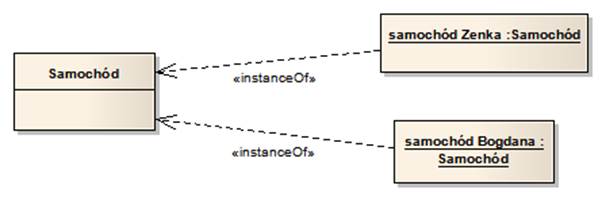
Rysunek 1.5: Obiekty jako instancje klas
Powiedzieliśmy wcześniej, że modele powinny być tworzone z perspektywy konkretnego celu, któremu będą służyć. Różni czytelnicy modeli patrzą na obiekty i ich klasy z różnych perspektyw, w zależności od tego jaką pełnią rolę w procesie tworzenia systemu oprogramowania.
Możemy wyróżnić trzy perspektywy, których można użyć przy tworzeniu modeli, zwłaszcza modeli klas:
Perspektywa pojęciowa. Przyjmując tę perspektywę, modelujemy klasy reprezentujące pojęcia analizowanego środowiska. Model pojęciowy tworzony jest niezależnie od oprogramowania. Zazwyczaj nie ma pełnej odpowiedniości pomiędzy elementami tego modelu a klasami implementacyjnymi.
Perspektywa specyfikacyjna. Perspektywa ta dotyczy bezpośrednio oprogramowania, ale raczej w sensie definiowania typów obiektów niż szczegółów implementacji. Typ może być implementowany przez wiele klas, a klasa może implementować wiele typów. W perspektywie tej unika się zazwyczaj szczegółów związanych z konkretnym językiem programowania czy technologią.
Perspektywa implementacyjna. Perspektywa ta ukazuje wszystkie szczegóły implementacji. Na podstawie modeli implementacyjnych możliwe jest stworzenie kodu oprogramowania.
Wymienione perspektywy nie są formalnie zdefiniowane w języku UML. Są jednak bardzo przydatne podczas tworzenia i analizy modeli, chociaż granice między nimi nie zawsze są jednoznaczne.
1.5. System jako zbiór współpracujących obiektów
Klasy i należące do nich obiekty służą odzwierciedleniu statycznej struktury wybranej dziedziny problemu lub systemu oprogramowania. Obiekty najczęściej nie są jednak bezczynne, lecz wzajemnie na siebie oddziałują. Zbiór współpracujących ze sobą obiektów nazywamy systemem. Oczywistym przykładem systemu jest dowolny system oprogramowania, ale jest to pojęcie znacznie szersze. Działanie każdego systemu – w szczególności systemu oprogramowania – można przedstawić jako wzajemne przesyłanie komunikatów w ramach pewnego zbioru obiektów w ściśle określonym celu. Jak wiemy, obiekty posiadają zachowanie określone przez swoje klasy, w postaci zbioru usług. Usługi te mogą być wykonywane na prośbę innych obiektów. Prośby o wykonanie usługi oraz ewentualne odpowiedzi nazywamy komunikatami (ang. Message). W ramach wykonania usługi, obiekt może operować na wartościach swoich atrybutów, w wyniku czego jego stan może ulec zmianie. Może też przesyłać komunikaty do innych obiektów.
Język UML zawiera szereg różnych diagramów pozwalających odzwierciedlać dynamiczne aspekty modelowanych dziedzin. Przebiegu wymiany komunikatów pomiędzy obiektami możemy przedstawić za pomocą modeli interakcji (ang. Interaction Model). Przykład takiego modelu widzimy na diagramie zamieszczonym na rysunku 1.6. Diagram ten zawiera trzy tzw. linie życia, odpowiadające obiektom przedstawionym na górze diagramu („Bogdan”, „Samochód Bogdana” i nienazwany obiekt klasy „Silnik”). Pomiędzy liniami przebiegają komunikaty wyrażone w formie strzałek. Komunikaty te czytane w kolejności od góry do dołu tworzą sekwencję interakcji między obiektami, w tym wypadku opisującą proces uruchamiania samochodu i rozpoczynania jazdy. W podanym przykładzie kierowca najpierw przesyła do samochodu polecenie, aby się włączył. Powoduje to z kolei przesłanie przez samochód polecenia do silnika, aby się uruchomił. Następnie kierowca rozpoczyna jazdę, czyli wysyła do samochodu polecenie „jedź” (np. w rzeczywistości naciska pedał gazu). Wymaga to zwiększenia obrotów silnika, czyli samochód wysyła odpowiednie polecenie do silnika. Na diagramie widzimy zarówno prośby o wykonanie usługi (pełne strzałki), jak i odpowiedzi oznaczające zakończenie wykonywania usługi przez obiekt (przerywane strzałki).
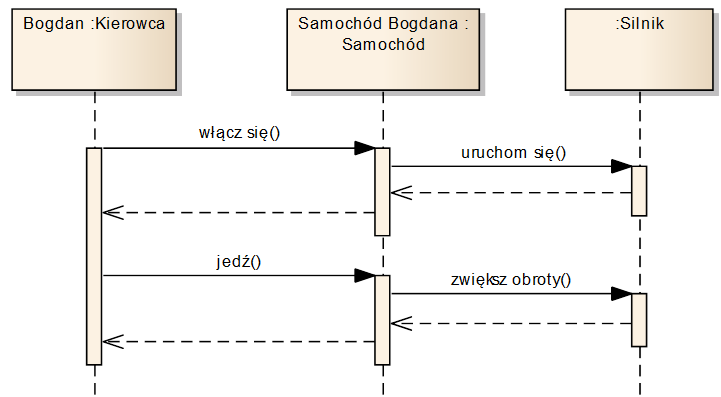
Rysunek 1.6: Przykładowy diagram interakcji
Warto zauważyć, że wpływ na to, jak zostanie wykonana określona usługa, mają trzy czynniki.
- Aktualny stan obiektu.
- Parametry komunikatu.
- Stan innych obiektów.
Zauważmy też, że w podanym przykładzie, kierowca chcąc uruchomić silnik, wysyła jedynie odpowiedni komunikat do samochodu i oczekuje na rezultat. Nie wie on, w jaki sposób samochód realizuje usługę „włącz się” i jakie inne obiekty są w to zaangażowane. Samochód jest dla niego czarną skrzynką z przyciskami do wywoływania określonych usług. Można powiedzieć że z punktu widzenia kierowcy uruchomienie samochodu stanowi tzw. proces, jako że znane jest mu tylko jego wejście (co zrobił, żeby go rozpocząć) i wyjście (co uzyskał w jego efekcie). Podejście procesowe jest często przydatne przy wytwarzaniu oprogramowania, jako że dobrze zaprojektowany obiekt udostępnia innym obiektom tylko te usługi lub właściwości, które są im potrzebne. Ważne jest jednak, aby udostępniane usługi (nazwy operacji w klasie) były dobrze i jednoznacznie opisane, tak, aby wywołujący te usługi wiedział co otrzyma w wyniku ich realizacji.
2. Modelowanie struktury systemu
Język UML oferuje szereg typów modeli służących do modelowania struktury. Różne typy dostosowane są do różnych celów, którym mają służyć. Najbardziej podstawowym i najczęściej używanym typem modelu jest model klas (ang. Class Model). Diagramy klas mogą dotyczyć opisu rzeczywistości, definicji struktur danych lub projektu szczegółowej struktury kodu. Drugim często używanym typem modeli jest model komponentów (ang. Component Model). Model komponentów znajduje zastosowanie przede wszystkim w definiowaniu architektur logicznych systemów oprogramowania. Do modelowania architektur fizycznych służy natomiast model wdrożenia (ang. Deployment Diagram), również nazywany diagramem montażu. Język UML zawiera również inne, rzadziej używane modele służące do modelowania struktury. Są to model obiektów (ang. Object Model), model pakietów (ang. Package Model) oraz model składowych (ang. Composite Structure Model). Ich omówienie wykracza poza zakres tego podręcznika.
2.1. Model klas
Diagramy klas stanowią najbardziej uniwersalną i prawdopodobnie najbardziej rozpowszechnioną formę modelowania struktury. Podstawowym elementem diagramu klas jest oczywiście klasa, czyli uogólnienie zbioru obiektów o tym samym sposobie zachowania i atrybutach (patrz poprzedni rozdział). Klasa definiuje zatem grupę podobnych obiektów, które zostały uznane za warte wspólnego reprezentowania na potrzeby danego modelu. Na rysunku 2.1 przedstawione zostały różne dopuszczalne reprezentacje graficzne klas w języku UML.
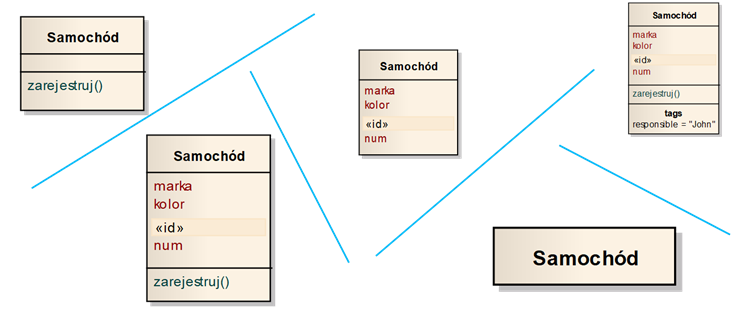
Rysunek 2.1: Reprezentacje klas o różnym poziomie szczegółowości
Najprostszą reprezentacją klasy jest prostokąt zawierający wyśrodkowaną nazwę klasy. Ikona klasy może zawierać kilka przegródek, oddzielonych liniami poziomymi. Najczęściej spotykane są reprezentacje składające się z jednej, dwóch lub trzech przegródek. Pierwsza przegródka od góry zawiera nazwę klasy, druga zwiera jej atrybuty, a trzecia – operacje. Język UML dopuszcza tworzenie większej liczby przegródek w zależności od potrzeb. W przykładzie na rysunku 2.1 reprezentacja w prawym górnym rogu zawiera dodatkową przegródkę na tzw. metki (ang. Tag), które określają meta-atrybuty klasy (np. informacje o wersji klasy czy osobie odpowiedzialnej). Na danym diagramie klas, poszczególne przegródki mogą być ujawnione (zwinięte) lub nie.
Przykłady notacji języka UML dla atrybutów przedstawione są na rysunku 2.2. Atrybuty definiują własności opisujące obiekty danej klasy, którym da się przypisać konkretną wartość. Posiadają one konkretne nazwy oraz mogą mieć określny typ. Przykłady notacji języka UML dla operacji widzimy na rysunku 2.3. Operacje reprezentują możliwe sposoby zachowania modelowanych obiektów poprzez określenie możliwych do wykonania funkcji lub procedur. Podobnie jak w przypadku atrybutów, operacje posiadają zdefiniowaną nazwę oraz mogą posiadać typ zwracanego rezultatu. Operacje odróżniane są od atrybutów poprzez podanie parametrów umieszczonych w nawiasach. Dla przykładu, operacja „ObliczCene” na rysunku 2.3 zawiera dwa parametry o nazwach „znizka” oraz „podatek”.
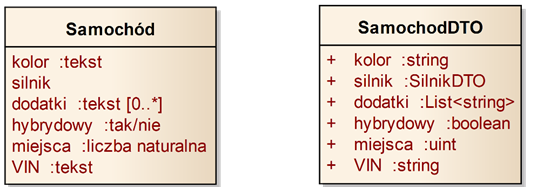
Rysunek 2.2: Przykładowe klasy z pokazanymi atrybutami

Rysunek 2.3: Przykładowe klasy z pokazanymi operacjami
W przykładzie na rysunku 2.2 możemy zauważyć dodatkowe oznaczenie dla jednego z atrybutów – „dodatki”. Oznaczenie to określa tzw. krotność (ang. Multiplicity) lub inaczej – liczność. Krotność dla atrybutów ujmujemy w nawiasy kwadratowe i podajemy jako zakres, np. [1..5] oznacza zakres od 1 do 5. Znak ‘*’ oznacza dowolną wartość, czyli zakres [0..*] oznacza zakres od zera do nieskończoności.
Dodatkowym oznaczeniem składników klasy, używanym najczęściej podczas modelowania kodu, jest widoczność. Widoczność możemy określić zarówno dla atrybutów, jak i operacji. Rodzaje widoczności w języku UML odpowiadają najczęstszym rodzajom widoczności w obiektowych językach programowania. Widoczność publiczną znakiem ,,+''. Widoczność prywatną oznaczamy znakiem ,,-''. Widoczność chronioną (ang. protected) oznaczamy znakiem „#”.
Język UML umożliwia również definiowanie własnych typów prostych, za pomocą tak zwanych typów wyliczeniowych (and. enumeration). Umożliwiają one zdefiniowanie typu poprzez określenie listy wartości dla tego typu. Przykładowy typ wyliczeniowy wraz z przykładem jego zastosowania został przedstawiony na rysunku 2.4.
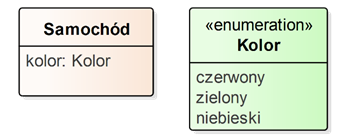
Rysunek 2.4: Przykład typu wyliczeniowego wraz z zastosowaniem
Oznaczenie wykorzystywane w notacji typów wyliczeniowych nosi nazwę stereotypu. Stereotypy możemy nadawać dowolnym elementom języka UML omawianym w tym i kolejnych rozdziałach, czyli w szczególności również klasom. Umożliwiają on nadanie dodatkowego (np. bardziej precyzyjnego) znaczenia danemu elementowi modelu. W ten sposób możemy tworzyć nowe, własne rodzaje elementów, które pochodzą od elementów standardowych. Szereg istniejących elementów języka UML również używa oznaczenia za pomocą stereotypów. Przykładem są omówione powyżej typy wyliczeniowe oraz interfejsy, które będą omówione w dalszej części rozdziału. Stereotyp jest określany poprzez podanie jego nazwy w nawiasach kątowych (tzw. nawiasy francuskie). Przykłady stereotypów przedstawione są na rysunku 2.5. Stereotyp może być powiązany z określeniem nowego kształtu dla danego elementu modelu. Dla przykładu, na rysunku, stereotypowi «UI Element» został przypisany kształt elementu ekranowego (okienka). Po nadaniu elementowi tego stereotypu, kształt ikony dla tego elementu może się zmienić ze standardowego na przypisany do stereotypu. Zwróćmy zatem uwagę, że mechanizm stereotypów pozwala rozszerzać notację języka UML w sposób praktycznie nieograniczony.

Rysunek 2.5: Przykładowe elementy języka UML z nadanymi stereotypami
Zgodnie z definicją modelowania struktury, diagramy klas, oprócz klas powinny zawierać również różnego rodzaje relacji między klasami. Najczęściej używanymi relacjami na diagramach klas są relacje asocjacji oraz relacje generalizacji. Relacja asocjacji posiada dwa bardziej wyspecjalizowane warianty – relacje agregacji i kompozycji. Często są również stosowane relacje zależności oraz relacje realizacji.
Relacja asocjacji definiuje możliwe powiązania między obiektami klas. Obiekty na końcach asocjacji mogą mieć zdefiniowane określone role. Asocjacje oznaczamy linią łączącą odpowiednie klasy. Role klas możemy zapisać jako nazwy końców asocjacji. Końce asocjacji mogą również definiować krotności dla uczestniczących w relacji obiektów. Krotność określa, ile obiektów danej klasy może potencjalnie być powiązanych z określonym obiektem klasy przeciwnej. Krotności oznaczane są w tej sam sposób jak dla atrybutów (bez nawiasów kwadratowych) – podajemy zakres możliwych wartości. Warto zauważyć, że asocjacja może odzwierciedlać również powiązania między różnymi obiektami tej samej klasy. W takiej sytuacji, asocjacja łączy klasę z samą sobą za pomocą „zawiniętej” linii.
Przykłady asocjacji przedstawia rysunek 2.6. Jak widzimy, między dwoma klasami możemy zdefiniować kilka asocjacji, które określają różne role dla powiązań między obiektami. Dana osoba może występować np. w roli kierowcy lub w roli właściciela dla danego pojazdu. Może również być jednocześnie kierowcą i właścicielem. Zgodnie z diagramem, konkretna osoba może posiadać dowolnie dużo (od 0 do wielu) samochodów oraz może kierować (w danej chwili) maksymalnie jednym samochodem (krotność od zera do jednego). Z kolei samochód może mieć dokładnie jednego właściciela oraz maksymalnie jednego kierowcę. Zwróćmy uwagę na to, że krotność „dokładnie jeden” możemy oznaczyć zarówno jako „1..1” jak i po prostu jako „1”. Ponadto – z założenia – brak określenia krotności dla danego końca asocjacji (lub np. dla atrybutu) oznacza krotność „1”.
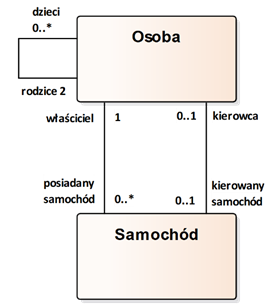
Rysunek 2.6: Przykładowe zastosowania asocjacji
Na rysunku 2.6 widzimy również asocjację dotyczącą tylko klasy „Osoba” (asocjacja „zawinięta”). Zgodnie w tym fragmentem modelu, dana osoba ma dokładnie dwóch rodziców oraz może mieć dowolnie dużo dzieci.
Specjalną własnością asocjacji jest tzw. nawigowalność (skierowanie asocjacji). Nawigowalność oznacza możliwość efektywnego osiągnięcia obiektów jednej klasy przez obiekty drugiej klasy. Inaczej mówiąc, obiekty jednej klasy „wiedzą” o istnieniu odpowiednich obiektów innej klasy i mogą korzystać z ich usług, np. odczytywać ich atrybuty lub uruchamiać ich operacje (dotyczy to tylko elementów o widoczności publicznej). Nawigowalność asocjacji oznaczamy poprzez dodanie grotu strzałki na końcu asocjacji. Zwróćmy uwagę na to, że strzałki możemy umieścić na wszystkich końcach asocjacji, czyli na obydwu końcach w przypadku asocjacji między dwoma klasami. Przy okazji warto wspomnieć, że asocjacje mogą łączyć jednocześnie więcej klas.
Przykład asocjacji nawigowalnej jest przedstawiony na rysunku 2.7. Z rysunku wynika, że obiekty klasy „Dowód rejestracyjny” mają dostęp do danych odpowiadających im samochodów, natomiast obiekty klasy „Samochód” nie mają zdefiniowanego dostępu do danych przypisanych do nich dowodów rejestracyjnych.
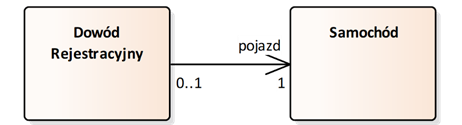
Rysunek 2.7: Przykład asocjacji nawigowalnej
Specjalnym rodzajem asocjacji są relacje agregacji. Stosujemy je, kiedy potrzebne jest odzwierciedlenie związku między grupą, a jej elementem lub elementami. Relacja agregacji jest zatem relacją grupowania, na przykład grupowania składników (części) pewnej całości. Relacja agregacji stosuje wszystkie elementy notacji asocjacji i dodatkowo jest wyróżniana poprzez umieszczenie małej ikony rombu po jednej stronie relacji. Romb umieszczany jest przy tej klasie, która stanowi całość. Przykład relacji agregacji widzimy na rysunku 2.8. Klasa „Samochód” stanowi element grupujący (całość), a klasa „Bagaż” definiuje elementy grupowane (składniki).
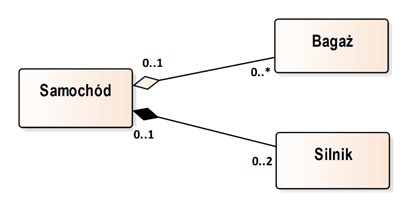
Rysunek 2.8: Przykład zastosowania agregacji i kompozycji
Rysunek 2.8 zawiera również relację między klasami „Samochód” i „Silnik”. Jest ona oznaczona podobnie jak relacja agregacji, lecz ikona rombu jest wypełniona. Jest to relacja kompozycji, która stanowi „silniejszą” wersję relacji agregacji. Reprezentuje ona związek pomiędzy całością a jej integralnymi częściami. Istotną cechą relacji kompozycji jest zasada, że obiekty odpowiadające składnikom nie mogą być zawarte w więcej nić jednym obiekcie odpowiadającym całości. Inaczej mówiąc – w relacji kompozycji składniki nie mogą być dzielone między różne całości. Dlatego też, krotność po stronie całości nie może być większa niż 1. W naszym przykładzie na rysunku 2.8, każdy silnik może być zawarty w co najwyżej 1 samochodzie (ew. może nie być zawarty w żadnym samochodzie). Przy okazji, warto też zwrócić uwagę na krotność po drugiej stronie tej relacji. Wynika z niej, że samochód może posiadać maksymalnie 2 silniki (np. silnik spalinowy i elektryczny). Dodatkowym wyróżnikiem relacji kompozycji jest to, że składniki zazwyczaj powstają i kończą swoje istnienie razem z całością, do której należą – czas życia składników jest ograniczony czasem życia całości (np. silniki samochodu są złomowane razem z samochodem). Ten aspekt relacji kompozycji jest szczególnie istotny podczas modelowania struktury kodu, gdyż definiuje proces tworzenia i destrukcji obiektów składowych. Warto jednak podkreślić, że różnica między relacjami asocjacji, agregacji i kompozycji jest dosyć płynna. Ich stosowanie często zależy od konkretnej dziedziny problemu, kontekstu zastosowania oraz celu danego modelu.
Bardzo ważnym aspektem modelowania obiektowego jest tworzenie taksonomii klas. W obiektowych językach programowania umożliwia to mechanizm dziedziczenia. W języku UML taksonomie tworzymy za pomocą relacji generalizacji-specjalizacji (w skrócie – generalizacji). Relacja generalizacji określa zależność pomiędzy klasami obiektów bardziej ogólnych i klasami obiektów bardziej specjalizowanych. Klasy specjalizowane „dziedziczą” po klasie ogólnej wszystkie jej atrybuty, operacje oraz relacje (asocjacje, agregacje, kompozycje, generalizacje). Oznacza to, że obiekty klasy specjalizowanej posiadają wszystkie elementy zdefiniowane w danej klasie, oraz dodatkowo – wszystkie elementy pochodzące z klasy ogólnej. Język UML dopuszcza również możliwość generalizacji wielobazowej. Klasy mogą zatem specjalizować jednocześnie kilka klas ogólnych. Warto jednak zwrócić uwagę na to, że niektóre języki programowania nie dopuszczają dziedziczenia wielobazowego. W takiej sytuacji należy oczywiście unikać stosowania generalizacji wielobazowej w modelu kodu.
Relacje generalizacji oznaczamy strzałką z dużym grotem w kształcie trójkąta. Strzałka zwrócona jest od klasy specjalizowanej do klasy ogólnej (wskazuje na klasę ogólną). Przykłady zastosowania relacji generalizacji widzimy na rysunku 2.9. Od klasy ogólnej „Pojazd” specjalizują dwie klasy – „Samochód” oraz „Samolot”. Z relacji tych wynika, że obiekty klasy Samochód będą posiadać 4 atrybuty (liczba kół, limit pasażerów, VIN i kolor), a obiekty klasy Samolot – trzy (liczba kół, limit pasażerów, zasięg lotu).
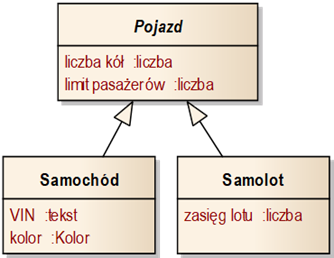
Rysunek 2.9: Przykład zastosowania generalizacji i klas abstrakcyjnych
W relacjach generalizacji często spotykamy klasy na tyle ogólne, że nie posiadają z zasady żadnych obiektów będących ich instancjami. Takie klasy nazywamy klasami abstrakcyjnymi. Używa się ich przede wszystkim w celu przedstawiania cech wspólnych innych klas. Reprezentacja klasy abstrakcyjnej różni się od zwykłej klasy w ten sposób, że jej nazwa zapisana jest kursywą. W przykładzie na rysunku 2.9 klasą abstrakcyjną jest klasa Pojazd. Oznacza to, że w rzeczywistości opisywanej tym diagramem nie istnieją pojazdy jako takie. Konkretny pojazd musi być albo samochodem, albo samolotem, czyli instancją jednej z klas specjalizujących po klasie Pojazd.
Klasy abstrakcyjne stosowane są zarówno w modelowaniu rzeczywistości (modele dziedziny) jak i w modelowaniu kodu. Warto tutaj zwrócić uwagę na to, że w wielu językach programowania istnieją konstrukcje umożliwiające definiowanie klas abstrakcyjnych. Inną konstrukcją używaną podczas programowania, analogiczną do klas abstrakcyjnych jest interfejs. Interfejsy, podobnie jak klasy abstrakcyjne nie posiadają instancji. Zasadniczą rolą interfejsów jest definiowanie zestawów operacji opisujących usługi dostarczane przez określone podsystemy. Stosowanie interfejsów pozwala na oddzielenie specyfikacji funkcjonalności (interfejs) od jej implementacji (konkretna klasa). W odróżnieniu od klas abstrakcyjnych, interfejsy zazwyczaj nie posiadają atrybutów, a jedynie operacje. W języku UML interfejsy modelujemy podobnie jak klasy, przy czym dodatkowo oznaczamy stereotypem «interface». Inną metodą oznaczenia interfejsu jest umieszczenie ikonki ‘○’ (okręgu) w prawym górnym rogu ikony interfejsu.
Notację interfejsów ilustruje rysunek 2.10. Na rysunku, interfejs „IPulaSamochodow” jest implementowany przez klasę „MPulaSamochodow”. Implementacja interfejsu przez klasę w języku UML modelowana jest za pomocą relacji realizacji. Relacja ta jest notacyjnie podobna do relacji generalizacji, przy czym strzałka jest rysowana linią przerywaną. Warto zauważyć, że klasa „MPulaSamochodow” powtarza wszystkie operacje realizowanego interfejsu. W ten sposób wskazujemy, że klasa ta posiada metody (kod wykonawczy) dla odpowiednich operacji interfejsu.

Rysunek 2.10: Przykład interfejsu wraz realizującą go klasą
5.2. Model komponentów i model wdrożenia
Kod systemu oprogramowania może składać się z setek lub nawet tysięcy klas. Czyni to model klas bardzo złożonym i powoduje trudności w zapanowania nad tą złożonością. Najczęściej stosowaną techniką panowania nad złożonymi systemami jest podział całości na mniejsze podsystemy lub komponenty.
Kolejną techniką ułatwiającą panowanie nad złożonością systemów jest stosowanie dobrze określonych interfejsów pomiędzy komponentami. Interfejs definiuje „fasadę” dla komponentu, poprzez którą z danym komponentem komunikują się inne komponenty. Ważne jest to, że wnętrze komponentu zostaje ukryte za fasadą i nie jest dostępne z zewnątrz. Komunikacja poprzez interfejsy pozwala ograniczyć kanały komunikacji wewnątrz systemu. Pozwala to zmniejszyć wzajemne zależności między klasami, które utrudniają diagnozę ewentualnych błędów.
Naszym celem jest ukrycie szczegółów i koncentracja na najważniejszych elementach. Do tego celu możemy wykorzystać model komponentów. Podstawową jednostką modelu komponentów jest komponent, którego notacja w języku UML jest przedstawiona na rysunku 2.11. Komponenty reprezentowane są podobnie do klas, czyli w formie prostokątów z nazwą. Zasadniczo, nie posiadają one jednak dodatkowych przegródek na atrybuty i operacje. Aby odróżnić komponenty od klas oznaczamy je specjalną ikoną w prawym górnym rogu. Na diagramach komponentów umieszczamy komponenty wraz z interfejsami. Interfejsy dostarczane przez komponent oznaczane są specjalną „wypustką” zakończoną okręgiem. Interfejsy wymagane przez komponent różnią się tym, że wypustka zakończona jest półokręgiem. Zwróćmy uwagę na to, że oznaczenia interfejsów na diagramach komponentów wykorzystują analogię wtyczki i kontaktu. Interfejs wymagany i dostarczany można połączyć ze sobą tworząc odpowiednią relację między komponentami.

Rysunek 2.11: Podstawowe elementy notacji komponentu
Łatwo zauważyć, że diagram komponentów ukrywa wiele szczegółów. Jeśli chcemy przedstawić ogólną strukturę systemu, tworzymy diagram komponentów. Jeśli chcemy przedstawić szczegóły struktury poszczególnych komponentów, pokazujemy szczegółowe diagramy klas zawierające definicje interfejsów i klas je realizujących. Oczywiście, na diagramie komponentów możemy uwidaczniać wiele komponentów oraz relacje między nimi. Rysunek 2.12 przedstawia najważniejsze elementy notacyjne dla relacji między komponentami. Relacje najczęściej modelujemy za pomocą relacji zależności (strzałka z przerywaną linią). Najbardziej podstawową metodą jest łączenie interfejsu wymaganego z interfejsem dostarczanym (patrz: „ISystemMagazynowy” na rysunku 2.12). Skróconą metodą zapisu jest pominięcie interfejsu wymaganego i połączenie komponentu zależnością bezpośrednio z interfejsem dostarczanym przez inny komponent (patrz: „IPulaSamochodów”). Jeszcze bardziej zwartą metodą zapisu jest zastosowanie tzw. połączenia montażowego (ang. Assembly). Jest to specjalny rodzaj relacji, którego notacja wykorzystuje połączone notacje interfejsu wymaganego i dostarczanego (patrz: „IZamowienia”). Możliwe jest również połączenie zależnością komponentów w sposób bezpośredni – bez interfejsu. Takie połączenie tworzymy najczęściej wtedy, kiedy komponenty komunikują się w sposób inny niż proceduralny (np. poprzez zapytania SQL). Takie zależności warto wtedy oznaczyć dodatkowym stereotypem (patrz stereotyp «SQL» na rysunku 2.12).
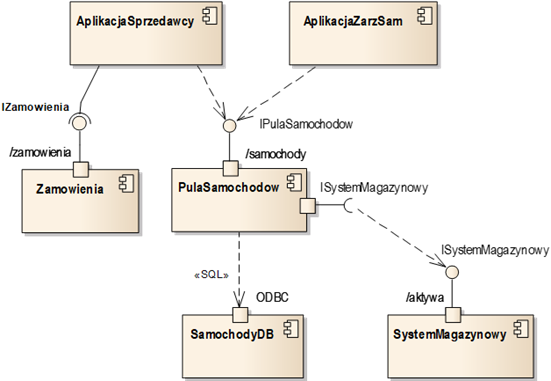
Rysunek 2.12: Przykładowy diagram komponentów
Rysunek 2.12 prezentuje jeszcze jeden istotny element diagramów komponentów – tzw. porty. Port oznacza punkt interakcji komponentu, służący do komunikacji z otoczeniem (np. udostępnieniem usług). Port reprezentowany jest za pomocą małego kwadratu umieszczonego na krawędzi komponentu. Opcjonalna nazwa portu może być umieszczona obok ikony portu. Port może stanowić miejsce powiązania interfejsu z komponentem. Mówimy wtedy, że interfejs jest udostępniany (albo wymagany) poprzez odpowiedni port. Port może mieć różne znaczenie zależne od technologii stosowanej do komunikacji między komponentami. Przykładowo w technologiach stosujących usługi typu REST, port może definiować punkt dostępu (ang. endpoint) z odpowiednim adresem względnym określonym w nazwie portu (patrz np. porty „/samochody” i „/zamówienia” na rysunku 2.12). W technologiach dostępu do relacyjnych baz danych, port może odpowiadać uchwytowi połączenia bazodanowego (np. ODBC).
Model komponentów definiuje ogólną logiczną strukturę systemu. Często jednak konieczne jest również przedstawienie struktury fizycznej, czyli sprzętowej oraz powiązanie jej ze struktura logiczną. Do tego celu wykorzystujemy model wdrożenia, inaczej nazywany modelem montażu (ang. Deplyment Model). Fizyczne składniki systemu, stanowiące środowisko działania oprogramowania, nazywane są węzłami (and. Node). Węzłami mogą być na przykład serwery, komputery osobiste, urządzenia mobilne i maszyny wirtualne. Reprezentacją węzłów są prostopadłościany z umieszczoną wewnątrz nazwą. Miedzy węzłami można poprowadzić asocjacje (jak w modelu klas) oznaczające określone ścieżki komunikacyjne. Asocjacje mogą być wyposażone w krotności definiujące możliwe liczby węzłów danego typu. Węzły z relacjami asocjacji zostały zilustrowane na rysunku 2.13. Zgodnie z tym modelem, system powinien obejmować węzeł (np. duża farma serwerów) typu „Klaster SZS” oraz wiele połączonych z nim węzłów typu „Magazyn”, „Sprzedaż”, „Komputer Klienta” i „Smartfon Klienta” (co najmniej 1 dla pierwszych dwóch). Dodatkowo, Klaster SZS łączy się z węzłami typu „Serwer Producenta Samochodów” oraz „Serwer Managzynu”. Zwróćmy uwagę na to, że węzłom (tak jak dowolnym elementom modeli w języku UML) może3my nadawać stereotypy. W naszym przykładzie, stereotypy («kubernetes cluster», «pc computer») doprecyzowują rodzaj węzła z punktu widzenia zastosowanego rozwiązania technologicznego (klaster serwerów w technologii Kubernetes, komputer PC).
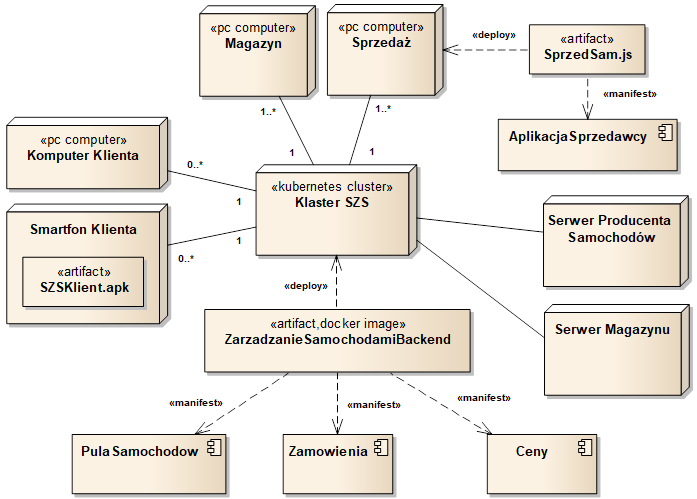
Rysunek 2.13: Przykładowy diagram wdrożenia
Na diagramach wdrożenia możemy również umieszczać tzw. artefakty (ang. Artifact), które reprezentują elementy wykonywane w odpowiednich węzłach. Artefakty najczęściej oznaczają pliki wykonywalne zgodne z konkretną technologią (np. pliki EXE w systemie Windows, pliki APK w systemie Android, pliki JS wykonywane w przeglądarkach internetowych). Notacja dla artefaktów przypomina notację dla komponentów, przy czym wyróżnikiem jest umieszczenie stereotypu «artifact». Artefakty mogą być „montowane” w węzłach. Rysunek 2.13 pokazuje dwa możliwe sposoby zaznaczenia montażu artefaktów. Pierwszy z nich polega na umieszczeniu ikony artefaktu wewnątrz ikony węzła (patrz „SZSKlient.apk”). Drugi polega na zastosowaniu specjalnej relacji zależności (tzw. relacji montażu) oznaczonej stereotypem «deploy» (patrz „SprzedSam.js” i „ZarzadzanieSamochodamiBackend”). Przy okazji zauważmy, że elementy języka UML mogą mieć nadane wiele stereotypów. W naszym przykładzie artefaktowi „ZarzadzanieSamochodamiBackend” nadaliśmy dodatkowy stereotyp «docker image», który sygnalizuje technologię wykonania tego artefaktu (tzw. obraz w technologii Docker).
Artefakty stanowią połączenie modelu fizycznego i logicznego. Modelują one bowiem fizyczne elementy (np. plik), które wyrażają odpowiednie komponenty, czyli składniki logicznej struktury systemu. Na diagramach wdrożenia możemy również pokazać tego typu zależności. Stosujemy w tym celu tzw. relację wyrażania, oznaczaną stereotypem «manifest». Na rysunku 2.13 widzimy kilka takich relacji, które wskazują na komponenty przedstawione w modelu komponentów (por. rysunek 2.12).
3. Modelowanie dynamiki systemu
Każdy modelowany system podlega zmianom. Obiekty składające się na system wchodzą we wzajemne interakcje, wykonują określone akcje oraz zmieniają swój stan. Przez model dynamiki rozumiemy więc przedstawianie przedmiotu modelowania od strony istotnych zmian jakim on podlega.
3.1. Model przypadków użycia
Częstą potrzebą podczas modelowania systemu oprogramowania jest potrzeba zidentyfikowania elementarnych jednostek funkcjonalności systemu z punktu widzenia jego użytkowników. Aby zidentyfikować funkcjonalność systemu z punktu widzenia jego użytkowników powinniśmy w pierwszej kolejności zdefiniować tychże użytkowników. W języku UML do tego celu wykorzystujemy aktorów. Aktor definiuje klasę obiektów spoza modelowanego systemu.
Podstawową notacją aktora w języku UML jest ikona człowieka
narysowana prostymi kreskami, co ilustruje rysunek 3.1 (ikona po lewej
stronie). Częstą praktyką jest nadawanie stereotypu «system» aktorom definiującym
zewnętrzne systemy informatyczne (ikona w środku rysunku). Nadanie
stereotypu może być również związane ze zmianą kształtu ikony.

Rysunek 3.1: Warianty notacji aktora
Możliwe jest stosowanie relacji generalizacji między
aktorami. Przykład zastosowania tych relacji widzimy na rysunku 3.2.
Dziedziczeniu podlegają głównie relacje aktorów z przypadkami użycia.
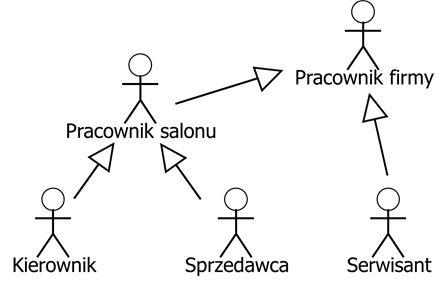
Rysunek 3.2: Relacje generalizacji dla aktorów
Dla aktorów i przy ich udziale realizowane są wspomniane na początku „elementarne jednostki funkcjonalności”, czyli – przypadki użycia systemu. Przypadek użycia definiujemy jako klasę zachowań modelowanego systemu (tzw. podmiotu), prowadzących do osiągnięcia obserwowalnego, istotnego rezultatu dla jakiegoś aktora (lub aktorów).
Podstawową notacją dla przypadków użycia w języku UML jest ikona elipsy, co ilustruje rysunek 3.3. Nazwa przypadku użycia może być umieszczona pod lub wewnątrz elipsy. Jako ciekawostkę można przytoczyć wariant notacji, który stosuje ikonę klasy.

Rysunek 3.3: Warianty notacji przypadku użycia
Każdy przypadek użycia powinien mieć jasno określony cel, który powinien wynikać z jego nazwy. Ważne jest, aby nazwy były pisane w jednolitej formie. Można na przykład przyjąć formę polecenia (np. „Zarejestruj pojazd”, „Dodaj użytkownika”, „Pokaż …”, „Obsłuż …”).
Sposobem na realizację celu określonego w nazwie przypadku użycia jest wymiana komunikatów miedzy aktorem (lub aktorami) a system. Komunikaty te przeplatane są także akcjami systemu, których skutki są następnie widoczne dla aktorów. Pierwszy komunikat pochodzi zazwyczaj od aktora, który uruchamia daną funkcjonalność. Przypadek użycia powinien definiować wszystkie możliwe alternatywne zachowania systemu prowadzące do danego celu. Te alternatywy mogą prowadzić do zadanego celu inną drogą niż podstawowy sposób zachowania. Mogą również kończyć się niepowodzeniem – cel nie zostanie osiągnięty mimo podjęcia próby jego osiągnięcia.
Na diagramach przypadków użycia umieszczamy aktorów i przypadki użycia wraz z łączącymi je relacjami. Na rysunku 3.4 widzimy diagram zawierający przykłady takich relacji. Najczęściej spotykaną jest relacja asocjacji między aktorem i przypadkiem użycia. Relacja ta oznacza możliwość uczestnictwa danego aktora w powiązanym z nim przypadku użycia. W ramach takiego uczestnictwa, aktor może być tzw. aktorem głównym. Oznacza to, że aktor uruchamia dany przypadek użycia i jest on realizowany na jego rzecz. Udział aktora jako aktora głównego możemy zaznaczyć poprzez zastosowanie asocjacji nawigowalnej, skierowanej do przypadku użycia.
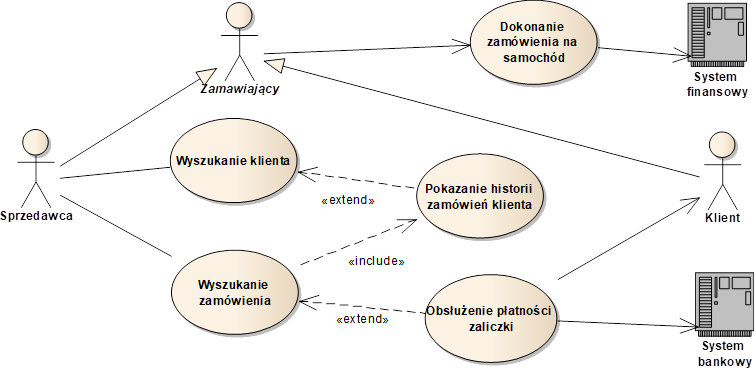
Rysunek 3.4: Przykładowy diagram przypadków użycia
Aktor może również pełnić rolę poboczną (pomocniczą) w relacji z przypadkiem użycia. Oznacza to, że aktor zaczyna brać udział dopiero w dalszych krokach scenariuszy danego przypadku użycia. Uczestnictwo aktora pomocniczego możemy zaznaczyć poprzez zastosowanie nawigowalności asocjacji skierowanej w stronę tegoż aktora.
Oprócz relacji między aktorami i przypadkami użycia często stosowane są relacje między przypadkami użycia. Język UML standardowo definiuje dwie relacje zależności – relację «include» i relację «extend». Relacja «include» („wstawienie”) oznacza bezwarunkowe włączenie w treść scenariuszy jednego przypadku użycia, treści scenariuszy innego. Na rysunku 3.4 widzimy jedną taką relację, oznaczoną przerywaną strzałką z odpowiednim stereotypem.
Druga z nich to relacja «extend» („rozszerzenie”). Oznacza ona możliwość wplecenia treści scenariuszy przypadku użycia rozszerzającego w treść scenariuszy przypadku użycia rozszerzanego. Możliwość wplecenia może podlegać określonym warunkom, które powinny być dołączone do specyfikacji danej relacji «extend». W najprostszym przypadku, wplecenie warunkowane jest przez wybraniem opcji uruchamiającej rozszerzający przypadek użycia podczas wykonywania rozszerzanego przypadku użycia.
Semantyka relacji «include» i «extend» oparta jest na bezwarunkowym lub warunkowym wstawianiu treści jednych przypadków użycia w treść innych. Zrozumienie tej semantyki często sprawia kłopoty. Z tego powodu powstała propozycja alternatywy - relacji «invoke». Relacja ta ma semantykę podobną do semantyki wywołania procedury. Zawsze jest skierowana od przypadku wywołującego do przypadku wywoływanego. Wywołanie może być bezwarunkowe lub możemy dla niego określić warunek. Rysunek 3.5 pokazuje fragment zawierający aktora i przypadki użycia z rysunku 3.4, gdzie zamiast standardowych relacji zastosowano relacje «invoke».
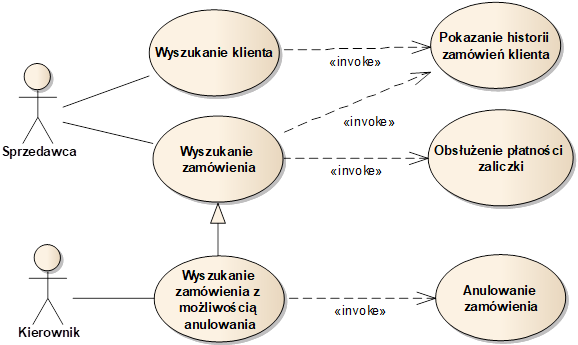
Rysunek 3.5: Wykorzystanie relacji «invoke»
Podobnie jak dla aktorów, również między przypadkami użycia możliwe jest stosowanie relacji generalizacji. Oznacza ona, że przypadek użycia specjalizowany dziedziczy cechy przypadku użycia ogólnego. Rysunek 6.5 dostarcza nam odpowiedniego przykładu.
6.2. Model czynności
Częstą potrzebą podczas modelowania systemów jest przedstawienie jakiegoś procesu w postaci schematu blokowego. Oznacza to konieczność zbudowania modelu składającego się z akcji oraz przepływów sterowania między akcjami, czyli modelu czynności. Zadaniem modelu czynności jest połączenie takich akcji w sieć (graf) opisującą kolejność ich wykonywania.
Rysunek 3.6 przedstawia przykładowy diagram, który posłuży nam do wyjaśnienia notacji modelu czynności. Diagramy czynności stanowią grafy, przy czym wyróżniamy w nich kilka rodzajów węzłów. Najbardziej typowym węzłem są akcje, oznaczane ikoną prostokąta z zaokrąglonymi rogami. Wewnątrz ikony umieszczona jest treść akcji, która powinna stanowić nazwę elementarnej operacji wykonywanej w ramach opisywanego procesu (np. „dokonanie płatności zaliczki”). Akcje mogą posiadać wypustki (ang. Pin) oznaczane małymi kwadratami umieszczonymi na krawędziach akcji. Wypustki służą definiowaniu danych przepływających między akcjami i oznaczane są zazwyczaj nazwą tych danych (np. „dowód rejestracyjny”). Do oznaczania decyzji służą węzły decyzyjne (ang. Decision Node) oraz węzły scalenia (ang. Merge Node). Obydwa rodzaje węzłów oznaczane są ikoną rombu (diamentu). Obok ikony węzła decyzyjnego można umieścić treść podejmowanej decyzji, często w formie pytania (np. „jaka dostępność?”). Na diagramach czynności możemy również zaznaczać ciągi akcji wykonywanych równolegle. Do tego celu wykorzystujemy belki synchronizacji. Belka rozwidlenia (ang. Fork) pozwala rozdzielić sterowanie między kilka równoległych przepływów akcji. Z kolei belka złączenia (ang. Join) pozwala połączyć równoległe przepływy akcji w jeden. Belki synchronizacji rysujemy jako poziome lub pionowe grube kreski. Każdy diagram czynności powinien również zawierać węzeł początkowy (duża czarna kropka) oraz węzły końcowe (mała czarna kropka z obwódką).
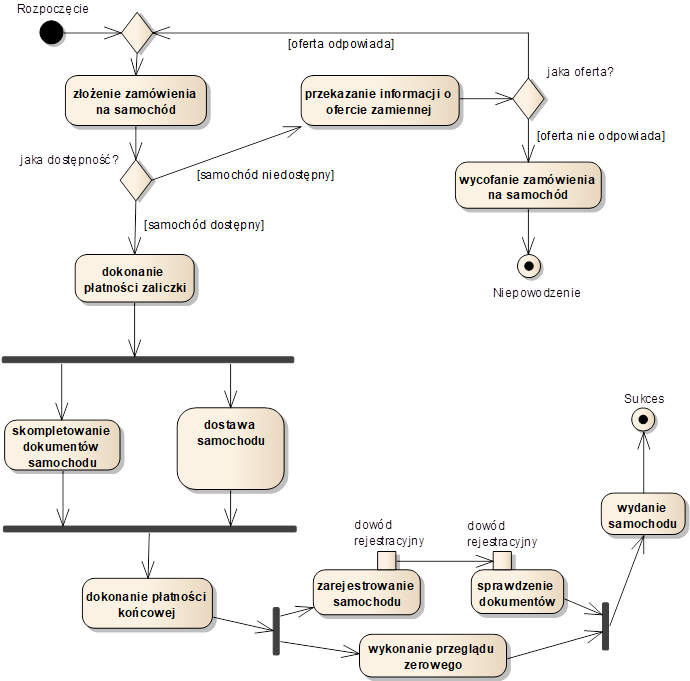
Rysunek 3.6: Przykładowy diagram czynności
Między węzłami umieszczamy przepływy sterowania (ang. Control Flow) lub przepływy obiektów (ang. Object Flow). Obydwa rodzaje przepływów mają taką samą notację strzałki. Obok strzałki możemy umieścić warunek (ang. Guard), który zapisujemy jako tekst umieszczony w nawiasach kwadratowych (np. „[samochód dostępny]”). Przepływ sterowania oznacza proste przejście między węzłami, natomiast przepływ obiektów dodatkowo oznacza przesłanie między akcjami określonego zestawu danych. Przepływy obiektów umieszcza się najczęściej między wypustkami akcji. W ten sposób możliwe jest łatwe określenie danych przesyłanych takimi przepływami.
Działanie opisywane diagramem czynności kończy się w momencie dotarcia do węzła końcowego. W tym momencie wszystkie pozostałe akcje są przerywane (jeśli działają) i działanie całego systemu opisywanego diagramem jest przerywane. Istnieją również specjalne węzły końcowe, tzw. węzły końca przepływu (ang. Flow Final Node). Dotarcie do takiego węzła nie kończy działania całego systemu, a jedynie danej gałęzi. Węzły końca przepływu reprezentowane są za pomocą okręgu ze znakiem „X” w środku.
Bardziej skomplikowane sieci akcji możemy dzielić na mniejsze elementy. W tym celu, możemy definiować tzw. węzły czynności (ang. Activity Node). Czynność jest podobna do akcji w tym sensie, że definiuje jakąś operację wykonywaną przez obiekty danego systemu. Różnica polega na tym, że czynność nie jest operacją elementarną, ale może składać się z wielu akcji.
3.3. Model maszyny stanów
Bardzo podobnym w swojej notacji do modelu czynności jest model maszyny stanów. Podstawowa różnica jest taka, że węzły w diagramach maszyny stanów definiują stany, a nie akcje.
Odpowiedni diagram jest przedstawiony na rysunku 3.7. Stany (ang. State) reprezentowane są za pomocą ikony prostokąta z zaokrąglonymi rogami. Każdy stan określa pewną stabilną konfigurację systemu (np. obiektu), która może trwać w czasie. Między stanami prowadzimy przejścia (ang. Transition), oznaczane strzałkami. Przejścia mogą być opisane przez podanie tzw. wyzwalacza (ang. Trigger). Wyzwalacz odpowiada konkretnemu zdarzeniu, które powoduje zmianę stanu.
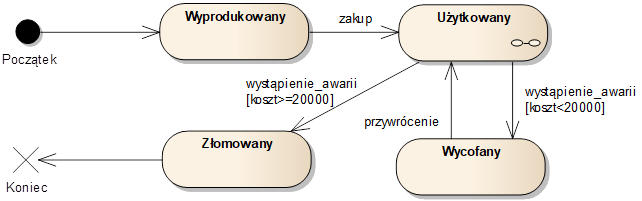
Rysunek 3.7: Przykładowy diagram maszyny stanów
Wyzwalacz może być dodatkowo wyposażony w warunek, zgodnie ze standardową notacją warunków w języku UML (napis w nawiasach kwadratowych). W przypadku wystąpienia zdarzenia określonego wyzwalaczem, dodatkowo badany jest warunek. Przejście między stanami następuje jedynie w razie spełnienia tego warunku.
Na diagramie maszyny stanów występują również tzw. pseudostany. Najczęściej używanymi pseudostanami są pseudostan początkowy oraz pseudostan terminalny. Pseudostan początkowy (ang. Initial Pseudostate) oznacza stan, w którym rozpoczyna się działanie maszyny stanów (np. stan obiektu zaraz po jego utworzeniu). Na diagramie, taki pseudostan połączony jest zawsze jednym przejściem z jednym stanem właściwym. Analogicznie, pseudostan terminalny (ang. Terminal Pseudostate) oznacza możliwe stany, w których znajduje się maszyna stanów (np. obiekt) przed jej skasowaniem (zakończeniem działania). Do pseudostanu terminalnego może prowadzić wiele przejść ze stanów właściwych.
3.4. Model sekwencji
Przedstawione wyżej modele czynności reprezentują procesy jako ciągi akcji wykonywanych przez różne obiekty. Często jednak przydatne jest przedstawienie procesu jako sekwencji komunikatów wymienianych między obiektami. Do tego celu możemy wykorzystać modele sekwencji.
Podstawowymi elementami diagramów sekwencji są linie życia (ang. Lifeline) oraz komunikaty (ang. Message), co ilustruje rysunek 3.8. Linia życia reprezentuje działanie jednego obiektu. Rysujemy ją jako pionową przerywaną linię zakończoną u góry ikoną obiektu. Między liniami życia umieszczamy komunikaty, które oznaczane są jako strzałki. Kolejność przesyłania komunikatów wynika z kolejności ich umieszczenia na diagramie, który czytamy z góry na dół. Przesłanie komunikatu w jednego obiektu do drugiego powoduje wykonanie jakiejś operacji przez obiekt docelowy. Wykonanie operacji zaznaczamy tzw. belką wykonania (ang. Execution Specificaton). Belka taka rysowana jest jako wąski prostokąt nałożony na linię życia obiektu, do którego kierowany jest komunikat. Po otrzymaniu takiego komunikatu, obiekt ten podejmuje działanie zaznaczone odpowiednią belką wykonania.
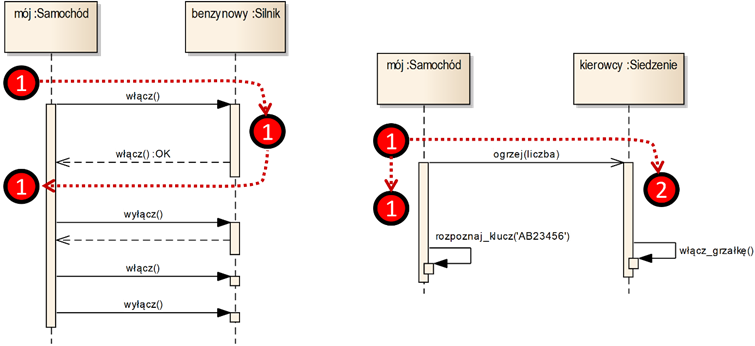
Rysunek 3.8: Podstawowe elementy notacji diagramów sekwencji
Zasadniczo wyróżniamy trzy rodzaje komunikatów. Komunikaty synchroniczne (ang. Synchronous Message) oznaczane są strzałką z wypełnionym grotem. Komunikaty takie najczęściej powiązane są z komunikatami zwrotnymi, oznaczanymi strzałką z pustym grotem, pisaną linią przerywaną. Znaczenie komunikatów synchronicznych i zwrotnych wyjaśnia diagram po lewej stronie rysunku 3.8. Wysłanie komunikatu synchronicznego „włącz()” powoduje przekazanie sterowania z obiektu „mój:Samochód” do obiektu „benzynowy:Silnik”, co symbolizuje żeton „1”. Drugi z tych obiektów podejmuje działanie („włącza się”), a pierwszy przechodzi w stan oczekiwania. Po wykonaniu operacji przez silnik, sterowanie (żeton „1”) wraca do samochodu. Oznaczane to jest komunikatem zwrotnym „włącz():OK”. Po zwróceniu mu sterowania, samochód może podjąć dalsze działania, w tym np. przesłać kolejne komunikaty. Jak widzimy, dwa obiekty synchronizują swoje działania, gdyż jeden czeka na zakończenie działania drugiego.
Trzecim rodzajem komunikatów są komunikaty asynchroniczne (ang. Asynchronous Message), które oznaczamy strzałką z pustym grotem. Znaczenie komunikatów asynchronicznych wyjaśnia diagram po prawej stronie rysunku 3.8. Wysłanie komunikatu „ogrzej(liczba)” powoduje powstanie dwóch ścieżek sterowania (wątków), oznaczonych żetonami „1” i „2”. Obydwie ścieżki działają równolegle, co oznacza, że obydwa obiekty mogą wykonywać swoje operacje w tym samym czasie. W przeciwieństwie do sytuacji z komunikatem synchronicznym, tutaj obiekt „mój:Samochód” nie czeka na zakończenie działania operacji „ogrzej()”. W naszym przykładzie, obiekt „kierowcy:Siedzenie” uruchamia operację „włącz_grzałkę()”, a w tym samym czasie obiekt „mój:Samochód” uruchamia operację „rozpoznaj_klucz()”. Przy okazji widzimy notację komunikatów kierowanych przez obiekty do samych siebie. Ważną cechą komunikatów asynchronicznych jest brak związanych z nimi komunikatów zwrotnych.
Na diagramach sekwencji możemy również definiować cykl życia obiektów. Obiekty mogą być tworzone i niszczone w wyniku przesyłania komunikatów od innych obiektów. Przykład takich komunikatów widzimy na rysunku 6.9. Pierwszy z komunikatów jest komunikatem utworzenia (ang. Create Message). Oznaczamy go strzałką przerywaną prowadzącą od jakiejś linii życia do ikony obiektu rozpoczynającej inną linię życia. Ikona obiektu jest rysowana nas poziomie komunikatu, co ma symbolizować utworzenie obiektu w wyniku tego komunikatu. Zakończenie życia (zniszczenie) obiektu zaznaczamy znakiem „X” umieszczonym na końcu linii życia. Najczęściej, obiekt kończy życie w wyniku otrzymania komunikatu, co ilustruje rysunek 3.9 (komunikat „skasuj”).
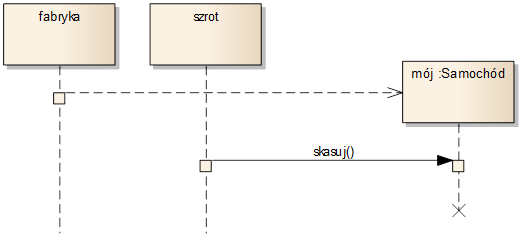
Rysunek 3.9: Tworzenie i kasowanie obiektów na diagramie sekwencji
Na diagramach sekwencji możemy modelować przebiegi alternatywne oraz pętle. Używamy wtedy tzw. fragmentów łączonych (ang. Combined Fragment) wyrażanych za pomocą prostokątnych ramek obejmujących odpowiednie komunikaty. Typ ramki określony jest w polu znajdującym się w lewym górnym rogu ramki. Najczęściej stosowane są ramki typu „alt”, „opt” i „loop”. Po nazwie typu ramki można umieścić jej nazwę.
Przykłady ramek „alt” i „loop” widzimy na rysunku 3.10. Najbardziej zewnętrzna jest ramka „alt” o nazwie „uruchomienie”. Ramka taka podzielona jest przerywanymi poziomymi liniami na kilka części. Każda część oznaczona jest warunkiem umieszczonym w nawiasach kwadratowych. Działanie ramki polega na tym, że wykonywane są komunikaty zawarte w obszarze, dla którego spełniony jest warunek.
Ostatnią (tutaj – najbardziej wewnętrzną) ramką na rysunku 3.10 jest ramka „loop” (pętla) o nazwie „ogrzewanie siedzeń”. Ramka taka oznacza wykonanie zawartej w niej sekwencji komunikatów dopóki spełniony jest określony warunek.
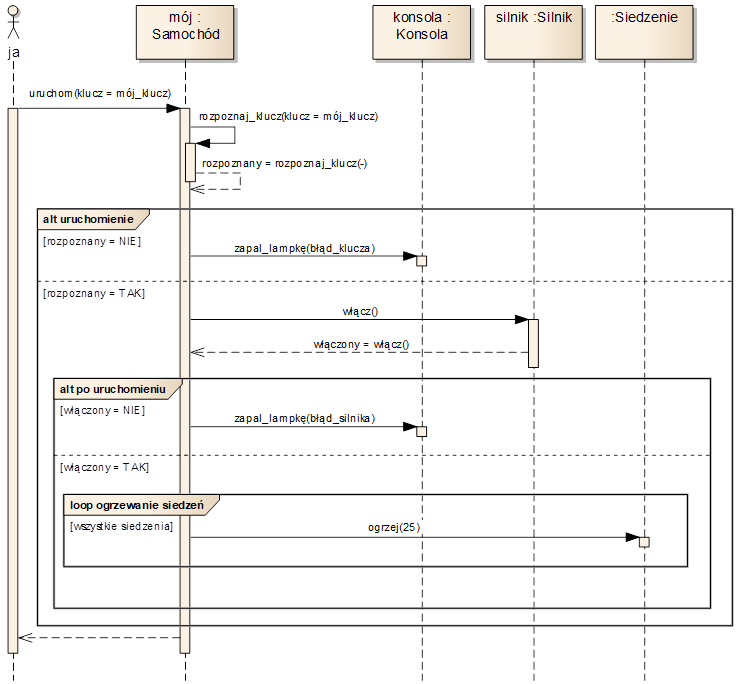
Rysunek 3.10: Przykładowy diagram sekwencji z ramkami „alt” i „loop”
W poprzednich przykładach, diagramy sekwencji były tworzone na poziomie modelu klas. Często jednak korzystne jest pokazanie dynamiki wymiany komunikatów między komponentami, m.in. za pośrednictwem ich interfejsów. Odpowiedni przykład widzimy na rysunku 3.11. Etykiety komunikatów odpowiadają operacjom interfejsów przedstawionych na diagramie definiującym komponent „PulaSamochodow”. Istotnym elementem notacyjnym jest linia życia interfejsu „IPulaSamochodow”, która jest „zagnieżdżona” w linii życia obiektu komponentu „PulaSamochodow”.
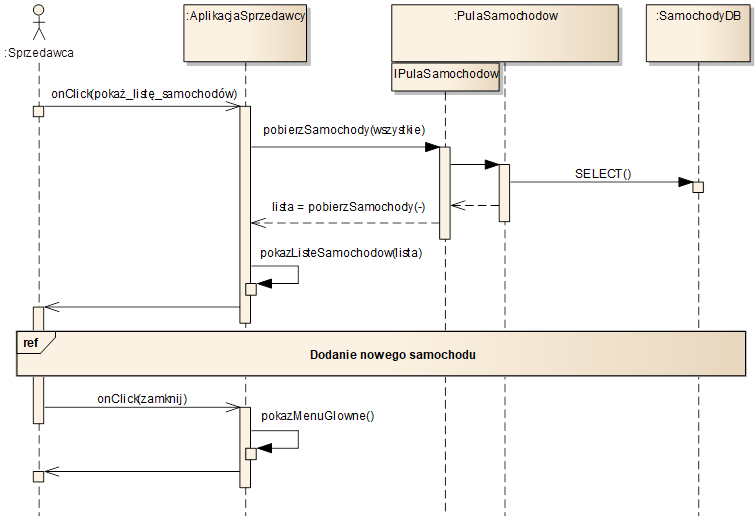
Rysunek 3.11: Realizacja przypadku użycia „Pokazanie listy samochodów”
Charakterystycznym elementem na rysunku 3.11 jest ramka typu „ref” (referencja) z etykietą „Dodanie nowego samochodu”. Jest to tzw. użycie interakcji (ang. Interaction Use). Ramka ta oznacza odniesienie do innego diagramu interakcji (tu: sekwencji). Znaczenie tej ramki referencji jest takie, że cały diagram z rysunku 3.12 jest niejako wstawiany w miejsce ramki.
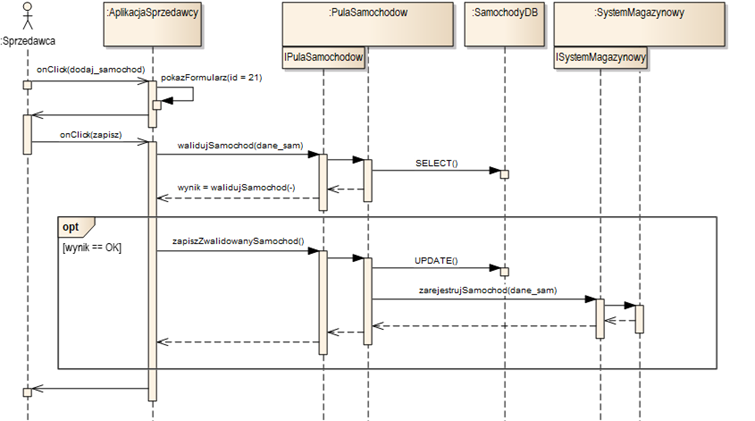
Rysunek 3.12: Realizacja przypadku użycia „Dodanie nowego samochodu”
Rysunek 3.12 ilustruje zastosowanie ramki „opt” (opcja). Jest to niejako wariant ramki „alt” zawierający tylko jeden warunek. Zawartość ramki wykonywana jest tylko w przypadku spełnienia warunku. W przeciwnym razie cała zawartość ramki jest pomijania w wykonaniu danej sekwencji.
Analizując diagram na rysunku 3.12, jak również wszystkie diagramy poprzednie, warto zwrócić uwagę na ciągłość przepływu sterowania. W typowych zastosowaniach, komunikaty powinny tworzyć spójną sekwencję, gdzie kolejne komunikaty wynikają bezpośrednio z poprzednich. Ponadto, komunikaty nie powinny pojawiać się „znikąd”, ale mieć swoje źródło w belce wykonania, która wynika z poprzednich komunikatów w sekwencji. Inaczej mówiąc, komunikaty nie powinny występować w miejscach, w których dany obiekt nie otrzymał wcześniej sterowania.