Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | 3. Podstawy inżynierii wymagań i projektowania oprogramowania |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | czwartek, 20 listopada 2025, 19:02 |
Opis
Podstawowym pojęciem inżynierii wymagań jest oczywiście „wymaganie”. Wymaganie to jako własność produktu końcowego (systemu oprogramowania), którą musi on posiadać, aby spełnić oczekiwania zamawiającego. Mówi się, że system spełnia wymagania, jeśli zostało potwierdzone, że posiada wszystkie własności określone tymi wymaganiami.
Na tej podstawie możemy również określić, czym jest inżynieria wymagań. Jest to dyscyplina inżynierii oprogramowania, która obejmuje działania polegające na zbieraniu, analizowaniu, negocjowaniu i specyfikowaniu (zapisywaniu) wymagań. Głównym produktem tej dyscypliny jest specyfikacja wymagań, która jest podstawą efektywnego kosztowo wytworzenia systemu oprogramowania zgodnego z oczekiwaniami zamawiającego.
1. Wprowadzenie do inżynierii wymagań
1.1. Rola wymagań w inżynierii oprogramowania
Podstawowym pojęciem inżynierii wymagań jest oczywiście „wymaganie”. Wymaganie to jako własność produktu końcowego (systemu oprogramowania), którą musi on posiadać, aby spełnić oczekiwania zamawiającego. Mówi się, że system spełnia wymagania, jeśli zostało potwierdzone, że posiada wszystkie własności określone tymi wymaganiami.
Na tej podstawie możemy również określić, czym jest inżynieria wymagań. Jest to dyscyplina inżynierii oprogramowania, która obejmuje działania polegające na zbieraniu, analizowaniu, negocjowaniu i specyfikowaniu (zapisywaniu) wymagań. Głównym produktem tej dyscypliny jest specyfikacja wymagań, która jest podstawą efektywnego kosztowo wytworzenia systemu oprogramowania zgodnego z oczekiwaniami zamawiającego.
Można powiedzieć, że jakość wymagań jest kluczowym elementem powodzenie każdego projektu konstrukcji systemu oprogramowania. Źle sformułowane wymagania są bardzo częstą przyczyną niepowodzeń. Z drugiej strony, można powiedzieć, że dobre sformułowanie wymagań polega na dobrym odzwierciedleniu rzeczywistych potrzeb zamawiającego. W szczególności, dobrej jakości wymagania powinny charakteryzować się kilkoma podstawowymi cechami.
Wymagania powinny być kompletne. Oznacza to, że
powinny one obejmować cały zakres potrzeb zamawiającego, opisany w niezbędnych
szczegółach.
Drugą istotną cechą wymagań jest ich jednoznaczność i
poprawność. Takie wymagania powinny definiować jeden możliwy zakres
systemu, i nie pozostawiać pola do różnych interpretacji. Aby zapewnić
jednoznaczność i poprawność, należy stale upewniać się, że wymagania są
przejrzyste dla zamawiającego, ale również – że są zrozumiałe dla deweloperów.
Wymagania powinny być również spójne, czyli
niesprzeczne. Eliminacja sprzeczności polega na ciągłym wzajemnym porównywaniu
wymagań ze sobą, szczególnie wymagań różnych rodzajów. Sprzeczności często
prowadzą do problemów podczas realizacji systemu.
Kolejna cecha dobrej specyfikacji wymagań to możliwość
zarządzania. Wymagania powinny być podzielone na dobrze określone
jednostki, które mogą sterować procesem wytwórczym. Powinny one być na tyle
małe, aby można było je przydzielać do wykonania w stosunkowo krótkich
odcinkach czasu (np. w ciągu jednej iteracji/sprincie). Jednocześnie, poszczególne
wymagania powinny mieć przypisane
odpowiednie atrybuty pozwalające na efektywne przydzielanie ich do
wykonania w trakcie projektu.
Bardzo istotną, można powiedzieć – kluczową cechą wymagań
jest ich testowalność (mierzalność). Wymaganie, którego nie jesteśmy w
stanie przetestować jest nic niewarte. Stosunkowo prosto jest sformułować testy
dla wymagań funkcjonalnych. Sprawa jest trudniejsza w przypadku wymagań
jakościowych. Konieczne jest opracowanie odpowiednich metryk, które pozwolą na
jednoznaczne potwierdzenia spełnienia takich wymagań.
Ważne jest, aby źródłem wymagań były osoby (zamawiający, użytkownicy) dobrze umocowane i reprezentatywne. W szczególności mogą to być kluczowi użytkownicy (np. kierownicy zespołów, doświadczeni konsultanci wewnętrzni, mentorzy) oraz kluczowi sponsorzy projektu (kierownicy wysokiego szczebla, którym zależy na powodzeniu projektu).
Bardzo istotnym składnikiem inżynierii wymagań jest zarządzanie wymaganiami. Polega na ciągłym upewnianiu się, że rozwiązujemy właściwy problem i budujemy właściwy system. Dzieje się to poprzez systematyczne podejście do: 1) zbierania, 2) organizowania, 3) dokumentowania, 4) wykorzystywania, zmieniających się wymagań na system oprogramowania. Zarządzamy wymaganiami ponieważ nie są one oczywiste i pochodzą z wielu źródeł. Poza tym, zarządzanie dotyczy różnych rodzajów wymagań oraz różnych poziomów ich szczegółowości. W typowym systemie oprogramowania możemy wyróżniać setki lub nawet tysiące wymagań, które musimy w odpowiedni sposób uporządkować. Należy również zawsze pamiętać, że wymagania podlegają ciągłym zmianom, wynikającym np. ze zmian otoczenia biznesowego lub warunków w ramach organizacji zamawiającej oprogramowanie.
Kluczowe w zarządzaniu wymaganiami jest umiejętne podzielenie całego zbioru wymagań klienta na odpowiednie jednostki, czyli pojedyncze wymagania. Każde wymaganie to jedna charakterystyka systemu, który mamy zbudować. Aby móc efektywnie zarządzać wymaganiami musimy je móc w jednoznaczny sposób identyfikować. Wymaganie powinno mieć nazwę (jedno krótkie zdanie) oraz treść (reprezentację, w postaci kilku akapitów tekstu, czy niedużego modelu graficznego). Wymagania powinny także mieć odpowiedni zbiór atrybutów, które ułatwiają zarządzanie nimi. Bardzo pomocne jest, na przykład, nadanie wymaganiom numerów identyfikacyjnych, priorytetów, czy określenie osób za nie odpowiedzialnych.
Zarządzanie wymaganiami to również zarządzanie zmianami
wymagań. Jest to nieodłączny element każdego projektu. Zmiany wymagań wynikają
ze zmieniających się warunków prawnych, biznesowych czy organizacyjnych. Zmiany
mogą też wynikać z niezdecydowania klienta lub niezrozumienia jego potrzeb.
Mogą też wynikać z polityki wewnątrz organizacji zamawiającej oprogramowanie. Niezależnie
od przyczyn, należy podkreślić, że praktycznie nie istnieją nietrywialnie
projekty, podczas których nie dochodzi do zmiany wymagań. Niestety, czasami
nawet najmniejsza zmiana sformułowania wymagania może rodzić bardzo poważne
konsekwencje dla realizowanego systemu. Dlatego też, każda zmiana wymagań
powinna być traktowana z bardzo dużą uwagą.
1.2. Specyfikowanie środowiska systemu
W dzisiejszych czasach elementem niemal każdej organizacji
biznesowej jest jakiś system oprogramowania. Systemy oprogramowania wspierają
co najmniej część działalności przedsiębiorstw, a w wielu przypadkach są
fundamentem tej działalności, jak np. w przypadku handlu elektronicznego. Różnego rodzaju organizacje i przedsiębiorstwa funkcjonujące
w określonych środowiskach biznesowych również stanowią fragmenty otaczającego
nas świata. Aby zrozumieć daną organizację biznesową powinniśmy stworzyć
jej model.
Dokonując analizy przedsiębiorstwa, pierwszym pytaniem, na
które powinniśmy odpowiedzieć jest: gdzie przebiega granica naszego biznesu? Definicję
zakresu biznesu zaczynamy od definicji jego otoczenia. Otoczenie biznesu
definiujemy jako zbiór wszystkich jednostek współpracujących z biznesem. Tymi jednostkami
współpracującymi mogą być klienci, podwykonawcy, dostawcy podzespołów, spedytorzy,
zleceniodawcy, instytucje państwa, agenci, itd. Biznes może również
współpracować bezpośrednio z zewnętrznymi systemami informatycznymi.
Aby opisać współpracę powinniśmy przede wszystkim zidentyfikować i opisać przebieg procesów biznesowych. Żeby zrozumieć pojęcie procesu biznesowego należy zrozumieć samo pojęcie procesu. Ogólna definicja określa proces jako serię wzajemnie powiązanych zadań, które przekształcają dane wejście w wyjście. Należy zwrócić uwagę na dwa aspekty wynikające z tej definicji. Pierwszy aspekt związany jest z samym wyróżnianiem danego procesu oraz jego potencjalnymi interakcjami z innymi procesami. Z tego punktu widzenia proces posiada wejście, wyjście oraz określone granice wyznaczające co konkretnie on obejmuje. Drugi aspekt dotyczy wewnętrznej struktury procesu. W celu jej pokazania trzeba dokładnie określić w jaki sposób tworzące go zadania są ze sobą powiązane i w jaki sposób prowadzi to do uzyskania oczekiwanego wyjścia na podstawie wejścia. Typowo, poszczególne zadania przedstawiane są w postaci sekwencji uporządkowanej w czasie. Proces biznesowy jest szczególnym rodzajem procesu, który wytwarza wartość dla jego odbiorcy. Innymi słowy wartość wyjścia z procesu jest większa niż jego wejścia z punktu widzenia danego biznesu. Podsumowując, można powiedzieć, że proces biznesowy:
- posiada jasno określone granice, wejście i wyjście,
- składa się z sekwencji uporządkowanych na przestrzeni czasu czynności,
- tworzy wartość dodaną dla określonego odbiorcy (beneficjenta procesu).
Istnieje wiele sposobów modelowania procesów biznesowych, w tym dedykowane do tego notacje, jak BPMN (Business Process Modeling Notation). Model czynności zawarty w języku UML posiada elementy, które są w znacznym stopniu analogiczne do elementów języka BPMN. Zaletą takiego rozwiązania jest możliwość łatwej synchronizacji modeli procesów biznesowych z innymi modelami. Na przykład, w celu określenia zakresu modelowanych procesów biznesowych możemy wykorzystać diagramy przypadków użycia. Przykładowy taki diagram widzimy na rysunku 1.1.

Rysunek 1.1: Procesy biznesowe
modelowanie jako przypadki użycia biznesu
Przypadek użycia biznesu możemy opisać wykorzystując diagram czynności. Przykładowy diagram modelujący proces biznesowy „Zakup części zamiennych on-line” przedstawiony jest na rysunku 1.2.
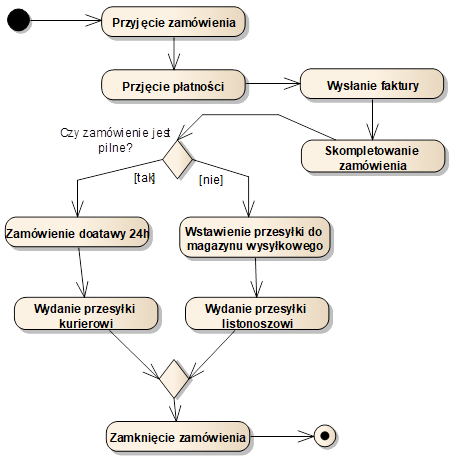
Rysunek 1.2: Diagram czynności opisujący proces
biznesowy
1.3. Struktura specyfikacji wymagań – rodzaje wymagań
Dobre praktyki inżynierii wymagań wskazują na
potrzebę jednoznacznego podziału specyfikacji zarówno pod kątem poziomu
abstrakcji (szczegółowości) wymagań jak i ich rodzaju. Dobrze zbudowana specyfikacja wymagań powinna mieć strukturę piramidy,
przedstawionej na rysunku 1.3. Szczyt
takiej piramidy stanowi ogólny opis systemu – jego wizja. Elementy wizji
systemu stanowią punkt wyjścia do sformułowania wymagań użytkownika określających
zakres budowanego systemu. Podstawą piramidy i jednocześnie jej największym fragmentem
są wymagania oprogramowania, wyrażające wszystkie szczegółowe potrzeby
zamawiającego. Na wszystkich poziomach piramidy formułujemy wymagania czterech
rodzajów: wymagania funkcjonalne, jakościowe, słownikowe, oraz ograniczenia środowiskowe
i techniczne.
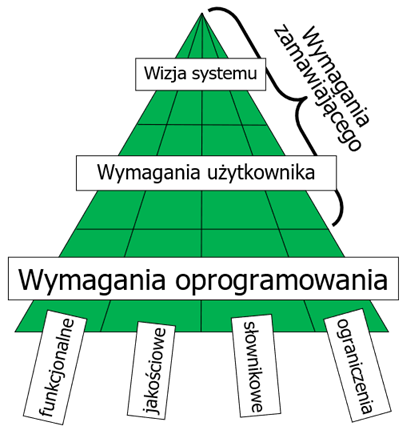
Rysunek 1.3: Organizacja specyfikacji wymagań
Należy tutaj podkreślić, że specyfikacja wymagań nie musi (a
często – nie powinna) być tworzona jako
jeden gruby dokument na początku całego procesu wytwarzania oprogramowania. W
metodykach iteracyjnych (zarówno zwinnych jak i sformalizowanych), wymagania są
zbierane i formułowane przez cały okres projektu. W wielu projektach konieczne
jest jednak sformułowanie formalnej umowy między zamawiającym a wykonawcą
systemu. Kluczowym elementem takiej umowy jest specyfikacja wymagań
zamawiającego. Z punktu widzenia struktury wymagań, taka
specyfikacja powinna objąć dwie górne warstwy piramidy. W ramach wymagań zamawiającego, zamawiający przedstawia swoje
rzeczywiste potrzeby związane z wspieraną przez system dziedziną swojej
działalności. Jednocześnie, określa zakres systemu na tyle jednoznacznie, żeby
możliwe było dokonanie wyceny budowanego systemu przez wykonawcę.
Wizja systemu ma charakter bardzo ogólny i nie powinna mieć charakteru wiążącego w kontaktach między zamawiającym a wykonawcą systemu. Celem jej jest sformułowanie intencji przyświecających rozwojowi systemu i wyszczególnienie problemów odkrytych w modelu biznesu zamawiającego. Kompletna wizja systemu powinna zawierać:
- opis problemu biznesowego, który jest podstawą dla powstania nowego systemu
- przedstawienie interesariuszy powstającego systemu, czyli osób bezpośrednio i pośrednio zainteresowanych powstaniem systemu
- ogólne cechy i funkcje systemu oraz słownik pojęć biznesowych,
- najważniejsze ograniczenia środowiskowe i techniczne przyszłego systemu,
- opcjonalnie - motto projektu, czyli krótki „slogan” oddający główny cel powstania produktu informatycznego.
Wymagania użytkownika definiują system w sposób na tyle szczegółowy, aby potencjalnie stanowić mniej lub bardziej formalną podstawę do kontroli postępów prac, w tym – zawarcia kontraktu na wykonanie systemu. Typowo, na wymagania użytkownika składają się wymagania funkcjonalne wyrażone przez uporządkowaną strukturę jednostek funkcjonalnych (np. przypadków użycia), definicje użytkowników i systemów zewnętrznych, słownik pojęć dziedziny wykorzystywanych podczas formułowania wymagań, istotne wymagania jakościowe oraz ograniczenia środowiskowe przyszłego systemu.
W trakcie prac na systemem, wymagania oprogramowania podlegają dokładnej specyfikacji – uszczegółowieniu. Odpowiada za to najbardziej szczegółowy poziom piramidy wymagań, czyli wymagania oprogramowania. Precyzja określenia wymagań oprogramowania powinna zapewniać jednoznaczność implementacji systemu przez zespół deweloperski. Na ich podstawie, zespół powinien móc zaprojektować i zakodować wszystkie komponenty systemu. Oznacza to, że w ramach specyfikowania wymagań oprogramowania konieczne jest szczegółowe ustalenie z zamawiającym scenariuszy zachowania systemu, wyglądu interfejsu użytkownika oraz struktury przetwarzanych przez system danych wraz z opisem algorytmów przetwarzania danych.
Na wszystkich poziomach piramidy wymagań powinien być
wyraźnie zachowany podział między różnymi rodzajami wymagań. Rodzaje
wymagań stanowią „kolumny” piramidy, gdyż na kolejnych poziomach stanowią
jednolitą całość, opisywaną w sposób coraz bardziej szczegółowy.
Wymagania funkcjonalne określają sposób zachowania się systemu w interakcji z jednostkami na zewnątrz tego systemu – użytkownikami (ludźmi) oraz systemami zewnętrznymi. W ramach specyfikacji wymagań funkcjonalnych powinniśmy odpowiedzieć na podstawowe pytanie: „co system ma robić?” W szczególności, specyfikacja powinna określać m.in. usługi dostarczane przez system, sposób reakcji na komunikaty dochodzące spoza systemu, sposób zachowania w określonych sytuacjach i przy aktualnym stanie systemu. Zestaw wymagań funkcjonalnych określa zakres funkcjonalności konieczny do zrealizowania przez zespół budujący system oprogramowania.
Wymagania jakościowe inaczej nazywamy wymaganiami pozafunkcjonalnymi. Stanowią one charakterystyki systemu określające sposób oceny działania systemu. O ile wymagania funkcjonalne definiują to, „co system powinien robić”, o tyle wymagania jakościowe definiują to, „jak system powinien coś robić”. System może realizować wszystkie wymagania funkcjonalne, lecz nadal nie spełniać oczekiwań zamawiającego. Może np. działać zbyt wolno, być zawodny lub nie spełniać kryteriów bezpieczeństwa.
Ograniczenia środowiskowe i techniczne określają warunki narzucone budowanemu systemowi przez jego otoczenie oraz konieczne do zastosowania technologie. Ograniczenia nie są zatem wymaganiami w sensie potrzeb zamawiającego. Stanowią one wymagania w sensie narzuconych przez zamawiającego warunków, w jakich będzie tworzony i uruchamiany system. Te warunki mogą dotyczyć środowiska, w jakim będzie pracował system (np. wyposażenie stanowisk pracy, warunki pogodowe), technologii wymaganych podczas budowy sytemu (np. posiadane licencje na system bazy danych) lub jego działania (np. posiadany przez zamawiającego sprzęt).
Wymagania słownikowe definiują zakres pojęć i danych, które są używane w ramach dziedziny problemu obejmującej budowany system. Słownik powinien zawierać na bieżąco aktualizowane definicje wszystkich pojęć używanych w ramach wymagań funkcjonalnych, jakościowych oraz ograniczeń. Definicje te wykonywane są na różnym poziomie szczegółowości. Na poziomie wizji, często wystarczy krótkie 1-2 zdaniowe wyjaśnienie znaczenia danego pojęcia. Na poziomie wymagań użytkownika konieczne jest określenie co najmniej najważniejszych atrybutów pojęć oraz wyspecyfikowanie relacji między pojęciami. Wymagania oprogramowania wprowadzają konieczność zdefiniowania wszystkich szczegółów dotyczących struktur danych, czyli stworzenie szczegółowego modelu danych.
Zbiór wszystkich wymagań stanowi specyfikację wymagań, która
może być wyrażona w sposób mniej lub bardziej sformalizowany. Często wymagane
jest stworzenie formalnego dokumentu, który będzie stanowił załącznik do umowy
miedzy zamawiającym z wykonawcą. Przykładową strukturę takiego dokumentu specyfikacji
wymagań zamawiającego przedstawia rysunek 1.4.
Struktura ta jest zgodna ze strukturą dwóch górnych warstw piramidy.
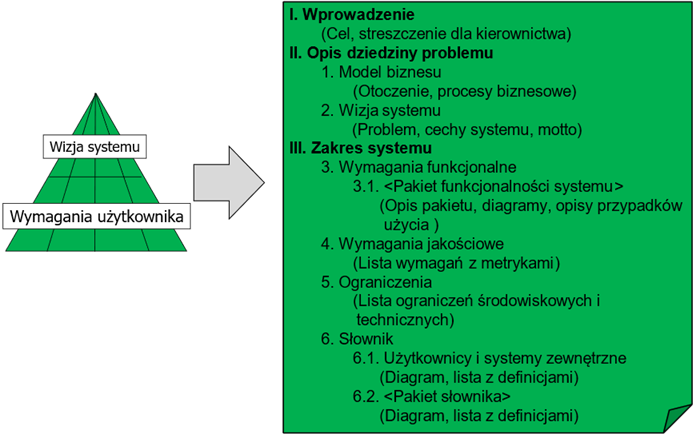
Rysunek 1.4: Przykładowa struktura dokumentu
specyfikacji wymagań zamawiającego
Warunki projektu mogą również narzucać tworzenie dokumentów wymagań już po zawarciu kontraktu. Struktura takich dokumentów może być rozwinięciem struktury specyfikacji wymagań zamawiającego, przedstawionej na rysunku 1.4. Jak wiemy, wymagania zamawiającego są uszczegóławiane w ramach specyfikowania wymagań oprogramowania. Dlatego też, dokument specyfikacji wymagań oprogramowania może zawierać uszczegółowienie elementów opisujących zakres systemu.
2. Podstawy specyfikowania wymagań
2.1. Specyfikowanie wizji systemu
Wizja systemu stanowi ona opis potrzeb zamawiającego w stosunku do potencjalnego systemu oprogramowania, wykonany na stosunkowo wysokim poziomie ogólności. Wizja systemu powinna dawać przede wszystkim odpowiedzi na następujące pytania:
- Po co budujemy nowy system?
- Jakie problemy naszego biznesu ten system rozwiąże?
- Dla kogo jest ten system?
- Jakie cechy ma mieć ten system, aby pokonać zidentyfikowane problemy?
Wizja systemu, mimo swej ogólności, powinna posiadać konkretną strukturę. Typowo, wizja zawiera stwierdzenie problemu, opis interesariuszy (grup zainteresowanych), podstawowe cechy sytemu i ograniczenia, a także – niekiedy – motto definiujące zasadniczy cel budowy systemu.
Pierwszym krokiem podczas analizy zasadności budowy systemu oprogramowania powinno być zdefiniowanie problemów, które ewentualny system mógłby rozwiązać. Opis problemu możemy sformułować w postaci stwierdzenia problemu (ang. problem statement). Powinno ono odpowiadać na pytanie „dlaczego potrzebujemy nowego oprogramowania?”.
Dla wyrażenia stwierdzenia problemu możemy skorzystać ze wzorca: "Problem polegający na …., dotyczący ….., którego rezultatem jest …., można rozwiązać budując system …., co spowoduje (korzyści) …. " .
Kolejnym elementem wizji systemu powinna być specyfikacja
interesariuszy (ang. stakeholder). Interesariuszami
są wszystkie te osoby, na których wdrożenie nowego systemu będzie miało
bezpośredni lub pośredni wpływ. Możemy wyróżnić kilka typowych grup
interesariuszy: użytkowników systemu, klientów organizacji biznesowej, zamawiających, dział IT. Podobnie jak dla stwierdzenia problemu, dla opisu grup
interesariuszy możemy wykorzystać wzorzec. Wzorzec może się składać z: nazwy interesariusza i typu, opisu interesariusza, zakresu obowiązków, kryteriów zadowolenia, zadań w projekcie.
Po zidentyfikowaniu problemu i interesariuszy możemy zająć się określaniem cech systemu. Cechy systemu stanowią odpowiedź na potrzeby poszczególnych grup zainteresowanych systemem. Na cechy systemu składają się dwa zasadnicze rodzaje wymagań: cechy funkcjonalne i cechy jakościowe. Cechy są stwierdzeniami na stosunkowo wysokim poziomie ogólności, i formułujemy je przy pomocy krótkich zdań w języku naturalnym. Ważne jest, aby formułując cechy systemu korzystać ze słownictwa używanego przez interesariuszy. Definicje poszczególnych pojęć powinniśmy umieścić w słowniku. W słowniku (np. w porządku alfabetycznym) umieszczamy używane w definicji cech systemu pojęcia, które mogą budzić wątpliwości. Poniższy przykład ilustruje wykorzystanie słownika do wyjaśnienia pojęć występujących w opisie cech systemu.
- Cecha F007: System musi umożliwiać zarządzanie modelami samochodów.
- Cecha J023: System powinien przyspieszyć przyjmowanie samochodów na stan o co najmniej 30%.
- Model samochodu – specyfikacja obejmująca nazwę producenta i nazwę modelu (np. „Fiak Tipi” lub „Opek Astal”) oraz wszystkie parametry techniczne serii samochodów.
- Samochód – konkretny egzemplarz danego modelu samochodu, posiadający unikany numer pojazdu oraz określony zestaw dodatkowego wyposażenia.
W powyższym przykładzie cechy systemu zostały oznaczone identyfikatorami. Przykładowo, cechy funkcjonalne są oznaczone identyfikatorem z przedrostkiem „F”, a cechy jakościowe – z przedrostkiem „J”. Identyfikator jest przykładem atrybutu wymagania. Zbiór atrybutów wymagań może obejmować na przykład następujące elementy: unikalny identyfikator, typ, status, waga dla zamawiającego, trudność wykonania, ryzyko, stabilność , osoba odpowiedzialna.
Podczas specyfikowania wizji systemu należy również wziąć pod uwagę ograniczenia. Ograniczenie oznacza zmniejszenie stopnia swobody, którą mamy podczas tworzenia i dostarczania systemu. Można wyróżnić wiele źródeł ograniczeń: techniczne, ekonomiczne, polityczne, prawne, środowiskowe i inne.
Ostatnim, opcjonalnym lecz często użytecznym elementem wizji systemu jest motto. Motto ma postać jednego czy dwóch zdań, które prosto i efektownie prezentują korzyści płynące z realizacji projektu.
2.2. Specyfikowanie wymagań użytkownika
Po podjęciu decyzji o budowie systemu powinniśmy określić jego zakres, a w ramach tego – zdefiniować jednostki wymagań, które umożliwią efektywne zarządzanie projektem. Specyfikacja wymagań użytkownika powinna dostarczyć odpowiedzi na kluczowe w procesie zarządzania projektem pytania.
- Jak obszerna będzie funkcjonalność systemu?
- Jakie dane będzie przetwarzał system?
- Kto będzie się posługiwał systemem?
- Ile system będzie kosztował i jak długo będzie trwała jego budowa?
Podstawowym założeniem dla przeprowadzenia analizy pod kątem wymagań użytkownika jest zgodność z wizją systemu oraz procesami biznesowymi. Ilustrację tej zasady widzimy na rysunku 2.1. Na podstawie procesu biznesowego zostało określone wymaganie funkcjonalne F098 na poziomie wizji systemu. W wyniku wywiadów oraz spotkań warsztatowych z klientem, wymaganie to zostało uszczegółowione poprzez ustanowienie trzech przypadków użycia (PU030, PU032 i PU033). Analogicznie, uszczegółowieniu podlegają wymagania jakościowe. W przykładzie na rysunku 2.1 widzimy, że ogólna cecha jakościowa J022 została uszczegółowiona w postaci wymagań J022-1 i J022-2.
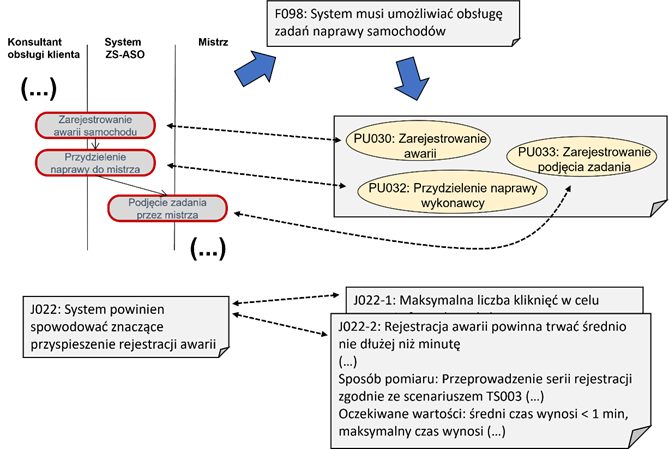
Rysunek 2.1: Identyfikacja
wymagań użytkownika na podstawie wizji i procesów biznesowych
Zidentyfikowane wymagania użytkownika dokumentujemy, aby mogły się stać podstawą do zawarcia kontraktu (mniej lub bardziej formalnej umowy) między zamawiającym a wykonawcą systemu, w tym - do określenia zasobów niezbędnych do realizacji systemu. Wymagania użytkownika powinny być zatem na tyle precyzyjne, aby nie było niedomówień co do zakresu systemu. Jednocześnie, powinny być na tyle ogólne, aby nie sugerować rozwiązań technicznych (dotyczących np. implementacji interfejsu użytkownika, baz danych, itp.), co jest dopiero zadaniem projektantów systemu.
Jednym z najczęściej spotykanych sposobów zapisu wymagań funkcjonalnych są przypadki użycia systemu. Punktem wyjścia do stworzenia modelu powinna być analiza cech systemu sformułowanych w wizji oraz analiza procesów biznesowych. Dla typowego systemu oprogramowania, model taki zawiera od kilkudziesięciu do nawet kilkuset przypadków użycia. W takiej sytuacji, konieczne jest umiejętne zarządzanie złożonością modelu. Podstawową techniką jest tutaj grupowanie w pakiety po kilka-kilkanaście przypadków użycia. Dla każdego pakietu tworzymy osobny diagram (czasami korzystne jest utworzenie dwóch-trzech diagramów). Na rysunkach 2.2 i 2.3 przedstawione są dwa przykładowe diagramy dla systemu obsługi sprzedaży samochodów.

Rysunek 2.2: Przykładowe przypadki użycia dla systemu
sprzedaży samochodów
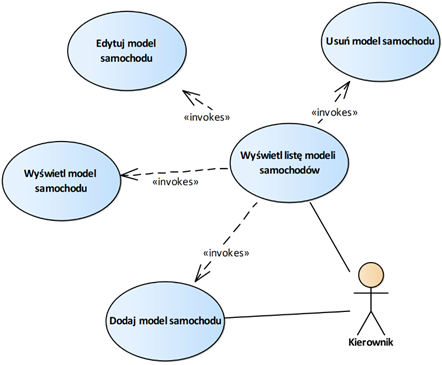
Rysunek 2.3: Przykład przypadków użycia realizujących
operacje CRUD
Alternatywnym do przypadków użycia sposobem formułowania wymagań funkcjonalnych są historie użytkownika. Historie użytkownika opisują oczekiwania klienta w stosunku do tworzonego systemu za pomocą krótkich zdań mieszczących się np. na kartkach z notesu. Zdanie stanowiące historię użytkownika powinno określać podmiot historii (użytkownik, który czegoś chce od systemu), cel biznesowy realizowany przez system i oczekiwany przez użytkownika, oraz motywację klienta stojącą za konkretnym oczekiwaniem. Do formułowania historii użytkownika można wykorzystać następujący prosty wzorzec:
- Jako <rodzaj użytkownika> chcę <jakiś cel>, aby <jakiś powód>
Kilka przykładowych historii użytkownika dla wcześniej
przedstawionej wizji, napisanych zgodnie z powyższym wzorcem przedstawia
rysunek 2.4.
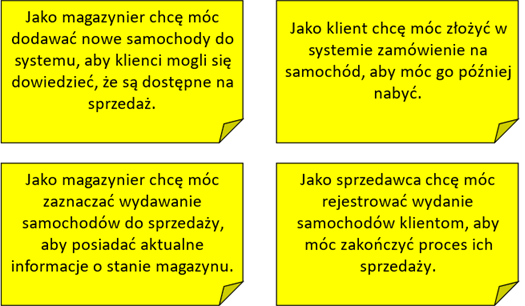
Rysunek 2.4: Przykłady historii
użytkownika
Drugim kluczowym składnikiem specyfikacji wymagań zamawiającego jest specyfikacja wymagań jakościowych, inaczej nazywanych wymaganiami pozafunkcjonalnymi. Bardzo istotne jest, aby zapewnić kompletność i jednoznaczność tego rodzaju wymagań. Kontrolę kompletności może nam zapewnić zachowanie zgodności z określoną taksonomią wymagań jakościowych. Istnieje wiele takich taksonomii, przy czym tutaj przestawimy chyba najbardziej szczegółową i wyczerpującą z nich, zawartą w normie ISO/IEC 25010:2011. Model jakości opisany w normie ISO 25010 zawiera następujący podział rodzajów wymagań jakościowych:
- Przydatność funkcjonalna (ang. Functional suitability) – dotyczy spełniania przez system wyrażonych wcześniej potrzeb.
- Efektywność wydajnościowa (ang. Performance efficiency) – dotyczy wydajności osiąganej przez system przy
założonych zasobach.
- Kompatybilność (ang. Compatibility) – dotyczy współpracy z
innymi systemami oprogramowania.
- Użyteczność (ang. Usability) – dotyczy
dostosowania sposobu użycia systemu do potrzeb użytkowników.
- Niezawodność (ang. Reliability)
– dotyczy zapewnienia określonego poziomu działania systemu przy założonych
zasobach.
- Bezpieczeństwo (ang. Security) – dotyczy ochrony danych
przez system.
- Łatwość utrzymania (ang. Maintainability)
– dotyczy minimalizacji nakładów pracy wymaganych podczas utrzymywania systemu
w eksploatacji.
- Przenośność (ang. Portability) – dotyczy możliwości działania oprogramowania na różnych środowiskach.
Aby móc sprawdzić stopień realizacji wymagań jakościowych należy określić dla nich metryki i związany z tym sposób testowania. Istotą testów cech jakościowych systemu jest jak największa obiektywizacja ich pomiaru. Pomiar można zdefiniować jako proces, w którym liczby lub znaki są przypisywane atrybutom obiektów świata rzeczywistego w taki sposób, aby opisać je zgodnie z jednoznacznie zdefiniowanymi zasadami. Pomiarom towarzyszą metryki – miary własności. Biorąc pod uwagę takie ogólne określenie pomiaru, można określić ogólny schemat definiowania metryk wymagań jakościowych. W skład metryki powinny wchodzić następujące elementy:
- sposób pomiaru (w tym: wymaganą liczbę wykonywanych pomiarów),
- zbiór możliwych wartości pomiaru (wraz z jednostką dla wartości liczbowych),
- oczekiwaną (akceptowalną) wartość (w tym: charakterystykę błędów).
Przykładowo, możemy w oparciu o analizę działania przedsiębiorstwa
dojść do wniosku, że wcześniej przedstawiona cecha J023 powinna się przekładać
na wykonanie w systemie czynności związanych z dodaniem na stan nowego
samochodu w czasie poniżej 2 minut. W
takim wypadku opis odpowiedniego wymagania jakościowego wraz z jego metryką
może wyglądać tak, jak przedstawiono na rysunku 2.5
– wymaganie JU038.
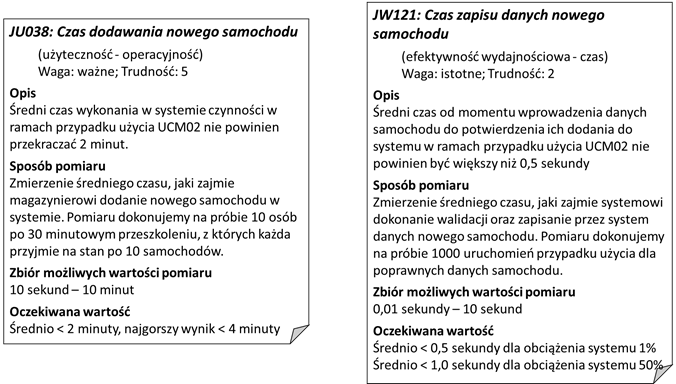
Rysunek 2.5: Przykłady
wymagań jakościowych wraz z metrykami
W celu zapewnienia spójności specyfikacji wymagań konieczne jest zdefiniowanie używanego słownictwa. Na poziomie wymagań użytkownika definicje pojęć danej dziedziny problemu powinny być znacznie bardziej precyzyjne niż na poziomie wizji. Pojęcia umieszczamy w słowniku dziedziny. Słownik dziedziny stanowi uporządkowany zbiór pojęć wraz z ich znaczeniami, za pomocą których można opisać wszystkie aspekty związane z określonym fragmentem rzeczywistości, a które są używane w specyfikacji wymagań użytkownika. Pojęcia w słowniku tworzą sieć powiązań (relacji) wzajemnych, tworząc pewnego rodzaju mapę danej dziedziny problemu.
Przykładowa reprezentacja graficzna słownika została przedstawiona na rysunku 2.6. Zawiera ona wybrane pojęcia z dziedziny sprzedaży samochodów, czyli tej, której dotyczą wymagania przedstawione w poprzedniej części tego rozdziału.
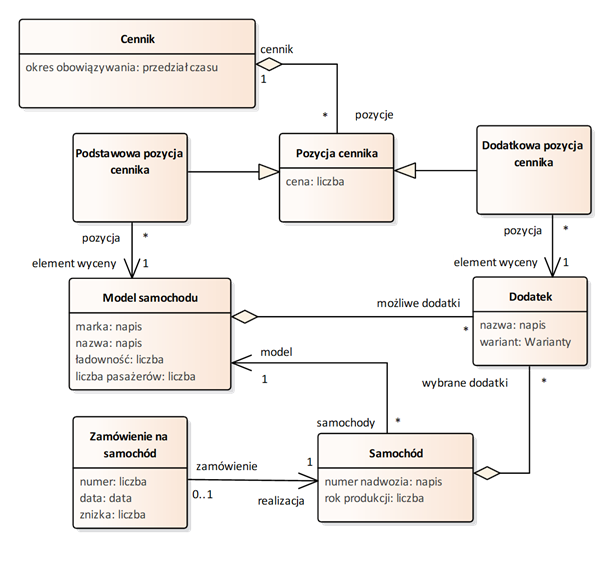
Rysunek 2.6: Przykładowa reprezentacja
graficzna słownika dziedzinowego jako diagramu klas
8.3. Specyfikowanie wymagań oprogramowania
Wymagania oprogramowania stanowią uszczegółowienie wymagań
użytkownika. Na tym poziomie piramidy wymagań, przypadki użycia zdefiniowane
podczas formułowania wymagań użytkownika są opisywane w szczegółach, poprzez
m.in. zdefiniowanie interakcji pomiędzy aktorami a systemem w postaci
scenariuszy przypadków użycia. W miarę tworzenia scenariuszy uszczegóławiany i
uzupełniany jest słownik dziedziny oraz ustalany jest wygląd interfejsu
użytkownika. Powstają również tzw. scenopisy, które łączą opis działania przypadków
użycia z wyglądem poszczególnych „scen”, czyli elementów wyświetlanych
użytkownikowi. Kompletna specyfikacja wymagań oprogramowania zawiera również rozbudowaną
specyfikację wymagań jakościowych, gdzie nowe lub zaktualizowane wymagania
wynikają z uszczegółowienia wymagań funkcjonalnych i słownika.
Podsumowując rolę wymagań oprogramowania, można powiedzieć, że dają one odpowiedź na trzy pytania:
- Jakie są szczegóły funkcjonowania systemu?
- Jakie dane będą przetwarzane przez system?
- Jakie inne szczegółowe cechy powinien mieć system?
Tego typu szczegóły są bardzo podatne na zmiany w miarę postępów prac nad systemem. Dlatego też, zazwyczaj formułuje się je bezpośrednio przed implementacją wybranego fragmentu funkcjonalności systemu. W cyklu iteracyjnym, dopiero po wybraniu zestawu przypadków użycia (lub historii użytkownika) do realizacji w danej iteracji, dokonuje się ich szczegółowego wyspecyfikowania.
Scenariusze określają w sposób precyzyjny interakcję użytkownika z systemem, prowadzącą do osiągnięcia określonego celu biznesowego. Scenariusz przypadku użycia powinien spełniać trzy cechy:
- opisywać sekwencję interakcji między aktorem i systemem,
- zaczynać się od interakcji aktora (w większości przypadków),
- kończyć się, kiedy zostanie osiągnięty cel przypadku użycia, lub kiedy na drodze do tego celu nastąpiła porażka.
Przypadek użycia jest zbiorem scenariuszy prowadzących do tego samego celu, w tym tych zakończonych porażką (rezygnacją, błędem lub sytuacją wyjątkową). Scenariusze przypadku użycia powinny definiować wszystkie alternatywne przebiegi obsługujące sytuacje wyjątkowe, z wyjątkiem tych najbardziej oczywistych, które mogą być opisane dla wielu przypadków użycia wspólnie (np. anulowanie wykonania operacji).
Pierwsze zdanie scenariusza jest w większości przypadków akcją inicjującą sekwencję współpracy pomiędzy użytkownikiem a systemem. Sekwencja taka jest zawsze inicjowana przez aktora dla głównych przypadków użycia (połączonych bezpośrednio z aktorem). Scenariusz może się zakończyć sukcesem (osiągnięciem celu biznesowego) bądź porażką (np. w wypadku wystąpienia sytuacji wyjątkowej).
Przykłady scenariuszy przypadku użycia spełniające powyższe zasady widzimy na rysunku 2.7. Zdania scenariuszy w tym przykładzie pisane są w prostej kontrolowanej gramatyce, która z jednej strony jest wystarczająca do kompletnego opisania interakcji aktor-system, a z drugiej na tyle prosta, aby scenariusze były przejrzyste i jednoznaczne. Oprócz zdań w gramatyce kontrolowanej, opisujących sekwencje wymiany komunikatów pomiędzy systemem a użytkownikiem, w scenariuszu mogą występować również zdania sterujące.

Rysunek 2.7: Przykładowe
scenariusze przypadku użycia
Podstawowym typem zdania scenariusza w gramatyce kontrolowanej jest zdanie typu POD(D) (Podmiot, Orzeczenie, Dopełnienie bliższe, opcjonalne Dopełnienie dalsze). Zdanie POD(D) składa się z podmiotu określającego wykonawcę akcji (np. „system”, „kierownik”), orzeczenia określającego wykonaną akcję (np. „zapisuje”, „wybiera”) oraz dopełnień określających pojęcia, którego ta akcja dotyczy (np. „model samochodu”, „okno dodania modelu samochodu”). Zdania POD(D) odpowiadają pojedynczym komunikatom wymienianym pomiędzy użytkownikiem a system. Zdania takie numerujemy w celu podkreślenia ich kolejności w sekwencji interakcji.
Zdania sterujące warunkowe pozwalają na kontrolowanie przebiegu scenariuszy przypadków użycia. Użycie zdania warunkowego pozwala na rozgałęzienie sterowania w zależności od spełnienia bądź niespełnienia danego warunku. Zdania warunkowe w proponowanej tutaj notacji, zapisywane są w nawiasach kwadratowych. Scenariusz alternatywny może zarówno prowadzić do spełnienia celu biznesowego (prowadząc do jego spełnienia inna drogą niż scenariusz główny) jak i do porażki (może np. obsługiwać sytuację wyjątkową lub błąd).
Zdania powrotu pozwalają na ponowne połączenie rozgałęzionych scenariuszy bądź zdefiniowanie powtarzanych interakcji (pętli). Definiując powrót trzeba określić scenariusz i numer zdania, które nastąpi po wykonaniu wszystkich zdań danego scenariusza.
Zdania wywołania (ang. invoke) określają krok scenariusza, w którym uruchamiany jest inny przypadek użycia. Mogą one mieć charakter zarówno warunkowy, jak i bezwarunkowy. Po wykonaniu wywołanego przypadku użycia sterowanie powraca do bieżącego przypadku i wykonanie przypadku jest kontynuowane od miejsca wywołania.

Rysunek 8.9: Przykładowy scenariusz
przypadku użycia z zdaniami wywołań
Podczas specyfikowania wymagań oprogramowania, korzystamy ze słownika stworzonego na etapie wymagań użytkownika. Słownik ten uzupełniamy o pojęcia pojawiające się podczas tworzenia szczegółowych wymagań systemowych. Definicje pojęć już istniejących w słowniku są również uszczegóławiane na tym etapie.
Przykłady fragmentów słownika rozbudowanego o elementy interfejsu użytkownika zostały pokazane na rysunkach 2.9 i 2.10. Na diagramach klas, elementy interfejsu użytkownika zostały oznaczone stereotypami. Elementy główne (okienka) zostały oznaczone stereotypem «UI element», a elementy aktywne (opcje, przyciski) – stereotypem «UI trigger» (wyzwalacz). Z okienkami zostały powiązane relacjami agregacji odpowiednie klasy słownika dziedziny.
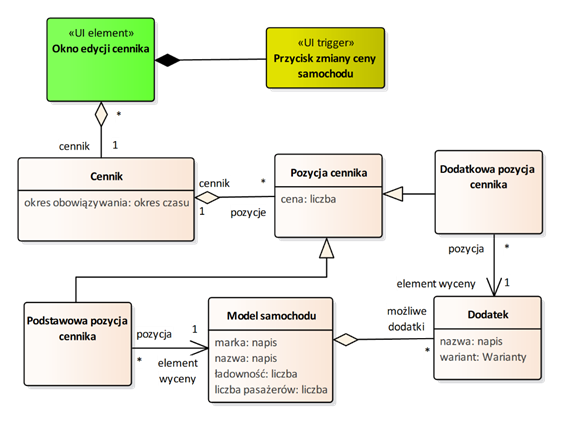
Rysunek 2.9: Przykład słownika na poziomie wymagań oprogramowania

Rysunek 2.10: Przykład słownika na poziomie wymagań oprogramowania z elementami interfejsu użytkownika związanymi z wieloma przypadkami użycia
Opisy scenariuszy i dokładne modele (słowniki) dziedziny nie dostarczają kompletu informacji koniecznych dla zaprojektowania i zaimplementowania systemu. Dlatego też, najczęściej konieczne jest zdefiniowanie wyglądu elementów interfejsu użytkownika. W najprostszym przypadku może to być tzw. szkielet interfejsu użytkownika (ang. wireframe), który polega na naszkicowaniu prostymi kreskami układu elementów ekranowych (okienka z zawartymi w nich polami, przyciskami itp.). Jeśli potrzebny jest bardziej dokładna definicja, wykonujemy tzw. makietę interfejsu użytkownika (ang. mockup). Najbardziej dokładny jest prototyp interfejsu użytkownika (ang. UI prototype), który często wykonywany jest w docelowym narzędziu, w którym będzie implementowany cały system.
Warto zauważyć, że wybrany stan interfejsu użytkownika stanowi swego rodzaju scenę. Poszczególne kroki scenariuszy przypadków użycia mogą powodować przejście do kolejnej sceny, czyli np. wyświetlenie kolejnego okienka. Takie sekwencje scen możemy nazwać scenopisami (ang. storyboard). Przykład scenopisu dla przypadku użycia z rysunku 2.7 przedstawia rysunek 2.11.
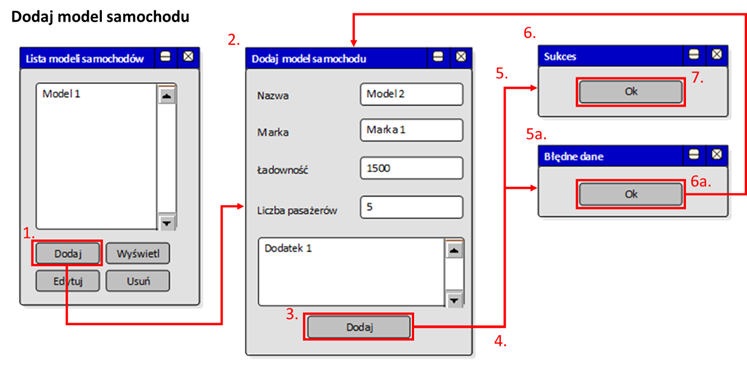
Rysunek 2.11: Przykładowy scenopis scenariuszy przypadku użycia
3. Wprowadzenie do architektury oprogramowania
3.1. Rola projektowania architektonicznego
Opanowanie złożoności na poziomie samego kodu jest bardzo trudne lub wręcz niemożliwe. Moduły (klasy), procedury, instrukcje są powiązane bardzo złożoną siecią zależności. Aby system działał efektywnie oraz pozwalał na łatwą jego pielęgnację, powinniśmy stosować dobre praktyki projektowania oprogramowania. Podstawą jest tutaj projekt architektoniczny pokazujący zasadniczą strukturę systemu oraz opisujący sposób działania podstawowych jednostek funkcjonalnych. Plany architektoniczne systemu powinny zapewniać członkom zespołu deweloperskiego dobrą platformę porozumienia – powinny wyrażać najważniejsze decyzje dotyczące sposobu budowy systemu.
Architektura oprogramowania stanowi wyrażony zestaw decyzji podjętych przez architekta. Decyzje te są podejmowane na podstawie wymagań klienta oraz wiedzy na temat dostępnych technologii wytwarzania oprogramowania. Plany architektoniczne pokazują strukturę i dynamikę (działanie) budowanego (lub istniejącego) systemu. Biorą one pod uwagę ograniczenia ekonomiczne i technologiczne, a także możliwość łatwego wprowadzania zmian i rozszerzeń wynikających ze zmian wymagań i zmian technologii. Są one wyrażane w języku graficznym (wizualnym), zrozumiałym dla projektantów i wykonawców systemu (programistów).
Architekturę oprogramowania tworzymy na stosunkowo wysokim poziomie ogólności. Architekci oprogramowania nie muszą projektować wszystkich szczegółów. Pozostawiają to zadanie deweloperom pełniącym role projektantów. Współpraca między rolami w ramach dyscypliny projektowania jest zilustrowana na rysunku 3.1. Architekt tworzy ogólny model systemu, dzieląc jego funkcjonalność na poszczególne komponenty oraz definiując interfejsy i przepływ komunikatów pomiędzy komponentami. Na tym poziomie, komponenty są czarnymi skrzynkami komunikującymi się między sobą poprzez dobrze zdefiniowane i stosunkowo wąskie interfejsy. Architekt projektuje również komunikację między komponentami tworząc odpowiednie diagramy opisujące dynamikę systemu, np. diagramy sekwencji. Projektowanie systemu na takim poziomie szczegółowości powoduje, że architekt musi zapanować nad co najwyżej kilkudziesięcioma komponentami zamiast setkami lub tysiącami klas (jednostek kodu) na raz. Oprócz projektowania elementów architektury logicznej, architekt definiuje również architekturę fizyczną, czyli strukturę składająca się z węzłów wykonawczych. Ponadto, rolą architekta jest zdefiniowanie zasad projektowania poszczególnych podsystemów oraz technologii ich implementacji. Architekt może na przykład zaprojektować część modeli projektowych komponentów, jako wskazówkę dla projektantów.
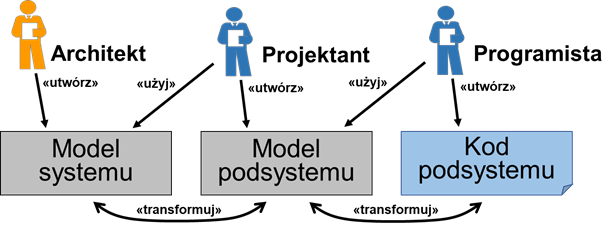
Rysunek 9.1: Projektowanie na różnych poziomach
Równolegle z architektem, projektanci tworzą szczegółowe modele
podsystemów. Często jest to bezpośrednio powiązane z tworzeniem kodu
podsystemów. Warto jednak podkreślić zasadniczą różnicę między
projektowaniem i kodowaniem (pisaniem kodu programu). Projektowanie polega na
podejmowaniu decyzji odnośnie sposobu implementacji komponentów poprzez podział
na jednostki kodu (np. klasy i atrybuty) oraz ogólne określenie ich funkcjonalności
(operacje). Kodowanie polega na realizacji projektu w formie konstrukcji
programistycznych oraz na zapisaniu kompletnej treści procedur (metod).
3.2. Architektury komponentowe i usługowe
Podział systemu na komponenty jest bardzo ważną decyzją architektoniczną. Decyzja ta powinna być podjęta na podstawie dobrze określonych przesłanek. Pierwszą przesłanką jest konieczność zapewnienia, aby komponent realizował dobrze zasadę abstrakcji. Oznacza to, że komponent powinien grupować w sobie elementy realizujące pewien zwarty podsystem. Zwartość komponentów jest bardzo istotną cechą określającą jakość architektury. Intuicja wskazuje, że dobry komponent powinien odpowiadać jakiemuś zbiorowi ściśle związanych ze sobą pojęć (klas) ze środowiska lub elementów wykonawczych (też klas!), realizujących pewne ściśle związane ze sobą przypadki użycia systemu. Ze zwartością komponentów wiąże się druga przesłanka podziału na komponenty – realizacja zasady zamykania informacji. Oznacza ona, że podsystem realizowany przez komponent powinien być ukryty dla „świata zewnętrznego”. Jednocześnie, komunikacja z pozostałymi komponentami powinna się odbywać przez jak najwęższy styk. W ten sposób, więzy między komponentami są stosunkowo słabe.
Dobrze zdefiniowane i reużywalne komponenty nazywamy usługami. Każda usługa dostarcza zestaw operacji dostępnych poprzez interfejsy. Każdy spójny zestaw operacji stanowi swego rodzaju „kontrakt”, na podstawie którego z usługi mogą korzystać inne komponenty. Taki kontrakt określa strukturę i sekwencje komunikatów odbieranych i wysyłanych przez usługę. W ramach wykonywania swoich operacji, usługa działa w sposób autonomiczny. Oznacza to, że usługa nie zakłada, że jest fragmentem jakiegoś konkretnego systemu. Zamiast tego, usługa jest zorientowana na wykonanie konkretnego zakresu funkcjonalności. Równocześnie, usługa powinna móc pracować w ramach systemów heterogenicznych, czyli złożonych z komponentów wykonanych w różnych technologiach. Dzięki temu, usługi mogą być instalowane w różnych konfiguracjach i na różnych węzłach wykonawczych. Zdecydowanie zwiększa to elastyczność architektury i łatwość rozwoju systemu zbudowanego z usług. Usługi mogą być dostępne w sieci i wtedy takie usługi nazywamy usługami webowymi (ang. web service).Zwróćmy uwagę na to, że kontrakt powinien być zgodny ze strukturą usługi, to znaczy – operacjami odpowiedniego interfejsu oraz klasami definiującymi obiekty transferu danych (ang Data Transfer Object, DTO). Obiekt transferu danych oznacza spójny pakiet danych przesyłany między komponentami w celu wykonania zadanych operacji. W naszym przykładzie na rysunku 3.2, klasy definiujące obiekty transferu danych wyróżniliśmy poprzez nadanie im przedrostka „X” (w języku angielskim skrót od X-fer = transfer). Alternatywnie, można np. zastosować przyrostek „DTO” oraz oznaczyć klasę odpowiednim stereotypem (np. «DTO»).
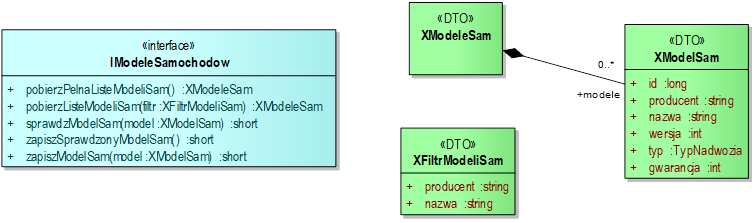
Rysunek 3.2: Przykładowy diagram definiujący interfejs usługi
Podejście architektoniczne, które bazuje na usługach nazywamy architekturą zorientowaną na usługi (ang. Service Oriented Architecture, SOA). Można również wyróżnić wariant architektury SOA – architekturę mikro-usługową (ang. microservice architecture). Wariant ten jest oparty na usługach, które dostarczają niewielkich, bardzo silnie skupionych zestawów operacji. Niezależnie od wariantu, podstawą architektur typu SOA są usługi gotowe. Spełniają one wszystkie założenia architektur komponentowych – minimalizują zależności między komponentami i ukrywają implementację zwartych wewnętrznie komponentów. Dodatkowo, w dużym stopniu oparte są na reużywalności, czyli ponownym wykorzystaniu gotowych komponentów – usług. Zadanie architekta polega na odpowiedniej „orkiestracji” takich usług, czyli połączeniu ich w spójną całość, umożliwiającą realizację zadanych wymagań. W zdecydowanej większości przypadków konieczne jest stworzenie nowych komponentów, które spajają cały system. W razie braku gotowych komponentów usługowych może być też konieczne zbudowanie nowych usług.
Systemy usługowe mogą być projektowane jako heterogeniczne. Oznacza to, że system jest budowany z usług tworzonych w różnych technologiach – na przykład, pisanych w różnych językach czy korzystających z różnych systemów zarządzania bazami danych. Dodatkowo, usługi mogą być zainstalowane na różnych węzłach wykonawczych, korzystających z różnych systemów operacyjnych i komunikujących się za pośrednictwem sieci. Aby takie usługi mogły się ze sobą efektywnie komunikować w sieci, potrzebny jest wspólny protokół wymiany danych. Interfejsy stosujące takie wspólne protokoły nazywamy interfejsami programowania aplikacji (ang. Application Programming Interface, API).
Obecnie najczęściej stosowanym stylem dla tworzenia API jest podejście REST (ang. REpresentational State Transfer), czyli „zmiana stanu poprzez reprezentację”. Jest ono oparte na idei nawigacji przez zasoby systemu poprzez wybieranie łączy webowych, co skutkuje zmianą stanu i przesłaniu reprezentacji tego stanu w celu jego udostępnienia użytkownikowi. REST korzysta ze standardowego protokołu HTTP, używanego m.in. w komunikacji WWW (ang. World Wide Web). Podstawowe zasady tworzenia systemów z API REST obejmują m.in. rozdzielenie obowiązków, bezstanowość, warstwowość, jednolitość interfejsów. Interfejsy REST są udostępniane w jednolity sposób pod odpowiednim adresem zasobu (tzw. URI, ang. Uniform Resource Identifier), np. „https://moj.adres.pl/samochody”. Możemy tutaj wyróżnić adres bazowy oraz tzw. punkt końcowy (ang. endpoint). W projekcie komponentowym, adres bazowy określa położenie całego komponentu (usługi). Punkt końcowy natomiast określa kanał dostępu do usługi reprezentowany na modelu jako port (np. o nazwie „/samochody”).
Interfejsy REST korzystają ze standardowych typów operacji HTTP (GET, PUT, POST, DELETE). Operacje zaprojektowane w ramach danego interfejsu (patrz np. interfejs na rysunku 9.2) stanowią składowe dostępne pod adresem zagnieżdżonym w stosunku do adresu punktu końcowego (np. „/samochody/sprawdz”). Wymiana danych następuje albo poprzez wartość (zapisaną w adresie), albo poprzez pliki (najczęściej w formacie JSON, czasami XML lub RSS). Wadą takiego sposobu komunikacji jest przesyłanie danych w sposób tekstowy, co zdecydowanie zwiększa objętość przesyłanych danych.
9.3. Typowe style architektoniczne
Jak już wspomnieliśmy, podział systemu na komponenty lub usługi jest najważniejszą decyzją podejmowaną przez architekta. Kluczowe w takim podziale jest odpowiednie określenie odpowiedzialności poszczególnych komponentów. Część komponentów powinna odpowiadać za komunikację z użytkownikami, część – za realizację logiki przetwarzania danych, a jeszcze inne – za przechowywanie danych. Te różne poziomy odpowiedzialności komponentów najkorzystniej jest zorganizować w warstwy. Stąd też, najpowszechniej stosowanym podziałem komponentów jest tzw. architektura warstwowa. Poszczególne warstwy określają odległość komponentów od środowiska zewnętrznego (użytkowników, systemów zewnętrznych). Istotną cechą systemów w architekturze warstwowej jest uporządkowanie komunikacji między warstwami. Komponenty mogą komunikować się w jedynie ramach danej warstwy lub z warstwą wyżej lub niżej. Nie jest dopuszczalna komunikacja przez wiele warstw.
Najprostszym stylem architektonicznym jest podział na dwie warstwy, czasami nazywany architekturą klient-serwer. Warstwa górna (klient) odpowiada za interakcję z użytkownikiem, a warstwa dolna (serwer) – za przetwarzanie i przechowywanie danych. Takie podejście można porównać do ogólnej struktury zakładu usługowego. Dla klienta widoczna jest przede wszystkim witryna (ang. frontend), a właściwe wykonanie usługi odbywa się na zapleczu (ang. backend). Tego typu metafora jest często stosowana przy określaniu warstw w systemach opartych na technologiach webowych. Komponenty zawierające interfejs użytkownika oraz logikę nawigacji między ekranami nazywa się „frontendem”. Komponenty wykonujące zadania przetwarzania danych oraz komponenty przechowujące dane nazywa się „backendem”.
Architektura dwuwarstwowa jest często zbyt ogólna, dlatego też często stosuje się architekturę wielowarstwową. Najczęściej wyróżnia się cztery zasadnicze warstwy, które ilustruje rysunek 3.3. Dwie górne warstwy najczęściej stanowią frontend systemu, a dwie dolne – jego backend. Warstwa górna – Widok – odpowiada za komunikację z użytkownikami (ludźmi). Logika całego systemu podzielona jest na dwie warstwy. Warstwa Logiki aplikacji steruje działaniem systemu poprzez realizację funkcjonalności przypadków użycia. Warstwa Logiki dziedziny odpowiada za właściwe przetwarzanie danych oraz zmiany stanu systemu. Poziom logiki dziedzinowej jest również najdogodniejszy do zorganizowania komunikacji z systemami zewnętrznymi (maszynami). Najniższą warstwą jest warstwa Przechowywania danych, która umożliwia przechowywanie stanu systemu w sposób trwały. Najczęściej korzysta ona z odpowiedniego systemu zarządzania bazą danych. Poniżej przedstawimy rolę poszczególnych warstw oraz typowy sposób ich wzajemnej komunikacji.
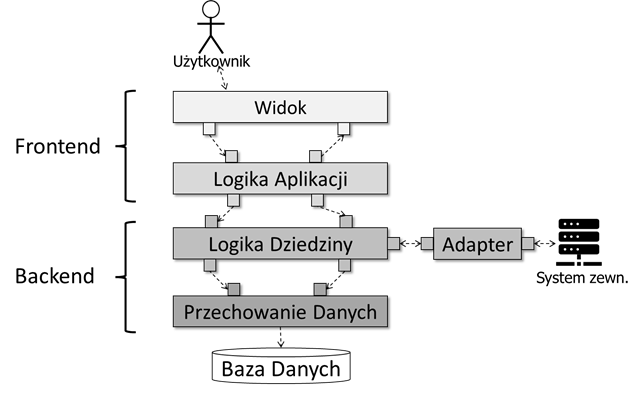
Rysunek 3.3: Schemat architektury warstwowej
Warstwa widoku obsługuje elementy interfejsu użytkownika (formularze, menu, okna multimediów, itd.) oraz umożliwia wymianę danych z użytkownikiem – wprowadzanie danych przez użytkownika oraz prezentację (wyświetlanie) danych użytkownikowi. Warstwa widoku komunikuje się z jednej strony z użytkownikiem, a z drugiej strony – z warstwą logiki aplikacji. Schemat komunikacji dla warstwy widoku ilustruje przykład na rysunku 3.4. Komponent warstwy widoku (tu: „UISprzedawcy”) reaguje na dwa rodzaje komunikatów. Z jednej strony, otrzymuje on polecenia od komponentu warstwy logiki aplikacji (tu: „AppSprzedawcy”). Dotyczą one potrzeby zaprezentowania (wyświetlenia) nowego widoku (np. okna, formularza) w ramach interfejsu użytkownika. Z drugiej strony, od użytkownika (tu: „Sprzedawca”) docierają komunikaty związane z różnego rodzaju zdarzeniami (np. przyciśnięcie przycisku, wybranie opcji). Takie komunikaty mogą również być związane z wprowadzeniem przez użytkownika odpowiednich danych.

Rysunek 3.4: Schemat komunikacji warstwy widoku
Zdarzenie oraz dane otrzymane od użytkownika są natychmiast przesyłane przez komponent warstwy widoku do komponentu warstwy logiki aplikacji. Odpowiada to realizacji kolejnej akcji (kroku) w scenariuszu interakcji aktora z systemem (np. w scenariuszu przypadku użycia). Z drugiej strony, każdy komunikat otrzymany od warstwy logiki aplikacji przekładany jest na odpowiednie polecenia wyświetlenia nowych elementów interfejsu użytkownika. Zwróćmy uwagę na to, że ten ostatni komunikat jest komunikatem poniekąd wirtualnym.
W ramach swojej implementacji, komponenty warstwy widoku zawierają odpowiedni kod (np. klasy) odpowiedzialny za rysowanie („renderowanie” od ang. render) elementów ekranowych oraz obsługę zdarzeń pochodzących od użytkownika. Bardzo istotne jest to, że w ramach swojej logiki, kod warstwy widoku odpowiada jedynie za prezentowanie oraz przyjmowanie danych.
Warstwa logiki aplikacji bezpośrednio odpowiada za realizację scenariuszy interakcji użytkowników z systemem. W tej warstwie zawarta jest implementacja logiki opisanej np. scenariuszami przypadków użycia. Warstwa logiki aplikacji komunikuje się z jednej strony z warstwą widoku, a z drugiej strony – z warstwą logiki dziedzinowej. Schemat komunikacji dla warstwy widoku ilustruje przykład na rysunku 3.5. Z warstwy widoku (tu: „UISprzedawcy”) docierają polecenia wykonania kolejnych akcji (kroków) scenariuszy wraz z danymi wprowadzonymi przez użytkownika. W rezultacie, komponent warstwy logiki aplikacji (tu: „AppSPrzedawcy”) podejmuje odpowiednie działania zgodne z odpowiednim krokiem w scenariuszu. Działania mogą być dwojakiego rodzaju. Po pierwsze, komponent może poprosić warstwę logiki dziedzinowej (tu: „Zamowienia”) o wykonanie jakiegoś zadania przetwarzania, aktualizacji lub odczytu stanu danych. Zazwyczaj zadanie jest wykonywane w sposób synchroniczny, czyli na końcu jest przesyłany komunikat zwrotny, zawierający wynik wykonania zadania (np. status lub odczytane dane). Drugi rodzaj działania polega na przesłaniu komunikatu do warstwy widoku z poleceniem wyświetlenia nowego widoku oraz ew. przesłanie danych do wyświetlenia.

Rysunek 3.5: Schemat komunikacji warstwy logiki aplikacji
Zwróćmy uwagę na to, że komunikaty między warstwą logiki aplikacji a warstwą logiki dziedzinowej przepływają w obydwie strony, lecz odpowiednia zależność na rysunku 3.5 jest skierowana w jedną stronę. Wynika to z tego, że komunikacja między tymi warstwami jest zazwyczaj synchroniczna w jednym kierunku.
Warstwa logiki dziedzinowej (często nazywana warstwą logiki biznesowej) odpowiada za wykonywanie wszystkich zadań związanych z przetwarzaniem oraz zmianą stanu danych w systemie. Warstwa logiki dziedzinowej komunikuje się z jednej strony z warstwą logiki aplikacji, a z drugiej strony – z warstwą logiki przechowywania danych. Schemat komunikacji dla warstwy logiki dziedzinowej ilustruje przykład na rysunku 3.6. Komponent tej warstwy (tu: „Zamówienia”) reaguje na komunikat zlecający wykonanie określonego zadania. Wykonanie zadania zależy od treści komunikatu oraz zawartych w nim danych. Może to być określone przetwarzanie danych, zmiana stanu systemu lub odczyt stanu systemu. Po wykonaniu zadania, komponent zwraca jego wynik komponentowi, który zadanie zlecił. Wynik może zawierać proste przekazanie sterowania, odpowiedni kod odpowiedzi lub obiekt transferu danych. W przypadku konieczności zmiany stanu lub odczytu stanu systemu, komponent warstwy logiki dziedzinowej przesyła komunikat do warstwy przechowywania danych (tu: „GlownaBazaDanych”). Komunikat taki zawiera odpowiednie zapytanie o dane lub zlecenie aktualizacji danych. W rezultacie, zwrotnie przesyłany jest komunikat z wynikiem zapytania lub rezultatem aktualizacji danych. Wynik ten może być wykorzystany np. do dalszego przetwarzania danych.

Rysunek 3.6: Schemat komunikacji warstwy logiki dziedzinowej
Warstwa przechowywania danych jest odpowiedzialna za trwały zapis oraz odczyt utrwalonych danych na odpowiednich nośnikach danych i przy wykorzystaniu odpowiednich systemów zarządzania utrwalaniem danych (np. systemy zarządzania bazami danych). Warstwa ta komunikuje się z warstwą logiki dziedzinowej, co ilustruje omawiany już rysunek 3.6. Kod w ramach tej warstwy zależny jest od konkretnej technologii przechowywania danych. Może to być relacyjna baza danych, baza danych NoSQL, repozytorium grafowe, system plików. Zapytania otrzymywane z warstwy logiki dziedzinowej dotyczą wykonania operacji na danych typu CRUD (Create / Read / Update / Delete). Są to typowe operacje związane z aktualizacją oraz odczytem danych. Komponenty w warstwie przechowywania danych mają za zadanie przetłumaczyć zapytania z formatu przyjętego w warstwach logiki (np. obiekty transferu danych) na odpowiednie zapytania w formacie przyjętym przez daną technologię przechowywania danych. Na przykład, w technologiach relacyjnych, zapytania są formułowane w języku SQL (Sequence Query Language).
Architektura warstwowa jest prawdopodobnie najczęściej spotykanym rozwiązaniem projektowym w typowych systemach interaktywnych (komunikujących się z użytkownikami – ludźmi). Istnieją jednak również inne style architektoniczne, w tym takie, które są przeznaczone np. do projektowania systemów wbudowanych (np. system sterowania samochodem), systemów automatyki (np. system sterowania produkcją) lub systemów obliczeń inżynierskich (np. obliczenia rozproszone przy wykorzystaniu superkomputerów). Omówienie wszystkich spotykanych styli architektonicznych jest poza zakresem niniejszego podręcznika.
4. Podstawy projektowania podsystemów
4.1. Projektowanie warstw prezentacji i logiki aplikacji
Komponenty warstw prezentacji i logiki aplikacji tworzą zazwyczaj spójną całość. Zgodnie z tym, co powiedzieliśmy w poprzednim rozdziale, warstwy te składają się na frontend systemu. Bardzo istotne jest wyraźne wydzielenie tych elementów frontendu, które są silnie zależne od technologii interfejsu użytkownika oraz technologii wymiany danych. Technologie te ulegają częstym zmianom, czy wręcz są zastępowane innymi. Dlatego też, projektując frontend bardzo wskazane jest dokonanie podziału na kod „brudny” i kod „czysty”. Kod „brudny” jest podatny na zmiany technologii i podlega istotnym zmianom w trakcie rozwoju całego systemu. Kod „czysty” jest zależny jedynie od logiki aplikacji opisanej scenariuszami interakcji użytkowników z systemem (np. scenariuszami przypadków użycia). Klasy takie nie są zależne od jakiegokolwiek konkretnego szkieletu technologicznego (ang. framework).
Komponenty warstwy frontend
projektujemy na bazie projektu architektonicznego, który został omówiony w
poprzednim rozdziale. Punktem wyjścia do projektowania jest zatem model
komponentów, którego ogólna struktura jest przedstawiona na rysunku 4.1.

Rysunek 4.1: Ogólna struktura komponentów warstwy frontend
Projektując strukturę komponentu warstwy frontend
można skorzystać ze wzorca pokazanego na rysunku 4.2.
Wzorzec ten definiuje klasy implementujące odpowiednie interfejsy z rysunku 4.1,
a także klasy realizujące szczegółową funkcjonalność frontendu.
Zwróćmy uwagę na to, że we wzorcu wyraźnie wyróżnione są elementy „czyste” i
„brudne”. Wszystkie klasy warstwy widoku traktowane są jako „brudne”, czyli
zależne od odpowiedniego szkieletu technologicznego (frameworka).
Elementami tego szkieletu są klasa i interfejs opatrzone stereotypem «framework» („WindowForm” i „EventHandler”). Zakładamy tutaj hipotetyczny szkielet
technologiczny, który należy w praktycznym zastosowaniu zamienić na szkielet
rzeczywisty (najpopularniejsze szkielety omawiamy niżej).
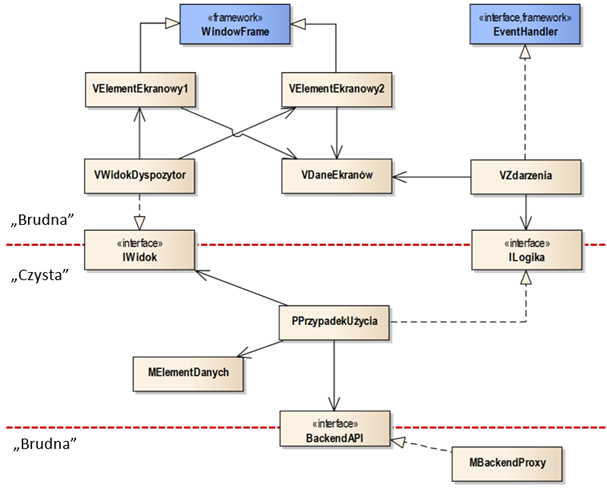
Rysunek 4.2: Przykładowa struktura komponentu warstwy frontend
Za wyświetlanie poszczególnych elementów ekranowych odpowiadają klasy specjalizujące od odpowiedniej klasy „okienkowej” zawartej we framework’u (tu: „WindowFrame”). Za przechwytywanie i obsługę zdarzeń pochodzących od użytkownika odpowiada klasa realizująca standardowy interfejs (tu: „EventHandler”). Innym często stosowanym rozwiązaniem jest bezpośrednia realizacja interfejsu obsługi zdarzeń przez klasy wyświetlające elementy ekranowe. W naszej przykładowej strukturze oznaczałoby to, że klasy „VElementEkranowy” oprócz specjalizowania od klasy „WindowFrame” implementowałyby interfejs „EventHandler”.
Komunikacja warstwy widoku z warstwą logiki aplikacji odbywa się za pomocą interfejsów „IWidok” oraz „ILogika”. Pierwszy z tych interfejsów umożliwia sterowanie wyświetlaniem kolejnych widoków (ekranów). W naszym wzorcu, jest on realizowany przez klasę, która spełnia rolę „dyspozytora” („VWidokDyspozytor”). Klasa ta rozdziela polecenia wyświetlenia elementów ekranowych do poszczególnych klas typu „VElementEkranowy”. Drugi z interfejsów służy do przekazywania zdarzeń do realizacji. Każde zdarzenie przechwycone w warstwie widoku jest kierowane do odpowiedniego interfejsu warstwy logiki aplikacji w celu podjęcia odpowiednich działań. Zwróćmy uwagę na to, że warstwa widoku w żadnym wypadku nie realizuje logiki nawigacji między ekranami.
Warstwa logiki aplikacji jest warstwą „czystą” i zawiera klasy implementujące interfejsy typu „ILogika”. Korzystają one również z interfejsów warstwy widoku (tu: „IWidok”) oraz warstwy backend (logiki dziedzinowej, tu: „BackendAPI”). W warstwie tej możemy również umieścić klasy odpowiedzialne za lokalną walidację oraz przetwarzanie danych (tu: „MElementDanych”). Za właściwe przetwarzanie danych odpowiada warstwa backend, do której zazwyczaj odwołujemy się za pomocą API. W naszym wzorcu zastosowaliśmy interfejs („BackendAPI”), który separuje czysty kod od kodu „brudnego”, odpowiedzialnego za komunikację sieciową. Interfejs ten jest realizowany przez tzw. klasę proxy (zastępnik, tu: „MBackendProxy”). Jest to klasa, która dokonuje odpowiednich operacji „zastępczych”, tzn. tłumaczy lokalne wywołania procedur zdefiniowanych przez interfejs, na wywołania zdalne, realizowane np. w technologii REST API. Więcej o działaniu klas proxy mówimy w następnym rozdziale.
Na rysunku 4.3 widzimy fragment przykładowego projektu komponentu zgodnego z podanym wzorcem. Zwróćmy uwagę na to, że pominęliśmy tutaj interfejsy wewnętrzne oraz klasę „dyspozytora”. Jest to rozwiązanie, które można zastosować dla niedużych komponentów o prostej logice w celu zmniejszenia rozmiaru kodu.

Rysunek 4.3: Przykładowy projekt struktury komponentu warstwy frontend
Działanie komponentu z
rysunku 4.3
ilustruje diagram sekwencji pokazany na rysunku 4.4.
Opisuje on wymianę komunikatów między obiektami w warstwie frontend
podczas realizacji przypadku użycia „Edytuj model samochodu”.
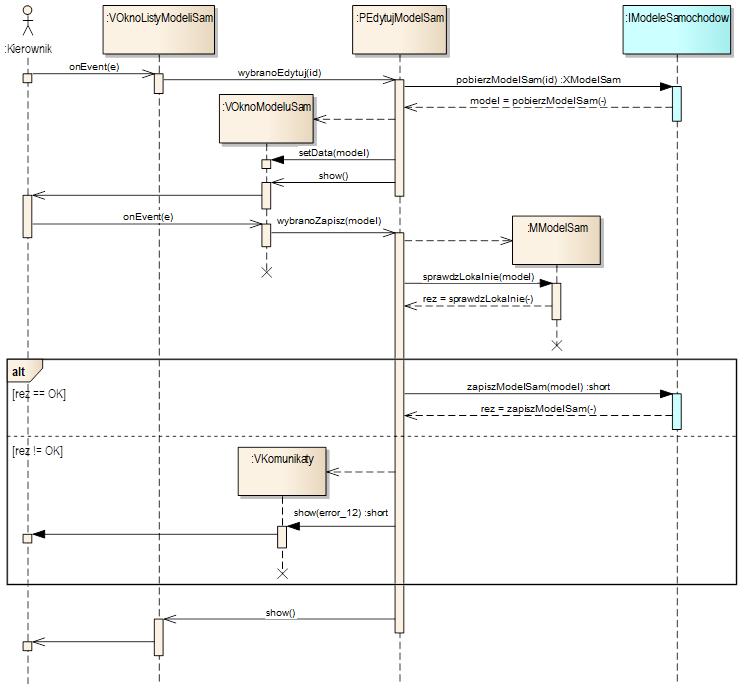
Rysunek 4.4: Przykładowy projekt działania komponentu warstwy frontend
4.2. Projektowanie warstwy logiki dziedzinowej
Jak wiemy z poprzedniego rozdziału, komponenty warstwy logiki dziedzinowej odpowiadają za wykonywanie zadań zlecanych przede wszystkim przez warstwę logiki aplikacji. Zadania te dotyczą wszelkiego rodzaju przetwarzania, zapamiętywania oraz odczytu danych. Zasadnicza funkcjonalność logiki dziedzinowej zazwyczaj projektowana jest jako zestaw niezależnych komponentów, często traktowanych jako usługi. Dla każdego takiego komponentu projektowany jest jeden lub więcej interfejsów zawierających odpowiednie zestawy operacji na obiektach dotyczących danej dziedziny problemu. Mamy wtedy do czynienia z wyraźnie wydzieloną warstwą backendu, na którą dodatkowo składa się warstwa przechowywania danych.
Jeśli warstwa frontendu wykonywana
jest po stronie serwera, to komunikacja z warstwą logiki dziedzinowej odbywa
się poprzez zwyczajne, lokalne wywołania procedur klas, realizujących
odpowiednie interfejsy. Znacznie bardziej złożona jest sytuacja, jeśli warstwa frontendu wykonywana jest po stronie klienta, tzn. na
maszynie użytkownika końcowego. W takiej sytuacji, aby wykonać operację logiki
dziedzinowej należy skomunikować się z warstwą backendu
poprzez zdalne wywołania procedur. Typowy mechanizm takiej komunikacji ilustruje
przykład przedstawiony na rysunku 4.5.
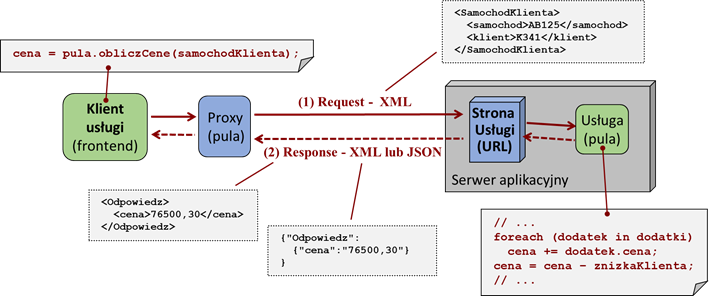
Rysunek 4.5: Zasada działania wywołań zdalnych (RPC, REST)
Obiekt klasy proxy przesyła pod odpowiedni adres (URL) serwera, komunikat żądania (ang. request) z umieszczonym w nim obiektem danych. Taki komunikat jest interpretowany przez serwer, w wyniku czego powinna zostać wywołana odpowiednia procedura obsługi żądania. Procedura ta odpowiada procedurze wywoływanej po stronie klienta i zawiera odpowiedni kod logiki aplikacji (tutaj: kod obliczania ceny samochodu). Po wykonaniu procedury, zwraca ona wynik i przekazuje sterowanie. W rezultacie, odpowiedni kod po stronie serwera powinien wysłać komunikat odpowiedzi (ang. response). Komunikat ten zawiera wynik przetwarzania danych wraz z ew. obiektem danych (tu: obiekt zawierający wyliczoną cenę). Po stronie klienta odpowiedź ta skutkuje powrotem z wywołania procedury i kontynuacją działania przez kod frontendu.
Realizacja powyższego mechanizmu przez komponenty logiki dziedzinowej zależy od zastosowanego szkieletu technologicznego (frameworku), umożliwiającego realizację wywołań zdalnych. Na rysunku 4.6 widzimy przykładową strukturę komponentu logiki dziedzinowej. Za obsługę wywołań zdalnych odpowiada „brudna” część tego komponentu, czyli część zależna od wybranego szkieletu technologicznego. W naszym przykładzie, zaprojektowano tzw. klasę kontrolera API (ang. API controller) o nazwie „ModeleSamochodowController”. Klasa ta specjalizuje standardową klasę „Controller”, która zapewnia obsługę odpowiednich mechanizmów technologicznych. Nasza klasa kontrolera zawiera obsługę wszystkich operacji realizowanego przez komponent interfejsu. Sygnatury tych operacji dostosowane są do wybranego szkieletu technologicznego dla obsługi API REST.

Rysunek 4.6: Przykładowa struktura komponentu backend
W bardziej złożonych
sytuacjach, kiedy logika dziedziny implementuje złożone algorytmy, warto
zastosować rozdzielenie odpowiedzialności na wiele klas. Tego typu podejście
realizuje wzorzec modelu dziedziny (ang. domain
model). We wzorcu tym, logika jest rozproszona między klasy zgodne z modelem
opisującym daną dziedzinę problemu. Przykład zastosowania
wzorca model dziedziny widzimy na rysunku 4.7. Zwróćmy uwagę na to, że dosyć złożona
struktura komponentu przysłonięta jest dla innych komponentów przez wąski
zestaw operacji interfejsu (tu: zaledwie jedna operacja interfejsu „IAnalityka”). Jest to realizacja wzorca projektowego fasada
(ang. facade).
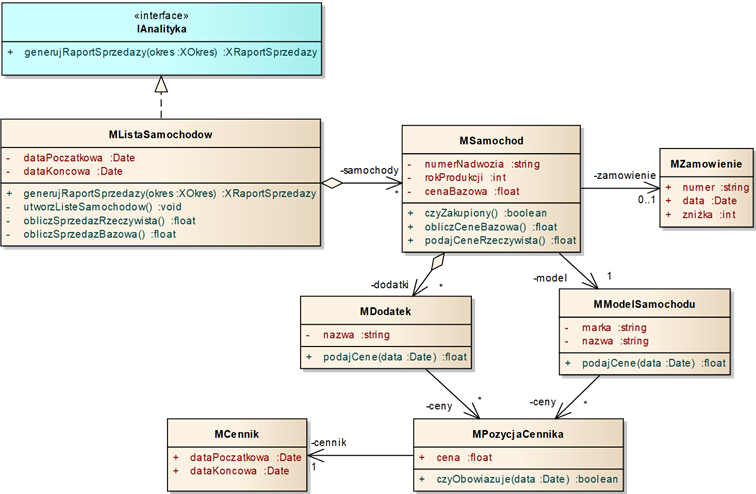
Rysunek 4.7: Komponent backend zaprojektowany zgodnie z modelem dziedziny
4.3. Projektowanie baz danych
Technologia baz danych relacyjnych jest obecnie powszechnie stosowana jako podstawowa metoda przechowywania danych ustrukturalizowanych. Podstawowym językiem umożliwiającym dokonywanie operacji na danych w bazach relacyjnych jest język SQL (Structured Query Language – strukturalny język zapytań). Język ten pozwala na pisanie tzw. zapytań do bazy danych, które pozwalają na wykonywanie złożonych operacji zapisu i odczytu danych. W języku SQL definiujemy również strukturę bazy danych, która oparta jest na czterech podstawowych konstrukcjach – tabelach, kolumnach, wierszach i powiązaniach. Opisując zasady projektowania baz danych relacyjnych zakładamy, że czytelnik jest zaznajomiony z podstawami tej technologii.
Podstawą projektu bazy danych jest definicja jej struktury. W tym celu możemy wykorzystać notację ERD/ERM (Entity Relationship Diagram/Model – diagram/model związków encji). Notacja ta nie jest ustandaryzowana i istnieją różne jej warianty. Jest ona podobna do notacji modelu klas języka UML. Tabele bazodanowe odpowiadają klasom, a kolumny w tabelach odpowiadają atrybutom. Powiązania między tabelami (często mylnie nazywane relacjami) odpowiadają asocjacjom między klasami. Podstawową jednostką przechowywania danych w bazie relacyjnej jest wiersz tabeli. Analogiem wiersza w podejściu obiektowym jest obiekt, zatem wiersze nie są zazwyczaj uwzględniane podczas projektowania bazy danych. Należy podkreślić, że model relacyjny posiada istotne różnice w stosunku do modelu obiektowego. Dlatego też konieczne jest odpowiednie przetłumaczenie modelu dziedziny zapisanego jako model obiektowy w języku UML w model relacyjny. Poniżej przedstawiamy zasady takiej translacji.
Rysunek 4.8 ilustruje podstawowe reguły projektowania tabel relacyjnych. Bierzemy pod uwagę klasy modelu dziedziny, które będą wymagały przechowywania ich obiektów w bazie danych. Dla takich klas tworzymy odpowiadające im tabele. Proste atrybuty klas (typu napisowego, liczbowego itp.) zamieniamy w kolumny tabeli. Dla atrybutów typów złożonych stosujemy zasady opisane poniżej, dotyczące projektowania asocjacji. Na rysunku 10.8 widzimy również zasadę przechowywania obiektów w relacyjnej bazie danych. Obiekty utworzone np. w pamięci ulotnej (tu: obiekt „uzytkownik”) są zapisywane jako wiersze w tabeli, gdzie kolumny tej tabeli odpowiadają atrybutom klas.

Rysunek 4.8: Tworzenie tabel na podstawie klas modelu dziedziny
Na rysunku 4.9
widzimy dwie metody projektowania struktury bazy danych dla asocjacji o
krotności „1” na obydwu końcach (asocjacje „1-1”). W takiej sytuacji,
najprostszym rozwiązaniem (patrz lewa strona rysunku) jest zaprojektowanie
jednej tabeli zawierającej kolumny odpowiadające atrybutom obydwu klas. Innym
rozwiązaniem jest stworzenie dwóch tabel odpowiadających dwóm klasom i ustanowienie
odpowiedniego połączenia między nimi (patrz prawa strona rysunku). Połączenie
tabel oznaczone jest linią, a krotności odpowiednimi symbolami (dwie kreseczki
oznaczają krotność „1”). Zwróćmy uwagę na to, że w tabelach zostały umieszczone
dodatkowe pseudo-kolumny oznaczone jako «PK» i «FK». Są to tzw. klucze główne
(ang. primary key) oraz klucze
obce (ang. foreign key).
Klucz główny stanowi unikalny identyfikator wiersza w danej tabeli. Z kolei
klucz obcy zawiera wartość klucza głównego w innej tabeli, który odpowiada
wierszowi połączonym z danym wierszem. Dzięki mechanizmowi kluczy możliwe jest
łatwe oznaczanie połączeń między wierszami (obiektami).
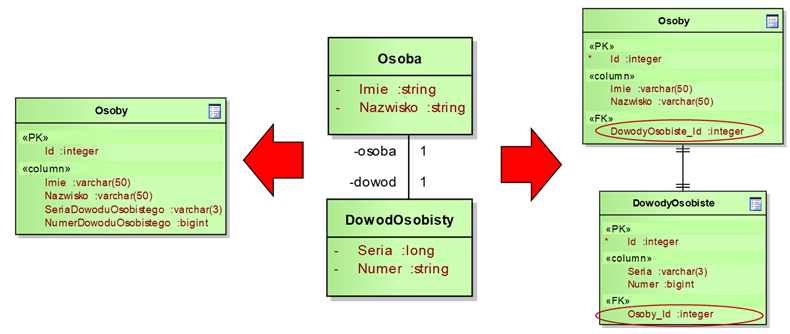
Rysunek 4.9: Tworzenie struktury tabel na podstawie asocjacji o krotności „1-1”
Rysunek 4.10 przedstawia sposób realizacji asocjacji o krotnościach „1” oraz „*” (wiele) – inaczej nazywanymi asocjacjami „1-N”. W naszym przykładzie, osoba może być uczniem co najwyżej jednej klasy szkolnej, natomiast do klasy szkolnej może być zapisanych wielu uczniów (co najmniej dwóch). W takiej sytuacji, podobnie jak w przypadku asocjacji „1-1” tworzymy dwie tabele. Podstawowa różnica polega na tym, że klucz obcy umieszczamy tylko w jednej tabeli – tej, która w powiązaniu posiada krotność „wiele”. Można tutaj zauważyć pewną wadę technologii relacyjnej, gdyż nawet niewielka zmiana krotności może powodować konieczność przebudowy struktury bazy danych (np. zmianę kluczy obcych). Zwróćmy jeszcze uwagę na oznaczenia krotności w notacji ERD – krotność „N” oznaczana jest jako tzw. „kurza łapka”, a krotność „0” lub „1” jako kółko z kreseczką.
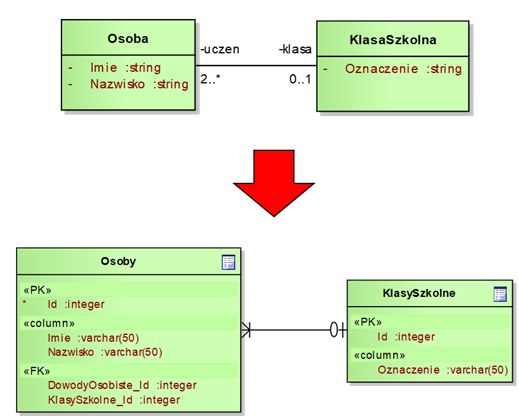
Rysunek 4.10: Tworzenie struktury tabel na podstawie asocjacji o krotności „1-N”
Rysunek 4.11 przedstawia najbardziej złożoną sytuację dotycząca asocjacji, czyli realizację asocjacji „wiele” do „wielu” („N-N”). Mamy tu przykład sytuacji, kiedy osoba może należeć do wielu stowarzyszeń, a stowarzyszenie może liczyć wielu członków będących osobami. W technologii relacyjnej wymaga to ustanowienia dodatkowej tabeli (tu: „OsobyStowarzyszenia”), która zawiera klucze obce wskazujące na dwie tabele utworzone na podstawie klas. Rozwiązanie takie jest konieczne z uwagi na ograniczenia modelu relacyjnego. Tabela nie może np. zawierać listy kluczy obcych, tak jak to jest możliwe w przypadku stosowania paradygmatu obiektowego.
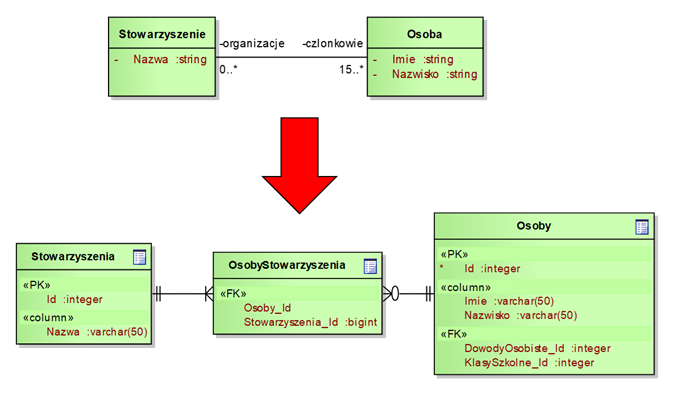
Rysunek 4.11: Tworzenie struktury tabel na podstawie asocjacji o krotności „N-N”
Ostatni przykład dotyczy traktowania relacji generalizacji. Na rysunku 4.12 widzimy dwie klasy („Osoba” i „Firma”), które specjalizują od klasy ogólnej („Klient”). W modelu relacyjnym nie możemy relacji generalizacji zamodelować bezpośrednio. Możemy natomiast zastosować jedno z kilku rozwiązań pokazanych na rysunku. Najprostsze rozwiązanie polega na umieszczeniu wszystkich kolumn w jednej tabeli odpowiadającej klasie ogólnej. To rozwiązanie ma zaletę prostoty oraz niekiedy – lepszej wydajności. Podstawowa wada polega na redundancji danych – dla niektórych wierszy niektóre kolumny będą puste. Drugie rozwiązanie polega na stworzeniu tabel jedynie dla klas szczegółowych. W takiej sytuacji, w tabelach tych dodajemy atrybuty klasy ogólnej. Takie rozwiązanie niej jest jednak polecane dla bardziej złożonych hierarchii generalizacji. Ostatnie rozwiązanie polega na utworzeniu tabel dla każdej klasy występującej w relacji generalizacji. W takiej sytuacji w tabelach odpowiadających klasom specjalizowanym należy umieścić klucze obce wskazujące na wiersze w tabeli odpowiadającej klasie ogólnej.
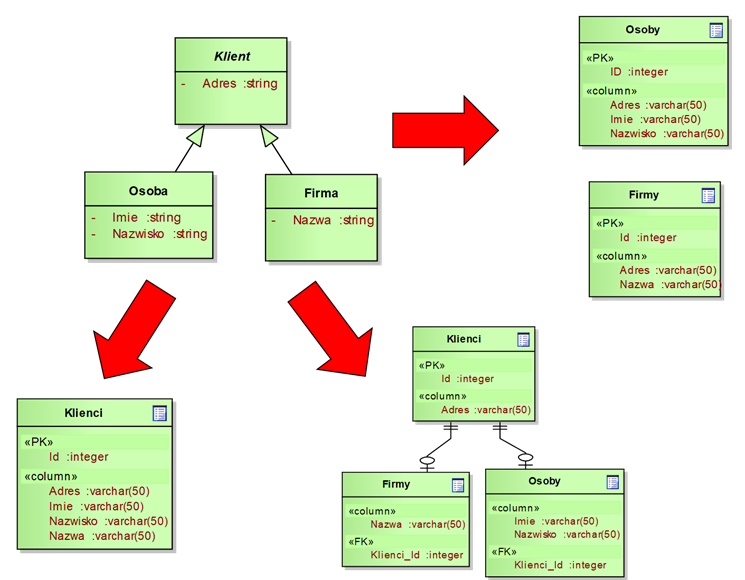
Rysunek 4.12: Tworzenie struktury tabel na podstawie generalizacji