Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | 3. Warstwa łącza danych |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | środa, 14 stycznia 2026, 22:49 |
Opis
Warstwa transportowa w modelu TCP/IP pełni kluczową funkcję pośredniczącą między aplikacjami a mechanizmami przesyłu danych w sieci. Jej zadaniem jest zapewnienie sprawnej i niezawodnej komunikacji między procesami działającymi na różnych urządzeniach. Główne protokoły tej warstwy to TCP i UDP. TCP, jako protokół połączeniowy, gwarantuje dostarczenie danych w poprawnej kolejności i bez błędów, realizując mechanizmy kontroli przepływu oraz zarządzania zatorami. UDP natomiast oferuje transmisję bez nawiązywania połączenia, bez kontroli poprawności, co czyni go idealnym dla aplikacji wymagających niskiego opóźnienia, takich jak gry online czy transmisje audio-wideo. Warstwa ta odpowiada również za ustanawianie i zamykanie sesji komunikacyjnych oraz uwzględnia parametry jakości usług (QoS), które są istotne dla różnicowania priorytetów ruchu sieciowego, szczególnie w systemach wymagających niezawodnej i terminowej transmisji danych.
1. Warstwa Transportowa
Warstwa transportowa modelu TCP/IP odgrywa kluczową rolę w zapewnianiu niezawodnej i uporządkowanej komunikacji pomiędzy aplikacjami działającymi na różnych urządzeniach sieciowych. Odpowiada za ustanawianie, utrzymywanie i zamykanie sesji komunikacyjnych, a także za kontrolę transmisji danych między hostami. Dwa główne protokoły tej warstwy to TCP (Transmission Control Protocol) i UDP (User Datagram Protocol). TCP oferuje mechanizmy potwierdzania, retransmisji, kontroli przepływu oraz zarządzania zatorami, co gwarantuje dostarczenie danych w odpowiedniej kolejności. Z kolei UDP jest protokołem bezpołączeniowym, pozbawionym kontroli błędów, ale charakteryzuje się niskim narzutem i dużą szybkością, co sprawdza się w transmisjach czasu rzeczywistego. Warstwa transportowa uwzględnia również wymagania dotyczące jakości usług (QoS), umożliwiając klasyfikację i priorytetyzację ruchu sieciowego, co ma szczególne znaczenie w aplikacjach multimedialnych, VoIP czy transmisjach strumieniowych.
1.1. Protokoły TCP i UDP
Transport Control Protocol (TCP) oraz User Datagram Protocol (UDP) to dwa główne protokoły warstwy transportowej w modelu TCP/IP, które umożliwiają komunikację pomiędzy aplikacjami działającymi na różnych urządzeniach w sieci. Oba protokoły działają nad warstwą sieciową (najczęściej opartą na IP), ale oferują zupełnie odmienne mechanizmy przesyłania danych, co przekłada się na ich odmienne zastosowania w praktyce.
TCP jest protokołem połączeniowym, co oznacza, że przed wymianą danych musi zostać ustanowione logiczne połączenie pomiędzy nadawcą a odbiorcą. Proces ten nazywany jest trzyetapowym uzgadnianiem połączenia (three-way handshake) i obejmuje wzajemną wymianę pakietów z ustawionymi flagami SYN i ACK. Po zestawieniu połączenia TCP zapewnia gwarancję dostarczenia danych w odpowiedniej kolejności, bez duplikatów i z mechanizmem retransmisji w przypadku zgubienia segmentów. Protokół ten utrzymuje stan połączenia i stale monitoruje jego parametry, takie jak numer sekwencyjny oraz potwierdzenia odbioru. TCP stosuje również mechanizmy kontroli przepływu i zarządzania zatorami, takie jak sliding window czy algorytmy slow start, dzięki czemu potrafi dynamicznie dostosować się do zmiennych warunków w sieci. Każdy segment TCP zawiera rozbudowany nagłówek zawierający m.in. informacje o porcie źródłowym i docelowym, numerze sekwencyjnym, długości danych oraz zestawie flag kontrolnych.
W przeciwieństwie do TCP, protokół UDP jest bezpołączeniowy i nie zapewnia żadnej kontroli nad dostarczaniem danych. Przesyłane pakiety, zwane datagramami, są wysyłane niezależnie od siebie, bez wcześniejszego uzgadniania stanu połączenia i bez mechanizmów potwierdzania odbioru. Odbiorca może otrzymać datagramy w dowolnej kolejności, a niektóre z nich mogą zostać utracone bez powiadomienia nadawcy. Nagłówek UDP jest znacznie prostszy niż w przypadku TCP i składa się jedynie z czterech pól: portu źródłowego, portu docelowego, długości oraz sumy kontrolnej. Dzięki minimalizmowi UDP charakteryzuje się bardzo niskim narzutem i opóźnieniami, co czyni go atrakcyjnym rozwiązaniem w zastosowaniach wymagających dużej szybkości transmisji i tolerancji na utratę danych. Przykładami takich zastosowań są transmisje multimedialne w czasie rzeczywistym, protokoły DNS, VoIP oraz gry online.
Z perspektywy architektury systemów komputerowych TCP i UDP odpowiadają na różne potrzeby aplikacji. TCP wybierany jest tam, gdzie wymagana jest niezawodność, spójność danych i kontrola błędów, natomiast UDP sprawdza się w sytuacjach, gdzie kluczowe są szybkość, prostota i brak narzutu związanego z kontrolą połączenia. Projektanci systemów sieciowych muszą odpowiednio dobrać protokół transportowy do charakterystyki aplikacji, której ma służyć, a sama warstwa transportowa pełni kluczową rolę w zarządzaniu przepływem informacji w nowoczesnych sieciach komputerowych.
Protokół TCP
Protokół TCP (Transmission Control Protocol) jest jednym z podstawowych protokołów warstwy transportowej w modelu TCP/IP. Został zaprojektowany z myślą o zapewnieniu pewnego, uporządkowanego i niezawodnego przesyłania danych między aplikacjami działającymi na różnych hostach. W przeciwieństwie do protokołów bezpołączeniowych, takich jak UDP, TCP jest połączeniowy, co oznacza, że przed rozpoczęciem transmisji danych musi zostać nawiązane logiczne połączenie między nadawcą a odbiorcą.
Protokół TCP zapewnia nawigację strumienia bajtów, co oznacza, że dane są postrzegane jako ciągły ciąg bajtów bez podziału na wiadomości czy pakiety. Każdy bajt jest numerowany, a odbiorca potwierdza odbiór tych bajtów przy pomocy mechanizmu ACK (acknowledgment). Dzięki temu możliwe jest sekwencjonowanie – dane, które dotrą w nieodpowiedniej kolejności, są sortowane u odbiorcy. TCP posiada również mechanizm retransmisji – jeśli odbiorca nie potwierdzi odebrania segmentu w określonym czasie, nadawca ponownie wysyła dane. Dodatkowo stosowane są algorytmy kontroli przepływu (flow control) i zarządzania zatorami (congestion control), dzięki czemu TCP dynamicznie dostosowuje prędkość przesyłu do warunków w sieci.
Trójfazowe ustanawianie połączenia (three-way handshake)
Aby rozpocząć komunikację, TCP używa procesu three-way handshake, który obejmuje trzy kroki:

Struktura nagłówka TCP
Nagłówek TCP ma zmienną długość (zazwyczaj 20 bajtów bez opcji), a jego pola zawierają kluczowe informacje sterujące przesyłaniem danych. Poniżej szczegółowe omówienie pól nagłówka:

Opis wybranych pól:
Port źródłowy i docelowy: identyfikują aplikacje końcowe (np. port 80 dla HTTP, port 443 dla HTTPS).
Numer sekwencyjny (SEQ): identyfikuje pierwszy bajt danych w danym segmencie. Pozwala na właściwe ułożenie danych u odbiorcy.
Numer potwierdzenia (ACK): wskazuje numer kolejnego bajtu, którego odbiorca oczekuje (czyli ostatni otrzymany bajt + 1).
Data offset: określa długość nagłówka TCP.
Flagi kontrolne (flags): pojedyncze bity służące do zarządzania połączeniem. Najważniejsze z nich:
SYN: inicjalizacja połączenia.
ACK: potwierdzenie.
FIN: zamknięcie połączenia.
RST: reset połączenia.
PSH: dane mają być natychmiast przekazane aplikacji.
URG: dane pilne.
Rozmiar okna: informuje nadawcę o liczbie bajtów, jakie może jeszcze wysłać bez otrzymania kolejnego potwierdzenia (mechanizm kontroli przepływu).
Suma kontrolna: zapewnia wykrywanie błędów w nagłówku i danych.
Wskaźnik URG: wskazuje, gdzie kończą się dane oznaczone jako pilne.
Opcje TCP: np. okno skalowania, selektywne potwierdzenia (SACK), timestamp – mogą być obecne w nagłówku po podstawowych polach.
TCP jako protokół stanowy przechowuje informacje o aktywnych połączeniach, numerach sekwencyjnych, rozmiarze buforów i czasie życia połączenia. Dzięki temu może zapewniać wysoką jakość transmisji nawet w warunkach niestabilnej sieci.
Kontrola przepływu i zarządzanie zatorami
Sesje i połączenia
Zagadnienia związane z jakością usług (QoS)
Protokół UDP
Protokół UDP (User Datagram Protocol) to jeden z podstawowych protokołów warstwy transportowej w modelu TCP/IP, obok TCP. Jego kluczową cechą jest to, że działa w sposób bezpołączeniowy, co oznacza, że nie ustanawia, nie utrzymuje ani nie kończy połączenia z drugą stroną komunikacji. Z perspektywy systemowej, UDP traktuje przesyłane dane jako oddzielne, niezależne jednostki zwane datagramami. Każdy z nich może być wysłany do odbiorcy bez konieczności uzgadniania jakiegokolwiek stanu połączenia, a nadawca nie otrzymuje informacji, czy dane dotarły, czy zostały zagubione lub odebrane w odpowiedniej kolejności.
UDP zapewnia minimalną funkcjonalność, co czyni go wyjątkowo lekki i szybki. Nie stosuje mechanizmów retransmisji, numeracji pakietów ani buforowania. Odpowiedzialność za ewentualne potwierdzenia dostarczenia, korekcję błędów, czy uporządkowanie danych może być przeniesiona na warstwę aplikacji. Dzięki temu UDP ma bardzo niskie opóźnienia transmisji (latencję), co jest kluczowe w zastosowaniach takich jak transmisja głosu (VoIP), strumieniowanie wideo w czasie rzeczywistym, gry sieciowe, DNS czy NTP, gdzie ważniejsza od niezawodności bywa szybkość.
Struktura nagłówka UDP
Nagłówek UDP ma stałą długość 8 bajtów, co czyni go niezwykle prostym w porównaniu do TCP. Składa się z czterech pól, z których każde ma długość 16 bitów (2 bajty):


Opis pól nagłówka UDP:
Port źródłowy (Source Port): identyfikuje aplikację po stronie nadawcy. Jest to pole opcjonalne – może być ustawione na zero, jeśli port nie jest istotny.
Port docelowy (Destination Port): wskazuje, do której aplikacji na hoście docelowym datagram ma trafić. To pole jest obowiązkowe.
Długość (Length): określa całkowitą długość datagramu UDP, czyli długość nagłówka (zawsze 8 bajtów) plus długość danych.
Suma kontrolna (Checksum): pole służące do wykrywania błędów w przesyłanych danych. W IPv4 jest opcjonalna, ale w IPv6 jej stosowanie jest obowiązkowe. Suma kontrolna obejmuje pseudo-nagłówek (pochodzący z warstwy IP), nagłówek UDP oraz dane. Ma to na celu lepsze wykrywanie błędów spowodowanych np. przez błędne adresowanie.
Przykład przesyłania datagramu UDP
Dzięki swojej prostocie, przesyłanie informacji za pomocą UDP odbywa się bezpośrednio i bez udziału procedur ustalających połączenie:

Nie istnieje żaden mechanizm odpowiedzi, potwierdzenia ani ponownej transmisji. Odbiorca może, ale nie musi, w ogóle odebrać datagram. Może on zostać utracony, zduplikowany, przybyć w niewłaściwej kolejności lub być uszkodzony.
Zaletą UDP jest jego wydajność. Dzięki pominięciu wielu mechanizmów kontrolnych UDP zużywa mniej zasobów systemowych i sieciowych, co jest istotne w środowiskach o ograniczonej przepustowości lub w zastosowaniach czasu rzeczywistego. Jednocześnie jednak wymaga od aplikacji, by same zapewniały potrzebną niezawodność, jeśli jest ona konieczna, np. poprzez ponowne wysyłanie wiadomości czy potwierdzenia na poziomie logiki aplikacji.
W praktyce UDP jest często stosowany tam, gdzie utrata pojedynczych pakietów jest mniej krytyczna niż opóźnienia, oraz tam, gdzie dane są przesyłane cyklicznie lub okresowo, a ciągłość ma większe znaczenie niż integralność całości przesyłu.
Porównanie protokołów
TCP (Transmission Control Protocol) i UDP (User Datagram Protocol) to dwa podstawowe protokoły warstwy transportowej w modelu TCP/IP, które służą do przesyłania danych między aplikacjami działającymi na różnych hostach sieciowych. Pomimo że pełnią tę samą ogólną funkcję, działają według zupełnie innych zasad i są przeznaczone do różnych typów zastosowań.
TCP to protokół połączeniowy i stanowy. Oznacza to, że przed przesłaniem danych między dwoma urządzeniami musi zostać nawiązane połączenie za pomocą procedury „three-way handshake”. TCP zapewnia szereg mechanizmów zwiększających niezawodność transmisji, takich jak numeracja bajtów, potwierdzanie odbioru (ACK), retransmisje zgubionych pakietów, kontrola przepływu (flow control) oraz zarządzanie zatorami (congestion control). Każdy segment TCP niesie nie tylko dane użytkownika, ale także dodatkowe informacje kontrolne, takie jak numery sekwencyjne, potwierdzenia oraz flagi, które określają stan połączenia.
UDP, w odróżnieniu od TCP, działa w trybie bezpołączeniowym i bezstanowym. Nie wymaga uprzedniego zestawienia połączenia ani nie utrzymuje informacji o stanie komunikacji. Datagramy UDP są wysyłane natychmiast, bez gwarancji dostarczenia, bez potwierdzeń i bez retransmisji. To znacząco zmniejsza narzut czasowy i systemowy, umożliwiając szybką transmisję danych w czasie rzeczywistym, ale kosztem braku niezawodności. Odpowiedzialność za ewentualną naprawę błędów lub potwierdzenia spoczywa na aplikacji.
Przykłady zastosowań protokołów TCP oraz UDP
Protokół TCP (Transmission Control Protocol) znajduje zastosowanie wszędzie tam, gdzie konieczne jest zapewnienie pełności, integralności i kolejności danych. TCP nie tylko umożliwia przesłanie pakietów, ale zapewnia także pełną kontrolę nad sesją: od rozpoczęcia po jej zamknięcie. W kontekście aplikacji sieciowych oznacza to, że klient wie, czy dane dotarły, a serwer – że zostały odebrane.
Jednym z najbardziej powszechnych zastosowań TCP jest protokół HTTP, wykorzystywany przez przeglądarki do pobierania stron WWW. Gdy użytkownik wpisuje adres strony, przeglądarka otwiera połączenie TCP z serwerem na porcie 80 (dla HTTP) lub 443 (dla HTTPS). Proces ten zaczyna się od trójfazowego handshake’u (SYN, SYN-ACK, ACK), który synchronizuje sekwencje numerów i umożliwia pełne zestawienie sesji.
Po zestawieniu połączenia klient wysyła zapytanie HTTP (np. GET /index.html), a serwer odpowiada odpowiednim zasobem. Dzięki mechanizmowi okna przesuwnego TCP może kontrolować tempo transmisji, by nie przeciążyć odbiorcy. W razie utraty pakietu TCP wykorzystuje retransmisję oraz numerację sekwencyjną, co zapewnia odbudowanie danych w poprawnej kolejności.
Dla protokołu HTTPS cały ten proces zachodzi wewnątrz bezpiecznego kanału TLS, który sam działa na TCP, wykorzystując jego cechy do zapewnienia bezpiecznej i spójnej transmisji. Nawet najmniejsze odchylenia lub zakłócenia są wykrywane i korygowane, zanim dane dotrą do aplikacji.
Podobnie sytuacja wygląda w przypadku protokołu FTP. Choć jego struktura zakłada dwa połączenia TCP – jedno do sterowania, drugie do danych – zasada pozostaje ta sama: dane muszą zostać przesłane w sposób niezawodny. Klient łączy się z serwerem na porcie 21, ustala parametry sesji, a następnie otwiera połączenie danych, np. na porcie 20. W ten sposób może przesłać plik binarny lub tekstowy bez ryzyka jego uszkodzenia. Mechanizmy TCP dbają, by każde z wysłanych segmentów dotarło i było złożone we właściwej kolejności.
Innym klasycznym przypadkiem wykorzystania TCP jest SSH (Secure Shell). Zapewnia on szyfrowany dostęp do powłoki systemowej zdalnego komputera. Każdy znak, który wpisuje użytkownik, przechodzi przez kanał TCP, a serwer odpowiada znakiem wyjściowym. Gdyby choć jeden segment zniknął lub dotarł w niewłaściwej kolejności, mogłoby to skutkować błędną interpretacją polecenia. TCP eliminuje to ryzyko.
W przeciwieństwie do TCP, UDP (User Datagram Protocol) nie zestawia połączenia ani nie utrzymuje sesji. Każdy pakiet (datagram) jest wysyłany niezależnie, bez gwarancji dostarczenia. To nie wada, ale cecha, pozwalająca osiągnąć ekstremalnie niskie opóźnienia. W aplikacjach czasu rzeczywistego, takich jak VoIP, streaming czy gry online, ważniejsza od kompletności danych jest ich szybkość.
DNS (Domain Name System) to przykład aplikacji wykorzystującej UDP. Gdy przeglądarka potrzebuje przetłumaczyć adres domenowy na IP, wysyła zapytanie UDP do serwera DNS. Ponieważ zapytania są krótkie i często powtarzalne, retransmisje są zbędne. W razie braku odpowiedzi klient po prostu ponawia zapytanie.
VoIP (Voice over IP) wykorzystuje UDP do przesyłania dźwięku. Przykładowo, aplikacja telefoniczna na smartfonie generuje pakiety audio co 20 ms i wysyła je do odbiorcy. Jeśli którykolwiek z nich się zgubi – nie jest retransmitowany. Próbka dźwięku jest po prostu pomijana. Retransmisja zajęłaby zbyt wiele czasu i pogorszyłaby jakość rozmowy.
Wideo streaming – np. przez protokół RTP (Real-time Transport Protocol) – także korzysta z UDP. Każda klatka wideo lub pakiet dźwięku trafia do odbiorcy bez pośrednictwa stanu połączenia. Jeżeli kilka ramek zostanie utraconych – odbiornik kontynuuje odtwarzanie na podstawie bufora i interpolacji.
W grach online UDP służy do przekazywania pozycji gracza, akcji, kolizji. Pakiety są wysyłane np. co 30–60 ms i zawierają stan gry. Serwer nie potwierdza ich odbioru. Silnik gry zakłada, że jeśli pakiet nie dotarł – można go pominąć lub przewidzieć jego wartość. To pozwala zachować niską latencję i płynność.
Choć UDP często kojarzony jest z transmisją o niskiej niezawodności, istnieją sytuacje, gdzie aplikacje tworzą nad nim własne mechanizmy retransmisji lub korekcji błędów. Dobrym przykładem jest QUIC, nowoczesny protokół wykorzystywany przez Google, który działa nad UDP i zapewnia funkcjonalność podobną do TCP: utrzymywanie połączenia, retransmisję, zarządzanie przeciążeniami. QUIC pozwala ominąć niektóre ograniczenia TCP – np. związaną z nim blokadę „head-of-line”, czyli sytuację, gdy brak jednego segmentu wstrzymuje dalsze przetwarzanie.
Z punktu widzenia warstwy OSI, TCP i UDP operują w tej samej – czwartej – warstwie transportowej, ale ich cechy funkcjonalne są skrajnie różne. TCP to protokół stanowy – utrzymuje informacje o numerach sekwencyjnych, czasie ostatniego potwierdzenia, stanie okna odbiorczego. Wymaga to więcej zasobów po stronie serwera, szczególnie przy tysiącach jednoczesnych połączeń.Każda sesja to osobna struktura z danymi o stanie. Dla porównania, UDP nie tworzy żadnej sesji – po odebraniu datagramu po prostu przekazuje go wyżej, niezależnie od tego, czy coś wcześniej było przesłane z danego źródła.
W praktyce często dochodzi do sytuacji, w których protokół domyślnie używa UDP, ale ma możliwość „przełączenia się” na TCP. Dotyczy to choćby DNS, który w razie odpowiedzi większej niż 512 bajtów automatycznie przełącza się na TCP. Zjawisko to określane jest jako fallback.
W dzisiejszych sieciach TCP i UDP nie rywalizują – raczej uzupełniają się. Dla przesyłania dużych plików, długich zapytań REST API, synchronizacji baz danych lub strumieni mediów wysokiej jakości z buforowaniem – TCP będzie wyborem naturalnym. Dla transmisji szybkiej, rozgłoszeniowej, zorientowanej na niskie opóźnienia, ale nie pełną niezawodność – UDP będzie protokołem bardziej odpowiednim.
Dobrym przykładem są serwery gier online. Dane kontrolne i logowania często przesyłane są przez TCP – zapewnia to ich pełność, poprawność i bezpieczeństwo. Dane o pozycji gracza, kolizjach, obrażeniach itp. – przez UDP – umożliwia to działanie z niskim opóźnieniem.
W protokole SSH istotne jest nie tylko to, że korzysta z TCP, ale też w jaki sposób zarządza danymi. Wpisanie znaku przez użytkownika powoduje wysłanie bajtu TCP – a każda operacja ma gwarancję odbioru. To kluczowe przy sterowaniu urządzeniami sieciowymi czy zdalnej administracji.
W przeciwieństwie do tego, komunikacja w stylu multicast (np. protokoły discovery, serwisy IPTV) zwykle oparta jest o UDP. TCP nie obsługuje multicastu. Dlatego transmisje grupowe – np. IPTV – wymagają UDP.
Innym zastosowaniem są systemy monitoringu – kamery IP przesyłają obraz przez UDP/RTP do odbiorników. Retransmisja klatek wideo mijałaby się z celem – ważniejsze, by strumień był ciągły, nawet jeśli kilka ramek zginie.
Aplikacje mobilne (np. komunikatory typu WhatsApp, Signal) często używają UDP do połączeń głosowych i TCP do wiadomości tekstowych. Ich logika zawiera zarówno wymóg niskiej latencji (głos), jak i niezawodności (tekst, multimedia). Pod spodem UDP wykorzystywany jest także do NAT traversal (np. STUN, TURN, ICE) – czyli umożliwienia połączeń między urządzeniami ukrytymi za NAT-em.
W systemach chmurowych, przy integracjach systemów mikroserwisowych, preferowane są połączenia TCP (np. HTTP/REST over TCP, gRPC). Niemniej, dla strumieni audio/wideo czy telemetryki z sensorów – UDP (np. z MQTT lub własnymi frame'ami) jest często lepszym wyborem.
Zastosowania w IoT również są interesujące: wiele sensorów wysyła dane z częstotliwością co kilka sekund – datagram UDP wystarczy, nie trzeba utrzymywać połączenia TCP. Jeśli jeden pakiet zaginie – dane przyjdą za 10 sekund i system nadal będzie działać poprawnie. W takiej architekturze minimalizacja zużycia energii (zwłaszcza w LoRaWAN, NB-IoT) jest kluczowa – a krótkie datagramy UDP idealnie się wpisują.
Na koniec warto wspomnieć, że mimo prostoty UDP, wiele firm stosuje mechanizmy application-layer reliability – własne potwierdzenia, okna, numery sekwencyjne, retransmisje. TCP je zawiera natywnie, ale nie zawsze wystarczy: stąd QUIC, SCTP, lub dostosowane UDP dla specjalnych potrzeb.
1.2. Kontrola przepływu i zarządzanie zatorami
Kontrola przepływu i zarządzanie zatorami to dwa niezależne, ale ściśle współpracujące mechanizmy implementowane w protokole TCP, których celem jest zapewnienie stabilnej i wydajnej komunikacji pomiędzy urządzeniami w sieci. Kontrola przepływu chroni odbiorcę przed przeciążeniem bufora poprzez ograniczanie liczby bajtów, które nadawca może wysłać bez potwierdzenia. W tym celu TCP wykorzystuje tzw. okno odbiorcze (receiver window), którego rozmiar komunikuje odbiorca w każdym segmencie ACK. Z kolei zarządzanie zatorami działa po stronie nadawcy i ma za zadanie unikać przeciążenia sieci, które może prowadzić do masowej utraty pakietów, zwiększonych opóźnień i spadku wydajności. TCP realizuje to poprzez mechanizmy kontrolujące tempo transmisji w zależności od obserwowanej odpowiedzi sieci, w tym opóźnień, utraty pakietów i potwierdzeń. Kluczowe komponenty to okno przeciążeniowe (congestion window), zmienne progowe (ssthresh) oraz algorytmy: Slow Start, Congestion Avoidance, Fast Retransmit i Fast Recovery. Obie techniki działają równolegle, zapewniając równowagę pomiędzy przepustowością a stabilnością.
W ramach kontroli przepływu TCP wykorzystuje mechanizm nazywany przesuwanym oknem odbiorczym. Działa on w oparciu o zasadę informowania nadawcy przez odbiorcę o tym, ile jeszcze bajtów danych jest w stanie przyjąć bez ryzyka przepełnienia bufora. Przy każdym pakiecie ACK odbiorca przesyła informację w polu „Window Size” nagłówka TCP, wskazując liczbę bajtów, które może jeszcze odebrać. Nadawca nie może przekroczyć tej wartości przy kolejnych wysyłanych danych. Działa to jak ogranicznik prędkości, który jest elastyczny i zależy od aktualnego stanu aplikacji odbierającej dane.
Dla przykładu, jeśli bufor odbiorcy ma pojemność 4096 bajtów, a dotychczas odebrano 1024 bajty, to w kolejnym ACK zostanie zadeklarowane „Window Size = 3072”, co informuje nadawcę, że tyle jeszcze może wysłać. Gdy bufor odbiorcy się zapełni, wartość tego pola może spaść do zera, co zmusza nadawcę do zatrzymania transmisji do momentu otrzymania okna większego od zera. To zapobiega sytuacji, w której nadawca "zalewa" odbiorcę danymi, których ten nie jest w stanie przetworzyć na czas.
Mechanizm przesuwnego okna pozwala na równoczesne zarządzanie wieloma segmentami, których odbiór jest oczekiwany. Okno „przesuwa się” do przodu wraz z postępem transmisji, co oznacza, że kolejne dane mogą być przesyłane w miarę, jak odbiorca potwierdza otrzymanie poprzednich segmentów.

Gdy odbiorca potwierdzi odebranie segmentów C i D, okno przesuwa się dalej:

Dzięki temu dane są wysyłane płynnie i tylko w zakresie, który odbiorca może przyjąć.
W standardowym TCP pole „Window Size” ma długość 16 bitów, co pozwala na zadeklarowanie maksymalnie 65 535 bajtów. W przypadku szybkich sieci, w których produkt opóźnienia i przepustowości (bandwidth-delay product) jest większy, to ograniczenie może znacząco obniżyć efektywność transmisji. Dlatego wprowadzono opcję rozszerzenia okna za pomocą tzw. „Window Scale Option”, która wprowadza mnożnik (skalę) pozwalający na deklarowanie rozmiaru okna do wartości 1 GB. Mnożnik ten ustalany jest podczas fazy nawiązywania połączenia i jest stały przez całą sesję. W ten sposób TCP może efektywnie wykorzystać szybkie połączenia, nie będąc ograniczonym przez rozmiar nagłówka.
W sytuacji, gdy wartość okna spada do zera, nadawca przerywa transmisję i oczekuje na powiększenie okna przez odbiorcę. Aby uniknąć sytuacji „wiecznego oczekiwania”, TCP stosuje mechanizm „Zero Window Probe”, w którym okresowo wysyła pojedyncze bajty danych, aby sprawdzić, czy okno odbiorcy zostało powiększone. Jeśli tak, transmisja może być wznowiona. Mechanizm ten działa jako rodzaj pulsacyjnego testu – wystarczającego, by utrzymać połączenie i sprawdzić gotowość odbiorcy do kontynuacji.
TCP nieustannie dostosowuje rozmiar swojego okna wysyłkowego, który jest efektywnym minimum z dwóch wartości: rozmiaru okna deklarowanego przez odbiorcę (flow control) oraz okna przeciążeniowego (congestion control). Ostateczna liczba bajtów, które mogą być wysłane bez potwierdzenia, to wartość min(CWND, RCV_WINDOW), co oznacza, że kontrola przepływu i zarządzanie zatorami działają razem, ustalając wspólny limit na transmisję.
Zarządzanie zatorami w TCP to mechanizm dynamicznego dostosowywania tempa transmisji danych w zależności od obciążenia sieci. W przeciwieństwie do kontroli przepływu, która chroni odbiorcę, mechanizmy przeciążeniowe mają na celu unikanie utraty pakietów w sieci wynikającej z przepełnienia buforów na routerach. Sygnały przeciążenia nie są przekazywane bezpośrednio – TCP wykrywa je pośrednio, najczęściej na podstawie utraty pakietów lub duplikatów ACK.
Główne komponenty tego mechanizmu to zmienna CWND (Congestion Window), która określa, ile bajtów nadawca może wysłać, zanim otrzyma potwierdzenia, oraz zmienna ssthresh (slow start threshold), która określa granicę między trybem Slow Start a Congestion Avoidance.
Na początku transmisji CWND wynosi 1 MSS (Maximum Segment Size), a TCP rozpoczyna transmisję w trybie Slow Start. W tym trybie, za każdy otrzymany ACK, CWND rośnie wykładniczo – co rundę RTT się podwaja. Mechanizm ten szybko „testuje” przepustowość sieci, ale prowadzi też do potencjalnego przeciążenia. W momencie, gdy CWND osiąga wartość ssthresh, TCP przechodzi do trybu Congestion Avoidance, w którym CWND rośnie już liniowo – o 1 MSS na rundę RTT.
Jeśli następuje utrata pakietu, wykryta przez timeout lub trzy duplikaty ACK, TCP uznaje to za przeciążenie sieci. W takiej sytuacji CWND zostaje zmniejszone – zależnie od algorytmu – i następuje powrót do jednej z wcześniejszych faz. Gdy pakiet zostanie utracony i nie zostanie potwierdzony, TCP inicjuje retransmisję i odpowiednio dostosowuje CWND.
Algorytm Fast Retransmit uruchamia się wtedy, gdy nadawca otrzyma trzy kolejne identyczne ACK (czyli odbiorca zgłasza „ciągle ten sam brakujący bajt”). W odpowiedzi nadawca natychmiast retransmituje brakujący segment, nie czekając na timeout. Po Fast Retransmit aktywowany jest Fast Recovery – CWND zostaje zmniejszony o połowę, ale nie do wartości początkowej, a TCP przechodzi bezpośrednio do Congestion Avoidance.
Cały ten mechanizm uzupełnia model AIMD (Additive Increase, Multiplicative Decrease), który steruje wartością CWND zgodnie z następującą logiką: po każdej rundzie bez przeciążenia CWND rośnie o 1 MSS (additive increase), natomiast po wykryciu przeciążenia CWND zostaje natychmiast zredukowane o połowę (multiplicative decrease).
Zarządzanie zatorami umożliwia TCP zachowanie tzw. sprawiedliwości sieciowej, czyli równomiernego podziału zasobów między wiele równoległych połączeń TCP, działających przez wspólną infrastrukturę. Dzięki strategii AIMD, protokoły TCP automatycznie dostosowują swoje tempo, zmniejszając agresję transmisji w przypadku wykrycia przeciążenia i zwiększając ją stopniowo w stabilnych warunkach. Z czasem każde połączenie osiąga równowagę zależną od warunków sieciowych.
Mechanizmy te, choć złożone, są przezroczyste dla użytkownika końcowego. Dla programistów oraz inżynierów sieci istotne jest jednak zrozumienie, jak TCP dynamicznie reaguje na różne warunki transmisji i jak parametry CWND, RTT, ssthresh i czas retransmisji (RTO) wpływają na efektywność, niezawodność i przepustowość połączenia. W implementacjach TCP spotyka się różne warianty algorytmów kontroli przeciążenia, takie jak TCP Reno, NewReno, Cubic, BBR – wszystkie one jednak opierają się na tych samych podstawowych zasadach adaptacyjnego sterowania ruchem.
Mechanizm przesuwnego okna (Sliding Window)
W TCP każde połączenie traktuje dane jako strumień bajtów. Aby kontrolować, ile danych można przesłać bez oczekiwania na potwierdzenie, wykorzystywane jest okno transmisyjne. Okno to reprezentuje zakres bajtów, które mogą być przesłane, ale jeszcze nie zostały potwierdzone przez odbiorcę.
Działanie okna przesuwnego
Okno przesuwne działa w następujący sposób:
Nadawca utrzymuje zmienną: rozmiar okna.
Wysłanie danych w zakresie tego okna nie wymaga oczekiwania na potwierdzenie.
Gdy odbiorca potwierdzi odbiór określonej liczby bajtów (ACK), okno przesuwa się do przodu, pozwalając na wysłanie kolejnych danych.
Załóżmy, że nadawca ma dane od bajtu 1 do 500, a rozmiar okna wynosi 100 bajtów:

W każdym cyklu przesunięcie okna zależy od tego, ile danych zostało potwierdzonych. TCP traktuje dane jako ciąg bajtów, więc każde ACK odnosi się do numeru kolejnego oczekiwanego bajtu.
Dynamiczne skalowanie okna
Rozmiar okna transmisji może być dynamicznie dostosowywany na podstawie sygnałów od odbiorcy. Jest to konieczne, gdy:
odbiorca ma ograniczone bufory;
aplikacja odbierająca dane nie nadąża z przetwarzaniem;
następuje krótkotrwały problem z wydajnością odbiorcy.
Pole „Window Size”
W nagłówku TCP znajduje się 16-bitowe pole „Window Size”, które określa ile bajtów danych odbiorca może jeszcze przyjąć. Jeśli wartość ta wynosi 0, nadawca musi wstrzymać się z dalszym wysyłaniem danych i cyklicznie próbować, czy okno zostało powiększone (mechanizm zero window probe).
Rozszerzenie okna – opcja „Window Scale”
Standardowy 16-bitowy rozmiar okna ogranicza możliwość przesłania więcej niż 65 535 bajtów bez potwierdzenia. W szybkich sieciach o dużej przepustowości i opóźnieniu (tzw. high-bandwidth delay product) może to być niewystarczające. Rozwiązaniem jest rozszerzenie rozmiaru okna dzięki opcji TCP „Window Scale”, która wprowadza 14-bitowy współczynnik skalowania.
Zjawisko blokady odbiornika (Receiver Silencing)
Jeśli aplikacja po stronie odbiorcy przestanie odbierać dane z bufora TCP, jego rozmiar może osiągnąć 0. Wtedy pole „Window Size” zostaje wyzerowane, a nadawca nie może przesyłać dalszych danych. Może jedynie cyklicznie wysyłać Zero Window Probes, aby sprawdzić, czy sytuacja uległa poprawie.
Zalety i ograniczenia
Zaletą kontroli przepływu w TCP jest to, że działa dynamicznie i automatycznie, dostosowując tempo nadawcy do możliwości odbiorcy. Umożliwia to bezpieczną transmisję danych nawet między systemami o różnych wydajnościach. Ograniczeniem natomiast jest to, że jeśli aplikacja odbiorcza jest zbyt wolna, może dojść do zatrzymania całej komunikacji.
Interakcja z zarządzaniem zatorami
Choć kontrola przepływu i zarządzanie zatorami to dwa różne mechanizmy, ich działanie może się zazębiać. Przykładowo, jeśli routery pośrednie są przeciążone, mogą zaczynać odrzucać pakiety, co zostanie zinterpretowane przez TCP jako oznaka przeciążenia – wywołując reakcję nie tylko na poziomie sieci, ale też modyfikując tempo wysyłania u nadawcy.
1.3. Sesje i połączenia
W warstwie transportowej sesja oznacza logiczne, dwukierunkowe połączenie pomiędzy dwoma procesami (aplikacjami) działającymi na odległych hostach. Choć model OSI wyodrębnia warstwę sesji jako oddzielny poziom, w praktyce funkcje tej warstwy często są realizowane przez transport, zwłaszcza przez protokół TCP. Sesja obejmuje nie tylko samą transmisję danych, ale również procesy zestawiania, utrzymywania i kończenia połączenia, a także zarządzanie numeracją bajtów, potwierdzeniami, retransmisjami i zamykaniem komunikacji.
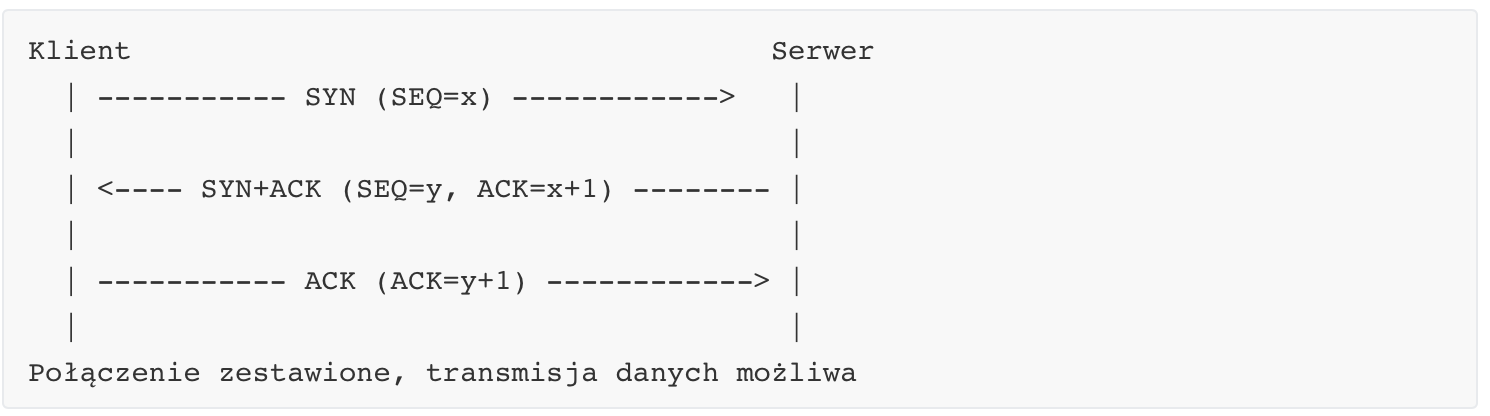
W TCP sesja rozpoczyna się od nawiązania połączenia, które realizowane jest poprzez mechanizm trójfazowego uzgadniania (three-way handshake). Proces ten służy do zsynchronizowania obu stron komunikacji, ustalenia początkowych numerów sekwencyjnych oraz potwierdzenia gotowości do rozpoczęcia transmisji danych. Inicjatorem połączenia jest zazwyczaj klient, który wysyła pierwszy segment z ustawioną flagą SYN i losowo wybranym numerem sekwencyjnym.
Pierwszy segment z SYN ustala początkowy numer sekwencyjny klienta. Drugi segment z SYN i ACK od serwera potwierdza numer klienta oraz podaje własny numer sekwencyjny. Trzeci segment z samym ACK potwierdza numer serwera. Po wykonaniu tej wymiany uznaje się, że połączenie zostało ustanowione i możliwe jest przesyłanie danych w obu kierunkach. Co ważne, każde połączenie TCP jest pełnodupleksowe, co oznacza, że każda ze stron może niezależnie wysyłać i odbierać dane.
Po ustanowieniu połączenia TCP utrzymuje stan sesji przez cały czas trwania komunikacji. W tym celu każdy z końców przechowuje informacje o bieżącym numerze sekwencyjnym, numerze potwierdzenia, rozmiarze okna odbiorczego, a także statusie flag i czasie życia połączenia. Dzięki temu możliwe jest śledzenie, które dane zostały wysłane, które zostały potwierdzone, oraz które muszą być retransmitowane. Stan ten jest przechowywany w strukturach nazywanych kontrolnymi blokami połączeń (Transmission Control Blocks, TCB), które zawierają również informacje o lokalnym i zdalnym porcie oraz adresach IP.
Zakończenie sesji TCP odbywa się w sposób kontrolowany i również składa się z wymiany segmentów. W przeciwieństwie do nawiązywania połączenia, które odbywa się w trzech krokach, zamykanie sesji TCP wymaga czterech etapów – każdy kierunek transmisji musi zostać zamknięty niezależnie.
Każda strona, która nie ma już danych do wysłania, inicjuje zamknięcie połączenia przez przesłanie segmentu z flagą FIN. Druga strona potwierdza ten segment (ACK), ale dopóki sama ma dane do wysłania, utrzymuje połączenie otwarte. Dopiero po zakończeniu własnej transmisji również wysyła FIN, na co pierwsza strona odpowiada ACK. Ten proces zapewnia, że żadna ze stron nie utraci ostatnich danych. Po wysłaniu ACK w odpowiedzi na FIN, gniazdo TCP wchodzi w stan TIME_WAIT, w którym pozostaje przez 2×MSL (Maximum Segment Lifetime), aby zapobiec ponownemu wykorzystaniu tych samych numerów sekwencyjnych.
TCP wykorzystuje zestaw flag w nagłówku segmentu, które kontrolują przebieg sesji. Flaga SYN służy do inicjalizacji połączenia. Flaga ACK oznacza potwierdzenie odbioru segmentu lub numeru sekwencyjnego. Flaga FIN sygnalizuje zakończenie transmisji w jednym kierunku. Flaga RST używana jest do natychmiastowego zerwania połączenia – zazwyczaj w sytuacjach wyjątkowych, takich jak próba komunikacji z nieistniejącym gniazdem. W kontekście sesji flagi te odgrywają kluczową rolę w utrzymaniu spójnego stanu po obu stronach komunikacji.
Numeracja sekwencyjna to podstawowy mechanizm umożliwiający TCP śledzenie kolejności bajtów w strumieniu danych. Każdy bajt w strumieniu ma przypisany unikalny numer, a segmenty TCP zawierają numer początkowy bajtu, który zawierają. Odbiorca na podstawie numerów sekwencyjnych i potwierdzeń (ACK) wie, które bajty zostały poprawnie dostarczone, a nadawca – które mogą wymagać retransmisji. Numer sekwencyjny ustalany jest losowo na początku sesji (w ramach handshake) w celu zwiększenia bezpieczeństwa i ochrony przed atakami typu spoofing. Zarządzanie numerami sekwencyjnymi jest kluczowe, ponieważ pozwala na niezależne kontrolowanie dwóch jednokierunkowych strumieni danych w ramach jednego połączenia TCP.
Ważnym aspektem transmisji danych w TCP jest problem idempotencji, czyli odporności na wielokrotne wykonanie tej samej operacji. TCP nie zakłada, że przesłane dane dotrą tylko raz – każdy segment może zostać zduplikowany i retransmitowany. Aby zapewnić poprawność działania, protokoły wyższych warstw (np. HTTP, FTP) muszą być projektowane tak, aby potrafiły zidentyfikować i właściwie obsłużyć powtórne dostarczenie tych samych danych. Przykładowo, serwer HTTP powinien wiedzieć, czy klient rzeczywiście ponownie żąda pliku, czy tylko otrzymał powtórkę pakietu. TCP dba jedynie o to, aby wszystkie bajty zostały dostarczone w odpowiedniej kolejności i bez błędów – nie interpretuje ich znaczenia.
Połączenia TCP mogą czasem znajdować się w stanie tzw. half-open, czyli półotwartym. Taka sytuacja występuje wtedy, gdy jedna ze stron (np. klient) uważa, że połączenie jest nadal aktywne, podczas gdy druga strona (np. serwer) już je zakończyła lub uległa awarii. Półotwarte połączenia mogą prowadzić do wycieków zasobów i błędów komunikacyjnych. W celu wykrycia takich sytuacji TCP stosuje mechanizmy takie jak keep-alive, które co pewien czas wysyłają specjalne segmenty sprawdzające, czy druga strona nadal odpowiada. Jeśli nie, połączenie może zostać jednostronnie zamknięte.
Alternatywą dla TCP jest protokół UDP, który z definicji nie obsługuje sesji ani nie utrzymuje żadnego stanu. UDP wysyła datagramy niezależnie od siebie, bez uprzedniego nawiązywania połączenia, bez potwierdzeń i bez mechanizmów kontroli transmisji. Nie ma numeracji sekwencyjnej, nie ma retransmisji, nie ma kontroli przepływu ani zarządzania zatorami. Aplikacja korzystająca z UDP musi samodzielnie radzić sobie z problemami związanymi z kolejnością, duplikacją i utratą danych – jeśli w ogóle tego wymaga. Sesje, w rozumieniu TCP, nie istnieją w UDP. Każdy pakiet jest traktowany jako osobna jednostka logiczna, a nadawca nie ma informacji, czy odbiorca istnieje, czy odebrał dane, czy jest gotowy do dalszej komunikacji.
Brak sesji w UDP powoduje, że protokół ten jest bezstanowy, co oznacza, że nie przechowuje żadnych informacji o przeszłej komunikacji. Dzięki temu UDP charakteryzuje się bardzo niskim narzutem protokołu i jest idealny do transmisji w czasie rzeczywistym (np. VoIP, wideo, gry online), gdzie opóźnienia są bardziej krytyczne niż gwarancja dostarczenia. Niemniej jednak brak mechanizmów sesyjnych oznacza również brak ochrony przed wieloma typami błędów, które TCP obsługuje domyślnie.
Podsumowując, sesje w warstwie transportowej TCP są fundamentalnym elementem niezawodnej komunikacji w sieciach komputerowych. Obejmują one cały cykl życia połączenia: od negocjacji parametrów, przez zarządzanie stanem i numeracją, aż po eleganckie zakończenie. TCP oferuje pełen zestaw narzędzi do kontrolowania przepływu danych, ich kolejności, niezawodności oraz wykrywania problemów, podczas gdy UDP celowo rezygnuje z tych funkcjonalności na rzecz prostoty i szybkości. Zrozumienie różnic pomiędzy tymi podejściami jest kluczowe dla inżynierów projektujących aplikacje sieciowe, którzy muszą wybrać odpowiedni protokół w zależności od wymagań transmisji, niezawodności, opóźnień i obciążenia sieci.
1.4. Zagadnienia związane z jakością usług (QoS)
Zagadnienia związane z jakością usług (QoS) w sieciach komputerowych stanowią jeden z kluczowych obszarów badań i inżynierii systemów sieciowych. QoS, czyli Quality of Service, odnosi się do zestawu technik, mechanizmów oraz parametrów, które mają na celu kontrolowanie, gwarantowanie lub poprawianie jakości transmisji danych przez sieć. Pojęcie jakości usług nabiera szczególnego znaczenia w kontekście sieci zróżnicowanych aplikacyjnie – gdzie różne typy ruchu, takie jak transmisje wideo, rozmowy głosowe, synchronizacja danych czy zapytania do baz danych, konkurują o te same zasoby komunikacyjne. Ponieważ zasoby te (przepustowość, buforowanie, czasy przetwarzania, opóźnienia) są ograniczone, niezbędne jest wdrożenie mechanizmów umożliwiających ich odpowiedni podział i zarządzanie.
QoS obejmuje zarówno aspekty ilościowe, takie jak dostępna przepustowość (bandwidth), średnie opóźnienie (latency), zmienność opóźnienia (jitter), jak i jakość percepcyjną, która ma szczególne znaczenie w aplikacjach czasu rzeczywistego, takich jak VoIP (Voice over IP), wideokonferencje, transmisje live czy gry sieciowe. Parametry te nie są tylko czysto techniczne – ich wartości bezpośrednio wpływają na komfort użytkownika końcowego. Na przykład, wysoki jitter w połączeniu głosowym może powodować zniekształcenia dźwięku, mimo że przepustowość sieci jest wysoka. Odpowiednie zarządzanie QoS wymaga więc nie tylko alokacji zasobów, ale również klasyfikacji pakietów, ich kolejkowania, oznaczania priorytetów i mechanizmów reagowania w przypadku przeciążeń lub awarii.
W klasycznych sieciach best-effort, takich jak standardowy model działania Internetu, wszystkie pakiety traktowane są jednakowo. Niezależnie od tego, czy są to pakiety wideo, zapytania DNS czy fragmenty plików FTP – nie mają przypisanego priorytetu ani nie są obsługiwane przez mechanizmy, które gwarantowałyby im określony poziom usługi. Ten model jest prosty i skalowalny, ale nieprzystosowany do potrzeb współczesnych aplikacji wrażliwych na opóźnienia. Dlatego wprowadzono szereg modeli i mechanizmów QoS, które pozwalają różnicować sposób obsługi ruchu, zapewniać priorytety, a w skrajnych przypadkach – gwarancje parametrów transmisji.
Jednym z podstawowych elementów QoS jest klasyfikacja ruchu, czyli zdolność sieci do rozróżnienia, do jakiej klasy należy dany pakiet. Klasyfikacja może być realizowana na podstawie informacji zawartych w nagłówkach protokołów warstw 3 i 4 (np. adres IP, port TCP/UDP) albo przez bardziej zaawansowane mechanizmy inspekcji pakietów. Dzięki klasyfikacji można przypisać pakietom etykiety oznaczające ich istotność. Przykładowo, pakiet RTP z głosem w czasie rzeczywistym może być oznaczony jako „priorytet wysoki”, podczas gdy pakiet z aktualizacją systemu operacyjnego jako „priorytet niski”.
W kolejnych etapach przetwarzania pakiety trafiają do kolejek obsługiwanych z różnym priorytetem. Najpopularniejsze metody obsługi kolejek to FIFO (pierwsze przyszło, pierwsze wyszło), WFQ (Weighted Fair Queuing), PQ (Priority Queuing) oraz CBWFQ (Class-Based Weighted Fair Queuing). Techniki te różnią się podejściem do kolejności obsługi pakietów oraz udziałem pasma przypisanym poszczególnym klasom ruchu. Na przykład, PQ może zawsze obsługiwać pakiety głosowe przed innymi, co gwarantuje niskie opóźnienia, ale może prowadzić do wygłodzenia mniej istotnych klas.
QoS może być realizowany według dwóch głównych modeli: IntServ (Integrated Services) i DiffServ (Differentiated Services). IntServ opiera się na rezerwacji zasobów w całej ścieżce transmisji i jest zbliżony do koncepcji kanałów w sieciach telefonicznych – każda aplikacja żąda określonych zasobów, a sieć albo przydziela je, albo odrzuca żądanie. Głównym protokołem wspierającym IntServ jest RSVP (Resource Reservation Protocol), który umożliwia przesyłanie żądań rezerwacji i ich potwierdzeń. Ten model oferuje silne gwarancje jakości, ale jest mało skalowalny i trudny w implementacji w globalnym Internecie.
DiffServ jest bardziej praktycznym rozwiązaniem i opiera się na przypisywaniu pakietom etykiet w polu DSCP (Differentiated Services Code Point) nagłówka IP. Pakiety są oznaczane zgodnie z wcześniej zdefiniowanymi klasami usług (np. EF – Expedited Forwarding dla VoIP, AF – Assured Forwarding dla ważnych danych) i obsługiwane przez routery zgodnie z tymi oznaczeniami. DiffServ nie gwarantuje twardej rezerwacji zasobów, ale umożliwia różnicowanie poziomu usług i bardzo dobrą skalowalność.

Z punktu widzenia warstwy transportowej, QoS dotyka głównie TCP i UDP jako podstawowych protokołów. TCP jest wrażliwy na opóźnienia, stratę pakietów i jitter, ponieważ jego mechanizmy retransmisji oraz dostosowywania tempa transmisji (np. poprzez CWND) zakładają pewne modele zachowania sieci. Jeśli jitter jest wysoki, może dochodzić do niepotrzebnych retransmisji lub nadmiernego zmniejszenia okna przeciążeniowego, co wpływa negatywnie na wydajność. UDP nie implementuje własnych mechanizmów QoS – jest bezstanowy i nie gwarantuje dostarczenia danych – dlatego jego użycie w aplikacjach czasu rzeczywistego wymaga wsparcia ze strony infrastruktury sieciowej. To routery, przełączniki i punkty dostępowe muszą zapewnić, że pakiety UDP będą miały odpowiedni priorytet i minimalne opóźnienia.
W systemach opartych o MPLS (Multiprotocol Label Switching) możliwe jest jeszcze bardziej zaawansowane zarządzanie QoS. MPLS umożliwia przypisywanie ścieżek przesyłu danych z uwzględnieniem klasy usług i może współpracować z modelami DiffServ. Przykładowo, pakiety VoIP mogą być kierowane przez szybsze i mniej przeciążone łącza, a dane mniej wrażliwe – przez kanały o niższym priorytecie. MPLS rozszerza możliwości QoS również w kontekście tzw. Traffic Engineering, gdzie inżynierowie mogą projektować sieci zgodnie z oczekiwanym ruchem i wymaganiami jakościowymi.
QoS nie jest też domeną wyłącznie dużych operatorów czy sieci korporacyjnych. W nowoczesnych domowych sieciach Wi-Fi QoS bywa realizowane przez funkcje takie jak WMM (Wi-Fi Multimedia), które przypisują różne priorytety do danych głosowych, wideo, danych ogólnych i sygnałów kontrolnych. Przykładowo, transmisja z kamery IP lub połączenia przez komunikator może otrzymać wyższy priorytet niż pobieranie pliku.
Równie istotne jak aspekty techniczne są aspekty biznesowe QoS. W sieciach operatorów telekomunikacyjnych QoS jest podstawą umów SLA (Service Level Agreement), w których usługodawca zobowiązuje się do utrzymania określonych parametrów transmisji, np. maksymalnego opóźnienia, dostępności usługi czy minimalnej przepustowości. Takie zobowiązania wymagają nie tylko monitorowania i raportowania parametrów sieciowych, ale również implementacji systemów automatycznego wykrywania i reagowania na pogorszenie jakości.
Mechanizmy QoS wiążą się także z bezpieczeństwem i zarządzaniem przeciążeniami. Ataki typu DDoS (Distributed Denial of Service) mogą zapełnić kolejki ruchu o niskim priorytecie, wpływając przy okazji na inne klasy ruchu. Dlatego niektóre systemy QoS uwzględniają również mechanizmy ochronne, takie jak policing (odrzucanie nadmiarowego ruchu), shaping (regulowanie tempa transmisji) i remarking (zmiana klasy pakietu). Zastosowanie tych technik może skutecznie ograniczyć skutki niepożądanych zjawisk sieciowych.
QoS to nie tylko mechanizmy w infrastrukturze, ale także proces zarządzania – obejmuje analizę ruchu, pomiar jakości, adaptacyjne planowanie pasma, oraz integrację z systemami zarządzania usługami. W nowoczesnych architekturach sieci, takich jak SDN (Software-Defined Networking), QoS może być realizowane dynamicznie na podstawie polityk i reguł aplikacyjnych, co pozwala np. aplikacji wideokonferencyjnej zgłosić zapotrzebowanie na niskie opóźnienie i automatycznie otrzymać odpowiedni poziom usług.
W środowiskach chmurowych QoS ma znaczenie nie tylko dla transmisji między użytkownikami a chmurą, ale również w ramach samych centrów danych – np. podczas synchronizacji replik baz danych, migracji maszyn wirtualnych czy działania kontenerów, gdzie opóźnienia sieciowe mogą powodować realne konsekwencje dla aplikacji rozproszonych. W takich środowiskach stosuje się również techniki lokalne, takie jak ograniczanie IOPS dla urządzeń blokowych, przydział zasobów CPU, czy regulacja pasma interfejsów wirtualnych.
QoS, choć trudny w implementacji na skalę globalną, pozostaje kluczowym elementem architektury sieci nowej generacji. Jego skuteczność zależy zarówno od implementacji technicznej w urządzeniach sieciowych, jak i od właściwego projektowania polityk, monitoringu i ciągłego dostrajania ustawień zgodnie z realnymi wymaganiami aplikacji i użytkowników.
2. Sieci IP i Routing
Adresacja IP (Internet Protocol) jest fundamentalnym mechanizmem identyfikowania urządzeń w sieciach komputerowych, zarówno lokalnych, jak i globalnych. Każde urządzenie podłączone do sieci IP musi posiadać unikalny adres, który umożliwia jego jednoznaczną identyfikację i zapewnia możliwość komunikacji z innymi węzłami sieci.
2.1. Adresacja IP i podział sieci
Wprowadzenie do adresacji IP
Adresacja IP (Internet Protocol) jest fundamentalnym mechanizmem identyfikowania urządzeń w sieciach komputerowych, zarówno lokalnych, jak i globalnych. Każde urządzenie podłączone do sieci IP musi posiadać unikalny adres, który umożliwia jego jednoznaczną identyfikację i zapewnia możliwość komunikacji z innymi węzłami sieci. Adres IP spełnia zatem funkcję identyfikatora logicznego – pełni rolę „adresu” w strukturze logicznej sieci, analogicznie do adresu pocztowego w systemie doręczania korespondencji.
Adresy IP występują w dwóch wersjach – IPv4 oraz IPv6. Obecnie najczęściej stosowanym formatem jest IPv4, chociaż rosnące zapotrzebowanie na adresy oraz ograniczenia tej wersji doprowadziły do intensywnego wdrażania protokołu IPv6, który oferuje znacznie większą przestrzeń adresową.
Adresy IPv4
Adres IPv4 to liczba 32-bitowa, zwykle zapisywana w postaci czterech oktetów dziesiętnych oddzielonych kropkami (np. 192.168.1.1). Każdy oktet może przyjmować wartości od 0 do 255. Adres IPv4 składa się z dwóch głównych części: identyfikatora sieci (network ID) i identyfikatora hosta (host ID). Pierwszy z nich wskazuje konkretną sieć, do której należy adres, natomiast drugi identyfikuje konkretne urządzenie w tej sieci.
Struktura adresów IPv4 została początkowo zorganizowana według tzw. klas adresowych (klasy A, B, C, D i E), z których klasy A, B i C były wykorzystywane do powszechnej adresacji hostów. Klasyfikacja ta została jednak zastąpiona bardziej elastycznym systemem CIDR (Classless Inter-Domain Routing), który pozwala na dowolne „przycinanie” adresów IP za pomocą masek sieciowych.
Maska sieci i podział na podsieci
Maska podsieci (subnet mask) to ciąg 32-bitowy, który określa, jaka część adresu IP odnosi się do sieci, a jaka do hostów. Najczęściej stosuje się zapis notacji CIDR, w którym po adresie IP występuje liczba określająca długość prefiksu sieciowego, np. 192.168.1.0/24 oznacza, że pierwsze 24 bity to identyfikator sieci.
Podział sieci (subnetting) polega na logicznym rozbiciu jednej dużej sieci na wiele mniejszych podsieci. Proces ten zwiększa efektywność zarządzania adresami i pozwala na lepszą segmentację ruchu w sieci. W sieciach dużych organizacji, podział na podsieci jest nieodzowny – pozwala np. oddzielić segmenty biurowe od serwerowych czy zarządzać dostępem między różnymi działami firmy.
Dzięki subnettingowi można również zaimplementować reguły kontroli dostępu (ACL), izolować ruch multicastowy, czy efektywnie wykorzystywać pulę przydzielonych adresów IP. Przykładowo, mając adres sieci 192.168.0.0/24, można utworzyć dwie podsieci po 128 adresów każda, stosując maskę /25 (czyli 255.255.255.128), co daje dwie sieci: 192.168.0.0/25 i 192.168.0.128/25.
Adresy specjalne i zakresy prywatne
Wśród adresów IPv4 istnieją również zakresy zarezerwowane dla konkretnych celów. Adresy prywatne (np. 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16) są używane w sieciach lokalnych i nie są routowane w Internecie. Adres 127.0.0.1 to tzw. adres loopback, wykorzystywany do testowania stosu sieciowego na własnym urządzeniu.
Aby umożliwić komunikację urządzeń z adresami prywatnymi z Internetem, stosuje się mechanizmy translacji adresów, z których najbardziej znany to NAT (Network Address Translation).
IPv6 – adresacja nowej generacji
W odpowiedzi na ograniczenia IPv4, w tym przede wszystkim wyczerpywanie się dostępnej przestrzeni adresowej, opracowano nową wersję protokołu – IPv6. Adres IPv6 ma długość 128 bitów, co pozwala na zaadresowanie niewyobrażalnie dużej liczby urządzeń (2¹²⁸). Adresy IPv6 zapisywane są w postaci ośmiu grup czteroznakowych liczb szesnastkowych, oddzielonych dwukropkami, np. 2001:0db8:85a3:0000:0000:8a2e:0370:7334.
IPv6 wprowadza również inne zmiany strukturalne. Nie występuje w nim klasyczny podział na sieć i host – całość jest zarządzana za pomocą długości prefiksu, np. /64. Adresacja IPv6 zakłada szerokie stosowanie autokonfiguracji (SLAAC – Stateless Address Autoconfiguration) oraz eliminację potrzeby stosowania NAT.
Zaletą IPv6 jest także uproszczona struktura nagłówka, możliwość efektywnego routingu oraz wbudowana obsługa IPsec, co sprzyja bezpieczeństwu transmisji. Pomimo tych zalet, pełna migracja z IPv4 do IPv6 jest procesem długofalowym i wymagającym kompatybilności w wielu warstwach infrastruktury sieciowej.
Znaczenie adresacji IP w projektowaniu sieci
Poprawna adresacja IP i świadome planowanie przestrzeni adresowej to fundament dobrze zaprojektowanej sieci. Umożliwia to nie tylko optymalne wykorzystanie zasobów adresowych, lecz także zapewnia przejrzystość struktury logicznej sieci i ułatwia jej rozbudowę, zarządzanie oraz diagnozowanie problemów. Dobrze zorganizowana adresacja ułatwia stosowanie polityk bezpieczeństwa, filtrowanie ruchu, segmentację sieci VLAN oraz wdrażanie usług takich jak DHCP czy DNS.
Na etapie projektowania istotne jest również uwzględnienie przyszłych potrzeb – adresacja powinna umożliwiać skalowalność sieci, bez konieczności jej przebudowy przy każdym rozszerzeniu. Dlatego administratorzy często stosują rezerwy adresów, alokacje z zapasem lub hierarchiczne modele podziału adresów, szczególnie w większych środowiskach.
Mechanizmy routingu: statyczny i dynamiczny
Protokoły routingu: RIP, OSPF, BGP
IPv4 i IPv6
2.2. Mechanizm routingu - statyczny i dynamiczny
Wprowadzenie do routingu
Routing (trasowanie) to proces decydowania o tym, którędy powinien zostać przesłany pakiet danych w sieci komputerowej z jego źródła do miejsca docelowego. Jest to podstawowy mechanizm działania sieci rozległych (WAN) i większych sieci lokalnych (LAN), który umożliwia komunikację między różnymi segmentami sieci, a także między różnymi sieciami. Routing realizowany jest przez specjalne urządzenia zwane routerami, które analizują docelowy adres IP pakietu i podejmują decyzję o dalszym kierunku jego przesyłania.
W praktyce routing może być realizowany na dwa sposoby – ręcznie, przez administratora (routing statyczny), lub automatycznie, przy wykorzystaniu protokołów routingu (routing dynamiczny). Każdy z tych mechanizmów ma swoje cechy, zastosowania, zalety i ograniczenia, które należy rozumieć w kontekście architektury i wymagań danej sieci.
Routing statyczny
Routing statyczny opiera się na ręcznym definiowaniu tras w tablicy routingu routera. Administrator wprowadza konkretne informacje określające, którędy mają być kierowane pakiety do określonych sieci docelowych. Taka trasa statyczna zawiera zazwyczaj adres sieci docelowej, maskę podsieci, adres następnego przeskoku (next-hop) lub interfejs wyjściowy.
Zaletą routingu statycznego jest jego prostota oraz pełna kontrola nad trasami. W sieciach o niewielkim rozmiarze i niskiej zmienności topologii może być to rozwiązanie wystarczające, bardzo stabilne i przewidywalne. Ponieważ nie są wymieniane żadne komunikaty routingu między routerami, routing statyczny jest również bezpieczniejszy (trudniej go zmanipulować), a jego konfiguracja zużywa mniej zasobów sprzętowych i pasma.
Jednak routing statyczny ma też istotne ograniczenia. Przede wszystkim nie jest skalowalny – każda zmiana w strukturze sieci (np. dodanie nowej podsieci, awaria łącza) wymaga ręcznej modyfikacji tras na odpowiednich routerach. W większych sieciach lub w środowiskach dynamicznych, gdzie topologia często się zmienia, zarządzanie trasami statycznymi staje się bardzo czasochłonne i podatne na błędy. Routing statyczny nie ma również wbudowanych mechanizmów wykrywania awarii łączy ani automatycznego wyboru alternatywnych tras.
Mimo tych ograniczeń, routing statyczny wciąż znajduje zastosowanie – zwłaszcza w sieciach peryferyjnych, małych oddziałach, środowiskach testowych oraz wszędzie tam, gdzie stabilność i przewidywalność tras są ważniejsze niż elastyczność. Może też stanowić zabezpieczenie dla tras dynamicznych (tzw. trasę domyślną lub trasę awaryjną – fallback).
Routing dynamiczny
Routing dynamiczny wykorzystuje specjalne protokoły, które pozwalają routerom na wymianę informacji o dostępnych trasach i ich jakości. Dzięki temu routery są w stanie automatycznie dostosować się do zmian w topologii sieci, takich jak pojawienie się nowej podsieci, awaria łącza, zmiana kosztów ścieżki czy reorganizacja segmentów.
Dynamiczne protokoły routingu automatyzują proces utrzymania i aktualizacji tablic routingu. W zależności od charakterystyki i potrzeb sieci, można stosować różne protokoły, z których każdy ma inne algorytmy, metryki oraz zakres działania. Do najczęściej używanych należą: RIP (Routing Information Protocol), OSPF (Open Shortest Path First) oraz BGP (Border Gateway Protocol), które zostaną szczegółowo omówione w kolejnym podrozdziale.
Podstawową zaletą routingu dynamicznego jest jego elastyczność. Routery na bieżąco reagują na zmiany w sieci, mogą wykrywać i omijać uszkodzone łącza, rekonfigurować trasy i balansować obciążenie. W dużych sieciach i środowiskach rozproszonych jest to mechanizm praktycznie niezbędny. Dynamiczny routing redukuje także konieczność ręcznej interwencji administratora przy każdej zmianie w architekturze sieci.
Jednocześnie należy pamiętać, że routing dynamiczny wymaga więcej zasobów – zarówno obliczeniowych (CPU, pamięć), jak i transmisyjnych (ruch kontrolny generowany przez protokoły routingu). Wprowadza również pewne ryzyko bezpieczeństwa, ponieważ złośliwe lub nieautoryzowane urządzenia mogą próbować wpływać na strukturę tras w sieci. Dlatego ważne jest stosowanie mechanizmów autoryzacji i filtrowania informacji routingu, a także staranny dobór protokołów do konkretnego środowiska.
Routing domyślny
W kontekście obu mechanizmów warto także wspomnieć o koncepcji routingu domyślnego. Jest to mechanizm, w którym pakiety kierowane do nieznanych sieci są przesyłane do określonego routera (tzw. bramy domyślnej). Umożliwia to uproszczenie konfiguracji, zwłaszcza w sieciach z dostępem do Internetu, gdzie wszystkie połączenia wychodzące kierowane są przez jeden punkt styku.
Trasa domyślna może być zdefiniowana zarówno statycznie, jak i dynamicznie, i stanowi bardzo użyteczne narzędzie w zarządzaniu ruchem sieciowym, szczególnie w środowiskach z jedną dominującą trasą wyjściową.
Zestawienie różnic
Routing statyczny oferuje prostotę i pełną kontrolę, lecz kosztem elastyczności i automatyzacji. Routing dynamiczny przeciwnie – automatyzuje zarządzanie trasami, dostosowując się do zmian w sieci, ale wymaga większej mocy obliczeniowej i może być bardziej podatny na problemy, jeśli nie zostanie właściwie zabezpieczony i skonfigurowany. W praktyce wiele organizacji stosuje oba mechanizmy równolegle, łącząc ich zalety w spójnej polityce routingu.
2.3. Protokoły routingu - RIP, OSPF, BGP
Protokoły routingu to zestawy reguł i mechanizmów wykorzystywanych przez routery do wymiany informacji o trasach w sieciach komputerowych. Dzięki nim urządzenia są w stanie dynamicznie dostosowywać swoje tablice routingu do aktualnej topologii sieci i wybierać najlepsze dostępne ścieżki do docelowych adresów IP. W zależności od skali i charakteru sieci stosuje się różne protokoły – od prostych, takich jak RIP, po zaawansowane, jak OSPF i BGP. Każdy z nich wykorzystuje odmienne algorytmy, metryki oraz modele zarządzania trasami. W niniejszym podrozdziale przedstawione zostaną trzy najważniejsze protokoły routingu: RIP (Routing Information Protocol), OSPF (Open Shortest Path First) oraz BGP (Border Gateway Protocol), z uwzględnieniem ich działania, zalet, ograniczeń oraz zastosowań.
Protokół RIP
Routing Information Protocol (RIP) należy do najstarszych i najlepiej znanych protokołów routingu typu wektora odległości (distance-vector). Opiera się na prostym mechanizmie, w którym każdy router cyklicznie informuje swoich sąsiadów o znanych mu trasach do sieci docelowych oraz liczbie przeskoków (ang. hop count) potrzebnych do ich osiągnięcia. To właśnie liczba przeskoków stanowi metrykę stosowaną w RIP – im mniejsza liczba przeskoków, tym bardziej preferowana jest dana ścieżka. Maksymalna liczba przeskoków wynosi 15 – każda trasa oznaczona jako 16 jest uznawana za nieosiągalną. To ograniczenie znacząco wpływa na skalowalność protokołu i czyni go praktycznym jedynie w przypadku mniejszych sieci.
Protokół RIP powstał na bazie wcześniejszych rozwiązań rozwijanych od lat 70., takich jak GWINFO w systemie Xerox Network Systems. Wersja RIP dla protokołu IP została zaimplementowana w demonie routed w systemie 4.2BSD i szybko zyskała popularność w systemach UNIX. Wersja pierwsza protokołu RIP – RIPv1 – została sformalizowana w 1988 roku.
RIPv1
Pierwotna specyfikacja protokołu RIP w wersji pierwszej (RIPv1) została opublikowana w 1988 roku. Po uruchomieniu routera obsługującego RIPv1, a następnie co 30 sekund, router ten rozsyła wiadomość żądania (request) do adresu rozgłoszeniowego 255.255.255.255 przez wszystkie interfejsy, na których aktywowano RIPv1. Routery sąsiednie, które odbiorą to żądanie, odpowiadają komunikatem zawierającym własną tablicę routingu. Router, który wysłał żądanie, aktualizuje na tej podstawie swoją tablicę, zapisując w niej osiągalne adresy sieci IP, liczbę przeskoków oraz adres następnego przeskoku, czyli adres interfejsu routera, od którego pochodziła odpowiedź.
W miarę odbierania aktualizacji od różnych sąsiadów, router uzupełnia swoją tablicę tras tylko wtedy, gdy otrzyma informację o sieci, której wcześniej nie znał, lub jeśli nowa trasa do znanej już sieci ma mniejszą liczbę przeskoków. Z tego powodu w typowych przypadkach router RIPv1 będzie miał w tablicy tylko jeden wpis dla danej sieci – ten, który wskazuje trasę o najmniejszej liczbie przeskoków. Jeżeli jednak otrzyma informacje o tej samej sieci od dwóch różnych sąsiadów i liczba przeskoków w obu przypadkach będzie taka sama, router może umieścić dwa wpisy do tej sieci, każdy wskazujący innego sąsiada jako następny przeskok. W takiej sytuacji router zastosuje mechanizm równoważenia obciążenia przy trasach o równym koszcie (equal-cost load balancing), dzieląc ruch IP pomiędzy dostępne trasy.
Routery korzystające z RIPv1 nie tylko co 30 sekund żądają informacji routingu od sąsiadów, ale również nasłuchują przychodzących żądań i w odpowiedzi same przesyłają swoją tablicę tras. W rezultacie tablice RIPv1 są aktualizowane średnio co 25–35 sekund. Aby uniknąć sytuacji, w której wiele routerów w tej samej sieci LAN aktualizuje swoje trasy jednocześnie, protokół wprowadza niewielką losowość do interwałów czasowych. Zakładano, że dzięki temu aktualizacje będą rozproszone w czasie, lecz badania Sally Floyd i Van Jacobsona z 1994 roku wykazały, że bez dodatkowej losowej zmienności timery i tak synchronizują się w czasie, prowadząc do zbieżnych zachowań routerów.
Protokół RIPv1 można skonfigurować w trybie „milczącym” (silent mode), w którym router nasłuchuje i przetwarza aktualizacje od sąsiadów, samodzielnie uaktualniając swoją tablicę tras, lecz nie rozsyła swojej tablicy w sieci. Tryb ten stosuje się zazwyczaj na urządzeniach końcowych (hostach), które nie pełnią funkcji trasujących.
RIPv1 wykorzystuje klasyczny, tzw. klasowy mechanizm routingu. Oznacza to, że aktualizacje tras nie zawierają informacji o maskach podsieci, co uniemożliwia stosowanie masek o zmiennej długości (VLSM). W praktyce wszystkie podsieci w obrębie jednej klasy adresowej muszą mieć identyczny rozmiar. Brakuje również wsparcia dla uwierzytelniania routerów, co czyni protokół podatnym na różne ataki i manipulacje. Te istotne ograniczenia zostały rozwiązane dopiero w późniejszej wersji protokołu – RIPv2.
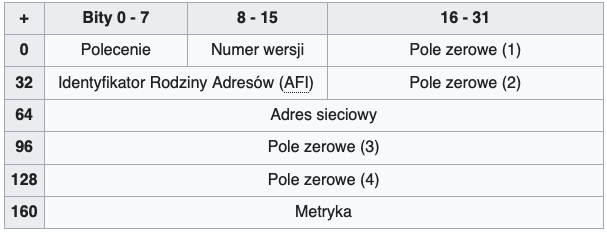
Polecenie To pole wskazuje, czy wiadomość RIP jest zapytaniem o aktualne trasy, czy odpowiedzią zawierającą tablicę routingu.
Numer wersji Określa, której wersji protokołu RIP dotyczy komunikat – możliwe wartości to 1 (RIPv1) lub 2 (RIPv2).
Pole zerowe (1) W wersji RIPv1 pole to musi być ustawione na wartość zero. W przypadku RIPv2 wykorzystywane jest do określenia numeru domeny routingu.
Identyfikator rodziny adresów To pole identyfikuje typ adresów używanych w polu adresu sieciowego. Dla adresów IP wartość kodowa (AFI) wynosi 2.
Pole zerowe (2) W RIPv1 pole to powinno być wyzerowane. W RIPv2 służy jako znacznik trasy (route tag), wykorzystywany do odróżniania źródeł poszczególnych wpisów w tablicy tras.
Adres sieciowy Pole to zawiera adres IP sieci. Jeżeli pakiet jest zapytaniem, wpis zawiera adres źródłowy, natomiast w odpowiedzi – adres sieci, której dotyczy wpis w tablicy tras.
Pole zerowe (3) W wersji pierwszej protokołu RIP musi być ustawione na zero. W wersji drugiej zawiera maskę podsieci odpowiadającą adresowi sieciowemu z wcześniejszego pola.
Pole zerowe (4) W RIPv1 nie jest używane i musi być puste. W RIPv2 to pole zawiera adres IP następnego routera, przez którego powinna zostać przesłana informacja – dotyczy to tylko wiadomości typu odpowiedź.
Metryka Pole to określa koszt danej trasy – logiczną odległość do sieci docelowej. Najczęściej metryką jest liczba przeskoków, czyli liczba routerów pośredniczących między źródłem a celem; każdy przeskok ma zazwyczaj wartość równą 1.
RIPv2
Z powodu licznych ograniczeń pierwotnej specyfikacji protokołu RIP, w 1993 roku opracowano jego udoskonaloną wersję – RIP w wersji 2 (RIPv2), która została oficjalnie opublikowana w 1994 roku, a w 1998 roku uzyskała status standardu internetowego numer 56. RIPv2 wprowadził możliwość przesyłania informacji o maskach podsieci, dzięki czemu zaczął wspierać tzw. routowanie bezklasowe (CIDR – Classless Inter-Domain Routing), umożliwiające tworzenie podsieci o różnej długości.
Dla zapewnienia zgodności wstecznej z wersją pierwszą, w RIPv2 utrzymano limit 15 przeskoków jako maksymalną wartość metryki – powyżej tej wartości sieć uznawana jest za nieosiągalną. RIPv2 może współpracować z routerami korzystającymi z RIPv1, o ile w komunikatach RIPv1 poprawnie ustawione są wszystkie pola protokołu, które muszą być wyzerowane. Dodatkowo, protokół wyposażono w tzw. przełącznik zgodności (compatibility switch), który umożliwia precyzyjne dostosowanie sposobu współdziałania z różnymi wersjami.
Aby ograniczyć niepotrzebne obciążenie urządzeń końcowych, które nie biorą udziału w routingu, RIPv2 nie używa rozgłoszeń (broadcast) do wysyłania swojej tablicy tras, jak miało to miejsce w RIPv1. Zamiast tego wykorzystuje adres multicast 224.0.0.9, dzięki czemu tylko sąsiednie routery zainteresowane odbiorem informacji o trasach przetwarzają te komunikaty. Wciąż jednak możliwe jest stosowanie adresowania unicast dla specyficznych zastosowań.
W roku 1997 do protokołu RIP wprowadzono mechanizmy uwierzytelniania, w tym uwierzytelnianie z wykorzystaniem algorytmu MD5, co znacząco zwiększyło bezpieczeństwo wymiany informacji między routerami.
RIPv2 wprowadził również tzw. znaczniki trasy (route tags), które pozwalają na rozróżnienie tras uczonych za pośrednictwem protokołu RIP od tych, które pochodzą z innych źródeł (np. z zewnętrznych protokołów routingu), co umożliwia lepsze zarządzanie polityką routingu w bardziej złożonych środowiskach sieciowych.
RIPng
RIPng (ang. RIP next generation) to rozszerzenie protokołu RIPv2, opracowane z myślą o obsłudze sieci opartych na protokole IPv6 – nowej generacji protokołu internetowego. RIPng został zaprojektowany tak, aby dostosować funkcjonalność klasycznego RIP do specyfiki adresacji i architektury IPv6.
Najważniejszą różnicą w stosunku do RIPv2 jest pełna zgodność z IPv6. W odróżnieniu od RIPv2, który obsługuje uwierzytelnianie aktualizacji tras (np. poprzez MD5), RIPng nie oferuje natywnego mechanizmu uwierzytelniania. W czasie jego projektowania założono bowiem, że bezpieczeństwo i uwierzytelnianie w sieciach IPv6 będą realizowane przy użyciu IPsec.
W zakresie struktury komunikatów istnieje istotna różnica: w RIPv2 adres następnego przeskoku (next-hop) może być zawarty w każdym wpisie tablicy routingu, natomiast w RIPng adres następnego przeskoku kodowany jest oddzielnie i dotyczy całej grupy wpisów, a nie pojedynczych tras.
Aktualizacje w RIPng przesyłane są za pomocą protokołu UDP na porcie 521, przy użyciu specjalnej grupy multicast przypisanej dla IPv6 – ff02::9 – co pozwala na efektywne rozsyłanie informacji tylko do zainteresowanych routerów w lokalnym segmencie sieci.