Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | 4. Zastosowania |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | sobota, 14 lutego 2026, 13:16 |
Opis
Aplikacje i usługi sieciowe stanowią podstawowy komponent współczesnych systemów informatycznych, umożliwiając komunikację i wymianę danych w rozproszonym środowisku. W centrum ich działania znajdują się protokoły aplikacyjne, takie jak HTTP, SMTP, FTP czy DNS, które definiują zasady interakcji między klientami a serwerami. Większość współczesnych aplikacji opiera się na modelu klient-serwer, zapewniając skalowalność, modularność i łatwość zarządzania. Coraz większe znaczenie zyskuje bezpieczeństwo — zarówno na poziomie transmisji danych, jak i autoryzacji dostępu — co jest kluczowe w kontekście cyberzagrożeń. Równolegle rozwijają się zdecentralizowane modele, jak sieci P2P, oferujące alternatywne podejście do współdzielenia zasobów. Istotnym trendem jest także rosnąca rola chmur obliczeniowych, które umożliwiają elastyczne, skalowalne i zdalne świadczenie usług sieciowych na żądanie, przy zachowaniu wysokiej dostępności i niezawodności.
1. Aplikacje i Usługi Sieciowe
Aplikacje i usługi sieciowe stanowią podstawowy komponent współczesnych systemów informatycznych, umożliwiając komunikację i wymianę danych w rozproszonym środowisku. W centrum ich działania znajdują się protokoły aplikacyjne, takie jak HTTP, SMTP, FTP czy DNS, które definiują zasady interakcji między klientami a serwerami. Większość współczesnych aplikacji opiera się na modelu klient-serwer, zapewniając skalowalność, modularność i łatwość zarządzania. Coraz większe znaczenie zyskuje bezpieczeństwo — zarówno na poziomie transmisji danych, jak i autoryzacji dostępu — co jest kluczowe w kontekście cyberzagrożeń. Równolegle rozwijają się zdecentralizowane modele, jak sieci P2P, oferujące alternatywne podejście do współdzielenia zasobów. Istotnym trendem jest także rosnąca rola chmur obliczeniowych, które umożliwiają elastyczne, skalowalne i zdalne świadczenie usług sieciowych na żądanie, przy zachowaniu wysokiej dostępności i niezawodności.
1.1. Protokoły aplikacyjne: HTTP, SMTP, FTP, DNS
Protokoły aplikacyjne stanowią najwyższą warstwę w modelu TCP/IP, zwaną warstwą aplikacji. To właśnie one odpowiadają za bezpośrednie wsparcie komunikacji pomiędzy aplikacjami użytkownika i usługami w sieci. Protokoły te definiują sposób, w jaki klient i serwer wymieniają dane, interpretują je, obsługują błędy i organizują sesje. Najczęściej używane protokoły tej warstwy to HTTP, SMTP, FTP i DNS, z których każdy pełni unikalną rolę w funkcjonowaniu Internetu. W odróżnieniu od niższych warstw, które zajmują się transmisją bitów, ramek lub segmentów, warstwa aplikacji jest najbliżej użytkownika – to dzięki niej możliwe jest przeglądanie stron internetowych, wysyłanie poczty elektronicznej, pobieranie plików czy rozwiązywanie nazw domen.
HTTP, czyli Hypertext Transfer Protocol, jest podstawowym protokołem używanym w sieci WWW. Klientem w tej komunikacji jest przeglądarka internetowa, a serwerem – serwer HTTP, najczęściej obsługiwany przez oprogramowanie takie jak Apache, Nginx lub Microsoft IIS. HTTP działa zgodnie z modelem zapytanie-odpowiedź. Klient wysyła żądanie (request), zawierające metodę (np. GET, POST, PUT, DELETE), ścieżkę zasobu, nagłówki oraz ewentualnie dane. Serwer przetwarza to żądanie i zwraca odpowiedź (response), składającą się z kodu statusu (np. 200 OK, 404 Not Found), nagłówków i treści.
HTTP działa domyślnie na porcie 80, jednak coraz częściej wykorzystuje się jego bezpieczną wersję – HTTPS – która korzysta z protokołu TLS i działa na porcie 443. Przejście do HTTPS oznacza, że transmisja danych pomiędzy klientem a serwerem jest szyfrowana i zabezpieczona przed podsłuchem oraz modyfikacją. HTTP jest protokołem bezstanowym, co oznacza, że każde zapytanie jest niezależne – nie ma automatycznego mechanizmu śledzenia sesji. Do implementacji sesji używa się ciasteczek (cookies), identyfikatorów sesji oraz tokenów autoryzacyjnych.

Kolejnym fundamentalnym protokołem aplikacyjnym jest SMTP (Simple Mail Transfer Protocol), który obsługuje przesyłanie poczty elektronicznej pomiędzy serwerami pocztowymi. SMTP działa na zasadzie komunikacji pomiędzy nadawcą a serwerem odbiorczym, z zastosowaniem komend tekstowych, takich jak HELO, MAIL FROM, RCPT TO, DATA i QUIT. SMTP używa portu 25 (dla połączeń nieszyfrowanych), 465 (dla SSL) i 587 (dla TLS). Protokół ten odpowiada wyłącznie za wysyłkę wiadomości – za ich odbieranie odpowiadają inne protokoły, takie jak POP3 lub IMAP.
Podczas sesji SMTP klient (serwer nadawczy lub program użytkownika) nawiązuje połączenie z serwerem SMTP i przesyła komendy w ściśle określonej kolejności. Po komendzie HELO następuje prezentacja klienta, następnie określenie nadawcy i odbiorców wiadomości. Komenda DATA wprowadza treść wiadomości, zakończoną sekwencją.

SMTP nie oferuje mechanizmu szyfrowania treści ani przesyłania załączników binarnych w swojej pierwotnej formie. Współczesne implementacje wykorzystują rozszerzenia protokołu, takie jak STARTTLS oraz MIME, aby umożliwić szyfrowanie i kodowanie multimediów. SMTP jest także wykorzystywany w walce ze spamem – stosuje się uwierzytelnianie nadawców (SPF, DKIM, DMARC) i techniki greylistingu.
FTP, czyli File Transfer Protocol, to jeden z najstarszych protokołów internetowych, zaprojektowany do przesyłania plików pomiędzy klientem a serwerem. FTP działa w modelu klient-serwer i wykorzystuje dwa oddzielne połączenia: jedno do sterowania (control connection) i drugie do przesyłania danych (data connection). Połączenie kontrolne jest utrzymywane na porcie 21, a port danych może być ustalany dynamicznie (aktywny tryb) lub ustalany przez klienta (pasywny tryb).
W trybie aktywnym klient nasłuchuje na wybranym porcie i informuje o tym serwer, który inicjuje połączenie zwrotne. W trybie pasywnym serwer udostępnia port, do którego klient się podłącza – ten tryb jest preferowany za firewallem lub NAT. Sesja FTP rozpoczyna się od komendy USER i PASS, po których klient uzyskuje dostęp do systemu plików serwera. Komendy takie jak LIST, GET (RETR), PUT (STOR), MKDIR i DELETE umożliwiają zarządzanie zasobami.

FTP nie zapewnia szyfrowania danych ani uwierzytelniania w swojej bazowej wersji. Aby zwiększyć bezpieczeństwo, stosuje się FTPS (FTP over SSL) lub całkowicie odrębny protokół SFTP (SSH File Transfer Protocol), który nie ma nic wspólnego z FTP i działa w ramach SSH.
Ostatnim z omawianych protokołów aplikacyjnych jest DNS (Domain Name System), który pełni funkcję systemu nazw dla zasobów sieciowych. Jego głównym zadaniem jest tłumaczenie symbolicznych nazw domenowych (np. www.roszczyk.net) na adresy IP (np. 192.0.2.1), które są używane przez protokoły niższych warstw do nawiązywania połączeń. DNS działa w modelu rozproszonym, opartym o hierarchię serwerów: root, TLD (Top-Level Domain), oraz serwery autorytatywne dla konkretnych domen.
Klient, zwany resolverem, wysyła zapytanie do serwera DNS (zwykle przez UDP na porcie 53), a ten odpowiada zgodnie ze swoją wiedzą lub przekazuje zapytanie dalej w hierarchii. Wyróżnia się zapytania rekurencyjne, w których serwer wykonuje całą ścieżkę zapytań aż do uzyskania odpowiedzi, oraz iteracyjne, w których klient sam kieruje kolejne zapytania na podstawie uzyskanych wskazówek.

DNS umożliwia także inne typy rekordów, takie jak MX (Mail Exchange – obsługa poczty), CNAME (aliasy), TXT (np. dla SPF) czy SRV (usługi). System ten odgrywa kluczową rolę w działaniu Internetu, dlatego podlega także wielu atakom, takim jak DNS spoofing, cache poisoning, czy DDoS. Aby zwiększyć jego odporność, rozwinięto zabezpieczenia jak DNSSEC (Domain Name System Security Extensions), które podpisują kryptograficznie rekordy i zapewniają ich integralność oraz autentyczność.
DNS, HTTP, FTP i SMTP to fundamentalne protokoły, bez których sieć w znanej formie nie mogłaby funkcjonować. Każdy z nich operuje na własnym porcie, implementuje odmienne zasady sesji, kodowania i transportu danych, i spełnia konkretne potrzeby komunikacyjne w sieci. Ich zrozumienie pozwala analizować ruch sieciowy, projektować aplikacje internetowe oraz diagnozować problemy z dostępnością usług. W praktyce, wiele narzędzi sieciowych – od snifferów i firewalli po serwery aplikacyjne – bazuje na precyzyjnej interpretacji nagłówków i zachowań tych protokołów.
1.2. Architektura klient-serwer
Architektura klient-serwer jest podstawowym paradygmatem organizacji usług i komunikacji w nowoczesnych sieciach komputerowych. Jej podstawową ideą jest rozdzielenie funkcjonalności na dwie współpracujące jednostki: klienta, który inicjuje żądania i odbiera odpowiedzi, oraz serwera, który przetwarza te żądania i zwraca wyniki. Takie podejście pozwala na scentralizowaną kontrolę, lepsze zarządzanie zasobami, standaryzację interfejsów oraz skalowalność, która jest niezbędna w środowiskach o dużej liczbie użytkowników i operacji. Model klient-serwer leży u podstaw działania niemal wszystkich usług sieciowych: od WWW, przez pocztę elektroniczną, po bazy danych i aplikacje korporacyjne.
Rola klienta i serwera w tej architekturze jest jasno określona. Klient to oprogramowanie lub urządzenie końcowe użytkownika, które wysyła żądania do serwera w celu uzyskania konkretnej usługi lub zasobu. Może to być przeglądarka internetowa ładująca stronę WWW, program pocztowy wysyłający wiadomość, terminal logujący się do zdalnego systemu, aplikacja mobilna komunikująca się z interfejsem API. Klient nie musi przechowywać danych ani wykonywać złożonych operacji – jego główną funkcją jest inicjowanie i odbieranie danych. Serwer natomiast jest aplikacją nasłuchującą na konkretnym porcie i oczekującą na żądania od klientów. Może działać na dedykowanym sprzęcie lub jako instancja w chmurze. Serwer jest odpowiedzialny za przetwarzanie żądań, dostęp do danych, autoryzację, logikę biznesową, a czasem również generowanie wyników lub ich formatowanie.

Model klient-serwer zakłada, że połączenia są asymetryczne – klient aktywnie inicjuje komunikację, natomiast serwer pasywnie nasłuchuje. Działa to dobrze w środowiskach, gdzie dostępność i centralizacja usług mają znaczenie – przykładem może być bankowość elektroniczna, sklepy internetowe, systemy rejestracji pacjentów czy zarządzanie zasobami uczelni. Główne zalety tej architektury to centralizacja danych i kontroli, łatwa aktualizacja i konserwacja serwera, lepsza ochrona informacji (dane pozostają po stronie serwera), możliwość wdrożenia silnego uwierzytelniania oraz rejestrowania aktywności. Wady to potencjalna pojedyncza punkt awarii (Single Point of Failure), ograniczenia przepustowości serwera i problemy ze skalowalnością przy dużym natężeniu żądań.
Architektura klient-serwer może być jedno-, dwu- lub wielowarstwowa. W modelu jednowarstwowym klient i serwer działają na tym samym urządzeniu, co nie jest już popularne. Model dwuwarstwowy to klasyczny przykład – klient przesyła żądanie, serwer odpowiada. W architekturze trójwarstwowej pojawia się dodatkowa warstwa pośrednia – serwer aplikacji lub serwer logiki biznesowej, który pośredniczy pomiędzy klientem a serwerem danych. To pozwala lepiej rozdzielić odpowiedzialności, zwiększyć skalowalność i bezpieczeństwo. Czwarta warstwa może obejmować np. usługi chmurowe, replikację danych, load balancery czy systemy cache'ujące.

W komunikacji klient-serwer wykorzystywane są różne protokoły warstwy aplikacji, zależnie od funkcji. Dla WWW jest to HTTP/HTTPS, dla poczty – SMTP, POP3, IMAP, dla zdalnego dostępu – SSH, dla transferu plików – FTP, dla baz danych – SQL przez TCP. Protokoły te mają charakter tekstowy lub binarny, synchroniczny lub asynchroniczny. Klient wysyła komunikaty w formie zgodnej ze specyfikacją protokołu, serwer je analizuje i zwraca odpowiedź, również zgodnie z protokołem. Klient może również oczekiwać kodu statusu, który wskaże, czy operacja się powiodła, oraz danych wyjściowych.
Model klient-serwer może być również stanowy lub bezstanowy. HTTP w wersji pierwotnej był protokołem bezstanowym – każde żądanie było niezależne, serwer nie „pamiętał” wcześniejszych interakcji. Dla zapewnienia sesji konieczne było dodanie mechanizmów takich jak ciasteczka, tokeny lub sesje serwerowe. W modelu stanowym serwer utrzymuje informacje o kliencie pomiędzy żądaniami – np. zalogowany użytkownik, koszyk w sklepie, postęp formularza. To umożliwia tworzenie złożonych interfejsów użytkownika, ale wymaga zarządzania pamięcią i skalowaniem.
Architektura klient-serwer opiera się na idei rozdziału odpowiedzialności: klient jest odpowiedzialny za interakcję z użytkownikiem i prezentację, a serwer – za przetwarzanie i przechowywanie. W systemach rozproszonych takie podejście umożliwia rozdzielenie komponentów aplikacji i ich uruchamianie na różnych maszynach. Przykład może stanowić aplikacja mobilna, która jako klient korzysta z interfejsu REST API serwera backendowego, który łączy się z bazą danych w chmurze. Klient może działać offline, zbierać dane, synchronizować się przy połączeniu.
Innym przykładem są aplikacje webowe typu SPA (Single Page Application), w których klient w przeglądarce (HTML+JavaScript) komunikuje się z serwerem za pomocą żądań AJAX/REST, a logika renderowania i interfejsu jest po stronie klienta. Serwer udostępnia dane, autoryzuje dostęp, obsługuje zapytania i przechowuje historię. Taki model prowadzi do częściowego rozmycia granicy między klientem a serwerem – klient staje się „inteligentny” (thick client), a serwer uproszczony (thin server). Przeciwieństwem są tzw. dumb clients, które jedynie wyświetlają wynik.
Model klient-serwer ewoluował w kierunku mikrousług, gdzie każdy serwis jest serwerem wobec innych komponentów i klientem wobec bazy danych czy usług trzecich. Serwisy komunikują się często poprzez REST lub gRPC, korzystają z brokerów komunikatów (RabbitMQ, Kafka), a logika systemu oparta jest na kontraktach i API. W takim układzie relacja klient-serwer może być dynamiczna i wielokierunkowa – serwer jednej usługi jest klientem kolejnej.

Kwestie synchronizacji, kolejkowania, buforowania i niezawodności mają ogromne znaczenie w architekturze klient-serwer. Klient może implementować retry, timeouty, asynchroniczne kolejki, a serwer – mechanizmy rozpraszania obciążenia (load balancing), replikację, mechanizmy failover i monitoring. Gdy klient nie otrzyma odpowiedzi, może uznać usługę za niedostępną i próbować później. Serwery często mają zdefiniowaną politykę przyjmowania połączeń – liczba jednoczesnych sesji, limity żądań, ochrona przed DDoS, throttling, cache’owanie odpowiedzi.
Architektura klient-serwer znajduje zastosowanie zarówno w prototypach, jak i dużych systemach korporacyjnych. Klientem może być lekka aplikacja IoT, a serwerem system SCADA. Klientem może być frontend Angulara, a serwerem Pythonowy FastAPI. W systemach ERP klient korzysta z interfejsu terminalowego lub przeglądarkowego, a serwer odpowiada za obliczenia finansowe, generowanie dokumentów, komunikację z drukarką i przesyłanie danych do banku. W edukacji serwerami są platformy e-learningowe jak Moodle, klientami przeglądarki uczniów, API mobilne, a także integracje z katalogami LDAP.
Z perspektywy bezpieczeństwa architektura klient-serwer wymaga rozważnego planowania: klient nie powinien mieć bezpośredniego dostępu do zasobów serwera, dane powinny być przesyłane z użyciem TLS, autoryzacja i uwierzytelnianie muszą być realizowane przez tokeny sesyjne, JWT lub OAuth2. Serwery muszą walidować dane wejściowe, logować zdarzenia, zapewniać kontrolę dostępu. Dodatkowo stosuje się reverse proxy, Web Application Firewall (WAF), mechanizmy rate limiting i sandboxing środowiska wykonywania kodu.
Z technicznego punktu widzenia klient-serwer to także model implementacyjny: aplikacje są rozwijane jako pary: frontend + backend, często w różnych technologiach. Klient w React, Vue, Flutter komunikuje się z backendem w Django, ASP.NET, Spring. Warstwa komunikacji oparta jest na JSON, XML, Protobuf. Interfejsy są dokumentowane przy pomocy OpenAPI lub GraphQL, testowane, wersjonowane. Klient może być sprzętowy (czytnik RFID), mobilny (tablet), desktopowy (aplikacja C#) lub webowy (HTML5).
Zasadniczą cechą tej architektury jest możliwość odizolowania aktualizacji, rozwijania i testowania klienta i serwera niezależnie. Backend może przejść refaktoryzację, migrację do innej bazy danych lub konteneryzację bez konieczności modyfikowania frontendu, o ile interfejs API pozostaje stabilny. Klient może z kolei oferować nowe funkcje, przejść na nową bibliotekę UI, zmienić wygląd i zachowanie, bez naruszania działania backendu. Ten podział obowiązków pozwala zespołom pracować równolegle, stosować DevOps i CI/CD.
1.3. Bezpieczeństwo w aplikacjach sieciowych
Bezpieczeństwo w aplikacjach sieciowych jest jednym z najważniejszych aspektów współczesnych systemów informatycznych. Wraz z rozwojem Internetu, rosnącą liczbą użytkowników, złożonością systemów i integracją rozproszonych usług, zagrożenia związane z bezpieczeństwem stają się coraz bardziej istotne. Aplikacje sieciowe – czyli takie, które komunikują się za pośrednictwem sieci, niezależnie od tego, czy są to systemy bankowe, portale społecznościowe, sklepy internetowe, interfejsy API czy aplikacje mobilne – narażone są na cały wachlarz ataków, manipulacji i nadużyć. Bezpieczeństwo tych aplikacji nie jest już jedynie technicznym aspektem implementacji, ale częścią całego procesu projektowania, testowania, wdrażania i utrzymania oprogramowania.
Podstawowym celem bezpieczeństwa aplikacji sieciowych jest ochrona poufności, integralności i dostępności danych. Poufność oznacza, że informacje są dostępne tylko dla uprawnionych użytkowników. Integralność – że dane nie zostały nieautoryzowanie zmodyfikowane. Dostępność – że system pozostaje aktywny i gotowy do działania w każdej chwili. Aby osiągnąć te cele, aplikacje muszą wdrażać różnorodne mechanizmy zabezpieczeń – od warstwy transportowej i uwierzytelniania, przez kontrolę dostępu, po zabezpieczenia przed konkretnymi atakami sieciowymi i aplikacyjnymi. Współczesna aplikacja sieciowa nie jest systemem zamkniętym – komunikuje się z innymi usługami, korzysta z zewnętrznych API, przechowuje dane w chmurze, a interfejs użytkownika działa w środowisku niekontrolowanym (np. w przeglądarce). To oznacza, że zagrożenia mogą pojawić się w każdym miejscu łańcucha komunikacyjnego.
Jednym z podstawowych aspektów bezpieczeństwa aplikacji sieciowych jest stosowanie szyfrowania transmisji danych. Każda aplikacja, która przesyła dane przez Internet, powinna wykorzystywać HTTPS zamiast HTTP. HTTPS to HTTP nad protokołem TLS (Transport Layer Security), który zapewnia szyfrowanie danych pomiędzy klientem a serwerem. Dzięki temu żaden podmiot pośredniczący – router, punkt dostępowy, proxy – nie jest w stanie odczytać zawartości pakietów. TLS zabezpiecza również integralność transmisji (czyli wykrywa modyfikacje danych) oraz uwierzytelnia serwer (certyfikaty SSL/TLS wystawione przez zaufane urzędy certyfikacji).

Poza szyfrowaniem transmisji, aplikacja musi zapewnić silne mechanizmy uwierzytelniania użytkowników i usług. Uwierzytelnianie to proces weryfikacji tożsamości. Może być realizowane w postaci loginu i hasła, certyfikatu klienta, tokenu sesji, kodu SMS lub klucza sprzętowego. W aplikacjach webowych powszechnie stosuje się sesje z identyfikatorem zapisywanym w ciasteczku HTTP-Only oraz tokeny typu JWT (JSON Web Token), które przechowywane są w pamięci lokalnej lub przesyłane w nagłówkach. JWT zawiera zakodowane informacje o użytkowniku i jego uprawnieniach oraz podpis cyfrowy serwera, który gwarantuje autentyczność tokena.
Autoryzacja to odrębny proces – oznacza przyznanie lub odmowę dostępu do konkretnego zasobu po potwierdzeniu tożsamości. Może być realizowana przez sprawdzenie ról użytkownika, przynależności do grupy, poziomu dostępu, flagi właściciela lub mechanizmów typu ACL (Access Control List). Dobre praktyki wymagają rozdzielenia uwierzytelniania od autoryzacji, tak by jedna warstwa nie polegała wyłącznie na drugiej. Szczególnie ważne jest unikanie sytuacji, w których np. użytkownik po prostu odwołuje się do zasobu przez adres URL, który nie został do niego przypisany.
Wiele ataków na aplikacje sieciowe wynika z błędów w implementacji mechanizmów uwierzytelniania i autoryzacji. Przykładowo: brak sprawdzania tożsamości w zapytaniach typu GET/POST, przewidywalne identyfikatory sesji, brak ochrony przed powtórnym wykorzystaniem tokena, brak ograniczeń prób logowania (brute force). Istotne jest również stosowanie ochrony przed atakami typu CSRF (Cross-Site Request Forgery), które polegają na wymuszeniu przez złośliwy serwis wykonania działania na autoryzowanym koncie użytkownika bez jego wiedzy.

Innym kluczowym zagadnieniem bezpieczeństwa aplikacji sieciowych jest ochrona przed atakami typu Injection – wstrzykiwanie kodu. Najpopularniejszy przykład to SQL Injection, w którym atakujący wprowadza dane wejściowe zawierające fragmenty poleceń SQL, które nie są poprawnie oczyszczane i są bezpośrednio wstawiane do zapytania. Skutkiem może być uzyskanie dostępu do bazy danych, odczyt danych innych użytkowników, modyfikacja zawartości, a w skrajnych przypadkach nawet eskalacja uprawnień.

Tego typu ataki są możliwe, gdy dane użytkownika są łączone ze stałymi ciągami znaków bez sanitizacji. Ochroną przed injection jest stosowanie tzw. zapytań parametryzowanych (prepared statements), które oddzielają logikę zapytania od danych wejściowych. W nowoczesnych bibliotekach ORM (Object-Relational Mapping) takie zabezpieczenia są domyślnie wbudowane, ale mogą być obchodzone przy niestandardowych manipulacjach ciągami zapytań.
Aplikacje sieciowe muszą być również odporne na ataki typu XSS (Cross-Site Scripting), które polegają na wstrzyknięciu złośliwego kodu JavaScript do aplikacji, który następnie jest uruchamiany w przeglądarce innych użytkowników. Kod ten może np. przechwytywać ciasteczka, modyfikować zawartość strony lub przekierowywać na złośliwe adresy. XSS dzieli się na trzy główne typy: reflected (kod zwracany natychmiast), stored (kod zapisany w bazie danych i serwowany innym użytkownikom) oraz DOM-based (manipulacje wewnątrz kodu JavaScript w przeglądarce).
Ochrona przed XSS polega na kodowaniu wszystkich danych wprowadzanych przez użytkownika przy wyświetlaniu ich na stronie. W przypadku HTML – zamiana znaków < i > na < i >, w przypadku JavaScript – stosowanie odpowiednich konstrukcji literalnych, w przypadku URL – kodowanie procentowe. Dodatkowo stosuje się nagłówki bezpieczeństwa (np. Content-Security-Policy), które ograniczają możliwość uruchamiania nieautoryzowanego kodu.
Zabezpieczenia aplikacji muszą też obejmować ochronę przed utratą dostępności, szczególnie w kontekście ataków DDoS (Distributed Denial of Service), które polegają na wysyłaniu olbrzymiej liczby żądań w krótkim czasie, co prowadzi do zablokowania lub spowolnienia usługi. Ochrona obejmuje filtrowanie ruchu, użycie WAF (Web Application Firewall), mechanizmy rate limiting, captche, a także usługi chmurowe do filtrowania ruchu na poziomie warstwy 3 i 4.
Kolejnym zagadnieniem bezpieczeństwa jest przechowywanie danych – szczególnie haseł i informacji osobowych. Hasła nigdy nie powinny być przechowywane w postaci jawnej, nawet zaszyfrowanej. Standardem jest stosowanie silnych, jednokierunkowych funkcji skrótu (np. bcrypt, Argon2), które utrudniają odtworzenie hasła z jego odcisku. Bazy danych powinny być również szyfrowane, dostęp do nich powinien być ograniczony przez kontrolę dostępu, a system powinien rejestrować próby nieautoryzowanego dostępu.
Współczesne aplikacje sieciowe często korzystają z autoryzacji opartej na tokenach OAuth2 i OpenID Connect, które umożliwiają bezpieczne logowanie przez zewnętrzne systemy (np. Google, Facebook, Azure AD). Protokół OAuth2 umożliwia przekazywanie uprawnień między systemami bez udostępniania haseł, przez użycie tymczasowych tokenów dostępu i tokenów odświeżania. Stosowanie tych rozwiązań wymaga jednak dokładnej implementacji, w tym ochrony tokenów przed kradzieżą (TLS, httpOnly cookies), ograniczania ich zakresu i czasu życia.

Ważnym elementem bezpieczeństwa aplikacji sieciowych jest regularne testowanie – zarówno manualne, jak i automatyczne. Stosuje się testy penetracyjne, audyty kodu, skanery podatności (np. OWASP ZAP, Burp Suite), systemy SAST/DAST, oraz analizę logów. Standardy takie jak OWASP Top 10 definiują najczęstsze i najbardziej niebezpieczne podatności występujące w aplikacjach webowych. Należy do nich m.in. nieautoryzowany dostęp, nieprawidłowa konfiguracja zabezpieczeń, nadużycie zasobów, brak walidacji wejścia, podatności na komponenty open-source. Zespół projektowy powinien znać te klasy i umieć im przeciwdziałać.
Ostatnią warstwą bezpieczeństwa jest użytkownik i jego interakcja z aplikacją. Projektując interfejsy należy unikać niejasnych komunikatów, stosować jednoznaczne ostrzeżenia, zabezpieczać formularze, zapewniać informację o czasie trwania sesji i umożliwiać jej zakończenie. Aplikacja powinna też informować o nieudanych próbach logowania, wymuszać silne hasła, oferować dwuskładnikowe uwierzytelnianie i umożliwiać sprawdzenie historii logowań.
1.4. Sieci P2P
Sieci peer-to-peer (P2P) stanowią alternatywę wobec tradycyjnego modelu klient-serwer, który dominuje w większości zastosowań sieciowych. W modelu P2P każdy węzeł sieci działa jednocześnie jako klient i serwer, co oznacza, że uczestnik sieci może zarówno pobierać dane, jak i je udostępniać. Brak centralizacji i hierarchicznej struktury sprawia, że sieci P2P cechują się wyjątkową odpornością na awarie, dobrą skalowalnością i wysoką efektywnością w rozproszonej wymianie zasobów. Ich działanie opiera się na kooperacji pomiędzy równorzędnymi uczestnikami, z których każdy ma potencjalnie równy dostęp do wspólnych zasobów i odpowiedzialność za ich przechowywanie i rozpowszechnianie.

W odróżnieniu od architektury klient-serwer, w której serwer centralny odpowiada za przechowywanie i dostarczanie danych wszystkim klientom, w modelu P2P dane są rozproszone pomiędzy uczestników sieci. Każdy peer może zawierać fragmenty danych, które są wymieniane z innymi węzłami bez potrzeby angażowania centralnego serwera. W związku z tym sieci P2P lepiej znoszą przeciążenia i ataki DDoS, ponieważ nie istnieje pojedynczy punkt awarii, którego wyeliminowanie mogłoby sparaliżować system.
Pierwsze powszechnie znane implementacje sieci P2P pojawiły się pod koniec lat 90. Jedną z najsłynniejszych była sieć Napster, służąca do dzielenia się plikami muzycznymi. Napster był modelem hybrydowym – centralny serwer indeksował lokalizacje plików, ale same dane przesyłane były bezpośrednio pomiędzy użytkownikami. W późniejszych latach powstały bardziej zdecentralizowane systemy, takie jak Gnutella, eDonkey czy BitTorrent, które z czasem ewoluowały w kierunku pełnej decentralizacji. W sieciach takich każdy peer sam przechowuje i rozpowszechnia dane, a mechanizmy odkrywania zasobów i trasowania zapytań są wbudowane w samą sieć.
W BitTorrent, który jest jednym z najbardziej zaawansowanych protokołów P2P, dane są dzielone na małe fragmenty, które są pobierane i jednocześnie udostępniane innym użytkownikom. Oznacza to, że im więcej osób pobiera dany plik, tym szybciej działa cała sieć, ponieważ rośnie liczba dostępnych źródeł. Mechanizm ten działa dzięki konstrukcji zwanej swarm (rój), w której wszyscy uczestnicy danego transferu wymieniają się fragmentami danych.
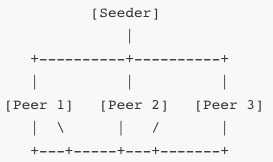
W powyższym schemacie każdy peer wymienia się fragmentami z innymi peerami. Seeder to peer, który posiada cały plik i udostępnia go innym. Klient rozpoczynający pobieranie staje się najpierw leecherem, a następnie – gdy pobierze część pliku – także udostępnia go innym. Gdy pobierze całość, staje się seederem.
Dzięki mechanizmowi równego udziału użytkowników w wymianie danych, sieci P2P są naturalnie odporne na skalowanie – im więcej użytkowników uczestniczy, tym większa przepustowość całego systemu. Ograniczeniem może być jednak dostępność rzadkich fragmentów plików. W tym celu stosuje się algorytmy optymalizujące rozprowadzanie danych, takie jak „rarest first”, który preferuje pobieranie najrzadszych fragmentów, aby zapewnić ich rozprzestrzenianie się w roju.
W kontekście komunikacji pomiędzy peerami, istotne są dwie koncepcje: routowanie i odkrywanie zasobów. W sieciach niezcentralizowanych nie istnieje centralny katalog plików ani węzeł indeksujący. Dlatego każdy peer musi samodzielnie znaleźć inne węzły posiadające interesujące go dane. W sieciach typu Gnutella wykorzystywano rozgłoszeniowe zapytania (flooding), które rozsyłały żądania po całej sieci. To jednak generowało duży ruch i było nieefektywne. W nowszych rozwiązaniach stosuje się struktury logiczne takie jak DHT (Distributed Hash Table), które umożliwiają zlokalizowanie zasobu na podstawie jego identyfikatora.

Każdy peer odpowiada za pewien zakres identyfikatorów i przechowuje informacje o zasobach znajdujących się w tym zakresie. Zapytanie o zasób kierowane jest do odpowiedniego peera poprzez system trasowania, który przypomina drzewo binarne lub sieć kółek, w zależności od implementacji. Takie rozwiązania są stosowane np. w protokole Kademlia i uTorrent.
W sieciach P2P istotnym problemem jest zarządzanie reputacją i wiarygodnością peerów. Ponieważ każdy peer może pełnić funkcję zarówno źródła danych, jak i ich odbiorcy, sieci te są podatne na ataki typu poisoning (rozpowszechnianie fałszywych danych), freeloading (brak współdzielenia plików) czy sybiling (podszywanie się pod wielu użytkowników). Aby przeciwdziałać tym zjawiskom, wprowadza się systemy reputacji, limity współdzielenia, protokoły weryfikacji danych (hashowanie SHA-1 lub SHA-256), oraz mechanizmy szyfrowania komunikacji pomiędzy peerami.
Sieci P2P znajdują zastosowanie nie tylko w udostępnianiu plików, ale również w wielu innych obszarach. Przykładem może być technologia blockchain, która działa w pełni w modelu P2P. W tej technologii każdy węzeł sieci posiada kopię rozproszonej księgi, do której są dopisywane nowe transakcje. Brak centralnego serwera i konsensus pomiędzy węzłami (np. przez Proof-of-Work lub Proof-of-Stake) sprawia, że sieć jest odporna na modyfikację danych i cenzurę.
Innym przykładem są komunikatory zdecentralizowane, takie jak Tox czy RetroShare, w których rozmowy są szyfrowane end-to-end, a dane przechowywane lokalnie. Aplikacje te nie opierają się na serwerze pośredniczącym i pozwalają na bezpośrednią komunikację pomiędzy użytkownikami. Podobne mechanizmy stosowane są w niektórych systemach rozproszonych gier sieciowych, aktualizacji oprogramowania czy streamingu P2P.
Jedną z form nowoczesnych sieci P2P są tzw. sieci mesh, w których urządzenia łączą się bezpośrednio ze sobą i przekazują dalej dane innym uczestnikom. Takie rozwiązania wykorzystywane są w sieciach ad-hoc, komunikacji kryzysowej, smart-city czy IoT. Przykładowo, urządzenia mogą tworzyć lokalną sieć wymiany informacji, nawet bez dostępu do Internetu.
W architekturze P2P występuje również problem NAT traversal – wielu użytkowników korzysta z sieci za NAT-em (Network Address Translation), co uniemożliwia bezpośrednie połączenia. W odpowiedzi powstały techniki takie jak STUN (Simple Traversal of UDP through NATs), TURN (Traversal Using Relays around NAT) i ICE (Interactive Connectivity Establishment), które umożliwiają zestawianie połączeń P2P nawet w środowiskach zamkniętych. Technologie te wykorzystywane są m.in. w protokole WebRTC, który umożliwia tworzenie bezpośrednich połączeń audio/wideo pomiędzy przeglądarkami.
Z perspektywy użytkownika końcowego, sieci P2P mogą działać transparentnie – użytkownik instaluje aplikację, która automatycznie odnajduje inne węzły, zarządza zasobami i optymalizuje przepływ danych. Ale z perspektywy administratora systemów lub projektanta sieci, implementacja protokołu P2P wymaga przemyślanego zarządzania pamięcią, pasmem, bezpieczeństwem i wydajnością. Wymagana jest synchronizacja danych, obsługa utraty pakietów, dynamiczne zarządzanie topologią sieci, balansowanie obciążenia i ochrona przed przeciążeniem.
Bezpieczeństwo w sieciach P2P to temat złożony. Brak centralnej kontroli sprawia, że trudniejsze jest monitorowanie aktywności, egzekwowanie zasad, przeciwdziałanie nadużyciom. Ataki typu man-in-the-middle, fałszywe źródła danych, analiza ruchu czy celowe przeciążanie wybranych peerów mogą być trudne do wykrycia i zneutralizowania. W odpowiedzi stosuje się szyfrowanie end-to-end, podpisy cyfrowe, redundancję danych, dywersyfikację źródeł, a także dynamiczne protokoły reputacyjne. W blockchainie bezpieczeństwo zapewniają funkcje skrótu i łańcuch bloków, w BitTorrent – hasze plików i algorytmy dystrybucji danych.
Projektowanie sieci P2P wymaga wiedzy z zakresu teorii grafów, teorii informacji, kryptografii i protokołów sieciowych. Algorytmy rozgłaszania, trasowania, synchronizacji i rozwiązywania konfliktów muszą być odporne na błędy, opóźnienia i działanie w niepewnym środowisku sieciowym. Sieci P2P oferują ogromny potencjał w budowie usług zdecentralizowanych, odpornych na cenzurę, awarie i przeciążenia – od systemów plików (IPFS), przez repozytoria kodu (GIT'a), aż po całe platformy aplikacyjne (Dat, Secure Scuttlebutt).
1.5. Chmura obliczeniowa
Chmura obliczeniowa to model świadczenia usług informatycznych, który umożliwia dostęp do zasobów obliczeniowych – takich jak serwery, pamięć masowa, bazy danych, sieci, oprogramowanie i inne komponenty infrastruktury – przez Internet, na żądanie i zazwyczaj w oparciu o rozliczenie za faktyczne zużycie. Koncepcja ta zrewolucjonizowała sposób, w jaki przedsiębiorstwa i indywidualni użytkownicy korzystają z technologii. Zamiast budować i utrzymywać własne centra danych, organizacje mogą wynajmować potrzebne im zasoby od dostawców usług chmurowych, dostosowując je dynamicznie do aktualnych potrzeb.
Chmura obliczeniowa opiera się na wirtualizacji zasobów fizycznych, co oznacza, że wiele maszyn wirtualnych może współdzielić jeden fizyczny serwer. Dzięki temu możliwe jest optymalne wykorzystanie infrastruktury, skalowanie usług w czasie rzeczywistym, szybkie uruchamianie nowych aplikacji oraz obniżenie kosztów związanych z utrzymaniem własnych serwerowni. Użytkownicy mają dostęp do usług chmurowych przez interfejsy programistyczne (API), panele administracyjne, linie poleceń lub portale webowe, niezależnie od fizycznej lokalizacji infrastruktury.
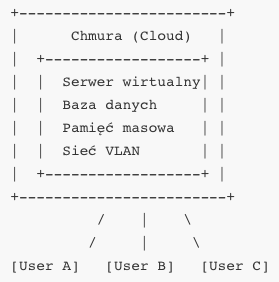
W chmurze obliczeniowej wyróżnia się kilka podstawowych modeli usługowych, które opisują poziom abstrakcji oferowany użytkownikowi. Infrastructure as a Service (IaaS) to najniższy poziom, w którym użytkownik uzyskuje dostęp do maszyn wirtualnych, wolumenów dyskowych, interfejsów sieciowych i innych zasobów infrastrukturalnych. Może samodzielnie zainstalować system operacyjny, skonfigurować środowisko i wdrożyć własne aplikacje. Przykłady usług IaaS to Amazon EC2, Microsoft Azure Virtual Machines, Google Compute Engine czy OpenStack.
Na kolejnym poziomie znajduje się Platform as a Service (PaaS), w którym użytkownik otrzymuje kompletną platformę do uruchamiania aplikacji, bez potrzeby zarządzania infrastrukturą. Usługi PaaS oferują zintegrowane środowiska programistyczne, bazy danych, systemy kolejkowania, skalowanie poziome i pionowe, zarządzanie stanem aplikacji. Programista może skupić się na kodzie i logice biznesowej, bez konieczności zajmowania się systemem operacyjnym, łatkami bezpieczeństwa czy serwerem webowym. Przykładami są Heroku, Google App Engine, Azure App Services czy Red Hat OpenShift.
Najwyższym poziomem usług są rozwiązania Software as a Service (SaaS), gdzie użytkownik korzysta z gotowych aplikacji dostępnych przez przeglądarkę lub klienta zdalnego. Nie zarządza infrastrukturą, systemem ani aktualizacjami – wszystko jest utrzymywane przez dostawcę. Przykładami SaaS są Google Workspace (Gmail, Docs, Sheets), Microsoft 365, Salesforce, Zoom czy Dropbox. Ten model pozwala na szybkie wdrażanie rozwiązań biznesowych bez inwestycji w sprzęt czy zespół IT.

Z perspektywy modelu wdrożenia chmury można wyróżnić chmurę publiczną, prywatną, hybrydową oraz multicloud. Chmura publiczna to taka, której zasoby są współdzielone przez wielu klientów i udostępniane przez zewnętrznego dostawcę – np. Amazon Web Services, Microsoft Azure, Google Cloud. Klient płaci za wykorzystanie zasobów, bez fizycznego dostępu do sprzętu. Chmura prywatna to środowisko chmurowe zbudowane dla jednej organizacji, najczęściej we własnym centrum danych lub w odizolowanej przestrzeni u dostawcy. Umożliwia pełną kontrolę, zgodność z regulacjami prawnymi, ale wiąże się z większymi kosztami wdrożenia i utrzymania.
Chmura hybrydowa to połączenie chmury prywatnej i publicznej, które pozwala na dynamiczne przenoszenie obciążeń, zwiększanie mocy obliczeniowej w okresach szczytowych, czy separację krytycznych danych od mniej wrażliwych. Multicloud to natomiast strategia polegająca na korzystaniu z usług różnych dostawców chmurowych jednocześnie – np. jednej aplikacji używa się w AWS, drugiej w Azure, trzeciej w lokalnym Kubernetesie. Umożliwia to optymalizację kosztów, zwiększenie niezawodności i unikanie uzależnienia od jednego dostawcy (vendor lock-in).
Zastosowanie chmury obliczeniowej ma ogromne znaczenie dla skalowalności i elastyczności systemów. Aplikacja może rozpocząć działanie na jednym węźle, a w miarę wzrostu ruchu – automatycznie uruchamiać kolejne instancje. Mechanizmy takie jak autoscaling, load balancing i replikacja danych pozwalają zachować wysoką dostępność i wydajność nawet w warunkach dynamicznych zmian zapotrzebowania. W przypadku awarii jednego serwera ruch może zostać przekierowany do innej lokalizacji geograficznej bez ingerencji użytkownika.
Ważną cechą chmury jest też model płatności – pay-as-you-go – w którym klient płaci tylko za faktycznie zużyte zasoby. Może to być liczba godzin działania maszyny, liczba żądań HTTP, ilość przesłanych danych, objętość przechowywanych plików. Pozwala to uniknąć inwestycji kapitałowych (CAPEX) i przejść na model operacyjny (OPEX), co jest korzystne z punktu widzenia planowania budżetu i elastyczności biznesowej. Użytkownik może w każdej chwili zmniejszyć lub zwiększyć zużycie zasobów, co jest trudne do osiągnięcia w tradycyjnych środowiskach on-premises.
Bezpieczeństwo w chmurze obliczeniowej wymaga nowych podejść i odpowiedzialności zarówno po stronie dostawcy, jak i klienta. Model współodpowiedzialności (shared responsibility model) określa, że dostawca odpowiada za fizyczne bezpieczeństwo centrów danych, hipernadzorcę, sieć i podstawowe usługi, natomiast klient odpowiada za konfigurację systemów, kontrolę dostępu, szyfrowanie danych i zgodność z przepisami. W praktyce oznacza to konieczność stosowania silnych polityk IAM (Identity and Access Management), szyfrowania danych w spoczynku i w tranzycie, backupu, audytów, alertów bezpieczeństwa i automatycznego reagowania.
Z punktu widzenia inżyniera systemowego czy administratora, chmura oznacza przejście z zarządzania fizycznymi maszynami na zarządzanie infrastrukturą jako kodem (IaC – Infrastructure as Code). Zamiast ręcznego konfigurowania serwerów, sieci, reguł zapory, tworzy się pliki konfiguracyjne w językach takich jak YAML, HCL (Terraform), JSON, które można wersjonować, testować i wdrażać automatycznie. Daje to większą kontrolę, powtarzalność i możliwość automatyzacji procesów wdrożeniowych w środowiskach deweloperskich, testowych i produkcyjnych.
W świecie DevOps chmura obliczeniowa pozwala na szybkie budowanie środowisk CI/CD (Continuous Integration / Continuous Deployment), w których kod źródłowy po zatwierdzeniu automatycznie przechodzi testy, budowanie kontenerów, wdrożenie do środowiska stagingowego i ewentualnie do produkcji. Usługi takie jak AWS CodePipeline, GitHub Actions, GitLab CI, Azure DevOps czy Google Cloud Build umożliwiają tworzenie pełnych łańcuchów dostarczania oprogramowania w chmurze, z wykorzystaniem konteneryzacji, testów jednostkowych, skanowania bezpieczeństwa i rollbacków.
Dla programisty chmura to dostęp do gotowych komponentów – baz danych (np. Amazon RDS, Firebase Realtime DB), kolejek wiadomości (SQS, Pub/Sub), cache (Redis, Memcached), funkcji bezserwerowych (AWS Lambda, Cloud Functions), logowania użytkowników (Cognito, Firebase Auth), przechowywania plików (S3, Blob Storage). Dzięki temu możliwe jest skupienie się na kodzie biznesowym, a nie infrastrukturze. Usługi są dostępne przez REST API, SDK, interfejsy CLI i gotowe biblioteki dla różnych języków programowania.
Chmura obliczeniowa odgrywa też ogromną rolę w analizie danych i uczeniu maszynowym. Usługi takie jak AWS SageMaker, Google AI Platform, Azure ML Studio oferują środowiska do trenowania modeli, przechowywania zestawów danych, automatyzacji eksperymentów, wersjonowania modeli, wdrażania ich jako REST API i monitorowania ich wydajności. Dodatkowo usługi Big Data, takie jak BigQuery, Redshift, Snowflake czy Databricks umożliwiają analizę petabajtów danych w czasie rzeczywistym, agregacje, uczenie nienadzorowane i integrację z wizualizacją wyników.

Z perspektywy użytkownika końcowego chmura może być niewidoczna – korzysta on z aplikacji przez przeglądarkę lub aplikację mobilną, nie wiedząc, że zasoby te są dynamicznie skalowane, przenoszone między strefami dostępności, replikowane i utrzymywane przez setki maszyn w różnych lokalizacjach. Ale to właśnie dzięki chmurze możliwe jest zapewnienie globalnej dostępności usług 24/7, wysokiej dostępności SLA, błyskawicznej reakcji na zmiany obciążenia, i automatycznego odzyskiwania po awarii.
2. Zabezpieczenia w Sieciach Komputerowych
Zabezpieczenia w sieciach komputerowych to zbiór działań, mechanizmów i technologii mających na celu ochronę integralności, poufności oraz dostępności danych przesyłanych w środowiskach sieciowych. Kluczową rolę w tym obszarze odgrywają narzędzia i protokoły zarządzania, takie jak SNMP (Simple Network Management Protocol) i NetFlow, które umożliwiają monitorowanie stanu urządzeń sieciowych, zbieranie informacji o przepływach danych oraz szybką reakcję na anomalie. Niezbędnym elementem zabezpieczeń jest także analiza ruchu sieciowego, pozwalająca na wykrywanie nieautoryzowanego dostępu, prób ataków oraz identyfikację przeciążeń i błędów konfiguracyjnych. Efektywne zarządzanie wydajnością i dostępnością zasobów sieciowych gwarantuje nieprzerwaną pracę systemów i minimalizuje ryzyko przestojów, co jest szczególnie istotne w środowiskach o krytycznym znaczeniu operacyjnym, takich jak centra danych czy infrastruktury administracji publicznej.
2.1. Narzędzia i protokoły zarządzania siecią: SNMP, NetFlow
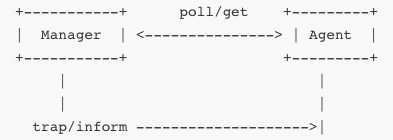
SNMP i NetFlow to dwa różne, ale komplementarne mechanizmy używane do zbierania informacji o stanie i ruchu w sieci. SNMP (ang. Simple Network Management Protocol) działa w modelu zarządzania opartego na agentach i menedżerze: na urządzeniach sieciowych jak routery, przełączniki, serwery działa oprogramowanie‑agent, które udostępnia dane o stanie urządzenia; system nadzoru (menedżer) zadaje pytania typu „get” lub „walk” i otrzymuje odpowiedź zawierającą dane, albo sam może wysłać informację (trap lub inform) o zdarzeniu. SNMP używa „MIB” – bazy obiektów zarządzania przedstawionych w drzewiastej strukturze, identyfikowanych przez OID (Object Identifier). Przykład: jeśli menedżer zapyta „1.3.6.1.2.1.1.3.0” (sysUpTime), agent odpowie liczbą 1000235, co oznacza czas pracy urządzenia w setnych częściach sekundy. Protokół ma trzy główne wersje – SNMPv1, v2c i v3; różnice obejmują uwierzytelnianie, poufność, autoryzację. SNMPv3 dodał uwierzytelnianie HMAC (MD5 lub SHA) i opcjonalnie szyfrowanie DES/AES. Tradycyjna konfiguracja: urządzenie definiuje „community string” (hasło w stylu „public”), które menedżer musi podać, by uzyskać dostęp „read-only” lub „read-write”. Trap pozwala agentowi wysyłać alerty bez pytania, np. przy przekroczeniu progów CPU czy awarii interfejsu. Dla wydajniejszego monitorowania stosuje się polling – okresowe odpytywanie agentów, co umożliwia zbudowanie historycznych wykresów, trendów i alertów.
NetFlow (i podobne IPFIX) działa nieco inaczej: urządzenie sieciowe (router/switch/firewall) eksportuje zbiory informacji o przepływach ruchu — zestawach pakietów, które dzielą te same właściwości (tzw. flow). Flowy są definiowane przede wszystkim przez pięć parametrów: adres źródłowy IP, adres docelowy IP, port źródłowy, port docelowy, protokół (5‑tuple), ale mogą być rozszerzone o dodatkowe atrybuty – typ serwisu (ToS), AS BGP, liczba pakietów, bajtów, czas rozpoczęcia i zakończenia, interfejs. Urządzenie gromadzi dane flow, a gdy flow się kończy (timeout wysoki lub niski), pakiety, których był częścią, lub gdy liczba bajtów przekroczy wartość progową, wysyła „record” do kolektora NetFlow. Kolektor zbiera, agreguje i analizuje te rekordy, co pozwala na identyfikację największych pod względem ruchu użytkowników, stosunków między sieciami, kanałów geograficznych, identyfikację problemów (np. błędów), wykrycie ataków (DOS/DDOS), analizę trendów.
NetFlow oferuje prostą, ale potężną mapę ruchu. Korzysta się z niestandardowych portów UDP (np. 2055) lub TCP/IP w IPFIX (por. RFC 7011), co pozwala przesyłać dane wśród różnych typów urządzeń. W połączeniu z SNMP można np. zestawić, że interfejs o największym ruchu (według SNMP – ifInOctets/ifOutOctets) odpowiada największym przepływom NetFlow, co daje pełny obraz wydajności i obciążenia sieci. SNMP ma ograniczenie: większość urządzeń utrzymuje licznik bajtów do wartości 32 bitów – w szybkich interfejsach trzeba używać SNMPv2 z counternami 64‑bitowymi (Counter64) – inaczej można przeoczyć fakt przerwania licznika.
Administracja wynajduje w SNMP ustawienia progów (thresholdy) dla CPU, pamięci, stanu interfejsów, natomiast NetFlow pozwala analizować przepływy, latencje, „elefanty” (elephant flows) i „myszy”. Gdy flow rzeczywiście trwa długo i zużywa wiele zasobów, można go przebadać i zoptymalizować (QoS, routowanie), albo throttling i QoS na podstawie szczytów wykresów. SNMP i NetFlow można połączyć z narzędziami SIEM/SOAR, aby reagować na zmiany.
Złożone środowiska sieciowe często integrują SNMP i NetFlow z panelem typu grafana, rrdtool/Cacti, SolarWinds, PRTG, Paessler, ELK stack z Elastic Stack – zbierają dane, tworzą historyczne wykresy, przewidują trendy i alarmują. Często router odpytywany SNMP co 60 s, zbiera NetFlow w czasie rzeczywistym w oknach 5 min, a aplikacje agregują i wizualizują korelacje między obciążeniem, wydajnością a flowami.
SNMP pozwala monitorować konfigurację, interfejsy, błędy, zasoby urządzeń, natomiast NetFlow karmiony przez informacje o ruchu – pozwala ocenić wzorce ruchu, przepustowości, kanały i bezpieczeństwo sieci. To rozdanie SNMP+NetFlow jest standardem w wielu przedsiębiorstwach, ISP i centrach danych.
Wysokiej klasy rozwiązania korzystają również z rozszerzeń takie jak sFlow, jflow (Cisco), IPFIX czy eFlow (Huawei). IPFIX jest standaryzowaną wersją NetFlow v9, używa protokołu eksportu szablonów i rekordów. sFlow to próbkuj ruch pasujący co N‑ty pakiet i eksportuje ramki wprost do kolektora, co obniża narzut w szybkich sieciach 100 Gbps+.
Z punktu widzenia implementacji, SNMP wymaga konfiguracji ACL („grant snmp read‑only” lub v3 users), NetFlow – definicji „flow exporter” (adres kolektora, port UDP) i „flow monitor” powiązanego ze szablonem. Aktywacja trace‑flow połączenia analizuje także pakiety TCP/UDP poruszające się przez dane interface’y.
W serwisach chmurowych (AWS, Azure) SNMP nie działa bezpośrednio – korzysta się z CloudWatch, Azure Monitor, ale można wdrożyć agenty SNMP/Telegraf do VM‑ów. Dla NetFlow można użyć flow logs (VPC Flow Logs / NSG Flow logs), które umożliwiają podobną analizę ruchu, a integracja z SIEM analizuje zagrożenia, nadużycia, anomalie. SNMP może posłużyć do audytu, NetFlow do wykrywania botnetu, ataków DDoS, skanowania portów, wycieków danych.
2.2. Analiza ruchu sieciowego
Analiza ruchu sieciowego polega na przechwytywaniu, badaniu i interpretowaniu pakietów przesyłanych przez sieć. Pozwala zrozumieć, co się dzieje „pod maską” komunikacji między urządzeniami, identyfikować aplikacje, protokoły, anomalie, ataki, opóźnienia i wąskie gardła. Niezależnie od tego, czy chodzi o rozwiązania bezpieczeństwa, optymalizację wydajności, debugowanie lub zgodność z normami, analiza ruchu jest fundamentem obsługi sieci. Istnieją dwa główne podejścia: pasywne — gdy ruch jest przechwytywany (np. na mirrorowanym porcie SPAN, w TAP‑ie sieciowym lub na bridge’u), oraz aktywne — gdy wysyła się własny ruch testowy (ping, traceroute, HTTP get) w celu pomiaru zmian, opóźnień, strat czy trasowania. Pasywna analiza to typowo zadanie dla narzędzi takich jak Wireshark, tcpdump, tshark lub algorytmy systemów IDS/IPS (Snort, Suricata), ale też silniki NetFlow/sFlow. Współczesne platformy automatyzują analizę wyników przez uczenie maszynowe – analiza protokołów niedokumentowanych (np. aplikacji IoT), identyfikacja anomalii bez sygnatur, korelacja zdarzeń w czasie. Narzędzia filtrują ruch według IP, portów, kierunku, typu protokołu, a następnie pozwalają rozkładać pakiety na składowe warstwy Ethernet/IP/TCP/HTTP itd., oferując szczegółowy widok na treść pakietów (nagłówki, flagi, payload). Analiza ruchu umożliwia określenie metryk takich jak opóźnienia między hostami (RTT), czas DNS, czas TCP three‑way handshake, czas TLS handshake, przepływność danych oraz proporcje ruchu szyfrowanego i nieszyfrowanego. Pozwala zidentyfikować retransmisje, out‑of‑order, błędy CRC, fragmentacje IP, problemy z MTU, DNS errors, błędy protokołowe (HTTP 4xx/5xx), nietypowe sekwencje SYN/ACK, podejrzane pakiety RST, FIN w złym czasie, skany portów (SYN‑scan, Xmas‑scan, NULL‑scan).

Po stronie narzędzi analiza może być liniowa — najpierw Ethernet, IP, TCP/UDP, aplikacja — lub heurystyczna: np. analiza TLS przy użyciu JA3 fingerprints, identyfikacja klientów (np. przeglądarki, IoT), analiza treści payload w protokołach DNS (zapytania A, MX, TXT), analiza ścieżek HTTP (request‑response), analiza RSS, JSON‑ów, SOAP, REST‑API, WebSocketów. Systemy głębokiej inspekcji pakietów (DPI) rozpoznają i klasyfikują pakiety na podstawie wzorców, czasem ekstraktują nawet dane formularzy, nagłówki, nagłówki HTTP multipart, przy jednoczesnym przestrzeganiu polityk prywatności.
Przykład: diagnoza wolnego ładowania strony. Pasywna analiza wykazuje — opóźnienia na DNS (czas zapytania + odpowiedź), potem wolny TLS handshake (kilka RTT), potem dużą liczbę retransmisji TCP (Time‑Wait lub brak ack), wreszcie pobieranie zasobów z dużymi opóźnieniami — analiza per‑segment i histogramów pokaże obraz problemu.
Aktywna analiza sieciowa to technika, w której użytkownik lub administrator sam generuje ruch w sieci w celu diagnozowania jej właściwości, jakości usług lub topologii. W odróżnieniu od analizy pasywnej, polegającej na nasłuchiwaniu istniejącego ruchu, analiza aktywna wymaga świadomego wygenerowania zapytań diagnostycznych i obserwowania odpowiedzi. Umożliwia to wykrycie ukrytych komponentów infrastruktury takich jak load balancery, translatory adresów (NAT), systemy równoważenia obciążenia oparte na anycaście, tunele VPN, mechanizmy MPLS czy sieci dostarczania treści (CDN). Narzędzia takie jak ping, traceroute, httperf, wrk czy iperf umożliwiają wykonanie takich analiz.
Podstawowym narzędziem aktywnej diagnostyki jest ping, które bazuje na komunikacie ICMP Echo Request i Echo Reply. Mierzy czas potrzebny na przesłanie pakietu do celu i z powrotem, dostarczając informacji o opóźnieniach i utraconych pakietach. Przydatne jest także ustawianie flagi „Don't Fragment” (DF), co pozwala testować maksymalną jednostkę transmisji (MTU). Jeśli pakiet nie zostanie dostarczony, oznacza to zbyt małą wartość MTU na trasie – pozwala to lokalizować błędnie skonfigurowane urządzenia lub tunele VPN.

W tym przykładzie przesyłany jest pakiet 1500 bajtów (dodając 28 bajtów nagłówka IP/ICMP), a flaga „Don't Fragment” nie pozwala na fragmentację. Jeśli taki pakiet nie przejdzie, oznacza to, że na trasie znajduje się urządzenie z niższym MTU (np. 1400 bajtów w przypadku GRE lub IPSec).
Kolejnym narzędziem jest traceroute, które pozwala poznać każdy węzeł (router) na trasie do celu. Działa poprzez wysyłanie pakietów IP o stopniowo zwiększanym polu TTL (Time To Live). Gdy TTL osiąga zero, router zwraca ICMP Time Exceeded – na podstawie tych odpowiedzi można zrekonstruować trasę pakietów przez Internet. To umożliwia wykrycie asymetrycznych tras (gdy pakiet i odpowiedź idą innymi drogami), obecności tunelowania (gdy segmenty trasy są ukryte) czy zmian tras wynikających z dynamicznego routingu lub działania CDN.
Bardziej zaawansowane narzędzia to iperf i iperf3, które służą do pomiaru przepustowości TCP lub UDP między dwoma punktami. Umożliwiają pomiar przepływności w różnych kierunkach, testy w czasie rzeczywistym, badanie jittera (zmienność opóźnienia), strat pakietów, efektywności retransmisji TCP. iperf umożliwia również ustawienie czasu trwania testu, wielkości segmentów, liczby strumieni równoległych.

Wyśle 4 równoległe strumienie TCP przez 10 sekund, pozwalając zmierzyć maksymalną dostępną przepustowość na danym łączu.
Do testowania wydajności HTTP można używać httperf lub wrk. httperf pozwala symulować tysiące żądań HTTP, analizując czasy odpowiedzi, liczbę połączeń na sekundę, zachowanie serwera pod obciążeniem. wrk to nowoczesne narzędzie działające wielowątkowo, potrafiące jednocześnie wysyłać wiele żądań HTTP, rejestrować minimalne, maksymalne i średnie czasy odpowiedzi, rozkład błędów.

Ten test użyje 4 wątków (-t4), 100 równoczesnych połączeń (-c100) i będzie trwać 30 sekund. Rezultatem będzie informacja o liczbie zapytań na sekundę, czasie odpowiedzi i rozkładzie procentowym czasów reakcji.
Za pomocą tych narzędzi można także wykrywać load balancery – np. gdy różne pakiety TCP trafiają do różnych backendów. W przypadku anycastu – wiele serwerów ma ten sam adres IP, ale znajdują się w różnych miejscach świata – narzędzia aktywne pozwalają zidentyfikować do którego fizycznego serwera trafi ruch.
Analizując wartości TTL odpowiedzi, można stwierdzić czy pakiet przebył 2, 5 czy 15 routerów. Jeżeli TTL w odpowiedzi zmienia się przy kolejnym zapytaniu – może to oznaczać dynamiczne równoważenie ruchu, działanie mechanizmów BGP lub obecność sieci typu CDN.
W środowiskach VPN, analiza aktywna wykazuje, że pakiety omijają lokalne trasy, pojawiają się opóźnienia, a trasy traceroute stają się bardziej zwarte (tunelowanie). W MPLS – część tras może być ukryta, bo routery pośrednie nie ujawniają się w odpowiedziach ICMP (tzw. „label switching”).
Dzięki aktywnej analizie możliwe jest również wykrycie NAT-ów – np. w UDP, gdzie port źródłowy jest zmieniany przez NAT. Porównując sekwencje portów lub analizując źródła odpowiedzi można wykryć translację adresów oraz ustalić ich zakres działania.
Analiza ruchu to także podstawa wykrywania anomalii. System obserwuje trendy, alertuje gdy wykracza powyżej odchyleń, generuje SIEM events, pozwala reagować w czasie rzeczywistym (inline IPS). Przykłady: wzrost ruchu UDP do dziwnych portów, powtarzające SYN bez ACK (skanowanie), nietypowe DNS TXT z base64, duże uploady w nocy (wyciek), połączenia do C2 (Command & Control), beaconing. Analiza SSL zamieniaja komunikację w metryki: długość certyfikatu, commonName, issuer, fingerprint, ocsp stapling, pilność cipherSuite itp.
W chmurze natomiast analiza polega na eksportowaniu logów VPC Flow Logs, CloudWatch, Azure Network Watcher, Google VPC logging, zebranych i analizowanych w pipeline: zbieranie do S3/Blob, normalizacja (Glue/Kafka), analiza (Athena/BigQuery, ElasticSearch), dashboardy (Grafana), alerty (pagerduty, slack). Wirtualne TAPy i mirrorowanie w chmurze pozwalają analizować ruch między VM/containers/k8s pods.
Deep Packet Inspection (DPI) uruchamiany inline lub pasywnie może także działać z NAT, IPSec/VPN, TLS termination (w firmach), w chmurze przy load balancerze decryptuje ruch (jeśli ma certyfikat) i inspektuje.
Analiza ruchu sieciowego da się sklasyfikować także wg zastosowań: troubleshooting, bezpieczeństwo, compliance, planowanie pojemności, optymalizacja QoS, billing u ISP. W ISP analiza to billing per-flow, detekcja P2P ruchu, dynamiczny rating, shaping per subscriber. Wztchrone między warstwami, SNMP+NetFlow+pakiety daje pełny obraz: SNMP monitoruje counters (CPU, interfaces), NetFlow – ruch, DPI – treść, pakiety – szczegół pakietowy.
Przykład TCP three‑way handshake: pasywnie widzimy SYN, SYN-ACK, ACK, liczymy opóźnienia między nimi. Gdy SYN-ACK jest retranmitowany – oznacza latencję lub packet loss. Jeśli RST pojawia się bez wcześniejszego SYN, oznacza skan, skrypt lub omyłkowe połączenie. Jeśli FIN pojawia się, ale brak ACK – implicite half‑open, co może sygnalizować błędy w aplikacji.
Analiza ruchu to znak rozpoznawczy pracy sieciowca, DevOps inżyniera, analityka bezpieczeństwa. Wymaga narzędzi, znajomości protokołów, umiejętności odczytu pakietów i kontekstu biznesowego. Dla studentów warto zwrócić uwagę na strukturę pakietów – warstwy OSI – i stosowanie filtrów BPF (np. „tcp port 443 and host 1.2.3.4”) albo predefiniowanych metryk (MRTG, sFlow). Warto wiedzieć, że przy ruchu 10 Gbps analiza pakietów wymaga sprzętowej akceleracji – np. SmartNIC, FPGA, dedykowanych capture cards. Trzeba też pamiętać o prywatności – DPI może przechwytywać dane użytkownika, więc analizę należy stosować z ostrożnością i zgodnie z polityką RODO.
W codziennej pracy analiza może wyglądać następująco: klient narzeka na wolne działanie aplikacji; inżynier włącza tcpdump na mirrorowanym porcie serwera, filtruje komunikację między klientem a serwerem, analizuje licznik序号 pakietów, patrzy czy są retransmisje, out-of-order, diagnostyzuje czy problem jest po stronie sieci, serwera, aplikacji lub po stronie klienta.

Poza obrazem pakietów istotne są także heurystyki np. analiza przepływów do zdalnych krajów, portów 23, 5900, 3389 – podejrzane. W sieciach korporacyjnych lub rządowych stosuje się same aplikacje do analizy: Suricata w ty i Snort generują alarmy na specyficzne sygnatury (np. port knocking, exploit), a Zeek (dawniej Bro) analizuje sesje i protokoły na poziomie aplikacyjnym (HTTP URI, DNS queries).
Badanie ruchu DNS może ujawnić wycieki danych, zapytania do nietypowych subdomen z długimi losowymi nazwami – sygnał beaconingu. Analiza HTTP umożliwia sprawdzenie, które zasoby są pobierane, jakie nagłówki, cookies, cache‑control, CORS są obecne. Pozwala też identyfikować Crawlerów, boty, scrapperów.
2.3. Zarządzanie wydajnością i dostępnością
Zarządzanie wydajnością i dostępnością w sieciach to zagadnienie skupiające się na tym, aby usługi działały szybko, stabilnie i były dostępne nawet przy awariach. Pojęcia wydajność i dostępność uzupełniają się – wydajność określa, jak szybko zapytania są obsługiwane, jaką przepustowość osiąga usługa, jak niskie opóźnienia i jitter można zapewnić; dostępność dotyczy tego, że usługa działa nieprzerwanie, że użytkownik zawsze może się z nią połączyć nawet przy awariach sprzętu, oprogramowania czy łącza. Realizuje się to poprzez monitorowanie, skalowanie, redundancję, load balancing, odporność na błędy, przywracanie po awarii (DR/BCP), konteneryzację, replikację danych, backup, testy wydajności i planowanie pojemności. W efektywnym środowisku sieciowym działania te są zautomatyzowane, powiązane z narzędziami DevOps i ciągłym dostarczaniem usprawnień.
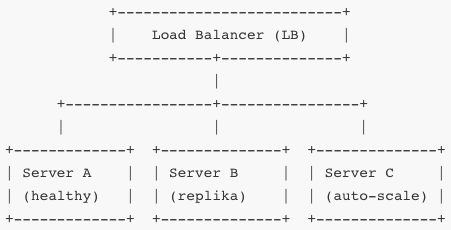
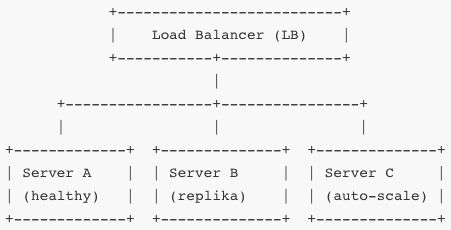
Monitorujesz czas odpowiedzi, CPU, pamięć, ruch sieci, błędy. Jeśli Server B osiąga pewien próg, automatycznie dodaje się Server C (autoscaling). Load balancer dzieli ruch między aktywne serwery. Jeśli któryś padnie, inne przejmują jego część (failover).
Monitorowanie to jedna podstawa – tracery czasów odpowiedzi (RTT), liczba żądań na sekundę (RPS), procent utraconych pakietów, błędów 5xx, średnie opóźnienia, zużycie zasobów. Realizuje się to przez SNMP, NetFlow, logi aplikacji, metryki Prometheus, ELK, Grafana, alerty PagerDuty/SMS/email. Dane te analizujesz w czasie rzeczywistym, definiujesz progi, DPI sygnalizuje anomalie (np. przyrost opóźnień, retransmisji).
Skalowanie dzielisz na poziome (dodajesz kolejne instancje) i pionowe (dodajesz CPU/pamięci do istniejących). Poziome jest bardziej odporne na awarie i efekt skały – nawet wiele równoczesnych żądań obsłuży się przez kilka serwerów. Pionowe bywa tańsze, ale najmniejsza awaria zatrzymuje cały węzeł. W środowisku kontenerowym (np. Kubernetes) definiujesz Deployment i Horizontal Pod Autoscaler – wzór: jeżeli CPU > 70% przez 2 minuty i RPS rośnie, HPA tworzy nowy Pod.
Redundancja dotyczy nie tylko serwerów, ale wszystkich warstw: zapis baz danych w master-read replica lub multi-master; pamięć klient-side cache w lokalnym węźle; strefy dostępności (Availability Zones), regiony. Backup odbywa się codziennie, ale także co godzinę snapshoty, okresowe przywrócenie w środowisku testowym potwierdza zdolności DR. Redis ma replikację synchroniczną; bazy SQL cluster; NoSQL – replikacyjny quorum; pliki obiektowe S3 z wersjonowaniem.
Dostępność mierzysz w procentach: SLA 99,9% to ~8,8 godzin przestoju rocznie; 99,99% to ~52 minuty. Tolerancja ustalana przez biznes, bo redundancja i monitoring kosztują. Planwork of Business Continuity/Disaster Recovery ustala RPO (ile danych można stracić) i RTO (ile czasu można przetrwać bez usług).
Do przywracania usług używasz mechanizmów failover: serwery stand-by, baze z repliką, sieci podłączone multi-path (BGP, Anycast), load balancer, Health Check TCP/HTTP by LB automatycznie przerzucał traffic. W kontenerach Probe Liveness i Readiness w Kubernetesie odznaczają zaburzone Pody i restartuje je.
Zarządzanie pojemnością polega na analizie trendów: różnice w ruchu porannym, weekendowym, sezonowym. Pomiar obciążenia w określonych dniach pozwala planować testy obciążeniowe (load tests) i zapas zasobów. Generujesz testy np. przy 2x oczekiwanym szczycie, aby ocenić zachowanie systemu, jego opóźnienia, throughput.
W otwartym środowisku konteneryzowanym ruch musi być sterowany politykami, QoS, limitami zasobów w cgroup. Dzięki temu jeden kontener nie zawojuje całej CPU lub pamięci DNS. Monitorując i skalując, kontrolujesz, że inne zasoby usługi nie wpadają w „noisy neighbor” – wąskie gardło np. IOPS dysku, EBS, bandwidth.
Observability oznacza nie tylko metryki, ale także trace'y – request distributed tracing (OpenTelemetry), gdzie całość requestu ma identyfikator trace‑id, a usługi raportują czasy request→response; możesz powiązać spadek wydajności z daną ścieżką. Jeśli PageA wyświetla się 200 ms wolniej, możesz sprawdzić którego mikroserwisu to dotyczy i czy może to wynik przeciążenia, snapshotu GC, braku replikcache, wolnej bazy.
Automatyką zarządzasz politykami – np. jeśli błąd 5xx > 1% i CPU > 90% to trigger alert i add pod; jeśli CPU < 10% i RPS zmaleje, scale down. To zapobiega przestojom i niskiej wydajności. Stabilizacja następuje poprzez tweak planów retry/backoff (exponential backoff z jitterem).
Dostępność wpływa na routing – stosujesz Anycast, BGP, Global Load Balancers, traffic steering. Globalna architektura kieruje użytkownika do najbliższego regionu zdrowego, Prober sprawdza zdrowie regionalne i usuwa region z puli, aż wróci. To minimalizuje opóźnienia i zapobiega awarii.
Wszystkie te mechanizmy muszą być przetestowane – chaos engineering (Netflix Simian Army Chaos Monkey), grid tests, awarie regionów, opóźnienia między regionami, snapshot bazy, failover load balancer back to default. Testy te muszą powtarzalnie ignorować awarie i potwierdzać z góry zadane SLA.
Scentralizowane logowanie (ELK/Graylog) agreguje błędy, metryki, trace. Anomaly detection na logach alertuje wzrost czasu requestów, błędów, timeoutów. Wykorzystujesz retry + circuit breaker (limit błędnych połączeń) + fallback.
Zarządzanie wydajnością i dostępnością wymaga współdziałania programistów, DevOps inżynierów, sieciowców i SRE; to ciągły proces – planowanie, implementacja, monitorowanie, analiza, poprawianie. Praktyka w labach i eksperymenty pozwalają zrozumieć jak elementy systemu współdziałają pod obciążeniem, jak awarie zepsują ścieżkę zapytania i jak odbudować system.