Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | 1. Podstawowa składnia języka |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | sobota, 17 stycznia 2026, 06:12 |
Opis
Wersja podręcznika: 1.0
Data publikacji: 01.01.2022 r.
1. Podstawowa składnia języka
Materiały zamieszczone w tym podręczniku powstały przy założeniu ukończenia przez Was już pierwszego kursu programowania – wprowadzenia do programowania strukturalnego, oraz częściowo – ukończenia programowania obiektowego C++. Zakładam więc, że informacje przedstawione w tym rozdziale nie są dla Was czymś nowym. Raczej są rozszerzeniem i przypomnieniem wiedzy już nabytej wcześniej. Jednak – by materiały były kompletne – nic nie będziemy pomijali.
Wiedza prezentowana w naszym podręczniku na żadnym etapie nie jest uzależniona od stosowanego przez Was kompilatora / środowiska programistycznego. Wszystkie przykłady i konstrukcje programistyczne powinny dać się skompilować i uruchomić na dowolnym standardowym kompilatorze C++ - my w trakcie naszej pracy wykorzystywaliśmy GCC., w połączeniu z CLion oraz QtCreator - jako środowiska programistyczne.
1.1. Struktura programu w C++
Struktura programu w C++
Język C++, jak już wiecie - jest dość elastyczny. Struktura programu jako takiego jest zupełnie swobodna, np. bloki instrukcji oraz definiowania zmiennych mogą się praktycznie dowolnie przeplatać ze sobą, funkcje mogą być definiowane w różnej kolejności i w różnych miejscach. Podobnie wygląda sytuacja z klasami
Schemat każdego programu w języku C++ można zapisać następująco:
/** Na samym początku zazwyczaj umieszcza się pliki dołączane (nagłówki bibliotek)
wraz z dodatkowymi dyrektywami kompilatora. Mówimy o zwyczajowym umieszczaniu -
bo z punktu widzenia składni języka załączenie bibliotek może być wszędzie */
/** dołączenie biblioteki standardowej języka C / C++ */
#include <cstdlib>
/** dołączenie strumieniowego wejścia / wyjścia (zalecanego dla języka C++ */
#include <iostream>
/** biblioteka string zawiera implementację łańcuchów tekstowych (napisów).
W C++ nie ma typu prostego w pełni implementującego napisy */
#include <string>
/** Wykorzystanie przestrzeni nazw biblioteki standardowej */
using namespace std;
/** Program zapisuje się w C++ w postaci funkcji. Każda funkcja zaczyna się
nagłówkiem, potem występuje treść zamknięta w nawiasy klamrowe. Więcej o funkcjach
będzie w dalszej treści podręcznika. Program może składać się z wielu funkcji. Zawsze
musi być co najmniej jedna - main (patrz niżej). Od niej zaczyna się tok wykonania
programu */
typ_zwracanej_wartosci nazwa_funkcji(lista_parametrow)
{
...
};
/** Przed lub pomiędzy funkcjami zamieszcza się definicje i deklaracje stałych,
zmiennych, typów i klas globalnych dla danego pliku, czyli takich, z których można
korzystać w każdej funkcji. */
const int...{definicja stalych}
...
typedef...{definicja typow}
...
double... {definicja zmiennych}
...
/** W każdym programie C++ jest jedna główna funkcja - nazywa się main. */
int main(int argc, char *argv[])
/** Nawiasy klamrowe służą do oznaczenia początku i końca funkcji */
{
/** Kolejne instrukcje składające się na nasz algorytm */
instrukcja;
instrukcja;
...
instrukcja;
/** W C++ pomiędzy instrukcjami znów mogą się znaleźć definicje
zmiennych, typów, stałych - lecz w takim wypadku będą one lokalne.
O zasięgu widoczności zmiennych będzie zamieszczona w dalszej części podręcznika. */
/** Funkcja main powinna zwrócić jakąś wartość. W przypadku prawidłowego zakończenia
programu zwrócone powinno zostać 0 lub równoważna stała symboliczna EXIT_SUCCESS */
return EXIT_SUCCESS;
} /// Zamykający nawias klamrowy na koniec funkcji main
Komentarze
Tłumaczenie zaczniemy dość nietypowo – od zamieszczania komentarzy. W języku C++ mamy dwa możliwe tryby komentowania. Pierwszy z nich historycznie wywodzi się jeszcze z języka C. W tym wypadku komentarzem jest każdy fragment tekstu zaczynający się od znaków /* i kończący się na */. Taki komentarz może zawierać wiele linii tekstu. Jeśli wewnątrz komentarza wystąpi jeszcze raz para /* zostanie ona zignorowana.
Drugi tryb komentarzy jest uzupełnieniem pierwszego: wszystko co zaczyna się od znaku podwójnego ukośnika // aż do końca linii jest traktowane jako komentarz.
Samo stosowanie komentarzy również rządzi się pewnymi regułami. My będziemy (i Wam również zalecamy) stosowali następującą konwencję komentowania:
- Komentarz zaczynający się od początku linii (bez instrukcji przed nim) będzie dotyczył tego co jest poniżej - czyli najpierw komentarz, potem kod.
- Komentarz umieszczony za instrukcją dotyczy tej instrukcji
W tym miejscu chciałbym także, byście rzucili okiem na komentarze nieco bardziej sformalizowane. Istnieje darmowy system generowania dokumentacji nazywający się doxygen. Na dzień dzisiejszy to najpopularniejszy standard komentowania kodu w różnych językach programowania, oraz generowania z takiego kodu gotowej dokumentacji – łatwej do czytania i przeglądania. Sama nazwa doxygen oznacza program parsujący kod źródłowy i generujący dokumentację do niego. Jeśli kod nie jest odpowiednio skomentowany – to jedyną informacją którą możemy z niego uzyskać jest informacja o strukturze kodu – klasach, ich wzajemnych związkach, dołączanych plikach, itp. W przypadku gdy w kodzie umieścicie odpowiednio przygotowane komentarze – możliwości programu rosną w sposób znaczący. Możecie uzyskać dokumentację API (Application Programming Interface) o jakości nie odbiegającej od dokumentacji dostarczanej do komercyjnych środowisk programistycznych. I to wszystko dla Waszego kodu, w dodatku zupełnie za darmo...
Jak więc komentować kod? Zasad jest kilka. Po pierwsze – istnieją specjalne znaki komentarza, które rozpoznaje i interpretuje Doxygen. W przypadku języka C++ jest to komentarz w następującej formie:
/**
* ... tekst (z opcjonalną gwiazdką * na początku) ...
*/
/*!
* tekst (z opcjonalną gwiazdką * na początku)
*/
///
/// ... text ...
///
//!
//! ... text ...
//!
/*! \brief Tu zamieszczamy opis krótki
* Dalszy ciąg krótkiego opisu
*
* Opis szczegółowy jest oddzielony od krótkiego pustą linią.
*/
/// Alternatywnie możecie zamieścić opis krótki po trzech ukośnikach.
/** A za nim zamieścić opis szczegółowy oznaczony jako blok */
int zmienna; /*!< To jest krótki opis zmiennej */
/**
* Funkcja sprawdza, czy z trzech odcinków da się zbudować trójkat.
* Pobiera trzy wartości typu int i zwraca wartość typu bool.
*
* @param[in] x długość pierwszego odcinka.
* @param[in] y długość drugiego odcinka.
* @param[in] z długość trzeciego odcinka.
* @return true jeśli da się zbudować trójkąt, false w przeciwnym wypadku
*/
bool triangle(int x, int y, int z) {
return (x < y+z) && (y < x+z) && (z < x+y);
}
Składnia języka raz jeszcze
W języku C++ formalizm zapisu jest stosunkowo prosty i ograniczony. Jednakże elegancja obowiązuje zawsze – tym bardziej, że w większości współczesnych środowisk i edytorów programistycznych możecie swobodnie korzystać z autoformatowania. Przypominam zestaw dobrych rad odnośnie formatowania:
- Każda instrukcja powinna być zapisana w oddzielnej linii,
- Wszystko to, co znajduje się pomiędzy nawiasami klamrowymi { i } (blok programu), powinno zostać przesunięte względem nich o 2-3 spacje,
- Zmienne deklarujemy kolejno, w oddzielnych linijkach umieszczając oddzielne deklaracje / definicje.
- Każda zmienna powinna być opisana za pomocą komentarza. Podobnie podstawowe kroki algorytmu.
namespace foospace
{
class Bar
{
public:
int foo();
private:
int foo_2();
};
int Bar::foo()
{
switch (x) {
case 1:
a++;
break;
default:
break;
}
if (isBar) {
bar();
return m_foo+1;
} else
return 0;
}
}
Budowa programu
Aby uruchomić program napisany w języku C++ wymagany jest etap kompilacji - przekształcenia kodu żródłowego w postać wykonywalną, charakterystyczną dla określonej platformy sprzętowej i systemu operacyjnego. Typowe (i zalecane) podejście do programowania w C++ zakłada, iż każdy program składa się z wielu plików:

Podział na wiele plików zdecydowanie ułatwia panowanie nad kodem, zwiększa możliwość jego ponownego wykorzystania, czy też pozwala na przyspieszenie etapu kompilacji dzięki wykorzystaniu tzw. kompilacji przyrostowej - kiedy to po wprowadzeniu zmian w jednym miejscu w kodzie kompilowany jest jedynie zmieniony plik, w przypadku pozostałych wykorzystywane są wcześniej już uzyskane pliki z kodem maszynowym (o / obj) - i prowadzony jest etap konsolidacji.
Standard języka dzieli elementy z których budujemy aplikacje na dwie zasadnicze grupy:
- składniki rdzenne - nie wymagają dołączania plików z deklaracjami, są dostępne w kodzie zawsze. Tu zaliczymy typy wbudowane (int, double, itp...) czy też podstawowe konstrukcje językowe (instrukcje if, pętle for, while, itp...)
- składniki biblioteki standardowej - wymagają dołączenia zewnętrznych bibliotek. Tu zaliczymy zarówno biblioteki systemowe (np do obsługi plików), jak i kontenery, algorytmy czy podobne elementy definiowane w tej bibliotece.
Sama biblioteka standardowa C++ została napisana przy wykorzystaniu ... C++ - co tylko dowodzi uniwersalności języka.
Wyrażenia
W dużym skrócie przypomnę – że w języku C++ mamy do czynienia ze słowami kluczowymi (jest ich określona ilość i nie można ich zmieniać), oraz typami, zmiennymi, stałymi, itp – definiowanymi przez użytkownika. Zobaczcie na trywialny przykład:
x = y + f(2);
W C++ by to miało sens – x, y i f muszą być odpowiednio zadeklarowane (by stały się bytami o swoich nazwach). Z każdą nazwą (identyfikatorem) jest związany typ, który określa jakie operacje można wykonać na jego przedstawicielu. Każdy taki byt musi być identyfikowalny – vide posiadać identyfikator. Identyfikator w C++ definiuje się następująco:
identyfikator:
niecyfra
identyfikator niecyfra
identyfikator cyfra
W skrócie:
<nazwa>::=<niecyfra> {<niecyfra>|<cyfra>}
gdzie niecyfra: litera łacińska lub _
Słowa kluczowe są zastrzeżone, wielkość liter jest rozróżnialna (ma znaczenie).
Przykłady poprawnych i niepoprawnych identyfikatorów:
// poprawne zmienne:
int Aaa, aAa, aaa;
double _kot, mi29, Moja1B_;
// niepoprawnie
char ala ma kota;
bool 39A;
double new;
float $inna_zmienna;
// definicja zmiennej
double zmienna;
// deklaracja
extern double inna;
Nie będę tutaj powtarzał znanych już Wam z poprzednich zajęć dodatkowych informacji o słowach kluczowych, znakach przestankowych, itp – zainteresowani niech sięgną do odpowiednich materiałów. Tu natomiast zatrzymamy się jeszcze przez chwilę przy deklaracjach i definicjach.
Deklaracje i definicje
C++ jest językiem ze statyczną kontrolą typów - co oznacza, że każdy jego element musi mieć typ. Co więcej - ten typ musi być znany kompilatorowi od pierwszego momentu jego użycia. By typ był znany - należy go najpierw kompilatorowi pokazać, czyli powiązać typ z identyfikatorem. Tak więc z każdą nazwą (identyfikatorem) jest związany typ, który określa jakie operacje można wykonać na jego przedstawicielu. Typy są różne – i nie mówimy tu tylko o typach danych ale o każdym elemencie języka. Przykładowe operacje które można wykonać na:
- stałych – można odczytać ich wartość
- zmiennych – można odczytać i zapisać
- funkcjach – można wykonać.
- klasach, szablonach, przestrzeniach nazw – o tym powiemy w drugiej części podręcznika
Deklaracja nie oznacza przyznania pamięci dla zmiennej, czy podania kodu dla funkcji – jest to jedynie informacja składniowa. W ten sposób programista może „obiecać” kompilatorowi, że gdzieś tam znajdzie się definicja zmiennej czy funkcji. Kompilator musi przyjąć deklarację programisty, i wg deklaracji sprawdzana jest poprawność składniowa kodu.
Z pojęciem deklaracji ściśle powiązane jest pojęcie definicji:
Innymi słowy – definicją są wszystkie informacje niezbędne do wygenerowania kodu wynikowego programu. Z tego wynika zależność pomiędzy deklaracją a definicją: każda definicja jest jednocześnie deklaracją (każdy program który można prawidłowo skompilować i uruchomić jest poprawny składniowo), natomiast nie każda deklaracja jest definicją (nie każdy program poprawny składniowo można skompilować i uruchomić).
W języku C++ wszystko co ma nadaną nazwę (stałe, zmienne, funkcje, itp) musi mieć typ, przy czym dla każdej nazwy musi istnieć tylko jedna definicja, natomiast może istnieć wiele takich samych deklaracji. Dlatego też działa mechanizm dołączania plików nagłówkowych (ale o tym za chwilę). Kilka przykładów deklaracji i definicji:
char znak; // definicja zmiennej typu podstawowego
string s; // definicja zmiennej typu definiowanego w bibl. standardowych
int licznik{1}; // definicja wraz z inicjacją
const double pi = 3.14; // definicja stałej (musi być z inicjacją, stara składnia)
extern long pid; // deklaracja zmiennej
char *imie = "Alicja"; // definicja tablicy znakow
// definicja tablicy tablic.
char *pora[] = {"wiosna",
"lato",
"jesien",
"zima"}
// wiele deklaracji – jedna definicja
extern int licznik;
int licznik;
extern int licznik;
// poniższy kod jest błędny
// licznik był już zadeklarowany / zdefiniowany jako int
extern double licznik;
// podobnie tutaj: licznik był już zadeklarowany / zdefiniowany jako int
double licznik;
// mimo że dwie definicje są identyczne – definicji nie można powtarzać.
int licznik;
// definicja dwóch zmiennych tego samego typu
int x, y;
// definicja mieszana – z inicjacją i bez niej.
int a1{2}, b1;
// definicja wskaźnika
long int *pole{nullptr};
// definicja mieszana – jedna zmienna to wskaźnik, druga zmienna jest statyczna.
int* p2, p3;
2. Typy danych
Język C++ należy do grupy języków programowania z silną kontrolą typów, co dla Was w praktyce oznacza, że kontrola typów w C++ odbywa się na etapie kompilacji (tylko pewne elementy tzw. późnego łączenia - sprawdzania typu zmiennej w trakcie wykonania programu - odbywają się w fazie wykonania programu, i tylko dla typów należących do jednej hierarchii klas). Dotyczy to wszystkich znanych technik programowania w C++ - także programowania generycznego (szablonów). Dalej znajdziecie krótkie przypomnienie dostępnych typów danych w C++.
2.1. Wprowadzenie
Zanim przejdziemy do dokładnego opisywania typów pora na jeszcze jedną uwagę, która& nie jest oczywista na pierwszy rzut oka, oraz jest cechą charakterystyczną C / C++, lecz już niekoniecznie w przypadku innych języków programowania.
- zwracana wartość może być tzw. wartością która oznacza brak wartości ( void),
- zwracaną wartość można pominąć (nie „przechwycić” jej) – co jest niemożliwe w wielu innych językach. Dlatego poprawne jest napisanie po prostu instrukcji 2+2; (pomijając kompletny brak jej sensu).
Zmienne, stałe i L-wartości
To, co jest charakterystyczne zarówno dla zmiennych, jak i stałych występujących w C++, to wspomniana na początku silna kontrola typów. W praktyce oznacza to, że zmienna czy stała musi mieć raz przypisany w momencie definicji, i potem do końca jej czasu życia niezmienny – typ danych które może przechowywać. Typ jest niezmienny – lecz od tego czy może się zmieniać wartość, czy nie – zależy czy mamy do czynienia ze zmienną czy ze stałą. W składni C++ to rozróżnienie jest zaznaczone, lecz często nie do końca poważnie brane przez kompilator.
Ogólnie stałe definiuje się i deklaruje tak jak zmienne – jedyną różnicą jest dodanie przedrostka const przed wyspecyfikowaniem typu. Podanie const w założeniu uniemożliwia zmianę wartości tak oznaczonej zmiennej w zasięgu jej widoczności bez jawnego rzutowania const cast. No właśnie . . . bez jawnego rzutowana . . . to co to za stała którą można zmienić w zmienną? Dlatego wspomniałem, że const nie jest brany poważnie przez kompilator. Jeśli włączona jest optymalizacja, kompilator sprawdza, czy istnieje w programie choćby teoretyczna możliwość zmiany wartości oznaczonej jako stała – i jeśli tak, to ignoruje przyrostek const tworząc zamiast tego zmienną, której wartości nie można prosto zmienić. W przeciwnym wypadku często wartości stałych są bezpośrednio rozwijane w kodzie programu, i nie jest im w ogóle przydzielana pamięć z obszaru pamięci danych.
Z pojęciami zmiennej i stałej ściśle związane jest pojęcie L-wartości. Ogólnie można przyjąć, że:
W praktyce L-wartościami najczęściej są zmienne bez modyfikatora const, ale także – np. parametry funkcji z tym modyfikatorem. Od powyższej definicji jest wyjątek – w przypadku definiowania stałej połączonego z jej inicjacją, stała stoi po lewej stronie równania – lecz nie jest ona L-wartością . . . wartość jest wyliczana na etapie kompilacji, a operator przypisania jest wtedy traktowany jako operator inicjacji. Dlatego też w nowych wersjach standardu języka raczej nastawiamy się na inicjację przy stosowaniu nawiasów klamrowych - a nie przy wykorzystaniu składni ze znakiem przypisania.
Na razie parametrami funkcji i innymi skomplikowanymi zagadnieniami nie zajmujmy się, natomiast sama definicja L-wartości mówi nam, dlaczego poprawny jest poniższy kod:
double r = 12.3;
double x;
x = 2.0*M_PI*r;x jest zmienną – więc jest L-wartością, natomiast niepoprawny jest ten kod:
double x;
2.0*M_PI*r = x;
Wartość wyrażenia 2*M PI*r nie jest L-wartością.
Ogólny podział typów danych
W pierwszym przybliżeniu wszelkie dostępne typy danych w języku C++ można podzielić na następujące grupy:
- Typy podstawowe. Wśród nich wyróżniamy typy ściśle powiązane z architekturą sprzętową komputera (logiczne, znakowe, całkowite, zmiennoprzecinkowe), typ wyliczeniowy i typ oznaczający brak wartości
- Typy pochodne dla typów podstawowych, czyli funkcje, wskaźniki i referencje
- Typy złożone, czyli tablice, struktury i klasy.

Wspomniany podział nie jest jedynym możliwym, wśród wspomnianych typów można na przykład wydzielić typy przeliczalne:
Do typów przeliczalnych zaliczamy typ logiczny, znakowy, całkowitoliczbowy i wyliczeniowy. Wyróżnienie typów przeliczalnych jest istotne z tego względu, że w niektórych instrukcjach (np. switch) zmienna sterująca musi być przeliczalna. Istnieje także wydzielona grupa typów arytmetycznych:
2.2. Typy proste
Typ logiczny
Nazwą typu logicznego jest bool. Typ może przechowywać tylko dwie wartości: fałsz (false) i prawda (true) uporządkowane w tej właśnie kolejności. Jest to typ arytmetyczny przeliczalny. Typ logiczny został wprowadzony jako nowy w języku C++ - w starym C jako logiczny fałsz przyjmowano wartość zero, jako prawdę wszystkie inne wartości. I tak też dokonywane jest rzutowanie w języku C++. W przypadku rzutowania zmiennej typu bool na typ liczbowy fałsz zostanie przedstawiony jako 0, natomiast prawda jako 1.
Fakt przechowywania tylko dwóch wartości sugerowałby wyjątkową oszczędność pamięci przy stosowaniu zmiennych tego typu – tak niestety jednak nie jest. Każda zmienna logiczna zajmuje w pamięci komputera co najmniej 1 bajt (a nie bit) – wynika to ze względów wydajności. W zdecydowanej większości architektur sprzętowych najmniejszą możliwą jednostką pamięci możliwą do przesłania między RAM a procesorem jest właśnie bajt.
Typ całkowity (stałoprzecinkowy)
Nazwą typu stałoprzecinkowego jest int. Typ int może przechowywać liczby całkowite (inaczej: stałoprzecinkowe) z pewnego określonego przedziału zależnego od połączenia procesora, systemu operacyjnego oraz kompilatora który wykorzystujecie.
W przypadku większości kompilatorów dla Windows, jeśli zdefiniujecie zmienną jako całkowitą, kompilator założy, że jest to 32-bitowa liczba ze znakiem. Zatem będziecie w stanie przechowywać w niej wartości z przedziału od -231 do 231-1, czyli od -2147483648 do 2147483647. Trochę ciężko zapamiętać, nie? Prościej skorzystać z faktu, że rzeczywista wartość maksymalna danego typu jest praktycznie zawsze dostępna przez odpowiednie makrodefinicje / szablony biblioteki standardowej. W przypadku int wartość minimalna i maksymalna są dostępne pod nazwami odpowiednio INT_MIN i INT_MAX, lub - lepiej - poprzez std::numeric_limits<int>::min i std::numeric_limits<int>::max.
Typ int występuje w kilku wariacjach, różniących się zakresem i faktem posiadania znaku lub nie. Dwie podstawowe modyfikacje to żądanie zmniejszenia ilości bitów i zakresu, czyli short, oraz żądanie zwiększenia liczby bitów i zakresu, czyli long. Drugi modyfikator to oznaczenie sposobu interpretacji najstarszego bitu w liczbie, czyli signed - oznacza że najstarszy bit oznacza znak liczby (innymi słowy – można przechowywać zarówno liczby dodatnie jak i ujemne) oraz unsigned - oznacza, że najstarszy bit wchodzi w skład liczby, i nie ma możliwości przechowywania wartości ujemnych.
Instnieje także typ long long - to jest long z modyfikatorem long
Jeśli nie podacie żadnego modyfikatora, C++ zakłada że typ jest typem zwykłym ze znakiem (czyli int jest równoważne signed int). Jeśli podacie tyko modyfikator typu, czyli short, long, signed lub unsigned – kompilator założy że zmienna będzie typu int. Wystarczy pisać np. long i będzie to oznaczało long int. Podobnie unsigned będzie oznaczać unsigned int.
1 = sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long)
co oznacza naszymi słowami, że każdy następny wielkościowo typ ma być nie mniejszy niż bezpośrednio go poprzedzający. Jak się można było spodziewać, tworzy to niezły misz-masz.
Aktualnie standard C++ definiuje, że char ma co najmniej 1 bajt, short oraz int co najmniej 2 bajty, long i long long co najmniej 4 bajty.
- Systemy 32 bitowe:
- LP32 or 2/4/4 (int 16 bitów, long i wskaźnik 32-bit) - Win16 API
- ILP32 or 4/4/4 (int, long i wskaźnik mają po 32 bity) - Win32 API, Unix and Unix-like systems (Linux, macOS)
- Systemy 64 bitowe:
- LLP64 or 4/4/8 (int i long 32 bity, wkaźnik - 64 bity) - Win64 API
- LP64 or 4/8/8 (int 32 bity, long o wskaźnik - 64 bity) - Unix and Unix-like systems (Linux, macOS)
Jak macie wątpliwości co do długości określonego typu na danej platformie, bądź też chcecie pewną długość wymusić - możecie stosować jawną deklarację długości korzystając z typów o stałej długości. Standard tutaje definiuje ich sporo, między innymi:
- int8_t, int16_t, int32_t, int64_t - typy ze znakiem
- uint8_t, uint16_t, uint32_t, uint64_t - typy bez znaku,
- int_fast16_t - zmienna będzie miała co najmniej 16 bitów, w rzeczywistości wykorzystana zostanie najszybrsza reprezentacja dopuszczalna przez daną architekturę, potencjalnie większa niż 16 bitów.
- intmax_t - najdłuższa wspierana wersja int na danej architekturze
- ....
Zainteresowanych po więcej szczegółów odsyłam do opisu standardu.
Do wykonywania obliczeń raczej stosujcie typy ze znakiem – podejście w stylu „zmienna x nie powinna przyjmować wartości ujemnej więc zdefiniuję ją jako unsigned int” może być przyczyną poważnych błędów – po przypisaniu do takiej zmiennej wartości ujemnej otrzymamy … brak błędu i bardzo dużą liczbę dodatnią. Rozsądnym stosowaniem typów bez znaku jest wykorzystywanie ich do indeksowania, a i to przy założeniu zachowania konsekwencji takiego podejścia (między innymi size_t z biblioteki standardowej jest akronimem typu bez znaku - co bywa kontestowane i krytykowane przez część społeczności programistów).
Oprócz samego definiowania zmiennych i stałych, istnieje także wiele sposobów zapisu literałów stałoprzecinkowych (wartości) w kodzie programu. Wartości możemy podawać dziesiętnie, ósemkowo lub szesnastkowo, wymuszając jednocześnie traktowanie liczby jako liczby ze znakiem lub bez. Liczby dziesiętne piszemy „normalnie”, liczby ósemkowe poprzedzamy cyfrą 0, a szesnastkowe parą znaków 0x. O ile z zapisem szesnastkowym nie ma problemów, to powinniście uważać na zapis ósemkowy:
int x{15};
int y{015};
if (x == y)
cout << "Tego sie spodziewamy";
else
cout << "a to jest";
15 i 015 to różne liczby!
| Zapis dziesiętny | Zapis ósemkowy | Zapis szesnastkowy |
| 0 | 00 | 0x0 |
| 2 | 02 | 0x2 |
| 83 | 0123 | 0x53 |
Dodatkowo, przy zapisie literałów możemy wymusić ich traktowanie jako liczby bez znaku (dodając U na końcu) lub jako liczby długiej (dodając L na końcu) lub bardzo długiej (LL). Przykładowe definicje zmiennych i stałych stałoprzecinkowych:
// zmienna całkowitoliczbowa ze znakiem
int a;
// zapis równoważny
signed int b;
// deklaracja zmiennej powiększonej:
extern long c;
// krótka liczba bez znaku
unsigned short d;
// inicjacja zmiennej liczbą w zapisie szesnastkowym
int e{0x0EF};
// inicjacja zmiennej liczbą w zapisie ósemkowym z wymuszeniem braku znaku
unsigned long f{0x12U};
Typ znakowy
W C++ występują dwa typy znakowe: char przeznaczony do trzymania znaków w kodowaniu ASCII (jednobajtowych), oraz wchar_t przeznaczony do trzymania znaków w kodowaniu UTF16 (dwubajtowy). Typ znakowy jest typem przeliczalnym i arytmetycznym.
W rzeczywistości C++ nie analizuje znaków w żaden sposób – przechowuje je, i operuje na nich tak jak na liczbach całkowitych. Dlatego też jest to typ arytmetyczny, i dlatego znaki możecie do siebie dodawać. Wartości znaków mogą być podawane jako literały znakowe (w pojedynczych apostrofach), albo bezpośrednio jako kody znaków. W przypadku podawania znaków jako literałów należy pamiętać o tym, że znak odwróconego ukośnika ma znaczenie specjalne, i służy do podawania kodów sterujących:
Typ znakowy można wykorzystywać również do operacji na małych liczbach całkowitych.
Pamiętajcie również, że istnieją w C++ dwa typy znakowe: signed char i unsigned char. Jest również typ char (bez modyfikatora) i jest on równoważny albo jednemu, albo drugiemu z nich (standard nie precyzuje, któremu) w związku z czym, nie należy zakładać nigdy sposobu, w jaki w danym kompilatorze wartości z zakresu -128 do -1 czy 128 do 255 będą traktowane przez typ char. W przypadku, gdy chce się używać zakresów typu char poza 0-127 należy jawnie określać char jako signed lub unsigned.
char z1{'a'}
char z2= '\t'
char z3 = 48;
wchar_t wz = L'ab';
Liczby rzeczywiste
Typ liczb rzeczywistych występuje (podobnie jak int) w kilku wersjach różniących się wielkością i zakresem wartości: float, double i long double. Jest typem arytmetycznym, lecz nie jest typem przeliczalnym.
Najmniejszy z typów rzeczywistych, float, nie powinien być przez Was traktowany jako podstawowy typ zmiennoprzecinkowy (mimo że wiele podręczników ciągle traktuje go w ten sposób). Najczęściej float posiada tylko 6 (sic!) cyfr znaczących - wszelkie obliczenia na takich wartościach obarczone są ogromną niedokładnością wynikłą z konieczności przybliżania. Dla porównania – double zazwyczaj ma 15-16 cyfr znaczących.
Literały stałoprzecinkowe można wprowadzać również na kilka sposobów, które pokażemy na przykładzie liczby 123.4567:
| Zapis | Typ |
|---|---|
| 123.4567 | double |
| 123.4567F lub 123.4567f | float |
| 123.4567L lub 123.4567l | long double |
| 1.234567e2 lub 123.4567E2 | double |
Wewnętrznie zmienna rzeczywista jest pamiętana w postaci dwu członów: podstawy a i wykładnika b i jest równa a * 10 b (a razy 10 do potęgi b), przy czym zarówno a jak i b muszą mieścić się w pewnym przedziale. Z tego faktu wynikają dwa ograniczenia - liczba bitów przeznaczona na pamiętanie podstawy a określa nam maksymalną możliwą precyzję zapamiętania liczby (ilość miejsc po przecinku), liczba bitów, jaka jest przeznaczona na pamiętanie b definiuje natomiast zakres zmienności zmiennej. Mówiąc inaczej, możecie zapamiętać dokładnie liczbę 0.000000000000001 oraz 100000000000000, natomiast nie można zapamiętać 100000000000000. 000000000000001 - część ułamkowa zostanie pominięta w tym przypadku. Co gorsza, jeśli dodacie te dwie liczby do siebie, w wyniku otrzymacie pierwszą z nich, a o spowodowanej poprzez zaokrąglenie niedokładności nie zostaniecie nawet poinformowani.
Ponadto liczby są pamiętane w systemie dwójkowym a nie dziesiętnym. Uruchomcie sobie poniższy program:
#include "iostream"
int main() {
for (double i=-1; i<1; i+=0.1)
std::cout << i << "\n";
return 0;
}
Zapewne zauważycie - że program nigdy nie wyświetli 0. Dlaczego - bo w systemie dwójkowym 1/10 jest liczbą niewymierną (nie ma skończonego rozwinięcia), podobnie jak 1/3 w systemie dziesiętnym ...
Sama dokładność typów zmiennoprzecinkowych także zależy od implementacji. Najczęściej spotykana postać zakłada, że:
- float jest pamiętany na 32 bitach (zgodnie z normą IEEE-754 32)
- double jest pamiętany w 64 bitach (zgodnie z normą IEEE-754 64)
- long double jest zależny od platformy, i może mieć 128 bitów (SPARC, ARM64), 80 bitów (większość implementacji dla procesorów rodziny x86-64), normalny format 64 bitowy analogiczny dla double (kompilator msvc firmy Microsoft)
Jako ciekawostkę możecie poczytać sobie o proponowanych w standardzie C++ 23 typach o stałej dokładności (ang. fixed-width floating-point types).
Przykłady definicji zmiennych rzeczywistych:
double da{1.23};
double db{.23};
double dc = 1.;
double dd = 1.2e-12;
Wartość minimalna i maksymalna liczb zmiennoprzecinkowych zazwyczaj nie jest definiowana tak, jak to miało miejsce w przypadku typów prostych. W zamian za to można uzyskać do niej dostęp poprzez szablon numeric_limits w sposób pokazany w przykładzie Rozmiary typów podstawowych.
Typ bez wartości (void)
Ostatnim z typów prostych które występują w języku C++ jest void – typ oznaczający brak wartości. Nie jest to typ ani arytmetyczny, ani przeliczalny, co więcej – nie można stworzyć zmiennej ani stałej typu void. Jego główne zastosowania to albo oznaczenie że funkcja wykorzystana jako wyrażenie nie zwraca żadnej wartości, oraz do rzutowania wskaźników. Oba przypadki zostaną dokładniej wyjaśnione w dalszej części podręcznika.
Wyliczenia
Wyliczenia w C++ są najczęściej wewnętrznie pamiętane jako jedna z odmian liczb całkowitych. Nie są typem stricte podstawowym, bo wymagają wcześniejszej definicji typu (przed pierwszym użyciem), natomiast też nie są typem użytkownika (nie można definiować w pełni ich zachowania). My zamieszczamy je wśród typów podstawowych.
Wyliczenie definiuje się przy wykorzystaniu słowa kluczowego enum, i są typem przeliczalnym, ale uwaga – nie zalicza się ich do typów arytmetycznych. Ogólnie wyliczenia są przewidziane do przechowywania ściśle określonego, zdefiniowanego przez użytkownika zbioru wartości. Przy czym trzeba pamiętać, że każde wyliczenie jest oddzielnym typem, który może – ale nie musi – mieć nazwę.
Domyślnie C++ przypisuje wartości liczbowe nazwom elementów wyliczenia kolejno, poczynając od zera i z krokiem 1, lecz programista może jawnie podać wartości numeryczne przypisywane stałym symbolicznym.

Istnieje możliwość przekształcenia wyliczenia na liczbę całkowitą i odwrotnie, lecz bez kontroli zakresu - wynik przekształcenia stałej liczbowej spoza zakresu jest niezdefiniowany.
Przykłady definicji i wykorzystania wyliczeń:
// wyliczenie nienazwane
enum {ala, kot, dwa_koty };
// wyliczenie nazwane
enum asta {la, vista };
// wyliczenie z określonym zakresem
enum eee {aaa = 3, zzz = 9 };
eee zmienna = eee(3); // ok
eee zmienna = eee(101); // źle
Współcześnie, zamiast starego enum zaleca się stosowanie enum class. Ogólnie zasady mapowania wartości przypisanych na nazwy pozostają bez zmian, natomiast zmieniono dwie cechy:
- w przypadku korzystania z enum class nie ma niejawnej konwersji na int
- nie można porównywać z int-ami, oraz z innymi wyliczeniami
- nie można inicjować wartością int
- nazwa wartości w nowych wyliczeniach może się powtarzać.
enum class Color { RED, GREEN, BLUE };
int main() {
Color c = Color::RED; //OK
c = BLUE; //Błąd!
int x = Color::RED; //Błąd!
}
Rozmiar i ograniczenia wybranych typów podstawowych
Poniższy program wyświetli Wam informację o wszystkich podstawowych typach arytmetycznych przeliczalnych na Waszej platformie.
#include "iostream"
#include "climits"
#include "numeric"
using namespace std;
volatile int char_min = CHAR_MIN;
int main()
{
cout << "Rozmiar typu bool: " << sizeof(bool) << " bajtow\n";
cout << "Liczba bitow do pamietania znaku: " << CHAR_BIT << '\n';
cout << "Rozmiar typu char: " << sizeof(char) << " bajtow\n";
/// stara składnia
cout << "Wartosci dla signed char: min: " << SCHAR_MIN << " max: " << SCHAR_MAX << '\n';
/// zalecana składnia
cout << "Wartosci dla unsigned char min: 0 max: " << (int)numeric_limits<unsigned char>::max() << '\n';
cout << "Domyslnym typem dla znakow jest ";
if (char_min < 0)
cout << "signed";
else if (char_min == 0)
cout << "unsigned";
else
cout << " ? dziwny jakis";
cout << "\n\n";
cout << "Rozmiar typu short int: " << sizeof(short) << " bajtow \n";
cout << "Wartosci dla signed short: min: " << numeric_limits<short>::min() << " max: " << numeric_limits<short>::max() << '\n';
cout << "Wartosci dla unsigned short min: 0 max: " << numeric_limits<unsigned short>::max() << "\n\n";
cout << "Rozmiar typu int: " << sizeof(int) << " bajtow\n";
cout << "Wartosci dla signed int: min: " << numeric_limits<int>::min() << " max: " << numeric_limits<int>::max() << '\n';
cout << "Wartosci dla nsigned int: min: 0 max: " << numeric_limits<int>::max() << "\n\n";
cout << "Rozmiar typu long int: " << sizeof(long) << " bajtow\n";
cout << "Wartosci dla signed long: min: " << numeric_limits<long>::min() << " max: " << numeric_limits<long>::max() << '\n';
cout << "Wartosci dla unsigned long: min: 0 max: " << numeric_limits<long>::max() << "\n\n";
cout << "Rozmiar typu long long: " << sizeof(long long) << " bajtow\n";
cout << "Wartosci dla signed long long: min: " << numeric_limits<long long>::min() << " max: " << numeric_limits<long long>::max() << '\n';
cout << "Wartosci dla unsigned long long: min: 0 max: " << numeric_limits<long long>::max() << "\n\n";
cout << "Rozmiar typu float: " << sizeof(float) << '\n';
cout << "Wartosci dla float: min: " << numeric_limits<float>::min();
cout << " max: " << numeric_limits<float>::max() << "\n\n";
cout << "Rozmiar typu double: " << sizeof(double) << '\n';
cout << "Wartości dla double: min: " << numeric_limits<double>::min();
cout << " max: " << numeric_limits<double>::max() << "\n\n";
cout << "Rozmiar typu long double: " << sizeof(long double) << '\n';
cout << "Wartosci dla long double: min: " << numeric_limits<long double>::min();
cout << " max: " << numeric_limits<long double>::max() << "\n\n";
return EXIT_SUCCESS;
}
3. Definicje zmiennych i ich zasięg
Zanim przejdziemy do opisywania typów pochodnych do podstawowych chciałbym powiedzieć coś więcej o deklaracjach i definicjach zmiennych. Same pojęcia wprowadziłem w poprzednim rozdziale – teraz pora na rozszerzenie podanych informacji w kontekście zmiennych.
Każda zmienna wymaga przydzielenia obszaru pamięci odpowiedniego dla niej. W C++ cała dostępna pamięć jest dzielona na kilka niezależnych obszarów (klas pamięci, ang. storage class). Obszar przeznaczony na zmienne lokalne zwyczajowo nazywa się stosem. Sam stos jest podzielony na dwie klasy pamięci: na zmienne globalne i lokalne. Każdy obiekt lokalny jest dostępny wyłącznie w kontekście, w którym został zadeklarowany, zaś jego czas życia jest od wejścia do kontekstu do wyjścia z niego.
Globalny zaś, deklarowany poza wszystkimi funkcjami, jest dostępny dla wszystkich funkcji. Jeszcze jedna różnica dotyczy inicjacji: zmienne typu prostego z kontekstu lokalnego nie są inicjowane wcale, natomiast pamięć przeznaczona na zmienne globalne powinna być inicjowana - czyli zmienne te są inicjowane abo przy wykorzystaniu domyślnego konstruktora (typy własne), albo zerując cały obszar pamięci przyznany zmiennej globalnej (typy proste).
Nie zainicjalizowana zmienna posiada wartość taką, jaka się jej trafiła w przeznaczonym dla niej kawałku pamięci. Ważną informacją jest fakt, że wyniki wszystkich operacji na takich wartościach (z wyjątkiem przypisania) są niezdefiniowane. Wartość taką nazywamy wartością osobliwą (ang. singular). Wartość osobliwa to po prostu taka wartość o której nie tylko nic nie wiemy, ale też nad którą program nie ma żadnej kontroli; innymi słowy, jest to wartość, której nikt nie nadał.
{
int x, y;
x = y;
}
Inicjacja zmiennych
W języku C++ mamy kilka wyrażeń umożliwiających inicjację zmiennych. Zasadniczo - działają one podobnie, a wielość form wynika raczej z uwarunkować historycznych.
double x=2.2;
double y(3.3);
double z{4.4}
Pierwsza forma ze znakiem przypisania = jest nieco myląca - w tym wypadku następuje inicjalizacja, a nie przypisanie zmiennej. Ta forma wywodzi się jeszcze z C.
Druga forma - z nawiasami okrągłymi - została wprowadzona w C++ - ze względu na składniowe podobieństwo do wykorzystania konstruktora. Niemniej znaczenie pozostało to samo co wykorzystanie =, ogólnie też zapis "kostruktorowy" nie przyjął się szeroko w społeczności.
Trzecia forma wprowadzona została w standardzie C++11. Znaczeniowo różni się ona od dwóch poprzednich - mianowicie, zabrania konwersji zawężających - czyli powodujących utratę informacji. Popatrzcie na poniższy kod:
int c1=1.7; // nie ma błędu, w c1 jest 1
int c2(2.7); // nie ma błędu, w c2 jest 2
int c3{3.7}; // to jest błąd
unsigned short c4{-1}; // to też
unsigned short c5{1e7}; // to też
Ogólnie - zaleca się jawne inicjowanie zmiennych - o ile to tylko jest możliwe. Kompilatory powinny generować ostrzeżenia o zmiennych które nie są zainicjowane - warto je czytać, i eliminować z własnego kodu.
3.1. Zasięg widoczności
W poprzednim rozdziale wspomniałem o „dostępności zmiennej w kontekście” … hem … a co to znaczy?
W C++ każda nazwa może być wykorzystywana jedynie w tej części programu, gdzie jest znana. Wszędzie znane są jedynie nazwy (identyfikatory) zdefiniowane w przestrzeni globalnej, ciągle przy zastrzeżeniu obowiązywania zasady predeklaracji.
Ogólne zasady widoczności można streścić następująco:
- nazwy globalne są widoczne od miejsca deklaracji do końca pliku. Globalnie widoczne są nazwy deklarowane poza funkcją, klasą i przestrzenią nazw,
- nazwy lokalne są widoczne wewnątrz bloku { },
- nazwy z przestrzeni nazw są widoczne wewnątrz tej przestrzeni,
- nazwy należące do klasy są widoczne wewnątrz klasy.
Kompilator C++ czyta plik z kodem od góry do dołu. Każdą napotkaną nazwę (identyfikator) próbuje rozszyfrować korzystając kolejno z lokalnej przestrzeni nazw, następnie z klasy, klas podstawowych dla danej klasy, przestrzeni nazw bieżących i podstawowych, oraz przestrzeni globalnej – i przestaje szukać po znalezieniu pierwszego dopasowania.
Z takiego cyklu działania wynika kolejny mechanizm: przysłaniania nazw. Każda nazwa może być wykorzystana tylko raz – ale w jednej przestrzeni nazw. Postawienie nawiasów klamrowych otwiera nową przestrzeń nazw. Popatrzcie na poniższy kod:
int x; // x zasięg nazw globalny
int main(int argc, char *argv[])
{
// x w zasięgu nazw funkcji main – inna zmienna niż globalne x
int x = 1;
{
// x w zasięgu nazw wewnętrznym – inne niż dwa dotychczasowe x
int x = 2;
cout << x << endl;
// odwołanie do globalnego x
::x = x + 2;
}
cout << x << endl;
cout << ::x << endl;
{
// tej linii nie da się wykonać – definicja x przykryła x z main
int x = x;
}
}
void f()
{
int y = x; // globalne x
int x = 22; // lokalne x
y = x; // lokalne x
}
Nazwa x jest wykorzystywana wielokrotnie, przy czym w zależności od kontekstu - wskazuje na różne zmienne...
3.2. Czas życia zmiennej
Pojęcie czasu życia zmiennej można zdefiniować następująco:
Czas życia zmiennej jest równy czasowi wykonania programu jedynie w przypadku zmiennych globalnych. Zmienne globalne są inicjowane przed uruchomieniem, kasowane po zakończeniu programu.
Zmienne lokalne są tworzone w momencie ich definicji, natomiast kasowane w momencie opuszczenia zasięgu w którym mogłyby być widoczne (a więc do nawiasu klamrowego zamykającego). Po skasowaniu zmiennej nie ma już możliwości odczytania jej zawartości. Zarządzanie czasem życia zmiennych statycznych jest w pełni automatyczne.
Zainteresowani mogą uruchomić poniższy programik – dzięki własnej klasie i jej konstruktorowi i destruktorowi informacje o tworzeniu i kasowaniu zmiennej będzie wyświetlana na ekranie.
#include <cstdlib>
#include <iostream>
using namespace std;
class CMoja {
public:
CMoja() { cout << "Tworze\n"; }
~CMoja() { cout << "Kasuje\n"; }
};
CMoja moja;
void testMoja() {
cout << "W funkcji: \n";
CMoja a;
cout << "Teraz dostepna:\n";
}
int main(int argc, char *argv[]) {
cout << "Przed funkcja: \n";
testMoja();
cout << "po funkcji: \n";
cout << "przed definicja\n";
CMoja b;
cout << "koniec programu\n";
system("PAUSE");
return EXIT_SUCCESS;
}
3.3. Modyfikatory deklaracji zmiennych i stałych
Umieszczaniem zmiennych w pamięci oraz ich zachowaniem można w pewien ograniczony sposób sterować. Odpowiednie właściwości uzyskujemy przez modyfikatory podawane w momencie definicji zmiennej:
- register – oznacza, że zmienna ma być trzymana w rejestrze procesora, a nie w pamięci. Co prawda znów mamy tu do czynienia z wyrażeniem woli programisty – ostateczna decyzja zostanie podjęta przez kompilator, ale przynajmniej przekazujemy mu wskazówki. Przy czym wskazówka zostanie odrzucona, jeśli … choć raz spróbujemy uzyskać wskaźnik (adres) takiej zmiennej.
- const – oznacza, że obiekt jest stały – nie będzie można zmieniać jego wartości. Konsekwencją tego jest obowiązek zainicjowania go (podania wartości początkowej, której nie będzie można zmienić).
- volatile – oznacza, że nie ma się wyłączności do podanego obiektu (tzn. może być to rejestr sprzętowy komputera albo zmienna używana przez inny wątek). W praktyce takie zmienne kompilator pomija w procesie optymalizacji dostępu – każdy odczyt wartości zmiennej musi się wiązać z jej ponownym pobraniem z pamięci operacyjnej.
- static – w ogólności oznacza, że obiekt taki istnieje przez cały czas, niezależnie od zasięgu, który go używa (zabrania się w ten sposób kasowania zmiennych lokalnych). Jeśli static zastosujemy do zmiennej lokalnej w funkcji - to każde nowe wywołanie funkcji będzie miało dostęp do jej wartości z poprzednich wywołań tej funkcji. Dla zmiennych które i tak już istnieją cały czas (zmiennych globalnych) oznacza z kolei zniesienie zewnętrznego symbolu obiektu (tzn. poza bieżącą jednostką kompilacji, czyli plikiem, nic nie może z tego korzystać). Trochę niemiłe zachowanie – bo mamy rozszerzenie dostępu do zmiennych lokalnych, i zawężenie dla zmiennych globalnych. W przypadku funkcji static ma podobne znaczenie jak w przypadku stałych - przekształca funkcję w funkcję lokalną, bez możliwości korzystania z niej poza danym modułem / jednostką kompilacji.
- extern – o nim więcej za chwilę.
Modyfikatory static i extern wzajemnie się wykluczają, zwłaszcza, że oznaczają dwie całkiem przeciwne właściwości.
Przyjrzyjmy się dokładniej zmiennym statycznym. Taką zmienną można zainicjalizować, jednak jest to inicjalizacja podobna do inicjalizacji zmiennej globalnej - wykonuje się tylko raz. Jeśli tego nie zrobimy, przypisana jej będzie wartość zerowa. W poniższym przykładzie wykorzystaliśmy zmienną statyczną do zliczania i wyświetlania liczby wywołań funkcji:
#include <iostream>
using namespace std;
void mojaFunkcja(int a, int b) {
// zmienna statyczna zostanie zainicjowana raz i tylko raz
// przed uruchomieniem programu, niezależnie od wywołań
// funkcji
static int liczbaWolan = 0;
cout << "Wywolan: " << ++liczbaWolan << " argumenty: " << a << ", " << "b\n";
}
int main() {
mojaFunkcja(1, 2);
mojaFunkcja(3, 4);
mojaFunkcja(5, 6);
mojaFunkcja(7, 8);
return 0;
}
Słowo static ma także specjalne znaczenie w odniesieniu do struktur – będzie omówione później.
W przypadku słowa kluczowego extern również możemy się spodziewać dwóch znaczeń:
- jeśli poprzedza deklarację zmiennej (globalnej lub lokalnej) lub stałej, ale nie zainicjalizowanej, oznacza to typową deklarację. Można spotkać również funkcje poprzedzone tym modyfikatorem, ale nie ma on wtedy żadnego znaczenia.
- jeśli poprzedza deklarację stałej zainicjalizowanej, oznacza to, że taka stała ma być również eksportowana do innych plików. Z kolei extern przed stałą niezainicjalizowaną oznacza jej import na etapie łączenia (linkowania) programu.
Tu ważna uwaga nt. różnicy traktowania stałych przez C i C++: domyślnie zmienne globalne w C++ są w pamięci globalnej, co oznacza możliwość dostępu do nich z innych plików (jednostek kompilacji). W C taka sama sytuacja dotyczy stałych, natomiast w C++ stałe domyślnie są dostępne tylko w danym pliku (tak jakby były zadeklarowane jednocześnie z modyfikatorem static).
extern "C" {
#include <clib.h>
}
4. Typy pochodne
Typy pochodne do typów podstawowych pozwalają na operowanie na adresach, łączenie wielu typów podstawowych, czy też finalnie – na tworzenie kompletnych własnych typów danych. Tworzeniem zupełnych typów danych zajmiemy się po zakończeniu omawiania składni.
4.1. Wskaźniki
Wskaźniki historycznie wywodzą się z niskopoziomowych elementów języka C, ściśle powiązanych ze sprzętem. Wtedy to wskaźnik był fizycznym adresem w pamięci RAM. W C++ do tej pory jest tak często traktowany – choć często nie jest to prawdą. Po pierwsze – większość kompilatorów operuje adresami wirtualnymi w odniesieniu do typów prostych. Po drugie – w przypadku obiektów złożonych nawet ta właściwość (adres wirtualny) nie zawsze musi być zachowana, jeden obiekt może mieć wiele adresów wirtualnych. Tak więc zdecydowanie lepszym przybliżeniem roli wskaźnika będzie następująca definicja:
Dzięki temu jesteście w stanie rozróżnić dwie zmienne tego samego typu i mające tą samą wartość.
Mimo że tożsamość między wskaźnikami a fizycznymi adresami nie jest prawdziwa, to w przypadku przechowywania podstawowych typów danych w pierwszym przybliżeniu możemy przyjąć, że zmienna wskaźnikowa przechowuje w pamięci adres elementu danego typu (nie sam element). Skoro przechowuje adres - to sama w rzeczywistości jest zmienną statyczną przechowującą wartość całkowitą, unikalną dla każdego obiektu (bytu) w programie. Rozmiar tej zmiennej jest zależny od architektury, najczęściej jednak na systemach 32 bitowych możecie spodziewać się 4 bajtów, na systemach 64 bitowych - 8 bajtów. Skoro wskaźnik sam w sobie jest zmienną, to oznacza że i on posiada tożsamość, vide - można tworzyć wskaźniki do wskaźników. Podobnie z wszelkimi innymi bytami – możliwe (często nawet wskazane) jest tworzenie wskaźników do obiektów i funkcji.
Wartością zerową, pokazującą „adres donikąd” lub też „byt który nie istnieje” jest nullptr, w starszych wersjach standardu także NULL lub po prostu 0.
Wskaźniki definiujemy identycznie jak zmienne danego typu – fakt definiowania lub deklarowania wskaźnika a nie zmiennej statycznej oznaczamy podając gwiazdkę przed nazwą zmiennej. Przykłady definicji zmiennych wskaźnikowych:
char c = 'a';
char *p = &c; // wskaźnik na c
int *pInt; // wskaźnik na int
int **ppInt; // wskaźnik na wskaźnik na int
int *pInt[10]; // wskaźnik na tablicę int
int ***pppInt; // wskaźnik na wskaźnik na wskaźnik na int
int (*fp)(int *p); // wskaźnik na funkcję
void (*SetMes)(void *_func); // wskaźnik na wskaźnik na funkcję
Pierwsze dwie linie powyższego kodu pokazują nam wzajemną zależność między wskaźnikiem a zmienną – c jest zmienną statyczną, natomiast p – wskaźnikiem do niej. Do wartości zmiennej można się dobrać zarówno przez wskaźnik p jak i bezpośrednio korzystając z nazwy c, natomiast jednoznacznie zidentyfikować o jaką zmienną chodzi można tylko poprzez p.
Operatory pobrania adresu (referencji) oraz wyłuskania
Ze wskaźnikami wiążą się dwa operatory ułatwiające, czy też umożliwiające pracę ze zmiennymi tego typu. Aby uzyskać wskaźnik do zmiennej – stosuje się operator referencji &, aby uzyskać dostęp do wartości wskazywanej, wykorzystuje się operator wyłuskania *:
int s1 = 5, s2 = 2;
int *p1, *p2;
p1 = &s1; // p1 wskazuje na zmienną s1
p2 = &s2; // p2 wskazuje na zmienną s2
// wydrukuje kolejno – wskaźnik (adres) zmiennej s2, oraz wartość s2
cout << p1 << "\t" << *p1 << endl;
// zwiększa wartość wskazywaną (teraz s1)
(*p1)++;
cout << s1 << endl;
// kopiowanie wartości wskazywanej (teraz s1) do s2
s2 = *p1;
s2++;
Arytmetyka wskaźników
W C++ wskaźniki można do siebie dodawać, wykorzystywać jako przełącznik w instrukcji switch, mnożyć, inkrementować itd. - typ wskaźnikowy jest typem przeliczalnym i arytmetycznym. W większości przypadków wyniki takich operacji są zgodne z intuicyjnym wyobrażeniem efektu działania na wskaźniku jak na adresie. W związku z tym możemy traktować operacje na wskaźnikach tak jak bezpośrednie operacje na pamięci RAM, z pominięciem jakiejkolwiek kontroli …. tak – C++ zakłada, że programista jest człowiekiem inteligentnym – nie zawiedźcie więc tego zaufania, i nie korzystajcie z możliwości takich operacji dopóki na pewno nie wiecie co robicie, i co przez to chcecie osiągnąć!
W przypadku arytmetyki na wskaźnikach działanie operatorów arytmetycznych jest „inteligentne”, tzn – jeśli mamy do czynienia ze zmienną jednobajtową (char) to zwiększenie wskaźnika o 1 przeniesie nas do następnego adresu (zwiększy wartość wskaźnika fizycznie o 1). Jeśli zdefiniowaliśmy wskaźnik na liczbę całkowitą (4 bajty) – to zwiększenie wskaźnika o 1 spowoduje zmianę adresu o 4 (bo skaczemy 4 bajty do przodu). Takie zachowanie wskaźników jest bardzo przydatne przy operacjach wykonywanych na tablicach – ale o tym za chwilę.
Na razie skupmy się na pozostałych aspektach arytmetyki wskaźników. Czasem w trakcie operacji na nich pewna szczątkowa kontrola typów jest zachowana. Przykładowo – nie można przypisać bezpośrednio wartości wskaźnika na char do wskaźnika na int:
char *a;
int *b;
// źle
b = a;
// dobrze formalnie – ale może być przyczyną strasznych błędów!
b = (int*)a;
Można natomiast dokonać jawnego rzutowania – i przypisanie zadziała … choć w pamięci nie zostanie zmieniony typ zmiennej a na int, i nie zostanie przydzielona dodatkowa pamięć na nią. Jeśli teraz chcielibyśmy do zmiennej b jakąś wartość, to zniszczymy strukturę pamięci danych naszego programu, i jego zachowanie stanie się niezdefiniowane.
Tak więc powtórzymy jeszcze raz – należy wiedzieć co się robi. Lecz jak już wiecie co robicie – to zauważcie, do czego może zostać wykorzystany typ void (a dokładniej – wskaźnik na ten typ). Skoro wiadomo, że zmienne typu void nie istnieją, to powszechnie wykorzystuje się go do porównywania adresów zmiennych dowolnego typu (ich tożsamości), rzutowania zmiennych, i przekazywania dowolnych struktur danych i funkcji między podprogramami. Pojawienie się zmiennej lub argumentu typu ... void *cos_tam ... jest informacją przekazywaną przez jednego programiście innym programistom: „.. wyłączam kontrolę typów – musisz wiedzieć jak obsłużyć mój kod, i mechanizmy języka w tym Ci nie pomogą ...”.
Wskaźniki i stałe
W przypadku pracy ze wskaźnikami musicie pamiętać, że zawsze mamy do czynienia z dwoma różnymi zmiennymi – jedną z nich jest sam wskaźnik, drugą jest zmienna wskazywana. Wykorzystanie const przy operacjach na wskaźnikach czyni stałym obiekt (zmienną) wskazywany, natomiast w żaden sposób nie wpływa na możliwość czy brak możliwości zmiany wskaźnika (adresu). Dopiero jak podamy *const - stały staje się wskaźnik. To rozróżnienie jest wykorzystywane głównie przy deklarowaniu parametrów funkcji.
char a, b;
// stały wskaźnik do znaku – nie można zmienić wskaźnika,
// natomiast można zmienić znak
char *const cp = &a;
// wskaźnik do stałego znaku – znaku nie można zmienić,
// można zmienić wskaźnik
char const* cp;
// forma alternatywna wskaźnika do stałego znaku
const char* cp;
// stały wskaźnik do stałego znaku
const char *const cp = &a;
// przykłady zastosowań
char n[] = "czem";
const char *p = n;
// to nie zadziała
p[1] = 'a';
// natomiast to tak
p = &b
4.2. Referencje
Pojęciem związanym z pojęciem wskaźnika jest referencja. W pierwszym przybliżeniu możecie ją rozumieć jako inną nazwę obiektu – czyli faktycznie dostajemy pewną analogię do wskaźników – możliwość odwołania się do jednego obiektu poprzez kilka nazw.
W praktyce możemy tworzyć wiele zmiennych odpowiadających temu samemu obszarowi pamięci, takich „zmiennych wirtualnych” - istniejących w kodzie programu jako nazwa, lecz nie posiadających własnej tożsamości – i to są właśnie referencje. W przeciwieństwie do wskaźników referencje nie są rzeczywistymi zmiennymi, i obszar ich zastosowań jest zdecydowanie bardziej ograniczony w stosunku do wskaźników. Ich główne zastosowanie to specyfikowanie argumentów funkcji – o tym będzie mowa w dalszej części podręcznika. Fachowo często się mówi o referencjach jako o stałym wskaźniku z niejawnym operatorem adresowania pośredniego. Brzmi skomplikowanie, ale dużo nam mówi o charakterze referencji, między innymi o jej podobieństwie do stałych. Przy czym pamiętajcie - w przypadku referencji stały oznacza tylko że nie można zmienić wskazywanego obiektu - jego tożsamości. Natomiast wartość przechowywaną we wskazywanym obiekcie można zmieniać.
Korzystając z referencji pamiętajcie by trzymać się kilku zasad:
- Każda referencja musi zostać zainicjowana w momencie definicji – podobnie jak stałe
- Wskazywanego obiektu dla referencji nie da się zmienić – raz zdefiniowana wskazuje ciągle na tą samą zmienną.
- Operatory zawsze działają na wartości – nigdy na referencji – inaczej niż we wskaźnikach, ale dokładnie jak w przypadku stałych wskaźników
- Optymalizacja we współczesnych kompilatorach często prowadzi do usunięcia obiektów reprezentujących referencje – podobnie jak w przypadku stałych
- Referencja bez modyfikatora const musi zostać zainicjowana L-wartością - stała referencja może być inicjowana wartością stałą (nie l-wartością).
Przykłady definiowania referencji:
int s1 = 5, s2;
int& r1{s1};
s2 = r1;
r1 = 6;
r1++;
// źle !
int& r3 = 1;
int& r4;
// dobrze
extern int& r2;
const double& r5=1;
5. Typy złożone
Część z typów złożone w C++ możemy traktować jako kontenery na inne elementy (w tym typy proste) - i takim podejściem się teraz zajmiemy. Zanim przejdziemy do opisów detalicznych poszczególnych typów złożonych - poznajmy ogólne zasady operowania kontenerami w C++. Co to jest takiego kontener? Jest to po prostu taki obiekt, który może w sobie zawierać inne obiekty. Zasady posługiwania się kontenerami w C++ (ogólne) są następujące:
- Każdy kontener może zawierać w sobie jakieś elementy (może być również pusty, choć nie każdy - puste tablice nie są dozwolone przez standard).
- Do każdego elementu umieszczonego w kontenerze możemy się dobrać poprzez specjalną wartość, zwaną iteratorem. Wartość ta pozwala nam na poruszanie się po kontenerze.
- Każdy kontener ma zdefiniowane odpowiednie wartości dla iteratorów stanowiące jego początek i koniec.
- Na iteratorze zawsze można wykonać operację pobrania następnego elementu (iterator typu forward).
- Dla niektórych typów kontenerów istnieje również możliwość pobrania poprzedniego elementu (iterator reverse) lub też możliwości przejścia na dowolny element w jednym kroku (iterator typu free-access).
W C++ istnieją różne rodzaje kontenerów - większość z nich jest dostępna jako klasy biblioteki standardowych. Jedynym „wbudowanym” (rdzennym) typem jest w C++ tablica – gdzie iteratorem jest wskaźnik, i jest to iterator o swobodnym dostępie. Tablice zostaną omówione teraz, pozostałe kontenery w dalszej części podręcznika.
5.1. Tablice
Tablica w C++ to ciąg obiektów jednego typu zajmujący ciągły obszar pamięci. Wielkość tablicy musi być stałą, znaną w czasie kompilacji (nie dotyczy tablic tworzonych dynamicznie za pomocą operatora new). Wymiar musi być znany na etapie kompilacji, ale nie musi być koniecznie jawnie podany – jeśli tylko da się go obliczyć na podstawie wartości inicjujących.
Tablica tworzona jest jako typ pochodny pomocą operatora [] z:
- typów fundamentalnych (oprócz void)
- typów wyliczeniowych
- wskaźników
- tablic (tablice wielowymiarowe)
- klas
Przykłady definicji tablic:
// trójelementowa tablica liczb zmiennoprzecinkowych
float v[3];
// pięcioelementowa tablica wskaźników na znak
char *a[5];
// dwuwymiarowa tablica liczb całkowitych
int d2[2][10];
// trójwymiarowa tablica liczb całkowitych
int d3[2][2][2];
// obliczenie wielkości tablicy z listy inicjującej
int v1[] = { 1, 2, 3, 4, 5 };
// jeśli lista inicjująca jest zbyt krótka – zostanie automatycznie
// dopełniona zerami
int v2[10] {1, 2};
// tablica jest równoważna wskaźnikowi na pierwszy element.
int *pInt = v1;
Jak wspomnieliśmy, iteratorem dla tablicy w C++ jest wskaźnik. Zmienna tablicowa jest tożsama ze wskaźnikiem na jej pierwszy element, i jeśli wrócicie do arytmetyki wskaźników – jasne też okaże się, w jaki sposób można poruszać się po tablicy w alternatywny sposób. Alternatywny do klasycznego indeksowania z wykorzystaniem operatora [] - którym zajmiemy się na początek.
Ogólnie dostęp do i-tego elementu tablicy można uzyskać poprzez podanie jego indeksu w nawiasach kwadratowych po nazwie zmiennej, przy czym pamiętajcie:
We wbudowanym typie tablicowym indeksami są zawsze liczby całkowite, przy czym, co również jest bardzo istotne:
Brak kontroli zakresu jest charakterystyczny nie tylko dla dostępu indeksowanego, ale także dla dostępu typu iteratorowego.
Oba podejścia do dostępu do elementów są w praktyce równoważne. Czasem możecie spotkać określenia że jeden jest szybszy czy drugi bardziej elegancki – w praktyce dzięki optymalizacjom kompilatorów różnice w czasie dostępu są pomijalne, natomiast co do elegancji – zadecydujcie sami:
int main()
{
int t[20];
// klasycznie (dostęp indeksowany)
for (int i = 0; i < 20; ++i)
tab[i] = 1;
// alternatywnie (dostęp iteratorowy)
for (int *x = t; x != t + 20;)
*x++ = 2;
// od C++11 - możliwe jest też stosowanie pętli zakresowej
for (auto& elem : tab)
cout << elem;
}
Statyczne tablice wielowymiarowe także są jednolitym obszarem pamięci. Jedynie zmienia się interpretacja znaczenia operatorów []. W przypadku tablic wielowymiarowych kod:
int tab[lr][lk];
...
tab[i][j] = 12;
oznacza: weź wartość spod indeksu i*lk+j z jednowymiarowej tablicy o wymiarze lk*lr. Dlatego też - nie ma różnicy między jednowymiarową a wielowymiarową tablicą statyczną.
Zaprezentowane wyżej tablice statycznie są przechowywane na stosie. Istotnym ograniczeniem takiego podejścia jest konieczność obliczenia rozmiaru tablicy na etapie jej kompilacji. Jeśli rozmiar tablicy na tym etapie nie jest znany, koniecznym staje się wykorzystanie dynamicznej alokacji tablic. Do tego celu wykorzystuje się operator new[rozmiar], z rozmiarem tablicy podawanym wewnątrz nawiasów kwadratowych. Tak utworzone tablice następnie muszą być również ręcznie usunięte za pomocą operatora delete[]. Po utworzeniu i przed usunięciem jednowymiarowe tablice statyczne są w pełni równoważne (mogą być stosowane zamiennie) z jednowymiarowymi tablicami statycznymi.
Dynamiczne i statyczne tworzenie tablic jest możliwe również dla tablic wielowymiarowych, przy czym w tym przypadku przestaje obowiązywać równoważność tablic statycznych i dynamicznych. Wielowymiarowa tablica statyczna jest jednolitym obszarem pamięci, a dostęp do odpowiednich elementów tej tablicy jest możliwy dzięki wewnętrznemu przeliczaniu indeksów dwuwymiarowych na indeks jednowymiarowy. W przypadku tablic tworzonych dynamicznie mamy do czynienia z rzeczywistą „tablicą tablic”, co pokazuje choćby kod konieczny do utworzenia i skasowania takiej tablicy:
// dynamiczne tworzenie
double **a;
a = new double[w];
for (int i=0; i< w; i++)
a[i] = new double[k];
...
a[i][j] = 1.5;
...
for (int i=0; i<w; i++)
delete[] a[i];
delete[] a;
Dokładniejszy opis działań w przypadku dynamicznego tworzenia i kasowania tablicy zamieściliśmy na poniższym rysunku:

5.2. Napisy
W C++ podstawowym typem napisowym jest string, tyle że nie jest to część języka, lecz jeden z kontenerów z biblioteki STL. W starym C wbudowanego typu napisowego w ogóle nie było - napisy były przechowywane i przetwarzane jako tablica o elementach typu char. Dzięki temu tablicę taką możemy inicjalizować stałą napisową:
char napis[20] = "Lolek"; // równoważne { 'L','o','l','e','k','\0' }
Zwróćcie uwagę na ostatni znak w tablicy – zawsze powinien być to znak o kodzie 0, podany jawnie lub niejawnie. Takie podejście jest istotą tak zwanych "null-terminated strings" – techniki bardzo niewygodnej, lecz przez tak długi czas będącej standardem, że nie można jej pominąć do dziś.
Wymieńmy niedogodności:
- skoro nie można bezpośrednio kopiować tablic, to nie można także bezpośrednio kopiować napisów,
- nie można ich porównywać (w większości innych języków istnieje domyślny operator dokonujący porównania leksykalnego),
- nie ma także domyślnego działania operatora dodawania, który powinien łączyć napisy,
- do tablicy musimy wpisywać napisy literka po literce (używa się do tego odpowiednich funkcji, pochodzących z biblioteki standardowej C, co nie zmienia braku naturalności takiego podejścia),
- często też powstają problemy z terminatorem napisu – znakiem o kodzie 0. Wstawienie go wewnątrz napisu powodowało skrócenie go do miejsca gdzie było wstawione 0.
Wszystkich wspomnianych wad pozbawiony jest typ string – lecz jak wspomnieliśmy – nie jest możliwe zupełne pominięcie go, choćby dlatego, że literały napisowe są zamieniane na stałe „null-terminated strings”
5.3. Struktury
W przeciwieństwie do tablic struktury to zbiór elementów, które różnią się typem, natomiast powinny pozostawać ze sobą w związku logicznym. Ze względu na wprowadzenie w C++ pojęcia klasy, znaczenie czystych struktur zdecydowanie zmalało. W zasadzie w C++ można traktować strukturę jako zdegenerowaną klasę. Zdegenerowaną – bo pozbawioną kontroli dostępu, ze wszystkimi polami i metodami publicznymi. Napisałem metodami – i to nie jest przeoczenie. W C++ struktura może mieć metody, a nie tylko pola.
Struktury definiujemy przy wykorzystaniu słowa kluczowego struct, następnie w nawiasach klamrowych podajemy opis pól i metod. Istnieją dwa ogólne schematy definicji – struktura nazwana i nienazwana. Zastosowanie struktur nienazwanych ogranicza się do tworzenia okazjonalnych zmiennych strukturalnych – osobiście rzadko widzę potrzebę ich stosowania.
Przykłady definicji struktur:
// struktura nazwana
struct costam {
int a;
char b;
double c;
} ct1;
costam ct2, ct3 =
{ 10, 'a', 3.5 };
// struktura nienazwana
struct {
int a1, a2;
double a3;
} ala;
// struktura nazwana z odwołaniem rekurencyjnym
struct struktura {
double a;
char nn[5];
costam ct;
struktura *nast;
};
Z punktu widzenia składni języka z definicją typów strukturalnych wiążą się pewne nie zawsze jasne aspekty. Po pierwsze – za nawiasem klamrowym zamykającym każdą strukturę musi znajdować się średnik – inaczej niż w przypadku innego stosowania nawiasów klamrowych. Dla każdej struktury zostanie automatycznie wygenerowany zestaw specyficznych metod: kontruktor domyślny, kopiujący i przenoszący, operator przypisania i przeniesienia oraz destruktor. O znaczeniu tych metod dowiecie się później.
Można mieszać ze sobą (osadzać jedne w drugich) struktury i tablice, lecz – uwaga – w przypadku osadzenia tablicy w strukturze domyślny, wygenerowany operator przypisania i konstruktor kopiujący przestanią działać prawidłowo! Wykonywane domyślnie kopiowanie jest płytkie - skopiowana zostanie jedynie wartość adresu tablicy, a nie sama tablica.
Kompilator musi mieć możliwość określenia wielkości każdego pola definiowanej struktury, żeby możliwe stało się obliczenie jej zapotrzebowania na pamięć. Lecz kto pomyśli, że rozmiar struktury jest równy sumie rozmiarów jej pól – może się srodze zawieść.
To niemiłe zachowanie jest spowodowane różnymi ograniczeniami i optymalizacjami dostępu do pamięci w różnych systemach operacyjnych.
Dostęp do pól jest możliwy poprzez operator wyłuskania (kropka) oraz desygnator nazwy pola. W przypadku stosowania wskaźników do struktur, obowiązują w zasadzie te same zasady i ograniczenia co w przypadku wskaźników do pól prostych. Zmienia się jedynie postać postać operatora wyłuskania na ->. Uważajcie na jeszcze jedną nieciekawą cechę - dwie struktury nie są sobie równoważne nawet jeśli mają identyczną definicję. Dla porządku jeszcze wspomnę, że nie ma jakiegokolwiek automatycznego rzutowania typów, ani z/na typy proste, ani z / na inne typy złożone, oraz że nazwy pól nie mogą się powtarzać.
Struktura może mieć natomiast pola statyczne – pole takie, podobnie jak w przypadku klas – jest jedno dla wszystkich instancji struktury. Możecie je traktować jako zmienną globalną zdefiniowaną w przestrzeni nazw struktury.
5.4. Unie
Unie z punktu widzenia kompilatora są bardzo podobne do struktur. Główna różnica polega na tym, że o ile w przypadku struktur każde kolejne pole jest alokowane w innym miejscu pamięci, o tyle w przypadku unii wszystkie pola są alokowane w tym samym obszarze pamięci, i współdzielą swoją wewnętrzną tożsamość. Oczywiście - powoduje to, iż w danym czasie w unii można przechowywać tylko jeden typ wartości (tylko jedno pole).
C++ nie sprawdza, co w danym obszarze jest zapisane - zostawiono to programiście. Natomiast sam fakt że zostawiono - nie zwalnia Was z tego. Nie powinno się odczytywać z unii typu, który nie został tam zapisany. Unie powstały w celu współużywania tej samej pamięci - stosujemy je gdy wiemy, że w danym momencie możliwe jest istnienie tylko jednego typu obiektu z podanego zbioru, a nie po to, by dostać się do pamięci jednego obiektu poprzez interfejs innego obiektu (tzw type-punning). To jest różnica między C++ a C. Stare C pozwalało na odczyt nieaktywnego pola unii (czyli nie tego, które ostatnio zostało zapisane). W C++ jest to zachowanie niezdefiniowane.
union unia
{
int calk;
char znak[];
};
unia u1;
u1.znak[0] = 'x'; // teraz w unii jest tablica znaków
u1.calk = 10 + 0x0f00; // teraz jest liczba
Stworzyliśmy w ten sposób jednolity obszar pamięci, który możemy interpretować (w zależności od odwołania) jako liczbę typu int, albo jako tablicę znaków (bajtów).
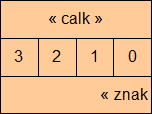
Natomiast nie powinniście odczytywać wartości liczby dzielonej modulo przez 255 korzystając z unii - nie w C++, mimo że w C byłoby to poprawne. Poniższy kod - choć w większości przypadków zadziała - nie powinien być wykorzystywany.
u1.calk = 10 + 0x0f00; // teraz jest liczba
std::cout << u1.znak[0];
Jeśli zdecydujecie się na wykorzystanie unii, pamiętajcie, że:
- Unie nie mogą mieć konstruktorów, destruktorów oraz pól statycznych,
- W tym samym obszarze pamięci mogą być przechowywane różne zmienne,
- Unia zajmuje tyle pamięci co największe z jej pól.
Unie są wyjątkowo mało przenośnie, w zasadzie ich zastosowanie ogranicza się do kilku przypadków: przechowywania zmiennych wariantowych (choć tu mamy znacznie lepsze rozwiązania, np std::variant), lub w kodzie niskopoziomowym. Unikajcie więc stosowanie nieoznakowanych unii, a jak potrzebujecie oszczędzać pamięć, a nie ufacie typowi wariant, to zbudujcie klasę opakowującą "oznakowaną" unię - oznakowaną czyli z polem typu:
union Unia
{
int calk;
char znak[];
};
enum class Typ { Calkowita, Znakowa };
struct Oznakowana {
Unia u1;
Typ typ;
};
Dodatkowo, możliwe jest stosowanie unii która ani nie ma zdefiniowanej nazwy, ani nie jest zdefiniowana żadna zmienna jej typu. Oba poniższe przykłady kodu są prawidłowe:
struct
{
int a;
union {
long l
char c[4];
};
} dzial;
union
{
struct { char c1, c2; short s; } p;
long l;
};
Pusta definicja unii nie oznacza tworzenia jakiegoś nowego typu, jest jedynie informacją, że dane pola współdzielą wspólny obszar pamięci.
5.5. Jawne rzutowanie typów
Na koniec tego rozdziału chciałbym wrócić do zagadnienia rzutowania typów w języku C++. Czasami to rzutowanie odbywa się w sposób niejawny i niewidoczny dla programisty, przy czym dzieje się to głównie w obrębie typów użytkownika (klas) znajdujących się w jednej hierarchii, lub też w obrębie typów arytmetycznych. Szczególnie często sytuacja taka ma miejsce w przypadku obliczania wyrażeń arytmetycznych. W tym przypadku C++ kieruje się szlachetną zasadą przyjmowania jako typu wynikowego tego, który ma największą dokładność (żeby nie groziła utrata danych). Tak więc jak dodajemy short do int, to wynik będzie int, jak dzielimy int przez double wynik będzie double …. wszystko pięknie, tylko jak myślicie, jaka wartość będzie w zmiennej x po wykonaniu poniższego kodu?
double x = 1 / 2;
Wydawałoby się że powinno być 0.5 a tu niespodzianka … w x zostanie zapamiętane 0. Liczby 1 i 2 są liczbami całkowitymi, więc wynik ich podzielenia też będzie liczbą całkowitą. A operacja przypisania jest operacją kolejną w stosunku do dzielenia … dopiero podczas przypisania nastąpi niejawne rzutowanie int na double.
5.6. Rzutowanie w stylu C
Aby uniknąć sytuacji analogicznej do opisanej, musimy jawnie wskazać, że choć jeden z argumentów jest typu double. Można to zrobić pisząc np. 1.0 zamiast 1. Można też wymusić rzutowanie w stylu C, podając przed argumentem w nawiasach typ, na jaki zmienna ma zostać przekształcona:
double x = (double)1/2;
Jednak rzutowanie takie nie jest zgodne pod względem składni z filozofią języka C++. Bardziej eleganckie jest rzutowanie w stylu inicjacji:
double x = double(1)/2;
ale i w takim przypadku wymuszamy na kompilatorze naszą decyzję, nie stosując mechanizmów ochronnych C++.
5.7. Rzutowanie w stylu C++
Oba podejścia wymienione wcześniej nie są zalecane w przypadku języka C++. Tutaj standard proponuje zastosowanie jednego z „cast-ów”:
static_cast
static_cast jest typem rzutowania typów pokrewnych niepolimorficznych (nie muszą być w jednej hierarchii dziedziczenia). Jego głowne zastosowanie to rzutowanie typów prostych na inne typy proste, przykładowo:
int x = 1;
double y = static_cast< double>(x)/2;
dynamic_cast
Jest to operator rzutowania typów polimorficznych, muszących pozostawać względem siebie w hierarchii dziedziczenia.
reinretpret_cast
Niebezpieczny operator rzutowania dowolnych typów na dowolne inne. W praktyce polega na bitowej zmianie znaczenia adresu – w swoim działaniu bardzo przypomina unie.
const_cast
Kolejny niebezpieczny operator rzutowania – w tym wypadku zmieniana jest zmienna na stałą (co jeszcze nie jest takie złe) jak i stała na zmienną … to dzięki jego istnieniu pisaliśmy że stałe w C++ nie zawsze koniecznie są stałe
6. Wyrażenia i operatory
Na początek chciałbym powrócić do wspomnianej wcześniej kwestii wyrażeń i tego, że prawie wszystko w języku C++ jest wyrażeniem. Skoro prawie wszystko jest wyrażeniem, to i istotną częścią języka są operatory które pozwalają budować owe wyrażenia. Są one najczęściej (ale nie zawsze) określane odpowiednimi symbolami. Każdy z nich ma swoje właściwości. A zaczniemy od hierarchii operatorów.
6.1. Priorytety operatorów
W C++ jest kilkadziesiąt różnych operatorów. Czasem wymagają one podania jednego argumentu, czasem dwóch. Są też takie które wymagają podania 3, lub dowolnej liczby argumentów. Czasem wynikiem ich działania jest wrtość logiczna, czasem wartość dowolnego typu. To co je wszystkie łączy - to hierarchia.
By przy interpretacji wyrażeń z nich zbudowanych nie powstał bałagan - hierarchia jest ściśle zdefiniowana, i podzielona na kilkanaście poziomów. Wszystkie operatory na danym poiomie są równoważne - o kolejności ich wykonania decyduje kolejność pojawiania się w kodzie
| Priorytet | Ilość arg. | Operator | Opis | Przykład |
|---|---|---|---|---|
| 1 | 2 | :: | zakres, przestrzeń nazw | std::cout |
| 2 | 2 | () [] . -> ++ -- dynamic_cast static_cast reinterpret_cast const_cast typeid |
nawiasy, inkrementacja postfiksowa (przyrostkowa), odwołanie do metod obiektów, odwołania do pól struktur... |
i++, obiekt->metoda() |
| 3 | 1 | ++ -- ~ ! sizeof new delete * & + - |
inkrementacja przedrostkowa (prefiksowa), referencja, wskaźnik |
++i, +k, -k, & ref, * wsk |
| 4 | 1 | (typ) | rzutowanie | (double) a |
| 5 | 2 | .* ->* | ||
| 6 | 2 | * / % | mnożenie, dzielenie, modulo | a / b |
| 7 | 2 | + - | dodawanie, odejmowanie | a + b |
| 8 | 2 | << >> | przesunięcie bitów | a << 2 |
| 9 | 2 | < > <= >= | porównywanie | a < b |
| 10 | 2 | == != | porównywanie | a == b |
| 11 | 2 | & | bitowy iloczyn | |
| 12 | 2 | ^ | różnica symetryczna XOR | |
| 13 | 2 | | | bitowa suma | |
| 14 | 2 | && | iloczyn logiczny | (warunek1) && (warunek2) |
| 15 | 2 | || | suma logiczna | (warunek1) || (warunek2) |
| 16 | 3 | x ? y : z | operator warunkowy – zwraca y, gdy x ma wartość niezerową, z w przeciwnym wypadku | |
| 17 | 2 | = *= /= %= += -= >>= <<= &= ^= != |
przypisanie | a %= b |
| 18 | 2 | , | operator przecinkowy, służący np. do grupowania wyrażeń podczas inicjalizowania pętli | for(i = 1, j = 1;;i++,j--) |
Od priorytetu operatora zależy, w jakiej kolejności zostaną wykonane operacje z których składa się wyrażenie. W przypadku operatorów o tym samym priorytecie, wyrażenie wykonywane w kolejności albo od lewej do prawej - albo od prawej do lewej, w zależności od tego z której strony jest wiązanie danego operatora.
W przypadku, gdybyście mieli wątpliwości odn. kolejności wykonania operacji – celowo jeden z najwyższych priorytetów ma operator nawiasów ().
6.2. Podział operatorów
Ogólnie operatory można podzielić na kilka grup:
Pierwszy, najbardziej ogólny z podziałów dotyczy liczby argumentów. W tym przypadku mamy do czynienia z operatorami jedno-, dwu-, i wieloargumentowymi. Jednak nie zawsze ten podział jest podziałem zrozumiałym w naturalny sposób. O ile nie budzi on naszego sprzeciwu w przypadku operatorów arytmetycznych (dodawanie dwuargumentowe, jednoargumentowy minus) czy logicznych (logiczna suma która ma dwa argumenty, czy negacja o jednym argumencie), o tyle nie bardzo wiadomo jak rozumieć pojęcie argumentu dla omawianego wcześniej operatora wyłuskania?
Dlatego też naszym zdaniem o wiele ważniejszy jest podział ze względu na rodzaj wykonywanej operacji. Z tego punktu widzenia możemy wydzielić następujące grupy operatorów.
Operatory arytmetyczne
Do operatorów arytmetycznych zaliczamy oprócz standardowego dodawania, odejmowania, mnożenia i dzielenia także operator modulo, inkrementacji i dekrementacji w dwóch wersjach, przed- i przyrostkowej, czy też … operator przypisania =. Wynikiem działania operatora przypisania jest wartość przypisana do l-wartości, po wykonaniu ew. konwersji typów. Typ wyniku zastosowania operatora arytmetycznego jest wynikiem niejawnej konwersji typów składowych operacji.
Operatory relacji
Operatory relacji służą, jak sama nazwa mówi – do ustalenia relacji w jakiej pozostają ze sobą argumenty. W tej grupie mamy dostęp do operatora równoważności (==), nierównoważności, większości, mniejszości i pochodnych. Znaczenie tych operatorów może być przedefiniowana przez programistę (i często bywa, w przeciwieństwie do pozostałych operatorów).
Wynikiem zastosowania operatora relacji jest zawsze wartość logiczna
Operatory logiczne
Operatory logiczne służą do budowania i wykonywania zdań logicznych. Mamy do dyspozycji operatory logicznej koniunkcji, agregacji i negacji. Wynikiem ich zastosowania jest zawsze wartość logiczna. Uważajcie, by operatorów logicznych nie mylić z następną grupą – operatorami bitowymi.
Operatory bitowe
Operatory bitowe również wykonują operacje logiczne, lecz nie na całych zmiennych, tylko na pojedynczych bitach wchodzących w skład zmiennych czy stałych. Na pojedynczych bitach – nie znaczy że bezpośrednio można wykonać operacje na wybranych bitach, są one wykonywane na wszystkich bitach danej zmiennej, lecz na każdym z nich niezależnie. Tutaj oprócz typowych koniunkcji, agregacji i negacji mamy dostęp również do różnicy symetrycznej XOR czy przesunięcia bitowego w lewo i w prawo. Typ wyniku po zastosowaniu operatora bitowego jest zależny od typu argumentów.

Operatory łączone
W C++ występuje duża grupa operatorów które są połączeniem przypisania wraz z jakąś operacją. Zawsze działają one wg następującego schematu:
// zapis klasyczny
x = x+y;
// zapis skrócony
x += y;
W przypadku tych operatorów L-wartość jest jednocześnie jednym z argumentów wyrażenia. Operatory łączone są dla wszystkich operatorów arytmetycznych i bitowych.
Inne operatory
Trochę dziwna nazwa dla grupy, prawda? Lecz w C++ występuje kilka operatorów, które wyjątkowo ciężko sklasyfikować. Mamy wśród nich wspomniane operatory zasięgu, wyłuskania, ale też i operator pobrania rozmiaru zmiennej czy typu sizeof, operator przecinka zwracający zawsze wartość najbardziej po prawej stronie (ten operator może łączyć wiele argumentów), czy specjalną postać wyrażenia warunkowego (wyrażenie ? wartość_prawda : wartość_fałsz).
7. Instrukcje sterujące
Wszystkie szerzej znane instrukcje wyboru stosowane w innych językach są zaimplementowane także w języku C++, tak więc mamy możliwość korzystania z if w wersji prostej i rozszerzonej, switch (który działa trochę inaczej niż ma to miejsce w innych językach), oraz trzech rodzajów pętli (tu już mamy bardzo wysoki stopień elastyczności, mocno różniący się od innych języków). W każdej z instrukcji sterujących będziemy mieli do czynienia z koniecznością oceny logicznej wyrażenia w celu podjęcia decyzji. Już o tym wspominaliśmy, lecz nie zaszkodzi powtórzyć:
Tak więc wyrażeniem, które służy do podjęcia decyzji, nie musi być wyrażenie którego wynikiem jest typ logiczny. Jeśli spojrzymy na poniższy program:
int main() {
int x;
cin << x;
if (x = 0)
cout << "mamy zero";
}
Po jego wykonaniu, niezależnie od tego, co zostanie wprowadzone jako x, nigdy nie zostanie wyświetlony napis „mamy zero”. Jest to efektem błędu popełnionego przy pisaniu programu – zamiast porównania w if mamy przypisanie. Lecz że jest to poprawne składniowo wyrażenie, zwracające wartość przypisywaną, czyli zero, wyrażenie zawsze będzie potraktowane jako fałsz – i napis się nigdy nie wyświetli, mimo że program da się skompilować i uruchomić. Jest to konsekwencją traktowania przez C++ prawie wszystkiego jako wyrażenie.
Mając to na uwadze, przejdźmy do opisu pojęcia instrukcji w języku C++.
7.1. Instrukcje proste i złożone
Dla każdej instrukcji sterującej dostępnej w języku C++ obowiązuje zasada warunkowego wykonania jednej i tylko jednej instrukcji. Może to być instrukcja prosta – najprostszy przypadek. Lecz często chcielibyśmy wykonać ciąg poleceń, co w tym wypadku? W tym celu wprowadzono pojęcie instrukcji złożonej.
Taka instrukcja jest nową przestrzenią nazw dla zmiennych, osadzoną w hierarchiczny sposób w nadrzędnych instrukcjach złożonych, aż do przestrzeni nazw wykonywanej funkcji. Dzięki temu wewnątrz bloku możemy definiować nowe zmienne, nawet o takiej samej nazwie jak już zdefiniowane wcześniej w innych, nadrzędnych blokach zmienne
Ogólna zasada jest taka, że wszędzie tam, gdzie może się znaleźć instrukcja prosta, można też umieścić instrukcję złożoną, przy czym po zamykającym nawiasie klamrowym może – ale nie musi – znaleźć się średnik.
Ściśle rzecz ujmując – po zamykającym nawiasie klamrowym nie może znaleźć się średnik. Natomiast sami możecie sprawdzić, że postawienie średnika nie będzie błędem składniowym … dlaczego?
Oprócz instrukcji złożonej w C++ występuje pojęcie instrukcji pustej – którą kończy po prostu średnik. Ciąg znaków { … };;; zostanie zinterpretowany jako jedna instrukcja złożona i seria trzech instrukcji pustych. Cecha zarówno miła, jak i niekoniecznie miła … popatrzcie poniżej:
int main() {
int x;
cin << x;
if (x == 0);
cout << "mamy zero";
}
Po uruchomieniu tego kodu niezależnie od tego co wprowadzimy, zawsze wyświetli się napis „mamy zero” … bo po if jest instrukcja pusta.
7.2. Instrukcja warunkowa
Instrukcja warunkowa w języku C++ ma następującą składnię:
if (wyrażenie_warunkowe)
// instrukcja wykonywana jeśli wyrażenie jest prawdziwe
else // else jest opcjonalne
// instrukcja wykonywana jeśli wyrażenie nie jest prawdziwe
Nie ma obowiązku podania bloku else – co więcej, jak to widzieliście wcześniej, można też postawić instrukcję pustą w części wykonywanej jeśli wyrażenie jest prawdziwe.
To nie jedyne dopuszczalne udziwnienie w C++. Poniżej prezentujemy inny rzadziej spotykany, lecz poprawny kod:
int main()
{
if ( int a = x + 2 > 0 )
cout << a << endl;
return 0;
}
Zauważcie, że w wyrażeniu będącym argumentem instrukcji if została zdefiniowana zmienna, która jest dostępna w instrukcji podporządkowanej (podobnie byłoby jeśli instrukcją podporządkowaną byłaby instrukcja złożona). W C++ jest to dopuszczalne, co więcej - jest to równoważne poniższemu zapisowi:
int main()
{
if ( int a = x + 2; a > 0 )
cout << a << endl;
return 0;
}
Ciągle nie ma to za wiele sensu, ale poniżej macie przykład kodu, który wykorzystuje tą składnię sensowniej:
int main()
{
std::vector<double> v;
...
if (auto n=v.size())
std::cout << "Rozmiar wektora to " << n << std::endl;
else
std::cout << "Wektor jest pusty\n"
...
}
7.3. Instrukcja wielokrotnego wyboru
Instrukcja wielokrotnego wyboru switch ma następującą składnię:
switch (wyrażenie) {
case 1:
...
break;
...
case n:
...
break;
default:
...
}
Wyrażenie, wg którego następuje różnicowanie wykonania musi być typu (dawać w wyniku) przeliczalnego. Zasadę wykonywania instrukcji switch zaprezentowaliśmy na rysunku poniżej:

Nie jest to działanie do końca zgodne z naszymi przewidywaniami. Po dokonaniu wyboru (wybraniu odpowiedniego case) jest wykonywany kod do wystąpienia break. Jeśli w trakcie wykonania pojawi się następny case – zostanie zignorowany. Ponieważ wnętrze bloków po case nie jest instrukcją złożoną – nie tworzą własnej przestrzeni zmiennych lokalnych. Z tego względu wewnątrz instrukcji switch nie można definiować stałych i zmiennych. Oczywiście jeśli blok instrukcji po case obejmiemy nawiasami klamrowymi – będziemy mogli wewnątrz zdefiniować zmienne.
7.4. Przerywanie wykonania pętli
Zanim przejdziemy do omawiania pętli – zajmijmy się możliwością przerwania ich działania. W przypadku każdej z pętli mamy dwie dodatkowe instrukcje sterujące:
- continue przerywa wykonanie aktualnego przebiegu pętli, i wymusza przeskok do sprawdzenia warunku, i ewentualnego wykonania kolejnego przebiegu.
- break przerywa bezwarunkowo wykonanie pętli i przejście do pierwszej instrukcji poza pętlą.
W przypadku pętli zagnieżdżonych, zawsze continue i break oddziałują tylko na pętlę w której bezpośrednio zostały wywołane … jeśli mamy pętlę w pętli – nie ma możliwości przerwania wykonania ich obu jednym poleceniem, chyba że jest to polecenie wyjścia z funkcji.
Nie zaleca się nadużywania, czy też częstego stosowania obu instrukcji break i continue. Zazwyczaj nie ma potrzeby ich stosowania, a jeśli jest – najczęściej jest przejawem złego zaprojektowania pętli i warunków nią sterujących.
7.5. Pętle o nieznanej liczbie iteracji
W C++, podobnie jak w innych językach programowania, mamy do dyspozycji trzy typowe pętle:
- pętlę o nieznanej liczbie iteracji która nie musi być wykonana ani razu - while,
- pętlę o nieznanej liczbie iteracji która musi się wykonać co najmniej raz – do-while,
- pętlę o zadanej liczbie iteracji for.
Dodatkowo, od C++11 mamy jeszcze pętlę zakresową (działającą na elementach w kontenerze) - jest to wersja pętli for z jednym argumentem.
Jednakże w przeciwieństwie do większości pozostałych języków – każda ze wspomnianych pętli może zostać prosto przekształcona w dowolną inną (są to bardzo elastyczne konstrukcje).
Na początek zajmiemy się pętlami typu while i do-while. Zasada działania obu z nich jest analogiczna, jedyna różnica polega na momencie sprawdzenia warunku – w pierwszym przypadku warunek jest sprawdzany w momencie wejścia do pętli, w drugim – w momencie wyjścia z niej.
Składnia obu pętli wygląda następująco:
// pętla while
while (wyrazenie)
// instrukcja wykonywana w pętli
instrukcja_w_petli();
// pętla do – while
do
// instrukcja wykonywana w pętli
instrukcja_w_petli();
while (wyrazenie);
Podobnie jak w przypadku if, wyrażenie może być dowolnego typu który ma jakąś wartość (czyli każdego poza void). Zasady wartościowania wyrażenia są również identyczne jak w przypadku instrukcji warunkowej.
Pętla jest wykonywana dopóki wyrażenie jest prawdziwe, wg pokazanego schematu:
7.6. Pętle o zadanej liczbie iteracji
Teoretycznie bardziej skomplikowaną niż omawiane wcześniej pętlą jest pętla o zadanej liczbie iteracji. Zazwyczaj taka pętla musi mieć zmienną sterującą, w wielu językach programowania w momencie wejścia do pętli musi być znana i ustalona liczba iteracji. W C++ oba te stwierdzenia są nieprawdziwe. Pętla for nie musi mieć zmiennej sterującej, inkrementowanej / dekrementowanej co krok. Liczba iteracji także nie musi być znana przed rozpoczęciem pętli – może się zmieniać w trakcie wykonywania pętli … Zwyczajowo stosuje się ją jako pętlę o zadanej liczbie iteracji, lecz nic nie stoi na przeszkodzie by tą pętlę wykorzystać analogicznie do while czy do-while.
Składnia wygląda następująco:
for (inicjalizacja; wyrazenie_warunkowe; krok)
// instrukcja wykonywana w pętli
instrukcja_w_petli();
Każdy z wymienionych elementów (inicjalizacja, wyrażenie_warunkowe, krok) są niezależnymi wyrażeniami / instrukcjami, każde z nich może zostać pominięte. Moment wykonania każdej z instrukcji wygląda następująco:
- inicjalizacja – instrukcja wykonywana przed pierwszym przebiegiem pętli. Zwyczajowo znajduje się tutaj definicja i inicjacja zmiennej sterującej.
- wyrażenie_warunkowe – instrukcja / wyrażenie warunkujące wykonanie kolejnego przejścia pętli, przy czym pętla może nie zostać wykonana ani razu. Jeśli pominiemy ten element – pętla nigdy się nie zakończy. Zwyczajowo umieszcza się tutaj wyrażenie testujące zmienną sterującą na okoliczność zakończenia pętli
- krok – instrukcja wykonywana po każdym wykonaniu pętli. Zwyczajowo tutaj znajduje się inkrementacja zmiennej sterującej.
W przypadku pominięcia wszystkich wyżej wymienionych elementów uzyskamy pętlę nieskończoną.
Tok wykonania pętli for pokazujemy na rysunku poniżej:

W nowszych standardach C++ jest jeszcze jedna postać pętli for - tzw. pętla zakresowa, lub for-each, czyli dla każdego z kolekcji. Ta pętla upraszcza składnię w przypadku przeglądania wszystkich elementów z jakiejś kolekcji:
for (typ nazwaZmiennej : kolekcja) {
// Instrukcje do wykonania
}
Przykładowo - poniższy kod wyświetli wszystkie elementy z tablicy:
int mojeNum[5] = {10, 20, 30, 40, 50};
for (int i : mojeNum) {
cout << i << "\n";
}
W przypadku pętli zakresowej - jeśli chcemy zmieniać wartość elementu w kolekcji, często stosujemy referencję jako typ zmiennej elementu - inaczej zmienialibyśmy kopię a nie oryginał:
for (int i : mojeNum) {
i += 2; // wartości w tablicy nie są zmieniane
}
for (int& i : mojeNum) {
i += 2; // wartości są zmieniane - mamy referencję
}
8. Funkcje
W języku C++ funkcje są podstawowymi jednostkami wykonawczymi, i są podstawowym elementem projektowania strukturalnego – to czego uczyliście się do tej pory opierało się głównie na funkcjach. Często funkcje są określane jako podprogram (ang. subroutine), aczkolwiek w C++ mają większe możliwości. Dzięki odpowiedniej składni i przeciążaniu operatorów jesteśmy w stanie przygotować funkcje które mają stan (ściślej - będą to obiekty które semantycznie i składniowo będą zachowywały się jak funkcje - o tym opowiem przy okazji programowania obiektorwego Możemy także stosować tzw funkcje nienazwane - czyli wyrażenia lambda - o nich tutaj wspomniemy.
8.1. Deklaracja i definicja funkcji
Jak już wspomniałem, rozróżnia się deklarację i definicję funkcji.
Deklaracja wygląda następująco:
< modyfikator > < typ_zwracany > < nazwa >( < typ1 > < arg1 >, < typ2 > < arg2 > <...> );
Definicje funkcji wyglądają bardzo podobnie, z tym że zamiast ; kończącego deklarację mamy nawiasy klamrowe { } zawierające "ciało" (ang. body) funkcji.
< modyfikator > < typ_zwracany > < nazwa >( < typ1 > < arg1 >, < typ2 > < arg2 > <...> ) {
< instrukcja 1 >;
< instrukcja 2 >;
...
< instrukcja n >;
return wartosc_zwracana;
}
W nagłówku funkcji występują następujące elementy:
- modyfikator - opcjonalny modyfikator funkcji, omówię go nieco później.
- typ_zwracany – typ wartości zwracanej przez funkcję, jeśli jej wywołanie zostało umieszczone w wyrażeniu. Wynik jest zwracany poprzez wywołanie instrukcji return z argumentem będącym zwracaną wartością. Jeśli funkcja nie zwraca żadnej wartości, typ zwracany należy zdefiniować jako void, i konsekwentnie return nie powinien mieć podanego żadnego argumentu lub argument typu void.
- nazwa – identyfikator, przy użyciu którego będzie wywoływana funkcja . Wbrew pozorom, w C++ nazwa nie identyfikuje jednoznacznie funkcji. Poza nazwą do identyfikacji jest również wykorzystana lista typów argumentów, dzięki czemu możliwe jest opisane dalej przeciążanie nazw funkcji.
- lista par: typ_argumentu nazwa_argumentu oddzielona przecinkami. Nazwa jest opcjonalna – nie musi występować w deklaracji bez jakichkolwiek konsekwencji, i nie musi też występować w definicji, tyle że wtedy taki argument nazywamy nienazwanym, i nie możemy go wykorzystywać w instrukcjach w ciele funkcji. Nazwa też nie musi się zgadzać w definicji i deklaracji, choć takie zachowanie świadczy o niechlujnym przygotowaniu kodu.
- argumenty funkcji mogą mieć wartości domyślne (domniemane). Wartości te są wpisywane w deklaracji funkcji, przy czym argumenty domniemane muszą być podane na końcu listy. Przy wywołaniu funkcji można pominąć tylko argumenty z końca listy, które mają wartości domyślne.
- Zapis (...) oznacza dowolną liczbę argumentów.
8.2. Przekazywanie argumentów do funkcji
Domyślnie argumenty przekazujemy do funkcji przez wartość - czyli robiona jest kopia przekazywanej zmiennej - dostępna w funkcji. Taki sposób jest dobry, pod warunkiem że wartość argumentu nie będzie zmieniana wewnątrz funkcji (jest to p-wartość), oraz że przekazywany argument ma niewielki rozmiar. Dlaczego akurat te warunki muszą zostać spełnione?
Argumenty przekazywane jako wartość są przekazywane poprzez stos, przy czym - jak wspomniałem - przy każdym wywołaniu funkcji jest tworzona na stosie ich kopia. Stąd ograniczenie na wielkość argumentu przekazywanego przez wartość - wykonywanie po kilkanaście tymczasowych kopii dużego obiektu zakrawa na śmieszność – ze względu na zużycie pamięci, oraz czas potrzebny na kopiowanie.
Inna właściwość, która się co prawda z poprzednią nie wiąże w sposób logiczny, ale której brak jest również mankamentem przekazywania przez wartość, to fakt, że wewnątrz funkcji nie mamy żadnego wpływu na zmienne, jakie jej zostały przekazane. Klasycznym przykładem, który to obrazuje, jest funkcja o nazwie 'swap', której zadaniem jest zamienić miejscami wartości w dwóch zmiennych.
Pierwsze podejście do funkcji mogłoby wyglądać następująco:
void swap(int a, int b) {
int temp = a;
a = b;
b = temp;
}
...
int main() {
int x=10, y=20;
swap(x, y);
cout << x << " " << y;
...
}
Lecz po jej wywołaniu okaże się, że zmienne w funkcji nadrzędnej nie zostały zmienione. Funkcja operuje na kopiach wartości argumentów, które jednocześnie są jej zmiennymi lokalnymi.
Poznaliście wskaźniki, więc może ich wykorzystanie będzie jakimś rozwiązaniem? Przekazywana jest co prawda nadal wartość, ale tą wartością jest wskaźnik do zmiennej, wystarczy więc posłużyć się wyłuskiwaniem:
void swap(int *a, int *b ) {
int temp = *a;
*a = *b;
*b = temp;
}
...
int main() {
int x=10, y=20;
swap(&x, &y);
cout << x << " " << y;
...
}
Niestety, jak zauważyliście, konieczna jest zmiana sposobu wywołania funkcji, co nie wygląda najlepiej.
W C++ jest jeszcze jedna możliwość (w starym C niedostępna) – przekazywanie parametrów przez referencję. Wygląda to podobnie do definicji zmiennych typu referencyjnego- wystarczy zmienić nagłówek:
void swap(int &a, int &b) {
int temp = a;
a = b;
b = temp;
}
...
int main() {
int x=10, y=20;
swap(x, y);
cout << x << " " << y;
...
}
I voila – otrzymujemy to, o co nam chodziło.
Tak na boku - w C++ ta funkcja jest już dostarczona w bibliotece standardowej, i to w formie szablonowej, gdzie argumenty mogą być dowolnego typu.
W przypadku kiedy zakładamy, że przekazywany argument nie powinien być zmieniany w funkcji, ale ciągle chcemy uniknąć jego kopiowania przy wywołaniu funkcji - możemy stosować stałe referencje:
void funkcja(const MojTyp& duzy) {
// tu nie można zmienić wartości przechowywanej w duzy
}
Podsumowując:
- W C++ możemy przekazywać argumenty do funkcji przez wartość i przez referencję (pamiętajcie – przekazanie wskaźnika jest przekazaniem przez wartość),
- Jeśli argumenty są małe (w sensie zajętości pamięci) i nie są zmieniane wewnątrz funkcji (a przynajmniej ta zmiana nie musi być widoczna poza ciałem funkcji) – korzystamy z przekazywania przez wartość.
- W pozostałych przypadkach powinien być przekazany wskaźnik, lub wykorzystana referencja.
- Dodatkowo, warto pamiętać, że tablice zawsze są przekazywane do funkcji jako wskaźnik.
- Praktyczna rada - jeśli zależy Wam na wydajności, obiekty przekazujcie przez (potencjalnie stałe) referencje, typy proste - przez wartość.
8.3. Zwracanie wyników z funkcji
Funkcja zwraca wyniki zazwyczaj poprzez return < wartość > , przy czym typ zwracanej wartości jest określony w nagłówku funkcji.
Do zwracania wyniku funkcji możemy wykorzystać każdą z metod omawianych wcześniej przy przekazywaniu argumentów. I podobnie jak wtedy - zwracanie dużych obiektów przez wartość, choć nie jest zalecane, nie stanowi problemu (zostanie wykonana kopia).
Lecz gdy zwracamy duże obiekty, i chcemy zrobić to elegancko, to mamy problem ... kto (funkcja? obiekt?) ma zarządzać czasem życia zwróconej wartości?
Jeśli typ zwracany jest typem podstawowym (lub typem niewielkich rozmiarów), to zwróćcie go po prostu przez wartość i nie zawracaj sobie głowy szczegółami. W pozostałych wypadkach macie do wyboru:
- Zwracamy obiekt tymczasowy (czyli przez wartość) – a wstyd i narzut czasowy trzeba zaakceptować...
- Zwracamy referencję do obiektu. Do jakiego? Nie może być to zmienna lokalna w funkcji ... mamy nadzieję że już rozumiecie dlaczego. Ale może do ... zmiennej statycznej w funkcji?. Sprytne, nie? Jednak unikajcie takich rozwiązań – mało intuicyjne, prowadzi do tworzenia zmiennych statycznych które wykorzystywane są niekoniecznie zgodnie z przeznaczeniem.
- Zwracamy wskaźnik do obiektu. W ten sposób należy jednak przyjąć prostą zasadę – tak zwracane są jedynie zmienne i obiekty tworzone dynamicznie, i odbiorca wyniku jest zobowiązany do usunięcia tego obiektu, przy czym jeszcze lepiej jest zmusić odbiorcę do skasowania obiektu dzięki odpowiednim wskaźnikom inteligentnym, np. unique_ptr
- Możecie też skorzystać z opisanej dalej w podręczniku semantyki przenoszenia.
8.4. Przeciążanie nazw funkcji
Wspomniałem, że w C++ nazwa funkcji nie jest jej unikalnym identyfikatorem – że kompilator automatycznie dodaje do nazw przyrostek zawierający typy wszystkich argumentów w odpowiedniej kolejności. Ten mechanizm jest wykorzystany do przeciążania nazw funkcji, czyli pozwolenia na to, by w programie mogło występować kilka funkcji o tej samej nazwie.
Przy czym kompilator musi mieć możliwość odgadnięcia, o którą funkcję chodzi autorowi, więc - muszą się różnić typami parametrów na liście (nie samymi nazwami - bo one nie są wykorzystywane przy wywołaniu), i nie można wykorzystać do przeciążania typu wartości zwracanej (wartość zwracają można "porzucić" - i nie byłoby przesłanki do wyboru odpowiedniej wersji funkcji.
Przykłady prawidłowego i nieprawidłowego przeciążania:
// prawidłowo
int funkcja(int _a);
int funkcja(int _a, int _y);
int funkcja(double _a);
int funkcja(string _a);
// nieprawidłowo
int funkcja(int _a);
double funkcja(int _a);
Kompilator sam dopasuje odpowiednią funkcję w momencie wywołania, kierując się następującymi zasadami:
- Ścisła zgodność (bez konwersji lub konwersje trywialne – tablica na wskaźnik, stała na zmienną, nazwa funkcji na funkcję)
- Zgodność z zastosowaniem promowania typów całościowych (bool na int, char na int i odpowiedniki bez znaku)
- Zgodność z zachowaniem standardowych konwersji (całkowite na zmiennoprzecinkowe i vice versa, rzutowania klas, rzutowanie na void*)
- Zgodność z zachowaniem definiowanych konwersji (dla klas)
- Zgodność z wielokropkiem w deklaracji funkcji.
void drukuj(int _x);
void drukuj(const char* _x);
void drukuj(double _x);
void drukuj(long _x);
void drukuj(char _x);
void h(char _c, int i, short s, float f)
{
// ścisla zdodnosc
drukuj(c);
drukuj(i);
// trywialna konwersja
drukuj('c');
drukuj(49);
drukuj(0);
drukuj("A");
// promocja w zakresie typów całościowych
drukuj(s); // wywoła drukuj(int)
// promocja w zakresie konw. standardowych
drukuj(f); // wywoła drukuj(double)
}
Jeśli znaleziono więcej niż jedną pasującą funkcję na tym samym poziomie – będzie błąd kompilacji. Jak się taki błąd pojawi – co robić? Najlepiej ręcznie rozwiać wątpliwości kompilatora:
void f1(char);
void f1(long);
void f2(char*);
void f2(int*);
...
int i;
f1(i); // niejednoznaczne
f1(long(i)); // ok
f2(0); // niejednoznaczne
f2(static_cast<int*>(0)); // ok
double pow(int x, int y);
double pow(double x, double y);
...
pow(2.0, 2); // niejednoznaczne
pow(2.0, (double)2); // i już ok.
</int*>8.5. Wskaźniki do funkcji
Wskaźnik na funkcję to ... jak się łatwo domyśleć – adres w pamięci, gdzie zaczyna się jakaś funkcja. To chyba dość oczywiste – zmienne mają adresy, bo są umieszczone w obszarze pamięci przeznaczonym na dane. Funkcje też mają adresy – bo są umieszczone w obszarze pamięci przeznaczonym na program. Jak z nich skorzystać? Całkiem prosto. Po pierwsze – nazwa funkcji standardowo może zostać zinterpretowana jako adres – wystarczy, że napiszemy ją bez nawiasów i argumentów na końcu. Dlatego też poniższy kod jest poprawny:
double funkcja(double (*wskaznik_na_funkcje)(double), double x)
{
double wynik;
wynik = (*wskaznik_na_funkcje) (x);
return (wynik);
}
cout << funkcja(sin, 1.75) << funkcja(cos, 1.75);
To co zrobiliśmy – to po prostu wykorzystaliśmy funkcję pomocniczą, która przyjmuje dwa argumenty. Drugi z nich to zwykła liczba zmiennoprzecinkowa. A pierwszy – to właśnie wskaźnik na funkcję. Definicja wskaźnika na funkcję jest bardzo podobna do definicji wskaźnika na zmienną. Zobaczcie:
/** Definicja wskaźnika na funkcję przyjmującą jeden parametr
typu double i zwracającą jedną wartość takiego samego typu.
Od tego momentu będzie istniała zmienna wskaźnikowa (przechowująca
adres) o nazwe func. */
double (*func)(double);
func = sin; /// przypisanie do zmiennej adresu funkcji sin
a = func(1.74); /// wywołanie funkcji wskazywanej
func = cos;
b = func(1.74);
Można także skorzystać z tablicy wskaźników na funkcje - deklaracja tablicy wygląda tak:
double (*funkcje[4])(double);
funkcje[0] = sin;
funkcje[1] = cos;
funkcje[2] = tan;
funkcje[3] = ctg;
Jak widzicie – nie ma w tym jakiejkolwiek magii czy problemów składniowych. Z doświadczenia wiem, że największym problemem jest zrozumienie i zaakceptowanie faktu, iż funkcja też może być zmienną ... więc jednak zrobiliśmy krok w kierunku programowania funkcyjnego. No to pora na krok następny.
8.6. Wyrażenia lambda
Wyrażenia lambda nie były dostępne w języku C++ od samego początku – pojawiły się w momencie definicji standardu C++11 – dlatego też są mniej znane i wykorzystywane niż na to zasługują. Do czego właściwie służą takie wyrażenia?
Ich podstawowe zastosowanie to tworzenie anonimowych funkcji. Jeśli ktoś z Was zna choćby podstawy JavaScript to wie, jak takie funkcje bez nazwy mogą być przydatne - np do budowy tzw callback-ów (wywołań zwrotnych).
Funkcja anonimowa to funkcja która nie posiada nazwy, lecz posiada swoje ciało, i można ją wywołać. Zasady tworzenia ciała funkcji lambda, jak i wszelkie ograniczenia kodu tam zamieszczanego są dokładnie takie same jak w przypadku standardowych funkcji C++ - cała różnica opiera się na nazwie, a dokładniej – jej braku. Więc dlaczego to takie użyteczne? Bo wygodne ... ;>
Sama składnia wyrażenia lambda jest następująca:
[]//początek wyrażenia lambda
(/*definicje argumentów*/)->/*typ wartości zwracanej*/
{
//ciało funkcji
}(Wartości zwracanych argumentów)
Przykładowe wyrażenie może więc wyglądać następująco:
// wyrażenie lambda
[]()->double {return 3.14; }();
/// odpowiadający mu kod klasyczny:
double dajPi() { return 3.14; }
dajPi();
Oczywiście – jeśli wyrażenie lambda zwraca jakąś wartość – to możemy ją odebrać, podobnie jak w przypadku zwykłych funkcji:
double pi = []()->double {return 3.14; }();
No dobrze – to gdzie ta wygoda, pomijając krótszy zapis jak na razie? Wygoda pojawia się, jak zaczniemy korzystać z adresów takiego wyrażenia. Adres możemy uzyskać pomijając nawiasy z wartościami parametrów w definicji wyrażenia. Przykład z dodawaniem dwóch liczb:
auto pAdres =[]( int x, int y )->int { return x+y; };
cout << pAdres( 5, 6 ) << pAdres( 7, 8 );
return 0;
Ciągle nie do końca widać tą wygodę. Ale ... przejdźmy do funkcji ogólnych, takich jak sort z biblioteki standardowej. Funkcja sort przyjmuje jako parametr wskaźnik do funkcji porównującej dwa pozostałe argumenty. Tą funkcję porównującą zawsze do tej pory musieliśmy definiować – wymyślać jej nazwę, zaśmiecać główną przestrzeń nazw, itp ... Teraz można podać w to miejsce wyrażenie lambda:
#include "cstdio"
#include "vector"
#include "ctime"
#include "cstdlib"
#include "algorithm"
int main()
{
std::srand( std::time( NULL ) );
typedef std::vector < int > VDaneT;
VDaneT dane( 10 );
for( size_t i = 0; i < dane.size(); ++i )
dane[ i ] = rand() % 50 + 1;
std::sort( dane.begin(), dane.end(),[]( const int & a, const int & b )->bool { return a > b; } );
for( size_t i = 0; i < dane.size(); ++i )
std::printf( "%d, ", dane[ i ] );
return 0;
}
Teraz mam nadzieję, iż widać że wygodnie ;)
8.7. Konwencja wywołania funkcji
Trochę trudno w to uwierzyć, ale podanie (zdawałoby się) wszystkiego, co można powiedzieć o danej funkcji: jej parametrów, wartości przezeń zwracanej, nawet nazwy - nie wystarczy kompilatorowi do jej poprawnego wywołania. Będzie on aczkolwiek wiedział, co musi zrobić, ale nikt mu nie powie, jak ma to zrobić. Cóż to znaczy? Celem wyjaśnienia porównajmy całą sytuację do telefonowania. Gdy chcemy zadzwonić pod konkretny numer telefonu, mamy wiele możliwych dróg uczynienia tego. Możemy zwyczajnie pójść do drugiego pokoju, podnieść słuchawkę stacjonarnego aparatu i wystukać odpowiedni numer. Możemy też sięgnąć po telefon komórkowy i użyć go, wybierając na przykład właściwą pozycję z jego książki adresowej. Teoretycznie możemy też wybrać się do najbliższej budki telefonicznej i skorzystać z zainstalowanego tam aparatu. Wreszcie, możliwe jest wykorzystanie modemu umieszczonego w komputerze i odpowiedniego oprogramowania albo też dowolnej formy dostępu do globalnej sieci oraz protokołu VoIP ( Voice over Internet Protocol ). Technicznych możliwości mamy więc mnóstwo i zazwyczaj wybieramy tę, która jest nam w aktualnej chwili najwygodniejsza. Zwykle też osoba po drugiej stronie linii nie odczuwa przy tym żadnej różnicy.
Podobnie rzecz ma się z wywoływaniem funkcji. Znając jej miejsce docelowe (adres funkcji w pamięci) oraz ewentualne dane do przekazania jej w parametrach, możliwe jest zastosowanie kilku dróg osiągnięcia celu. Nazywamy je konwencjami wywołania funkcji.
Dziwicie się zapewne, dlaczego dopiero teraz mówimy o tym aspekcie funkcji, skoro jasno widać, iż jest on nieodzowny dla ich działania. Przyczyna jest prosta. Wszystkie funkcje, jakie samodzielnie wpiszemy do kodu i dla których nie określimy konwencji wywołania, posiadają domyślny jej wariant, właściwy dla języka C++. Jeżeli zaś chodzi o funkcje biblioteczne, to ich prototypy zawarte w plikach nagłówkowych zawierają informacje o używanej konwencji. Pamiętajmy, że korzysta z nich głównie sam kompilator, gdyż w C++ wywołanie funkcji wygląda składniowo zawsze tak samo , niezależnie od jej konwencji. Jeżeli jednak używamy funkcji do innych celów niż tylko prostego przywoływania (a więc stosujemy choćby wskaźniki na funkcje), wtedy wiedza o konwencjach wywołania staje się potrzebna także i dla nas.
Jak już wspomniałem, konwencja wywołania determinuje głównie przekazywanie parametrów aktualnych dla funkcji, by mogła ona używać ich w swoim kodzie. Obejmuje to miejsce w pamięci , w którym są one tymczasowo przechowywane oraz porządek , w jakim są w tym miejscu kolejno umieszczane. Podstawowym rejonem pamięci operacyjnej, używanym jako pośrednik w wywołaniach funkcji, jest stos . Dostęp do tego obszaru odbywa się w dość osobliwy sposób, który znajdują zresztą odzwierciedlenie w jego nazwie. Stos charakteryzuje się bowiem tym, że gdy położymy na nim po kolei kilka elementów, wtedy mamy bezpośredni dostęp jedynie do tego ostatniego, położonego najpóźniej (i najwyżej). Jeżeli zaś chcemy dostać się do obiektu znajdującego się na samym dole, wówczas musimy zdjąć po kolei wszystkie pozostałe elementy, umieszczone na stosie później. Czynimy to więc w odwrotnej kolejności niż następowało ich odkładanie na stos.
Jeśli zatem wywołujący funkcję (ang. caller ) umieści na stosie jej parametry w pewnym porządku (co zresztą czyni), to sama funkcja (ang. callee - wywoływana albo routine - podprogram) musi je pozyskać w kolejności odwrotnej, aby je właściwie zinterpretować. Obie strony korzystają przy tym z informacji o konwencji wywołania, lecz w opisach "katalogowych" poszczególnych konwencji podaje się wyłącznie porządek stosowany przez wywołującego , a więc tylko kolejność odkładania parametrów na stos. Kolejność ich podejmowania z niego jest przecież dokładnie odwrotna.
Nie myśl jednak, że kompilatory dokonują jakichś złożonych permutacji parametrów funkcji podczas ich wywoływania. Tak naprawdę istnieją jedynie dwa porządki, które mogą być kanwą dla konwencji i stosować się dla każdej funkcji bez wyjątku. Można mianowicie podawać parametry wedle ich deklaracji w prototypie funkcji, czyli od lewej do prawej strony. Wówczas to wywołujący jest w uprzywilejowanej pozycji, gdyż używa bardziej naturalnej kolejności; sama funkcja musi użyć odwrotnej. Drugi wariant to odkładanie parametrów na stos w odwrotnej kolejności niż w deklaracji funkcji; wtedy to funkcja jest w wygodniejszej sytuacji.
Oprócz stosu do przekazywania parametrów można też używać rejestrów procesora , a dokładniej jego czterech rejestrów uniwersalnych. Im więcej parametrów zostanie tam umieszczonych, tym szybsze powinno być (przynajmniej w teorii) wywołanie funkcji.
Typowe konwencje wywołania
Gdyby każdy programista ustalał własne konwencje wywołania funkcji (co jest teoretycznie możliwe), to oczywiście natychmiast powstałby totalny rozgardiasz w tej materii. Konieczność uwzględniania upodobań innych koderów byłaby z pewnością niezwykle frustrująca. Za sprawą języków wysokiego poziomu nie ma na szczęście aż tak wielkich problemów z konwencjami wywołania. Jedynie korzystając z kodu napisanego w innym języku trzeba je uwzględniać. W zasadzie więc zdarza się to dość często, ale w praktyce cały wysiłek włożony w zgodność z konwencjami ogranicza się co najwyżej do dodania odpowiedniego słowa kluczowego do prototypu funkcji . Często nawet i to nie jest konieczne, jako że prototypy funkcji oferowanych przez przeróżne biblioteki są umieszczane w ich plikach nagłówkowych, zaś zadanie programisty-użytkownika ogranicza się jedynie do włączenia tychże nagłówków do własnego kodu.
Kompilator wykonuje zatem sporą część pracy za nas. Warto jednak przynajmniej znać te najczęściej wykorzystywane konwencje wywołania, a nie jest ich wcale aż tak dużo. Poniższa lista przedstawia je wszystkie:
- cdecl - skrót od C declaration ('deklaracja C'). Zgodnie z nazwą jest to domyślna konwencja wywołania w językach C i C++. Parametry są w tej konwencji przekazywane na stos w kolejności od prawej do lewej, czyli odwrotnie niż są zapisane w deklaracji funkcji. Słowo kluczowe które odpowiada tej konwencji to __cdecl
- stdcall - skrót od Standard Call ('standardowe wywołanie'). Jest to konwencja zbliżona do cdecl, posługuje się na przykład tym samym porządkiem odkładania parametrów na stos. To jednocześnie niepisany standard przy pisaniu kodu, który w skompilowanej formie będzie używany przez innych. Korzysta z niego więc chociażby system Windows w swych funkcjach API. Wasze programy powinny korzystać z tej konwencji w przypadku wyposażenia ich np. w system wtyczek. Konwencji tej odpowiada słowo __stdcall
- fastcall ('szybkie wywołanie') jest, jak nazwa wskazuje, zorientowany na szybkość działania. Dlatego też w miarę możliwości używa rejestrów procesora do przekazywania parametrów funkcji. Zazwyczaj tą konwencję oznacza się poprzez słówko __fastcall
- pascal budzi słuszne skojarzenia z popularnym ongiś językiem programowania. Konwencja ta była w nim wtedy intensywnie wykorzystywana, lecz dzisiaj jest już przestarzała i coraz mniej kompilatorów (wszelkich języków) wspiera ją.
- thiscall to specjalna konwencja wywoływania metod obiektów w języku C++. Funkcje wywoływane z jej użyciem otrzymują dodatkowy parametr, będący wskaźnikiem na obiekt danej klasy . Nie występuje on na liście parametrów w deklaracji metody, ale jest dostępny poprzez słowo kluczowe this . Oprócz tej szczególnej właściwości thiscall jest identyczna z stdcall. Ze względu na specyficzny cel istnienia tej konwencji, nie ma możliwości zadeklarowania zwykłej funkcji, która by jej używała.
A zatem dotychczas (nieświadomie!) używaliśmy tylko dwóch konwencji: cdecl dla zwykłych funkcji oraz thiscall dla metod obiektów.
To zadziwiające, że chyba najważniejsza dla programisty cecha funkcji, czyli jej nazwa, jest niemal zupełnie nieistotna dla działającej aplikacji! Jak już bowiem mówiłem, "widzi" ona swoje funkcje wyłącznie poprzez ich adresy w pamięci i przy pomocy tych adresów ewentualnie je wywołuje. Można dywagować, czy to dowód na całkowity brak skrzyżowania między drogami człowieka i maszyny, ale fakt pozostaje faktem, zaś jego przyczyna jest prozaicznie pragmatyczna.
Chodzi o wydajność: skoro funkcje programu są podczas jego uruchamiania umieszczane w pamięci operacyjnej (można ładnie powiedzieć: mapowane), to dlaczego system operacyjny nie miałby używać wygenerowanych przy okazji adresów, by w razie potrzeby rzeczone funkcje wywoływać? To przecież proste i szybkie rozwiązanie, naturalne dla komputera i niewymagające żadnego wysiłku ze strony programisty. Fajne to C++ - nieprawdaż?
Jedynie w czasie kompilacji kodu nazwy funkcji mają jakieś znaczenie. Kompilator musi bowiem zapewnić ich unikalność w skali całego projektu, tj. wszystkich jego modułów. Nie jest to wcale proste, jeżeli przypomnimy sobie o funkcjach przeciążanych, które z założenia mają te same nazwy. Poza tym funkcje o tej samej nazwie mogą też występować w różnych zakresach: jedna może być na przykład metodą jakiejś klasy, zaś druga zwyczajną funkcją globalną.
Kompilator rozwiązuje te problemy, stosując tak zwane dekorowanie nazw. Wykorzystuje po prostu dodatkowe informacje o funkcji (jej prototyp oraz zakres, w którym została zadeklarowana), by wygenerować jej niepowtarzalną, wewnętrzną nazwę. Zawiera ona wiele różnych dziwnych znaków w rodzaju @ , ^ , ! czy _ , dlatego właśnie jest określana jako nazwa dekorowana. Wywołania z użyciem takich nazw są umieszczane w skompilowanych modułach. Dzięki temu linker może bez przeszkód połączyć je wszystkie w jeden plik wykonywalny całego programu.
Ogromna większość funkcji nie może obyć się bez dodatkowych danych, przekazywanych im przy wywoływaniu. Pierwsze strukturalne języki programowania nie oferowały żadnego wspomagania w tym zakresie i skazywały na korzystanie wyłącznie ze zmiennych globalnych. C++ jednak aż taki stary nie jest. Przyjrzyjmy się zatem dokładniej, jak wywoływane są funkcje z parametrami.
Aby wywołać funkcję z parametrami, kompilator musi znać ich liczbę oraz typ każdego z nich. Informacje te podajemy w prototypie funkcji, zaś w jej kodzie zwykle nadajemy także nazwy poszczególnym parametrom, by móc z nich później korzystać. Parametry pełnią rolę zmiennych lokalnych w bloku funkcji - z tą jednak różnicą, że ich początkowe wartości pochodzą z zewnątrz, z kodu wywołującego funkcję. Na tym wszakże kończą się wszelkie odstępstwa, ponieważ parametrów możemy używać identycznie, jak gdyby było one zwykłymi zmiennymi odpowiednich typów. Po zakończeniu wykonywania funkcji są one niszczone, nie pozostawiając żadnego śladu po ewentualnych operacjach, które mogły być na nich dokonywane kodzie funkcji. Z tego wynika prosty wniosek: Parametry funkcji są w C++ przekazywane przez wartości. Zawsze przez wartości .... niezależnie od tego co pisałem wcześniej o przekazywaniu przez referencję czy o wskaźnikach. W obu wspomnianych wypadkach reguła przekazywania przez wartości jest tylko pozornie łamania. To złudzenie. W rzeczywistości także i tutaj do funkcji są przekazywane wyłącznie wartości - tyle tylko, że owymi wartościami są tu adresy odpowiednich komórek w pamięci. Za ich pośrednictwem możemy więc uzyskać dostęp do rzeczonych komórek, zawierających na przykład jakieś zmienne. Gdy dodatkowo korzystamy z referencji, wtedy nie wymaga to nawet specjalnej składni. Trzeba być jednak świadomym, że zjawiska te dotyczą samej natury wskaźników czy też referencji, nie zaś parametrów funkcji! Dla nich bowiem zawsze obowiązuje przytoczona wyżej zasada przekazywania poprzez wartość.