Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | 2. Wymagania użytkownika |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | środa, 1 lipca 2026, 07:24 |
Opis
W procesie wytwarzania oprogramowania jednym z kluczowych zagadnień jest określenie zakresu budowanego systemu. Wymagania użytkownika powinny opisać potrzeby klienta w sposób wystarczający do określenia rozmiaru systemu i nakładu pracy potrzebnej do jego zbudowania.
1. Wprowadzenie do wymagań użytkownika
1.1. Czym są i skąd się biorą wymagania użytkownika?
W procesie wytwarzania oprogramowania jednym z kluczowych zagadnień jest określenie zakresu budowanego systemu. Wymagania użytkownika powinny opisać potrzeby klienta w sposób wystarczający do określenia rozmiaru systemu i nakładu pracy potrzebnej do jego zbudowania. Specyfikacja wymagań użytkownika powinna zatem dostarczyć odpowiedzi na kluczowe w procesie zarządzania projektem pytania:
- Jak obszerna będzie funkcjonalność systemu?
- Jakie dane będzie przetwarzał system?
- Kto będzie się posługiwał systemem?
- Jakie zasoby (ludzie, czas, pieniądze) są potrzebne do zbudowania systemu?
Punktem wyjścia dla analityków oraz odbiorców przyszłego systemu przy formułowaniu wymagań użytkownika jest wizja sytemu. Zidentyfikowane wymagania użytkownika dokumentujemy, aby mogły się stać podstawą do zawarcia umowy między zamawiającym a wykonawcą systemu, w tym – do określenia zasobów niezbędnych do realizacji systemu. Wymagania użytkownika powinny być zatem na tyle precyzyjne, aby nie było niedomówień co do zakresu systemu. Jednocześnie, powinny być na tyle ogólne, aby nie sugerować rozwiązań technicznych (dotyczących np. implementacji interfejsu użytkownika, baz danych, itp.), co jest dopiero zadaniem projektantów systemu.
Rysunek 1.1 pokazuje podstawowe zasady przekształcania wizji systemu w zestaw wymagań użytkownika i utrzymywania spójności między nimi. Każda cecha funkcjonalna (tu: F098) powinna zostać poddana analizie pod kątem jej realizacji przez odpowiedni zestaw wymagań funkcjonalnych. Należy zwrócić uwagę na to, że cecha funkcjonalna może być przekształcona w kilka przypadków użycia (lub innych wymagań tego typu). Z drugiej strony, każde wymaganie funkcjonalne na poziomie wymagań użytkownika powinno wynikać z co najmniej jednej cechy sytemu. Podobnie jak wymagania funkcjonalne, przekształceniu podlegają wymagania jakościowe i ograniczenia. Przekształcenie polega najczęściej na doprecyzowaniu i określeniu metryk.
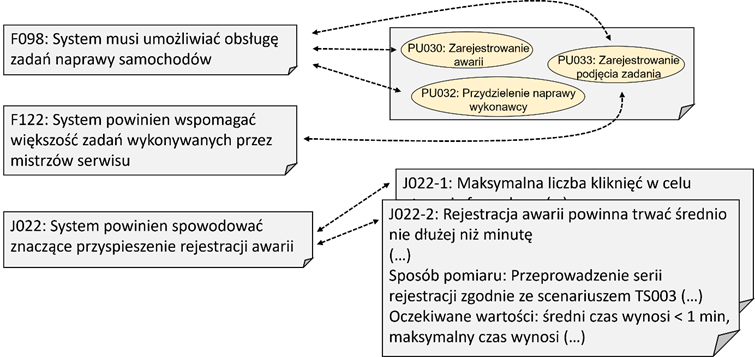
Rysunek 1.1: Zgodność wymagań użytkownika z wizją systemu
Jeśli planowany system jest zamawiany na rzecz organizacji biznesowej, to dobrym źródłem wymagań funkcjonalnych na poziomie wymagań użytkownika mogą być opisy procesów biznesowych. Zwróćmy uwagę na to, że takie postępowanie uzupełnia proces łowienia wymagań na podstawie cech systemu. Dzięki odniesieniu do szczegółowych czynności procesów biznesowych możemy łatwiej określić konkretne wymagania mieszczące się z zakresie budowy systemu.
1.2. Rodzaje wymagań użytkownika
Jednym z najczęściej spotykanych sposobów zapisu wymagań funkcjonalnych są przypadki użycia systemu. Notacja przypadków użycia jest oparta na bardzo prostych modelach graficznych. Zasadniczo składa się ona z dwóch elementów – aktorów (ikona człowieka) i przypadków użycia (elipsa), co ilustruje rysunek 1.2.
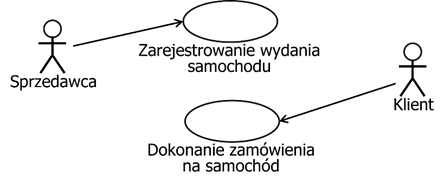
Rysunek 1.2: Przykładowy model przypadków użycia
Alternatywnym do przypadków użycia sposobem formułowania wymagań funkcjonalnych są historie użytkownika. Historie użytkownika opisują oczekiwania klienta w stosunku do tworzonego systemu za pomocą krótkich zdań mieszczących się np. na kartkach z notesu. Zdanie stanowiące historię użytkownika powinno określać podmiot historii (użytkownik, który czegoś chce od systemu), cel biznesowy realizowany przez system i oczekiwany przez użytkownika, oraz motywację klienta stojącą za konkretnym oczekiwaniem. Do formułowania historii użytkownika można wykorzystać następujący prosty wzorzec:
· Jako <rodzaj użytkownika> chcę <jakiś cel>, aby <jakiś powód>
Przykładowe historie, analogiczne do przypadków użycia z rysunku 1.2 przedstawia rysunek 1.3.
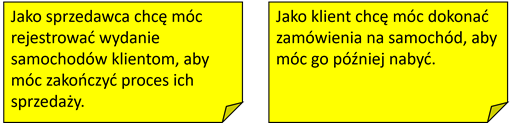
Rysunek 1.3: Przykładowy zestaw historii użytkownika
Drugim kluczowym składnikiem wymagań użytkownika są wymagania jakościowe. Wymagania te mogą w bardzo znaczącym stopniu wpłynąć na architekturę systemu, a tym samym – na koszt jego wykonania. Bardzo istotne jest zatem, aby zapewnić kompletność i jednoznaczność tego rodzaju wymagań na poziomie wymagań użytkownika. Kontrolę kompletności może nam zapewnić zachowanie zgodności z określoną taksonomią wymagań jakościowych. Istnieje wiele takich taksonomii, przy czym tutaj podamy ogólny podział w oparciu o normę ISO/IEC 25010:2011. Jest to standard przemysłowy, oparty na doświadczeniach z wielu rzeczywistych projektów. Identyfikuje on następujące rodzaje wymagań: Przydatność funkcjonalna, Efektywność wydajnościowa, Kompatybilność, Użyteczność, Niezawodność, Bezpieczeństwo, Łatwość utrzymania i Przenośność.
Aby móc sprawdzić stopień realizacji wymagań jakościowych należy określić dla nich metryki i związany z tym sposób testowania (patrz rys. 1.1, wymaganie J022-2). Na poziomie wymagań użytkownika konieczne jest określenie metryk na tyle precyzyjnych, żeby można było oszacować koszt realizacji systemu spełniającego te wymagania.
Trzecim rodzajem wymagań formułowanych na poziomie wymagań użytkownika są ograniczenia środowiskowe i techniczne. Ograniczenia zawężają możliwości odnośnie do projektowania i implementacji danego systemu oprogramowania. Przykład notacji dla ograniczeń przedstawia rysunek 4.

Rysunek 1.4: Przykładowy zestaw ograniczeń środowiskowych
Ostatnim rodzajem wymagań, zapewniającym spójność całej specyfikacji jest słownik dziedziny. W słowniku tym umieszczane są wszystkie pojęcia, stanowiące elementy dziedziny problemu, którą będzie wspierał tworzony system oprogramowania. Pojęcia te docelowo przekładają się na dane, które będzie musiał przechowywać oraz przetwarzać system. Ważnym elementem opisu słownika dziedziny jest zatem wyszczególnienie istotnych składników poszczególnych pojęć dziedzinowych. W szczególności, należy określić atrybuty pojęć, czyli elementarne jednostki danych, które będą podlegać przetwarzaniu.
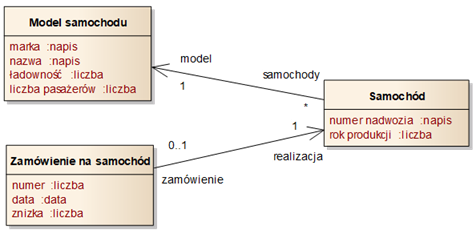
Rysunek 1.5: Przykładowy słownik dziedziny problemu
Słownik dziedziny może być opisany w tradycyjny sposób, czyli jako lista definicji pojęć w porządku alfabetycznym. W wielu przypadkach korzystniejsze jest przedstawienie słownika dziedziny w formie diagramu. Najczęściej używaną w tym celu notacją jest notacja modelu klas (język UML), zilustrowana na rysunku 1.5.
1.3. Organizowanie i dokumentowanie wymagań użytkownika
Podczas procesu zbierania wymagań użytkownika otrzymujemy pokaźny zbiór wymagań różnego rodzaju. W przypadku typowego, średniej wielkości systemu, samych wymagań funkcjonalnych może być kilkadziesiąt lub nawet kilkaset. Aby możliwe było zapanowanie nad taką liczbą wymagań, konieczne jest stworzenie logicznej struktury organizującej wszystkie jednostki wymagań.
Jak już zostało wspomniane, wymagań każdego rodzaju może być wiele. W celu lepszego panowania nad złożonością specyfikacji korzystne będzie podzielenie poszczególnych pakietów wymagań na pakiety składowe. Podstawową zasadą, którą należy się kierować grupując wymagania w pakiety, jest panowanie nad złożonością i zrozumiałość dla czytelników specyfikacji. Pomaga tutaj zasada 7 +/- 2, która określa ograniczenia percepcji. Przeciętny człowiek jest w stanie w danym momencie, w zależności od indywidualnych predyspozycji, przetwarzać w umyśle od 5 do 9 elementów. W przypadku większej liczby elementów konieczne jest zastosowanie dodatkowych technik (np. abstrakcji) w celu objęcia danego zagadnienia umysłem.
Niezależnie jednak od narzędzia, które jest wykorzystywane do zapisywania i zarządzania wymaganiami, klient najczęściej wymaga utworzenia specyfikacji w formie dokumentu podlegającego akceptacji. Wzór takiego dokumentu może być ustalony przez organizację zamawiającą system lub może być elementem warsztatu pracy analityków.
2. Specyfikowanie wymagań funkcjonalnych
2.1. Identyfikacja jednostek funkcjonalnych systemu
W typowym, interaktywnym systemie oprogramowania, cel biznesowy osiągamy w rezultacie przejścia przez ciąg interakcji użytkownika z systemem. Przykładowo, na rysunku 1 widzimy użytkownika, który chce uzyskać określony rezultat (np. zarejestrować nowego kontrahenta albo wydrukować listę kontrahentów). Aby osiągnąć ten rezultat, użytkownik musi najpierw wybrać określoną opcję w menu (pkt. 1 na rysunku). Efektem jest np. wyświetlenie formularza lub okienka na co użytkownik reaguje wprowadzeniem danych oraz wybraniem jednej z dostępnych w nowym oknie opcji (pkt. 2). Taki dialog między użytkownikiem a systemem może doprowadzić do osiągnięcia zamierzonego celu (pkt. 3 i 4). Może też zakończyć się niepowodzeniem (pkt. 3 i 5). Niepowodzenie może być spowodowane np. błędem walidacji danych lub wybraniem przez użytkownika opcji anulowania transakcji.
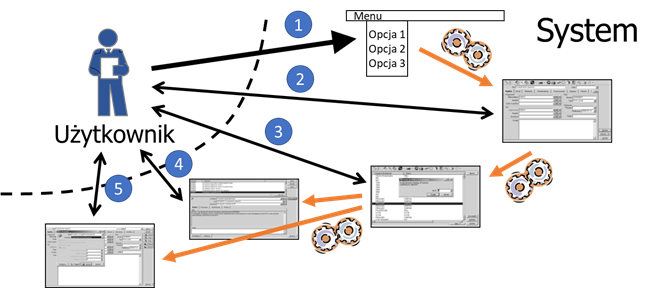
Rysunek 2.1: Współpraca systemu z użytkownikiem
Najczęściej stosowanymi jednostkami funkcjonalnymi prowadzącymi do uzyskania określonego rezultatu są wprowadzone już w poprzednich rozdziałach historie użytkownika oraz przypadki użycia. Punktem wyjścia do identyfikacji przypadków użycia lub historii użytkownika powinna być analiza cech systemu sformułowanych w wizji. Istotnym źródłem pomysłów na przypadki użycia może być również analiza procesów biznesowych. Podczas poszukiwania należy przede wszystkim pamiętać o podstawowych cechach charakteryzujących dobre jednostki funkcjonalne.
- Niezależność – możliwość realizacji danej funkcjonalności w jak największym stopniu niezależnie od innych;
- Negocjowalność – poziom ogólności dający możliwość ustalania szczegółów między klientem a wykonawcą;
- Cenność dla klienta – odpowiedni poziom korzyści, jakie klient (zamawiający, użytkownik) odniesie z implementacji tego wymagania;
- Szacowalność – możliwość dokonania racjonalnego szacowania rozmiarów oraz kosztu wykonania;
- Mały rozmiar – możliwość realizacji danego wymagania w stosunkowo krótkim czasie (kilka dni do kilku, np. 2-3 tygodni);
- Testowalność – możliwość udowodnienia spełnienia wymagania poprzez wykonanie testów.
Identyfikację przypadków użycia lub historii użytkownika może nam ułatwić wstępne zidentyfikowanie grup użytkowników systemu. W metodykach, które wykorzystują język UML, do tego celu wykorzystujemy aktorów. Aktor definiuje klasę obiektów spoza modelowanego systemu. Obiekty te mogą być osobami, urządzeniami lub zewnętrznym systemami informatycznymi. Możemy również powiedzieć, że aktor definiuje rolę graną przez obiekty w stosunku do danego systemu. Ważne jest to, że aktor nie może określać jakiejkolwiek części modelowanego systemu oprogramowania. W metodykach wykorzystujących historie użytkownika równoważnikiem aktorów są role użytkowników.
2.2. Historie użytkownika
Koncepcja historii użytkownika (ang. User Story) została zaproponowana po raz pierwszy przez Kenta Becka w ramach jego metodyki eXtreme Programming (XP) pod koniec lat 90. XX wieku. Od tamtego czasu, notacja i techniki związane z historiami użytkownika zyskały sporą popularność. Są one wykorzystywane w różnych projektach prowadzonych w sposób zwinny (ang. Agile), np. przy pomocy popularnej metodyki Scrum.
Treść historii użytkownika zawiera jedynie najważniejszą informację o zachowaniu się systemu z punktu widzenia przyszłego użytkownika. Historia użytkownika jedynie sygnalizuje potencjalną funkcjonalność systemu i jest punktem wyjścia do dyskusji o sposobach jej realizacji oraz walidacji. Ważne jest to, że historie użytkownika zachęcają w ten sposób do współpracy przedstawicieli klienta i wykonawcy. Oto kilka wzorców, które można zastosować pisząc historie użytkownika:
- Jako <rodzaj użytkownika> chcę <jakiś cel>, aby <jakiś powód> (np. Jako klient chcę złożyć zamówienie na samochód, aby rozpocząć proces jego zakupu.)
- <rodzaj użytkownika> chce <jakiś cel>, aby <jakiś powód> (np. Klient chce złożyć zamówienie na samochód – tu pomijamy opcjonalną część „dlaczego”.)
Na rysunku 2 przedstawiamy przykłady historii użytkownika o typowych rozmiarach. Typowo, takie historie można zrealizować w kilka dni pracy zespołu deweloperskiego.
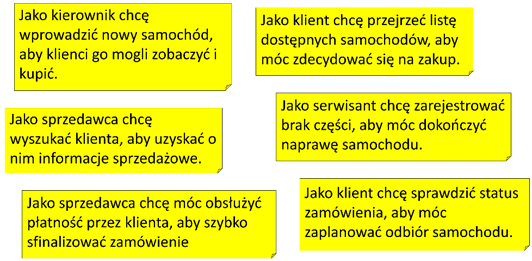
Rysunek 2.2: Przykłady historii użytkownika
2.3. Przypadki użycia i aktorzy
Model przypadków użycia został po raz pierwszy wprowadzona przez Ivara Jacobsona w połowie lat 90. XX wieku, podobnie jak w przypadku historii użytkownika. Ivar Jacobson jest również jednym z twórców języka UML (obok Grady’ego Boocha i Jamesa Rumbaugh). Dlatego też notacja przypadków użycia jest jednym z podstawowych modeli języka UML. Podstawowymi elementami modelu przypadków użycia są aktorzy i przypadki użycia. Model zawiera również relacje między nimi.
Podstawową notacją aktora w języku UML jest ikona człowieka narysowana prostymi kreskami, co ilustruje rysunek 2.3 (ikona po lewej stronie). Tak jak w przypadku innych elementów modeli, również aktorom można nadawać stereotypy. Częstą praktyką jest nadawanie stereotypu «system» aktorom definiującym zewnętrzne systemy informatyczne (ikona w środku rysunku). Jeśli stosujemy odpowiednie narzędzie do modelowania w języku UML, nadanie stereotypu może być również związane ze zmianą kształtu ikony (ikona po prawej stronie).

Rysunek 2.3: Warianty notacji aktora
Możliwe jest stosowanie relacji generalizacji między aktorami. Przykład zastosowania tych relacji widzimy na rysunku 2.4. W przykładzie tym, najbardziej ogólnym aktorem jest „Pracownik firmy”. Pozostali aktorzy specjalizują (dziedziczą) od niego zgodnie z odpowiednio skierowanymi relacjami. Aktorzy szczegółowi dziedziczą zakres odpowiedzialności, ale mogą uczestniczyć z kolejnych przypadkach użycia, które poszerzają ich zakres odpowiedzialności.
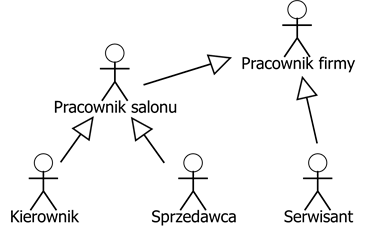
Rysunek 2.4: Relacje generalizacji dla aktorów
Przypadek użycia definiujemy jako klasę zachowań modelowanego systemu (tzw. podmiotu), prowadzących do osiągnięcia obserwowalnego, istotnego rezultatu dla jakiegoś aktora (lub aktorów). Podstawową notacją dla przypadków użycia w języku UML jest ikona elipsy, co ilustruje rysunek 2.5. Nazwa przypadku użycia może być umieszczona pod lub wewnątrz elipsy. Jako ciekawostkę można przytoczyć wariant notacji, który stosuje ikonę klasy (po prawej stronie rysunku). Jest to rzadko spotykana notacja, która nawiązuje do faktu, że przypadki użycia są rodzajem klas.

Rysunek 2.5: Warianty notacji przypadku użycia
Każdy przypadek użycia powinien mieć jasno określony cel, który powinien wynikać z jego nazwy. Warto tutaj przestrzegać określonych konwencji, które ułatwiają określenie celu przypadku użycia. Ważne jest, aby nazwy były pisane w jednolitej formie. Można na przykład przyjąć formę, w której stosujemy rzeczowniki odczasownikowe (np. „Zarejestrowanie pojazdu”, „Dodanie użytkownika”, „Pokazanie …”, „Obsłużenie …”). Inną formą jest forma polecenia (np. „Zarejestruj pojazd”, „Dodaj użytkownika”, „Pokaż …”, „Obsłuż …”).
Na diagramach przypadków użycia umieszczamy aktorów i przypadki użycia wraz z łączącymi je relacjami. Na rysunku 2.6 widzimy diagram zawierający przykłady takich relacji. Najczęściej spotykaną jest relacja asocjacji między aktorem i przypadkiem użycia. Relacja ta oznacza możliwość uczestnictwa danego aktora w powiązanym z nim przypadku użycia. W ramach takiego uczestnictwa, aktor może być tzw. aktorem głównym. Oznacza to, że aktor uruchamia dany przypadek użycia i jest on realizowany na jego rzecz.
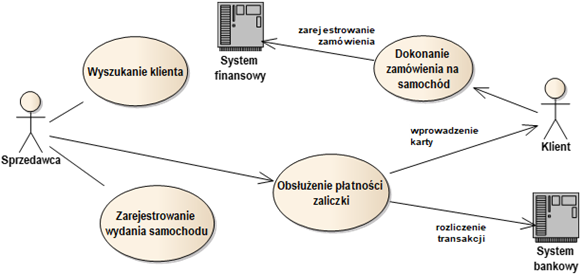
Rysunek 2.6: Przykładowy diagram przypadków użycia
Aktor może również pełnić rolę poboczną (pomocniczą) w relacji z przypadkiem użycia. Oznacza to, że aktor zaczyna brać udział dopiero w dalszych krokach scenariuszy danego przypadku użycia. Przykładowo, może to oznaczać, że system w pewnym momencie wyświetla na ekranie aktora pobocznego monit (np. komunikat o konieczności potwierdzenia operacji). Aktor musi wtedy zareagować na taki monit, aby wykonanie przypadku użycia mogło być kontynuowane. Przykładem na rysunku 8 są relacje przypadku użycia „Obsłużenie płatności zaliczki” z aktorami „Klient” i „System bankowy
2.4. Relacje między przypadkami użycia
Oprócz relacji między aktorami i przypadkami użycia często stosowane są relacje między przypadkami użycia. Język UML standardowo definiuje dwie relacje zależności – relację «include» i relację «extend». Dzięki temu możliwe jest bardziej precyzyjne wyróżnienie poszczególnych przypadków użycia. Możliwe jest również zastosowanie przypadków użycia w różnych kontekstach. Relacje «include» i «extend» ilustruje rysunek 2.7, który jest rozwinięciem rysunku 2.6.
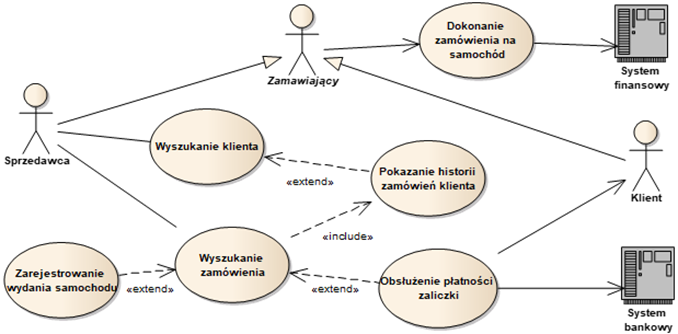
Rysunek 2.7: Model przypadków użycia z relacjami «include» i «extend»
Relacja «include» („wstawienie”) oznacza bezwarunkowe włączenie w treść scenariuszy jednego przypadku użycia, treści scenariuszy innego. Na rysunku 2.7 widzimy jedną taką relację, oznaczoną przerywaną strzałką z odpowiednim stereotypem.
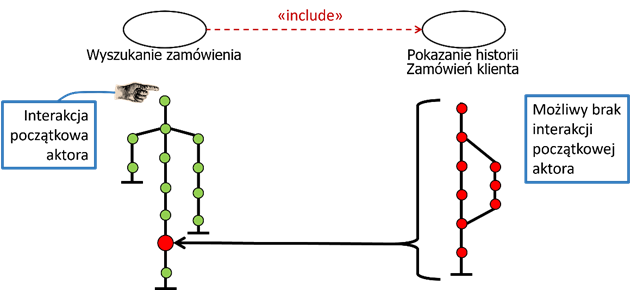
Rysunek 2.8: Włączenie treści przypadku użycia dla relacji «include»
Zasadę działania relacji «include» ilustruje rysunek 2.8. Na rysunku, interakcje (kroki scenariuszy) symbolizują kropki. W naszym przykładzie, cała treść przypadku użycia po prawej stronie jest wstawiona w odpowiednim punkcie treści drugiego przypadku użycia (po lewej stronie). Zwróćmy uwagę na to, że wstawienie treści nie podlega żadnym warunkom. Jednocześnie, należy podkreślić, że wykonanie przypadku użycia włączającego (tu: „Wyszukanie zamówienia”) nie musi zawsze zawierać wykonania przypadku użycia włączanego (tu: „Pokazanie historii …”). Możliwe jest wykonanie zgodne z jednym ze scenariuszy alternatywnych, który nie zawiera włączenia
Druga z relacji to relacja «extend» („rozszerzenie”). Oznacza ona możliwość wplecenia treści scenariuszy przypadku użycia rozszerzającego w treść scenariuszy przypadku użycia rozszerzanego. Możliwość wplecenia może podlegać określonym warunkom, które powinny być dołączone do specyfikacji danej relacji «extend».
Przypadek użycia rozszerzający może mieć kilka części wplatanych w przypadki rozszerzane. Przykład takiej sytuacji ilustruje rysunek 2.9. Widzimy tutaj, że przypadek użycia „Obsłużenie stałego klienta” rozszerza przypadek użycia „Zarejestrowanie wydania samochodu”. Rozszerzenie polega na warunkowym wpleceniu dwóch fragmentów funkcjonalności do treści przypadku rozszerzanego. Warunkiem wplecenia jest to, że klient jest zarejestrowany, czyli jest stałym klientem. Pierwszy fragment dotyczy przypomnienia na początku rejestrowania wydania samochodu, że klient jest stałym klientem. Drugi fragment dotyczy możliwości wprowadzanie danych karty rabatowej w celu otrzymania punktów rabatowych.
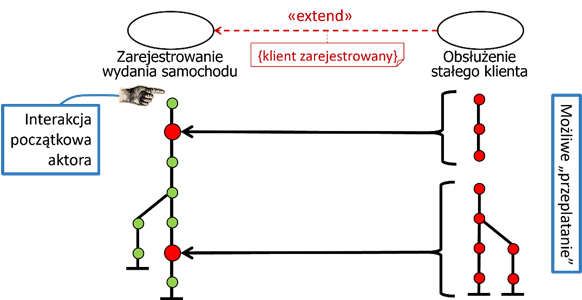
Rysunek 2.9: Wplecenie treści przypadku użycia dla relacji «extend»
Semantyka relacji «include» i «extend» oparta jest na bezwarunkowym lub warunkowym wstawianiu treści jednych przypadków użycia w treść innych. Zrozumienie tej semantyki często sprawia kłopoty. W szczególności, często popełnianym błędem jest niewłaściwe skierowanie relacji. Z tego powodu powstała propozycja alternatywy - relacji «invoke». Relacja ta ma semantykę podobną do semantyki wywołania procedury. Zawsze jest skierowana od przypadku wywołującego do przypadku wywoływanego. Wywołanie może być bezwarunkowe lub możemy dla niego określić warunek. Rysunek 2.10 pokazuje fragment zawierający wybranych aktorów i przypadki użycia z rysunku2.6, gdzie zamiast standardowych relacji zastosowano relacje «invoke».
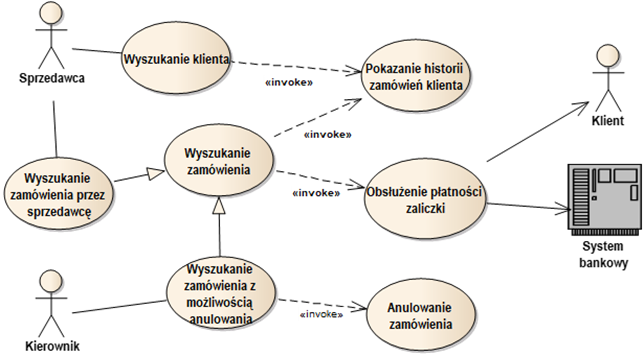
Rysunek 2.10: Zastosowanie relacji «invoke»
Działanie relacji «invoke» ilustruje rysunek 2.11. Widzimy tutaj dwa warianty relacji. Pierwszy wariant jest opatrzony warunkiem. Spełnienie tego warunku po dotarciu do odpowiedniego punktu w przypadku użycia „Pokazanie listy samochodów” powoduje uruchomienie scenariuszy przypadku użycia „Usunięcie zamówienia samochodu”. W drugim wariancie, scenariusze przypadku użycia „Przejrzenie historii zamówienia” są bezwarunkowo uruchamiane po dotarciu do odpowiedniego punktu w scenariuszu przypadku użycia „Usunięcie zamówienia samochodu”.
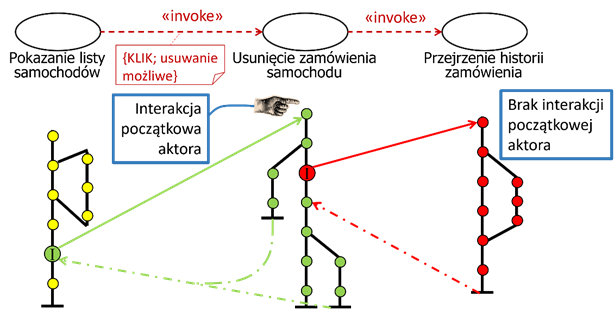
Rysunek 2.11: Wywołanie przypadków użycia w relacji «invoke»
Podobnie jak dla aktorów, również między przypadkami użycia możliwe jest stosowanie relacji generalizacji. Oznacza ona, że przypadek użycia specjalizowany dziedziczy cechy przypadku użycia ogólnego. Rysunek 2.10 dostarcza nam odpowiedniego przykładu. Przypadek użycia „Wyszukanie zamówienia z możliwością anulowania” specjalizuje „Wyszukanie zamówienia”. Oznacza to, że sprzedawca ma do dyspozycji podstawową funkcjonalność wyszukiwania zamówienia, która m.in. umożliwia uruchomienie funkcjonalności „Pokazania historii zamówień klienta”. Kierownik ma natomiast do dyspozycji przypadek użycia, który rozszerza możliwość wyszukiwania zamówień o funkcjonalność przypadku użycia „Anulowanie zamówienia”.
2.5. Opisy historii użytkownika i przypadków użycia
Na poziomie wymagań użytkownika wystarczy znacznie bardziej uproszczony opis poszczególnych jednostek wymagań funkcjonalnych. Oczywiste jest jednak, że ograniczenie się do samych historii użytkownika w formie pojedynczych zdań lub diagramów zawierających przypadki użycia z relacjami nie jest wystarczające
Historie użytkownika są z zasady bardzo „lekkim” sposobem formułowania wymagań funkcjonalnych. Opis historii użytkownika nie jest zatem w szczególny sposób sformalizowany. Mimo to, przyjmuje się, że kompletna historia użytkownika powinna składać się z trzech zasadniczych elementów (tzw. KKK):
- Karta – jedno zdanie, mieszczące się na typowej karcie katalogowej, zapisane zgodnie z wzorem typu „Jako … chcę … aby …”. Sposób tworzenia karty został przedstawiony w sekcji 2.2.
- Konwersacja – dodatkowy opis historii użytkownika, który jest wynikiem dyskusji nad szczegółami wpływającymi na jej implementację. Konwersacja może być zapisana w swobodnym języku naturalnym.
- Konfirmacja (potwierdzenie) – zestaw kilku testów akceptacyjnych, które miałyby potwierdzić prawidłowość implementacji historii użytkownika. Testy na tym poziomie opisane są w sposób skrótowy i powinny się z zasady mieścić na drugiej stronie karty katalogowej.
Przykładowo, dla historii „Jako serwisant chcę zarejestrować brak części, aby móc dokończyć naprawę samochodu” moglibyśmy zanotować następującą „konwersację”:
- Serwisant powinien móc wybrać parametry części z dostępnej listy.
- Po wpisaniu częściowego numeru części system powinien podpowiedzieć cały symbol na podstawie katalogu części.
- Zgłoszenie braku części powinno być porównane ze stanem magazynu części.
Trzecim elementem opisu historii użytkownika, który możemy wykonać na poziomie wymagań użytkownika jest konfirmacja. Formułujemy tutaj proste zdania opisujące możliwe testy, które powinny udowodnić prawidłowość działania historii użytkownika. Przykładowo, testy dla przykładowej konwersacji mogłyby wyglądać następująco:
- Lista parametrów wyświetlona serwisantowi powinna zawierać wszystkie parametry wprowadzone podczas konfiguracji parametrów.
- Gdy serwisant wprowadzi kilka liter symbolu, powinien otrzymać podpowiedzi zgodne z aktualnym stanem katalogu części.
- Jeśli serwisant zgłosi brak części, a dana część jest w magazynie, powinno zostać pokazane ostrzeżenie.

Rysunek 2.12: Przykładowy opis przypadku użycia
Nieco inny sposób opisu stosowany jest typowo dla przypadków użycia, co ilustruje rysunek 2.12. Główna część zawiera podobną treść do konwersacji historii użytkownika. Opis jest wykonany w języku naturalnym, przy czym wyróżnione zostały pojęcia istotne dla danej dziedziny problemu („część”, „zgłoszenie braku części” itd.). W naszym przykładzie widzimy dodatkowo dwie sekcje zawierające warunki. Pierwszy warunek jest warunkiem rozpoczęcia (ang. precondition). Zawiera on stwierdzenia, które muszą być prawdziwe, aby przypadek użycia mógł być uruchomiony przez aktora głównego. Druga sekcja warunków zawiera warunki zakończenia (ang. postcondition). Może ich być kilka, gdyż wykonanie przypadku użycia może się zakończyć na różne sposoby (np. sukces lub porażka). Warunki zakończenia dają zatem rozeznanie w możliwej złożoności przypadku użycia z punktu widzenia możliwych alternatywnych przebiegów.
3. Specyfikowanie wymagań jakościowych i ograniczeń
3.1. Sposób opisu wymagań jakościowych
Wymagania jakościowe można klasyfikować w różny sposób. Każda klasyfikacja dzieli takie wymagania na różne typy. Przykładowo, klient może wymagać odpowiednio krótkiego czasu odpowiedzi systemu, odpowiedniego poziomu dokładności obliczeń czy też łatwości wykonywania określonych czynności. Z uwagi na wielość klasyfikacji i typów wymagań jakościowych nie istnieje jednolity, sformalizowany sposób ich zapisu. Najczęściej wymagania tego typu tworzone są jako fragmenty tekstu wyrażone w języku naturalnym. Nazwy wymagań jakościowych najczęściej formułuje się w postaci prostych zdań zawierających orzeczenia modalne oparte o czasowniki takie jak musieć, być, zawierać. Oto kilka przykładowych zdań tego typu, zapisanych w formie „System będzie/może/musi/powinien …”:
- System będzie przechowywał dane osobowe w formie zaszyfrowanej
- System musi pokazywać wartości wagowe z dokładnością do 1mg
- System powinien wyświetlać mapę terenu przeciętnie w 2 sekundy
Struktura opisu wymagania jakościowego na poziomie wymagań użytkownika może być podobna do opisu wymagania funkcjonalnego. Istotną różnicą jest konieczność zdefiniowania zobiektywizowanej metryki wymagania. Metryka powinna określać sposób walidacji spełnienia wymagania oraz definiować możliwie obiektywne kryteria akceptacji. O metrykach wymagań jakościowych piszemy bardziej szczegółowo w dalszej części niniejszego rozdziału. Ogólnie, możemy wyróżnić następujące elementy kompletnego opisu wymagania jakościowego: nazwa wymagania, standardowe atrybuty wymagania, rodzaj wymagania, opis wymagania, metryka wymagania.
Na 3.1 pokazujemy kilka przykładowych fiszek wymagań jakościowych. Jak widzimy, metryki wymagań są przedstawione w sposób zobiektywizowany, ale bez wchodzenia zbytnio w szczegóły procedury testowania, przy czym zależą w bardzo istotny sposób od rodzaju wymagania. Dla przykładu, wymaganie JU012 na rysunku 3.1 jest rodzaju „użyteczność-operacyjność” i metryka dotyczy pomiaru czasy wykonania scenariusza przypadku użycia. Z kolei, wymaganie JK023 jest rodzaju „kompatybilność-interoperacyjność” i metryka jest już innego rodzaju. Dotyczy ona prawidłowości przesyłania danych z systemem zewnętrznym.
|
ID: JU012 |
Nazwa: System powinien umożliwiać szybkie dodawanie samochodów |
||
|
Wersja: 1.0 |
Waga klienta: ważne |
Waga wykonawcy: średnie |
|
|
STATUS |
Trudność: 2 |
Wydanie: 0.21 |
Odpowiedzialny: Magda |
|
Rodzaj: użyteczność – operacyjność |
|||
|
Opis: Średni czas dodania do systemu nowego samochodu nie powinien przekroczyć 2 minut, a maksymalnie może być dwa razy wyższy. Dotyczy przypadku użycia PU076. |
|||
|
Sposób pomiaru: Mierzymy czas, jaki zajmie magazynierowi dodanie nowego samochodu, czyli przejście przez główny scenariusz PU076. Pomiaru dokonujemy na próbie 10 osób po 30 minutach przeszkolenia. Każda osoba dodaje po 10 samochodów. |
|||
|
Możliwy wynik pomiaru: Czas mierzymy z dokładnością do 5 sekund w zakresie od 5 sekund do 10 minut (powyżej 10 minut uznaje się, że magazynier nie był w stanie dodać samochodu). |
|||
|
Oczekiwane wartości: Średni czas dla całej grupy wynosi mniej niż 2 minuty. Najgorszy czas wynosi poniżej 4 minut. |
|||
|
ID: JE021 |
Nazwa: System musi szybko wyświetlać ekran podsumowania czynności magazynowych |
||
|
Wersja: 1.1 |
Waga klienta: kluczowe |
Waga wykonawcy: średnie |
|
|
STATUS |
Trudność: 7 |
Wydanie: 0.21 |
Odpowiedzialny: Stefan |
|
Rodzaj: efektywność wydajnościowa – czas |
|||
|
Opis: Czas, w którym system wyświetla ekran podsumowania czynności magazynowych musi wynosić średnio poniżej 2 sek. Magazynier nie powinien czekać dłużej niż 5 sekund przy najgorszym obciążeniu systemu. Dotyczy przypadku użycia PU081, krok 5. |
|||
|
Sposób pomiaru: Mierzymy czas od momentu wybrania opcji wyświetlania ekranu podsumowania (krok 4) do momentu pełnego wyświetlenia ekranu (krok 5). Pomiaru dokonujemy przy różnych poziomach obciążenia systemu zgodnie z zasadą OB011. Wyniki mierzymy dla 100 prób na każdy poziom obciążenia. |
|||
|
Możliwy wynik pomiaru: Czas mierzymy z dokładnością do 0,1 sekund w zakresie od 0,1 sekund do 1 minuty (powyżej 1 minuty uznaje się, że system nie wyświetlił prawidłowo ekranu). |
|||
|
Oczekiwane wartości: Średni czas dla wszystkich poziomów obciążenia wynosi mniej niż 2 sekundy. Najgorszy czas dla poziomu obciążenia 5 wynosi mniej niż 5 sekund. |
|||
|
ID: JK023 |
Nazwa: System musi umożliwiać współpracę z systemem CEPiK |
||
|
Wersja: 1.0 |
Waga klienta: kluczowe |
Waga wykonawcy: trudne |
|
|
STATUS |
Trudność: 21 |
Wydanie: 0.21 |
Odpowiedzialny: Stefan |
|
Rodzaj: kompatybilność – interoperacyjność |
|||
|
Opis: System będzie umożliwiał wymianę danych o sprowadzanych i sprzedawanych samochodach z systemem CEPiK. Wymiana odbywać się będzie poprzez API dostarczane przez system CEPiK. Dotyczy wszystkich przypadków użycia w relacji z aktorem System CEPiK. |
|||
|
Sposób pomiaru: W trakcie testów akceptacyjnych (TA056 do TA071) sprawdzamy działanie systemu pod kątem współpracy z API systemu CEPiK. Sprawdzamy prawidłowość przesyłu danych o pojazdach oraz rejestracjach pojazdów. Przesył danych sprawdzamy dla różnych prędkości łącza oraz dla różnych poziomów obciążenia. |
|||
|
Możliwy wynik pomiaru: Liczba prawidłowo przesłanych rekordów w stosunku do wszystkich prób, w rozbiciu na prędkości łącza oraz poziomy obciążenia (0-100%). |
|||
|
Oczekiwane wartości: Dla prędkości łącza powyżej 1Mb/s oraz poziomu obciążenia poniżej 3, poziom przesyłu wynosi 100%. Dla niższych prędkości oraz od 3 poziomu w górę, poziom przesyłu wynosi co najmniej 98%. W przypadku przesyłów nieprawidłowych, błąd jest zarejestrowany we wszystkich przypadkach. |
|||
Rysunek 3.1: Przykładowe fiszki wymagań jakościowych
3.2. Rodzaje wymagań jakościowych
Tak jak wspomnieliśmy w pierwszych rozdziałach podręcznika, bardzo istotną cechą dobrej jakościowo specyfikacji wymagań jest jej kompletność. W przypadku wymagań jakościowych konieczne jest uwzględnienie szerokiego zakresu różnych rodzajów wymagań. Dwa podstawowe ujęcia, dotyczą kwestii wykonywania programu oraz kwestii ewolucji systemu. Przy pierwszym podejściu wymienia się najczęściej wydajność, użyteczność, bezpieczeństwo oraz przenośność. Druga perspektywa identyfikuje parametry związane z utrzymaniem systemu, takie jak koszt zmian, skalowalność, testowalność, łatwość analizy, stabilność czy dojrzałość. Na przestrzeni lat, praktycy inżynierii wymagań zauważyli, że bardzo łatwo jest pominąć niektóre rodzaje wymagań jakościowych. Aby temu zaradzić zaproponowano różne klasyfikacje (taksonomie) wymagań, których istotą jest stworzenie pewnego rodzaju listy kontrolnej.
Najbardziej chyba szczegółową i wyczerpującą klasyfikacją wymagań jakościowych jest klasyfikacja zawarta w normie ISO/IEC 25010:2011 - Systems and software engineering, Systems and software Quality Requirements and Evaluation (SQuaRE), System and software quality models (Inżynieria systemowa i oprogramowania, Wymagania i ocena jakości systemów i oprogramowania, Modele jakości systemów i oprogramowania). Model ten zawiera podział na osiem grup. Dla każdej z tych grup określimy podgrupy oraz podamy po kilka przykładowych nazw wymagań.
Przydatność funkcjonalna (ang. Functional suitability) dotyczy spełniania przez system, używany w określonych warunkach, wyrażonych lub domniemanych potrzeb. Obszar ten obejmuje w szczególności określenie stopnia i dokładność pokrycia oczekiwanej funkcjonalności.
- kompletność funkcjonalna(ang. functional completeness) – stopień, w jakim zbiór funkcji pokrywa wszystkie wyspecyfikowane zadania oraz cele użytkowników,
- poprawność funkcjonalna (ang. functional correctness) – stopień, w jakim system zapewnia prawidłowe rezultaty z wymaganym poziomem dokładności,
- adekwatność funkcjonalna (ang. functional appropriateness) – stopień, w jakim funkcje ułatwiają wykonanie zadań i osiągnięcie celów.
Efektywność wydajnościowa (ang. Performance efficiency) obejmuje zbiór atrybutów opisujących powiązania między poziomem wydajności oprogramowania, a wykorzystywanymi zasobami (konfiguracji sprzętu i oprogramowania oraz materiałów eksploatacyjnych) przy spełnieniu określonych warunków. Obejmuje on wymagania dotyczące czasu reakcji, zużycia zasobów i wielkości zadań, z którymi musi radzić sobie system.
- czas (ang. time behaviour) – stopień, w jakim czasy odpowiedzi (przetwarzania danych) i wskaźniki przepustowości systemu podczas wykonywania jego funkcji spełniają wymagania,
- zużycie zasobów (ang. resource utilization) – stopień, w jakim ilości różnych typów zasobów (technologicznych) używanych przez system podczas wykonywania jego funkcji, spełniają wymagania,
- pojemność (ang. capacity) – stopień, w jakim maksymalne limity parametrów systemu (liczba przechowywanych elementów, liczba jednoczesnych użytkowników, rozmiar przestrzeni danych itp.) spełniają wymagania.
Kompatybilność (ang. Compatibility) dotyczy zdolności do wymiany informacji z innymi produktami, systemami lub komponentami i/lub wykonywania zadanych funkcji współdzieląc ten sam sprzęt lub środowisko software’owe. Ogólnie zatem, dotyczy współpracy z innymi systemami oprogramowania.
- współistnienie (ang. co-existence) – stopień, w jakim system może efektywnie wykonywać swoje funkcje podczas dzielenia wspólnego środowiska i zasobów z innymi systemami, bez negatywnego wpływu na działanie,
- interoperacyjność (ang. interoperability) – stopień, w jakim dwa lub więcej systemów mogą wymieniać i używać wymieniane informacje.
Użyteczność (ang. Usability) dotyczy dostosowania sposobu użycia systemu do potrzeb użytkowników. Oznacza to kwestie jakości wrażeń użytkownika z użytkowania systemu od pierwszych kontaktów z systemem, poprzez naukę korzystania do efektywności współdziałania.
- rozpoznawalność odpowiedniości (ang. appropriateness recognizability) – możliwość rozpoznania przez użytkowników czy produkt jest odpowiedni dla ich potrzeb; np. rozpoznanie na podstawie pierwszego wrażenia z użycia, dostarczonej dokumentacji, demonstracji, strony webowej,
- łatwość nauczenia (ang. learnability) – miara wysiłku, jaki musi włożyć użytkownik do nauczenia się nieznanych lub nowych funkcji aplikacji w celu osiągnięcia niezbędnej efektywności działania i/lub satysfakcji,
- operacyjność (ang. operability) – nakład pracy użytkownika niezbędny do obsługi i kontroli funkcji realizowanych przez oprogramowanie,
- zabezpieczenie przed błędami użytkownika (ang. user error protection) – stopień, w jakim system zapobiega popełnianiu błędów przez użytkowników,
- estetyka interfejsu użytkownika (ang. user interface aesthetics) – stopień, w jakim system zapewnia przyjemne i satysfakcjonujące współdziałanie użytkownika z systemem,
- przystępność (ang. accessibility) – stopień dostosowania systemu do potrzeb użytkowników ze specjalnymi potrzebami (np. osoby niepełnosprawne).
Niezawodność (ang. Reliability) dotyczy zapewnienia określonego poziomu działania systemu w określonym czasie przy założonych zasobach. Wymagania te opisują stopień odporności systemu na nieprzewidziane sytuacje, związane ze zdarzeniami zewnętrznymi oraz spowodowanymi przez system.
- dojrzałość (ang. maturity) – poziom zapewnienie niezawodnego działania (brak defektów) systemu w normalnych warunkach,
- dostępność (ang. availability) – poziom dostępności i operacyjności działania systemu, kiedy jego działanie jest wymagane,
- odporność na błędy (ang. fault tolerance) – zdolność do stabilnego funkcjonowania nawet w przypadku wystąpienia błędu lub niestabilnego działania sprzętu lub oprogramowania systemowego,
- odtwarzalność (ang. recoverability) – zdolność oprogramowania do przywrócenia stabilnego i wydajnego działania po awarii oraz przywrócenia stanu danych sprzed awarii.
Bezpieczeństwo (ang. Security) dotyczy ochrony danych przez system. Obejmuje stopień zabezpieczenia danych przez system, który umożliwia do nich dostęp odpowiedni do rodzajów uprawnień użytkowników lub innych systemów.
- poufność (ang. confidentiality) – zapewnienie dostępu do danych tylko dla jednostek do tego autoryzowanych,
- integralność (ang. integrity) – uniemożliwienie nieautoryzowanej możliwości zmiany programów i danych,
- niezaprzeczalność (ang. non-repudiation) – zapewnienie możliwości dowiedzenia wykonania akcji, tak, aby nie można im było zaprzeczyć w przeszłości,
- odpowiedzialność (ang. accountability) – zapewnienie identyfikacji jednostki odpowiedzialnej za akcje,
- autentyczność (ang. authenticity) – zapewnienie identyfikacji tożsamości jednostki (osoby).
Łatwość utrzymania (ang. Maintainability) dotyczy nakładów pracy koniecznych podczas utrzymywania systemu w eksploatacji. Obejmuje to wymagania związane z koniecznością aktualizacji systemu, rozszerzania jego funkcjonalności w przyszłości czy też poprawiania ewentualnych błędów znajdowanych podczas eksploatacji.
- modularność (ang. modularity) – poziom podziału na rozdzielne komponenty i ich wzajemnego wpływu,
- reużywalność (ang. reusability) – możliwość wykorzystania zasobu w więcej niż jednym systemie,
- łatwość analizy (ang. analysability) – nakład pracy konieczny do identyfikacji niedoskonałości, przyczyn defektów lub wskazania tych części oprogramowania, które powinny zostać poddane modyfikacji,
- łatwość zmiany (ang. modifiability) – nakład pracy konieczny do implementacji zmiany, usunięcia zidentyfikowanego błędu lub dostosowania aplikacji do nowego środowiska,
- testowalność (ang. testability) – nakład pracy potrzebny do weryfikacji poprawności działania aplikacji po wprowadzeniu do niej modyfikacji.
Przenośność (ang. Portability) dotyczy możliwości działania, instalacji i zamiany oprogramowania na różnych środowiskach sprzętowych, systemowych i software’owych.
- adaptowalność (ang. adaptability) – możliwość dostosowania oprogramowania do różnych, wyspecyfikowanych środowisk, bez konieczności realizacji dodatkowych czynności lub środków poza tymi, które są obecne w samym oprogramowaniu,
- łatwość instalowania (ang. installability) – nakład pracy konieczny do instalacji oprogramowania w danym środowisku,
- łatwość zamiany (ang. replaceability) – zdolność oprogramowania, do zastąpienia innej, konkretnej aplikacji w jej środowisku.
3.3. Formułowanie metryk dla wymagań jakościowych
Zdefiniowanie sposobów dokonywania pomiarów wymagań jakościowych jest kwestią bardzo istotną, gdyż może mieć decydujący wpływ na wycenę realizacji systemu. Dlatego też, konieczne jest określenie metryk wymagań jakościowych, które pozwolą na dokonanie możliwie precyzyjnego szacowania rozmiarów systemu i kosztu jego implementacji. Aby szacowanie było możliwe, metryka powinna posiadać trzy elementy:
- Przedstawienie sposobu pomiaru – opis procedury pomiarowej, uwzględniający najważniejsze elementy procesu ustalania wartości mierzonej wartości, czyli dokonywania pomiaru.
- Określenie zbioru możliwych wartości pomiaru – opis jednostek, w jakich będzie dokonywany pomiar (fizycznych, logicznych, symbolicznych) oraz możliwy zakres pomiarowy.
- Określenie oczekiwanych wartości pomiaru – opis wartości pomiaru, które są oczekiwane, wraz z charakterystyką możliwych błędów, przy czym wartości te mogą być różne w zależności od warunków dokonywania pomiaru.
Podczas formułowania metryki najważniejsze jest znalezienie właściwej procedury pomiaru dla dennego wymagania jakościowego. Ogólnie można rozróżnić kilka podstawowych klas tego typu procedur.
- Dokonanie bezpośredniego pomiaru parametrów systemu (eksperyment). Parametrami mogą być m.in. czas, liczba transakcji w czasie, zajętość pamięci, czy też procent wykorzystanych zasobów fizycznych (papier, tusz). Pomiar dokonywany jest przy pomocy odpowiednich narzędzi pomiarowych.
- Przeprowadzanie audytów przez zewnętrzne jednostki audytujące lub odpowiednie oprogramowanie. Audyty mogą dotyczyć takich elementów jak kod systemu, projekt architektury systemu, bezpieczeństwa, zgodności z normami. Rezultatem audytu może być miara spełnienia określonych warunków jakościowych lub zaklasyfikowania systemu do określonej kategorii.
- Wykonanie ankietyzacji wśród interesariuszy. Głównie dotyczy to osób stykających się bezpośrednio z systemem. Ankieta jest wypełniana przez jej uczestników w trakcie lub bezpośrednio po kontakcie z systemem. Ankiety dotyczą głównie elementów użyteczności systemu, takich jak satysfakcja użytkowników, zrozumienie działania systemu, wysiłek włożony w wykonanie działania lub nauczenie się funkcjonowania systemu.
- Przeprowadzenie sprawdzianów wśród użytkowników. Sprawdziany umożliwiają obserwację współdziałania użytkowników z systemem. Najczęściej wykonuje się je w postaci różnego rodzaju testów sprawności używania systemu
- Symulowanie zdarzeń. Tego typu procedury polegają na sztucznym wywoływaniu nieprawidłowych sytuacji dotyczących różnych aspektów systemu. Jedną z klas takich procedur jest tzw. wstrzykiwanie błędów do systemu. „Wstrzyknięcie” błędu w kodzie polega na dokonaniu modyfikacji kodu powodującej jego nieprawidłowe działanie.
Powyższe typy procedur pomiarowych stosujemy w odpowiedni sposób do różnych kas wymagań jakościowych przedstawionych w poprzedniej sekcji. Najbardziej chyba oczywistymi do zmierzania są wymagania odnoszące się do dynamiki systemu, czyli wymagania wydajności. Efektywność, będąca miarą związku miedzy zasobami (mocą obliczeniową) a wynikami szybkości działania osiąganymi przez program łatwo wyrazić liczbowo mierząc czas wykonania pewnych operacji, czas odpowiedzi przy założeniu pewnych sygnałów itd.
W przypadku wymagań użyteczności, najczęściej chcielibyśmy zmierzyć wysiłek jaki użytkownicy systemu wkładają w korzystanie z jego funkcjonalności. Użyteczność podlega najczęściej weryfikacji poprzez ocenę użytkowników systemu oraz ekspertów ergonomii systemów informatycznych. Możliwa procedura pomiarowa może wykorzystywać audyt przeprowadzany przez określoną jednostkę lub eksperta od „doświadczenia użytkownika” (ang. user experience, UX). W ramach takiego audytu mogą być badane na przykład następujące kryteria: zgodność ze standardami i regułami komunikacji człowiek-komputer, intuicyjność, spójność, elastyczność, wygoda, poprawność. Innym, często wykorzystywanym sposobem na mierzenie użyteczności systemu są ankiety. Przy pomocy ankiet możemy mierzyć wiele różnych parametrów, których źródłem są przede wszystkim użytkownicy systemu i ich opinie o systemie. Takimi parametrami mogą być: miara wysiłku użytkownika (ang. Customer Effort Score, CES), miara satysfakcji klienta (ang. Customer Satisfaction Score, CSAT), miara chęci promowania (ang. Net Promoter Score, NPS).
Można również mierzyć użyteczność sytemu poprzez przeprowadzenie sprawdzianów różnego rodzaju. Efektem sprawdzianów może być określenie następujących miar: współczynnik powodzenia wykonania zadań (ang. Task Success Rate), czas przeznaczony na wykonanie zadania (ang. Time spent on task), miara błędów użytkownika (ang. User Errors).
Zupełnie inne metryki niż użyteczność dotyczą wymagań bezpieczeństwa. Testowanie bezpieczeństwa systemów często dotyczy testów całych środowisk wykonawczych. Testy polegają na weryfikacji czy operacje dotyczące danych spełniają określone standardy i założenia, a także na badaniu ścieżek przepływu komunikacji aktorzy-system (pod kątem np. przekroczenia uprawnień). Przetwarzanie danych przez system należy ocenić ze względu na zachowanie ich integralności, poufność przesyłu i wymiany, poziomy dostępu, czy sposób monitorowania zmian. Częstym sposobem jest zatem przeprowadzenie audytów przez wyspecjalizowane organizacje (np. kontrolowana próba „włamania” do sytemu). Efektem takiego audytu jest często uzyskanie certyfikatu bezpieczeństwa określonego rodzaju.
Podobne podejście może dotyczyć weryfikacji spełnienia wymagań kompatybilności. Duże możliwości daje tutaj wirtualizacja systemów operacyjnych i sprzętu. Korzystając ze środowisk-emulatorów można zbadać działanie systemu w różnych konfiguracjach sprzętowych i programowych oraz na różnych platformach. Innym sposobem weryfikacji jest sprawdzenie zgodności systemu z odpowiednimi standardami wymiany danych poprzez interfejsy systemowe. Istnieją tutaj odpowiednie zasady uzyskiwania certyfikatów zgodności i przejście przed odpowiednią procedurę certyfikacyjną może być elementem metryki tego typu wymagań. Podobne procedury weryfikacji można zastosować dla wymagań przenośności.
Zupełnie inne podejście należy zastosować dla wymagań łatwości utrzymania. Zadaniem jest najczęściej oszacowanie kosztu (wysiłek, czas) różnych czynności związanych z utrzymaniem – poprawienia błędu, rozszerzenia o nową funkcję czy też bieżącej obsługi systemu. Estymację taką możemy oprzeć na analizie kosztów zmian w systemie oraz testowania tych zmian, dokonywanych jeszcze w trakcie projektu konstrukcji tego systemu. Inną metodą jest przeprowadzenie audytów architektury oraz kodu systemu. Audyty takie przeprowadzane są najczęściej przez doświadczonych deweloperów.
3.4. Ograniczenia techniczne i środowiskowe
Osobnym składnikiem piramidy wymagań są ograniczenia techniczne i środowiskowe. Często tego typu charakterystyki systemu są traktowane jak wymagania jakościowe, jednak są one zasadniczo od nich różne. Bardzo istotnym wyróżnikiem ograniczeń jest sposób ich weryfikacji. Nie mamy tutaj określonych procedur weryfikacyjnych, gdyż ograniczenia są narzuconymi cechami warsztatu deweloperskiego lub otoczenia systemu. Są to zatem niezmienniki, rządzące procesem wytwarzania danego systemu oprogramowania.
Ograniczenia techniczne dotyczą technologii, jakie zespół deweloperski musi zastosować podczas budowy systemu. Ograniczają one stopień swobody w wyborze architektury, sprzętu czy narzędzi programistycznych. Ograniczenie nie jest wymaganiem w pełni tego słowa znaczeniu, gdyż nie zaspokaja konkretnej potrzeby klienta z punktu widzenia jego działalności. W związku z tym, dla ograniczeń nie definiujemy metryk z oczekiwanymi wartościami oznaczającymi ich spełnienie.
Jak się wydaje, brakuje jednolitego standardu definiującego rodzaje ograniczeń technicznych. Mimo to spróbujemy podać najważniejsze grupy tego typu charakterystyk systemu.
- Ograniczenia dotyczące języków programowania. Ograniczenie togo typu dotyczy sytuacji, kiedy klient wyraźnie narzuca konkretny język lub języki, w których musi być napisany kod sytemu. Dotyczy to również konieczności zastosowania określonych szkieletów programistycznych (frameworków) opartych na określonych językach.
- Ograniczenia dotyczące środowiska deweloperskiego. Ograniczenie tego typu dotyczy sytuacji, kiedy klient narzuca określony zestaw narzędzi, które muszą być wykorzystywane podczas budowy systemu. Dotyczyć to może całego procesu wytwórczego oraz procesu zarządzania projektem.
- Ograniczenia dotyczące stosowanego sprzętu. Ograniczenie tego typu związane jest z koniecznością wykorzystania określonych istniejących zasobów sprzętowych. Może to dotyczyć różnych elementów sprzętowych, takich jak stacje robocze, serwery, sieci, urządzenia peryferyjne.
- Ograniczenia dotyczące stosowanych komponentów programowych. Ograniczenia tego typu dotyczy konieczności zastosowania określonych gotowych komponentów jako składowych systemu. Najczęstszą sytuacją jest zastosowanie konkretnego komponentu bazodanowego lub technologii bazodanowej. Inne sytuacje obejmują komponenty odpowiedzialne za komunikację w systemie.
Podobnie możemy określić najważniejsze rodzaje ograniczeń środowiskowych.
- Ograniczenia dotyczące parametrów fizycznych środowiska. Parametrami środowiska mogą być m.in. temperatura, wilgotność, przejrzystość powietrza.
- Ograniczenia dotyczące zachowań i możliwości użytkowników. Zakres takich ograniczeń jest dosyć szeroki i może dotyczyć ograniczeń fizycznych, którym podlegają użytkownicy systemu, ograniczeń możliwości wykorzystywanie określonych funkcji sytemu lub ograniczeń umiejętności.
- Ograniczenia dotyczące infrastruktury nieinformatycznej. Przeważnie tego typu ograniczenia dotyczą kwestii zasilania systemu w energię. Mogą też dotyczyć innych aspektów infrastruktury, takich jak rozmiary pomieszczeń, sposoby kontroli dostępu do pomieszczeń, sposoby ustawienia stanowisk roboczych.