Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | 4. Zastosowania narzędzi CASE |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | piątek, 3 lipca 2026, 10:48 |
Opis
Implementacja systemu informatycznego oznacza realizację przez programistów założeń projektowych zgodnych w wymaganiami zamawiającego. Celem implementacji jest zapisanie struktury i funkcjonalności systemu w wybranym języku (lub językach) programowania przy wykorzystaniu wybranego środowiska implementacyjnego. Tworzony kod powinien wypełniać ramy określone przez modele komponentów, dostarczając ich odpowiedniej funkcjonalności.
1. Podstawy implementacji oprogramowania
1.1 Kodowanie systemu na podstawie projektu
Implementacja systemu informatycznego oznacza realizację przez programistów założeń projektowych zgodnych w wymaganiami zamawiającego. Celem implementacji jest zapisanie struktury i funkcjonalności systemu w wybranym języku (lub językach) programowania przy wykorzystaniu wybranego środowiska implementacyjnego. Tworzony kod powinien wypełniać ramy określone przez modele komponentów, dostarczając ich odpowiedniej funkcjonalności.
Przeniesienie projektu systemu opisanego modelami projektowymi do kodu nazywane jest inżynierią w przód (ang. forward engineering). Najbardziej typowym zadaniem jest tutaj przekształcenie modelu klas zapisanego w języku UML w kod zapisany w wybranym języku programowania. W niektórych sytuacjach konieczna jest jednak decyzja projektanta lub programisty. Dotyczy to na przykład decyzji odnośnie rodzaju struktur danych stosowanych do przechowania referencji. Inżynierię w przód omówimy na przykładzie modelu pokazanego na rysunku 1.1. Widzimy tu fragment modelu klas stanowiącego projekt realizacji jednego z interfejsów komponentu warstwy logiki dziedzinowej.

Rysunek 1.1: Przykładowy projekt struktury komponentu
Po zastosowaniu odpowiednich reguł translacji, otrzymamy kod pokazany poniżej. Kod został wygenerowany automatycznie w narzędziu CASE i jest zapisany w języku C#. Dla zwięzłości, pominięto kod dwóch operacji klasy „MZamowienia”.
///////////////////////////////////////////////////////////
// Implementation of the Interface IZamowienia
///////////////////////////////////////////////////////////
public interface IZamowienia {
XListaZamowien PobierzListeZamowien(XFiltrZamowien filtr);
XListaZamowien PobierzPelnaListeZamowien();
short DodajZamowienie(XZamowienie zam);
}//end IZamowienia
///////////////////////////////////////////////////////////
// Implementation of the Class MZamowienia
///////////////////////////////////////////////////////////
public class MZamowienia : IZamowienia {
private List<MZamowienie> zam;
private MZamowieniaDao dao;
public MZamowienia(){
}
public XListaZamowien PobierzListeZamowien(XFiltrZamowien filtr){
return null; }
public XListaZamowien PobierzPelnaListeZamowien(){
return null; }
// (...) pozostałe metody pominięte
}//end MZamowienia
///////////////////////////////////////////////////////////
// Implementation of the Class MZamowienie
///////////////////////////////////////////////////////////
public class MZamowienie : MDokument {
public MZamowienie(){
}
public short SprawdzPoprawnosc(){
return 0; }
}//end MZamowienie
Inżynieria w przód dotyczy najczęściej modeli statycznych języka UML. Oznacza to, że kod wygenerowanych metod jest pusty – zawiera jedynie standardowe instrukcje powrotu („return”). Jest to oczywiste, gdyż źródłowy model klas nie zawiera informacji, które pozwoliłyby taki kod wygenerować. Dynamika działania kodu (treść metod) jest opisywana innymi modelami. Informacje zawarte w modelach dynamiki programista może wykorzystać do napisania istotnych części kodu metod. Przykładem jest model sekwencji. Na rysunku 1.2 widzimy diagram zawierający kilka podstawowych konstrukcji tego modelu.

Rysunek 1.2: Przykładowy projekt działania operacji interfejsu
Na podstawie tego diagramu, programista może stworzyć kod metody „SprawdzWszystkieZamowienia” w klasie „MZamowienia”, który został pokazany poniżej.
public short SprawdzWszystkieZamowienia(DateTime data)
{
short
wynik
= 0;
lista = dao.Pobierz(wszystkie);
Przepisz(lista, zam);
if (null != lista)
{
foreach
(MZamowienie zamowienie in zam)
{
wynik = zamowienie.SprawdzPoprawnosc();
}
}
return
wynik;
}
Dobrą praktyką implementacji jest utrzymywanie jej zgodności z modelami projektowymi. W ten sposób, programiści mają stale aktualną „mapę kodu”, co zwiększa efektywność pracy programistów. Często jednak programiści wprowadzają zmiany projektowe bezpośrednio w kodzie. Aby zachować zgodność, można zastosować tzw. inżynierię odwrotną (ang. reverse engineering). Polega ona na odtworzeniu modelu (najczęściej – modelu klas) na podstawie kodu. Oczywiście, mechanizmy inżynierii odwrotnej, podobnie jak inżynierii w przód, są wbudowane w odpowiednie narzędzia CASE i są wykonywane automatycznie. Warto również zauważyć, że wykorzystanie inżynierii odwrotnej jest jeszcze szersze. Dzięki niej możemy stworzyć „wizualną mapę” dla kodu, który nie posiada dokumentacji w postaci modelu klas.
1.2. Dobre praktyki w zakresie kodowania
Kod, tak jak inne produktu procesu wytwarzania oprogramowania, jest najczęściej tworzony w zespołach. Jest on zatem czytany przez osoby o różnych kwalifikacjach, doświadczeniu i nawykach. Dobre praktyki programowania zostały wypracowane w wyniku doświadczenia wielu lat pracy różnych zespołów programistów. Praktyki te w obiektywny sposób opisują pewne pożądane cechy kodu – niezależnie od języka programowania, rozwiązań technicznych, charakteru organizacji informatycznej czy dziedziny projektu, w obrębie którego kod powstawał.
Podstawową przesłanką, którą każdy programista („koder”) powinien uwzględniać podczas pracy z kodem jest fakt, że nie pisze on kodu dla siebie. Troska kodera o przyszłego czytelnika objawia się w szeroko rozumianej łatwości przyswajania znaczenia kodu. Niestety, wielu programistów tworzy kod nadmiernie skomplikowany, stosując różnego rodzaju „sztuczki programistyczne”, które bardzo utrudniają współpracę w zespole. Co więcej, często takie „sztuczki” obracają się przeciwko ich autorom, którzy po kilku miesiącach wracają do swojego kodu i mają problem z jego zrozumieniem.
Dobre praktyki kodowania można podzielić na praktyki redaktorskie, merytoryczne oraz związane z nawykami codziennej pracy. Praktyki redaktorskie dotyczą pracy z kodem traktowanych jako tekst. Obejmują one kwestie dotyczące formatowania tekstu, jego komentowania oraz konwencji nazewniczych.
· Formatowanie tekstu. Kod powinien zawierać wcięcia i odstępy organizujące go w logiczne bloki. Linie nie powinny być zbyt długie, aby można je było łatwo objąć wzrokiem.
· Komentowanie kodu. Komentowanie jest ważne, gdyż często kod nie jest wystarczająco przejrzysty. Może na przykład zawierać pozornie niejednoznaczne odwołania, czy też mieć nieewidentne motywacje.
· Konwencje nazewnicze. Konwencje mają na celu ujednolicenie nazw stosowanych w kodzie, przy zachowaniu ich czytelności i podkreśleniu roli nazw nawet dla najmniej istotnych elementów .
Praktyki merytoryczne dotyczące pisania kodu w dosyć dużym stopniu pokrywają się z dobrymi praktykami w zakresie projektowania. Praktyki merytoryczne obejmują zasady strukturalizacji kodu, definiowania zmiennych i stałych, zasad przetwarzania danych oraz testowalności.
- Projektowanie podczas kodowania. Projekt oddawany w ręce programistów nie jest „martwy”. Pamiętajmy, że wprowadzając zmiany w kodzie, powinniśmy jednocześnie nanosić je w modelu projektowym, stosując zasady inżynierii odwrotnej.
- Zapewnienie parametryzowalności kodu. Wszystkie używane w kodzie stałe (napisy, liczby, symbole itp.) powinny być definiowane poza kodem, który się do nich odwołuje.
- Unikanie stosowania „magicznych wartości” (ang. magic numbers). Zagadnienie to związane jest z omówioną wyżej parametryzowalnością kodu. Należy unikać formuł przekazywanych bezpośrednio w postaci liczb, a nie określonych symbolicznie.
- Posługiwanie się wzorcami projektowymi. Programista, podobnie do projektanta, często ma możliwość zastosowania ogólnie przyjętych i sprawdzonych rozwiązań.
- Uwzględnianie kodu dla testów. Dzięki temu, poważne błędy mogą być wykryte na tyle wcześnie, aby móc uniknąć pracochłonnego ich poszukiwania oraz znacznej przebudowy kodu.
- Przestrzeganie walidacji parametrów wejściowych. Tworzony kod powinien „pilnować” kontraktów określonych dla implementowanych przez siebie modułów.
- Przestrzeganie zasad obsługi raportowania wykonania kodu (logowania). Należy zdefiniować politykę reakcji na błędy, unikać niepotrzebnego filtrowania wyjątków, a z drugiej strony – zasypywania nimi klas wywołujących.
- Dbałość o dane. Oprogramowanie często przetwarza dane istniejące od wielu lat. Kod powinien zatem szanować takie „odziedziczone” dane (ang. legacy data). W szczególności, zbiory danych (np. bazy danych) nie powinny być „zaśmiecane” danymi specyficznymi dla konkretnego systemu.
- Dbałość o wykorzystanie zasobów maszyn. Należy pamiętać, że kod będzie pracował w określonym środowisku wykonawczym o ograniczonych zasobach (pamięci, procesory, sieci).
- Branie pod uwagę przenośności. Należy pamiętać, że kod może być uruchamiany na różnych architekturach sprzętowych, pod kontrolą różnych (wersji) systemów operacyjnych itd.
- Branie pod uwagę skalowalności. Skalowalność oznacza możliwość reakcji kodu na różne poziomy obciążenia obliczeniami. Kod, który wymaga skalowalności powinien być pisany z myślą, że może on być on wywoływany wielokrotnie w krótkich odstępach czasu.
- Przestrzeganie zasad paradygmatu obiektowego. Częstym błędem jest pisanie kodu klas w stylu wywodzącym się z języków proceduralnych.
Trzecią grupą dobrych praktyk są praktyki związane z pewnymi nawykami w pracy z kodem. Dotyczą one przede wszystkim pracy zespołowej i przestrzegania zasad wersjonowania kodu.
- Zapewnienie „czystości” własnego kodu. Bardzo istotne jest, aby kod podlegający kontroli wersji był „czysty”, czyli pozbawiony błędów kompilacji, ostrzeżeń oraz innych wad utrudniających (lub wręcz uniemożliwiających) innym pracę i testowanie.
- Praca na aktualnym kodzie. Przed rozpoczęciem pracy z nowym fragmentem kodu powinniśmy się upewnić, że jest on aktualny.
1.3. Zarządzanie wersjami
Zarządzanie wersjami (ang. version control) oznacza zapisywanie kolejnych zmian w pliku lub zestawie plików. Każda zapisana zmiana tworzy wersję, do której można wrócić w dowolnym momencie. Zarządzanie zmianami w projektach konstrukcji oprogramowania najczęściej dotyczy plików z kodem źródłowym. Do zarządzania wersjami stosujemy specjalne narzędzia, które nazywamy systemami zarządzania wersjami (ang. Version Control System).
Istnieją dwa główne modele zarządzania wersjami: scentralizowane (klient-serwer) oraz rozproszone. Model scentralizowany polega na ustanowieniu centralnego serwera, na którym przechowywane są wszystkie wersjonowane pliki i dokonywane są wszystkie zapisy zmian w tych plikach. Współcześnie dużą popularność zyskał model zdecentralizowany. W tym systemie nadal mamy serwer, który umożliwia przechowywanie oraz wersjonowanie plików. Różnica polega na tym, że maszyny klienckie posiadają możliwość lokalnego wersjonowania plików i przechowują lokalnie kopie całej historii wersji. W ten sposób, każda maszyna lokalna ma możliwość odtworzenia całego zestawu wersjonowanych plików, nawet w razie awarii serwera. Najpopularniejszym obecnie systemem realizującym model zdecentralizowany jest system Git.
Istnieją dwie podstawowe strategie zarządzania równoległymi zmianami w plikach. Pierwsza polega na tworzeniu blokad (ang. lock), a druga na wykonywaniu scaleń (ang. merge). Pierwsza strategia zakłada możliwość zablokowania przez użytkownika wersjonowanego zasobu, by uniemożliwić innym zapis (stworzenie nowej wersji). Jednocześnie, odczyt jest cały czas dopuszczalny. Strategia polegająca na scaleniach zakłada, że istnieje mechanizm tworzenia spójnego i użytecznego pliku w oparciu o dwie różne jego wersje. Mechanizm scalania ilustruje rysunek 1.3. Przedstawia on sytuację, gdy osoby X i Y pracują jednocześnie na tej samej wersji pliku. Osoba X zapisuje swoje zmiany jako pierwsza. Następnie, zapisać zmiany próbuje osoba Y. Otrzymuje ona wtedy informację o nieaktualności swojego pliku. System sprawdza różnice i umożliwia scalenie zmian i zapis w postaci kolejnej wersji.

Rysunek 1.3: Scalanie zmian w systemie kontroli wersji
Od strony technicznej każda kolejna rewizja przechowywana jest najczęściej jako tzw. delta (zmiana) w stosunku do rewizji ją poprzedzającej.
Praca nad kolejnymi wersjami zasobu (pliku lub zestawu plików) nie musi być liniowa. Różne osoby mogą tworzyć różne warianty składające się z wielu wersji. Takie warianty nazywamy gałęziami (ang. branch). Gałęzie mogą być rozwijane całkowicie niezależnie, jednak w pewnym momencie powinny być ze sobą synchronizowane. Podstawą synchronizacji jest gałąź główna, zwana pniem (ang. trunk). Jeśli twórca uzna, że jego wariant (gałąź) jest już stabilna, może ją scalić z pniem. Rysunek 11.4 ilustruje tworzenie kilku gałęzi na bazie gałęzi głównej, czyli pnia.

Rysunek 11.4: Schemat wersjonowania dla zasobu o dwóch gałęziach

Rysunek 11.5: Znaczniki dla plików w systemie kontroli wersji
Podczas pracy w systemie zarządzania wersjami możemy wykonywać różne operacje umożliwiające równoległą pracę nad różnymi plikami. Pierwszą czynnością jest dokonanie operacji check-out, czyli stworzenie lokalnej kopii roboczej, zawierającej aktualną wersję zasobów, nad którymi będziemy pracować. Po dokonaniu zmian, wykonujemy operację check-out. W wyniku tej operacji tworzona jest kolejna wersja w aktualnej gałęzi. Ważne jest, aby przez utworzeniem nowej gałęzi dokonać aktualizacji (ang. update), czyli pobrać aktualną wersję zasobów z gałęzi głównej. Synchronizacja gałęzi z pniem odbywa się w wyniku operacji scalania (ang. merge). Istotnym elementem tej operacji jest pokazanie przez system różnicy między wersjami oraz pomoc w wybraniu zmian, które zostaną włączone do pnia.
2. Podstawy testowania
2.1. Rola testowania w inżynierii oprogramowania
Testowanie oprogramowania jest dyscypliną inżynierii oprogramowania zajmującą się określaniem metod oraz przeprowadzaniem badania poprawności działania oprogramowania. Na przestrzeni lat rozwinięto wiele metod, które pozwalają zespołom testującym nadążyć za coraz szybciej powstającymi programami, a także opanować coraz bardziej złożone interakcje między systemami informatycznymi.
Podczas powstawania systemu informatycznego konieczne jest stwierdzenie, czy jego działanie nie wykazuje odstępstw od pewnych narzuconych warunków. Warunki te powstają poprzez analizę potrzeb klienta oraz określenie możliwości zespołu tworzącego program. Odstępstwa od tak ustalonej specyfikacji nazywa się błędami oprogramowania i obejmują one takie sytuacje jak:
- oprogramowanie nie wykonuje czegoś, co powinno wykonywać,
- oprogramowanie robi coś, czego nie powinno robić,
- oprogramowanie nie wypełnia warunków dotyczących cech pozafunkcjonalnych,
- oprogramowanie zachowuje się w sposób nie przewidziany specyfikacją.
Istotną część błędów stanowią tzw. pluskwy (ang. bug) – są to usterki umiejscowione w kodzie programu i wynikające ze zmęczenia, przeoczeń bądź nieuwagi programistów. Celem procesu testowania oprogramowania jest możliwie wczesne znajdowanie nieprawidłowości działania aplikacji, a także odpowiednie opisywanie ich w celu ułatwienia programistom dokonania poprawek. W procesie testowania tworzy się dane testowe wykorzystywane podczas badania reakcji systemu na sygnały wejściowe. Zbiór danych testowych powinien być odpowiednio duży oraz zróżnicowany.
Nie istnieje jednoznaczna miara, pozwalająca ocenić skuteczność przyjętych strategii testowania. Jednym z podejść do problemu weryfikacji procesu testowania jest badanie pokrycia testami zbioru przetwarzanych przez system danych oraz kodu wykonywanego podczas uruchamiania testów. Miara pokrycia kodu i danych pozwala ocenić, które fragmenty kodu (linie, instrukcje) zostały „zbadane” oraz jaki zakres danych został wykorzystany przy weryfikacji systemu.
Inną miarą jest szacunkowe określenie liczby błędów w systemie i liczby błędów wykrytych. Można w tym celu stosować metodę posiewową. Technika ta polega na tym, że do kodu programu wprowadza się celowo pewną liczbę sztucznie wytworzonych błędów. Błędy te powinny być podobne do tych prawdziwych, gdyż w przeciwnym razie miara będzie mało dokładna. Następnie zespół testujący, nieświadomy umieszczonych błędów, jest oceniany poprzez odpowiednie oszacowania bazujące na liczbie wykrytych przez niego usterek.
Jeżeli:
B – liczba wykrytych błędów
b – liczba posianych błędów, które zostały wykryte
P – liczba posianych błędów
to szacunkowa liczba błędów przed wykonaniem testów wynosi
![]()
a szacunkowa liczba błędów pozostałych po wykonaniu testów wynosi
![]()
2.2. Podstawowe metody testowania
Popularne obecnie techniki testowania można podzielić na metody nieinwazyjne (metody czarnej skrzynki), metody związane z analizą powstającego kodu (metoda szklanej skrzynki) oraz metody analizy specyfikacji (testy statyczne).
Najczęściej używanymi metodami testowania są metody kierujące się zasadą testów czarnej skrzynki (ang. black box testing). Polegają one na sprawdzaniu działania programu (ogólnie: systemu informatycznego), bazującym całkowicie na monitorowaniu danych wejściowych i wynikowych oraz porównywaniu ich z oczekiwaniami (założeniami). Podczas takich testów nie wnika się w strukturę kodu programu, co oznacza również działanie nieinwazyjne (np. nie dokonuje się zmian kodu w celu wykonania testów). Testowanie tego typu obejmuje szereg różnych rodzajów testów związanych z funkcjonalnością oprogramowania. Jest to zatem metoda testowania dynamicznego.
By przeprowadzić udany test metodą czarnej skrzynki można wykorzystać pewne techniki weryfikacji oprogramowania bazujące na zasadach nieingerencji i nieznajomości kod programu. Należą do nich metody:
- tworzenia klas równoważności,
- warunków granicznych,
- zmian stanów,
- niedoświadczonego użytkownika.
Stosowanie metody klas równoważności wynika z podstawowej potrzeby prześledzenia wszystkich możliwych stanów w systemach komputerowych. W dowolnym, nawet najprostszym procesie informatycznym, liczba możliwych stanów, danych wejściowych, konfiguracji sprzętu, zachowań użytkownika jest ogromna, a z punktu widzenia ograniczonego czasem i funduszami zespołu programistycznego – wręcz nieskończona. Z drugiej strony, podczas badania jakości oprogramowania niezbędne jest przetestowanie jak najszerszego spektrum możliwych sytuacji, z jakimi będzie miał do czynienia sprawdzany program. Rozwiązaniem powyższego konfliktu jest metoda klas równoważności, która pomaga w wyborze odpowiednich zadań testowych, ograniczając liczbę takich zadań, nie zmniejszając jednocześnie skuteczności testów.
Klasą równoważności nazywa się zbiór zadań testowych, które testują to samo lub ujawniają te same błędy. Głównym zagadnieniem podczas testowania metodą klas równoważności jest identyfikacja klas równoważności, czyli taki podział zagadnień testowych, który powala uzyskać odpowiednie pokrycie testowanego oprogramowania i jednocześnie daje zastosować się w praktyce. Identyfikację klas równoważności można przeprowadzać ze względu na podobne dane wejściowe, podobne stany programu, podobne dane oczekiwane, podobne zachowania użytkownika itp.
Podczas podziału na klasy równoważności często ujawnia się problem warunków granicznych, zasadzający się na dylemacie jednoznacznego zaliczenia danego zadania testowego do jednej z kilku grup, które „zbiegają się” lub „stykają” w danym punkcie. Wtedy metoda klas równoważności zaczyna uzupełniać się z metodą warunków granicznych.
Testowanie warunków granicznych można również nazwać „praktycznym zastosowaniem klas równoważności dla testowania danych”. Ideą tej metody jest określenie przedziałów, jakie mogą przyjmować dane wejściowe oraz sprawdzenie zachowania się programu dla danych z okolicy granic tych przedziałów.
Przeciwwagą dla metod czarnej skrzynki są metody „szklanej (białej) skrzynki” (ang. glass-, white-box testing). Wykorzystują one wiedzę o kodzie programu w celu podniesienia skuteczności testów. Testy bazujące na wglądzie w strukturę programu polegają przede wszystkim na badaniu kodu. Testerzy zadają odpowiednie dane wejściowe, aby zbadać różne ścieżki działania kodu i określić przewidywane wyniki na wyjściu. Tego typu badania mogą być wspomagane poprzez formalne i nieformalne przeglądy kodu oraz poprzez analizę raportów narzędzi – analizatorów kodu.
W testach białej skrzynki wykorzystywane jest kilka technik, zapewniających badanie różnych aspektów działania kodu. Technika pokrycia instrukcji polega na przejściu podczas testów przez wszystkie instrukcje testowanego fragmentu kodu przynajmniej raz. Podobną techniką jest technika pokrycia gałęzi. Polega ona przejściu podczas testów chociaż raz wszystkimi możliwymi gałęziami wychodzącymi z punktów decyzyjnych (np. instrukcji warunkowych).
Kolejną techniką testów białej skrzynki jest technika pokrycia warunków. Polega ona na sprawdzeniu działania kodu dla różnych kombinacji warunków w instrukcjach warunkowych. Bardzo ogólną techniką testowania metodą białej skrzynki jest technika ścieżek bazowych. W ramach tej techniki należy określić tzw. złożoność cykliczną (cyklomatyczną) testowanego fragmentu kodu (procedury). Złożoność tą określamy na podstawie grafu przepływu sterowania. W grafie takim węzły odpowiadają instrukcjom, a krawędzie określają kolejność wykonywania tych instrukcji (łącznie z określeniem alternatywnych przebiegów). Złożoność cykliczną liczymy na podstawie liczby węzłów decyzyjnych, węzłów złączenia oraz regionów (obszarów zamkniętych krawędziami łączącymi węzły). Złożoność cykliczna determinuje liczbę niezależnych ścieżek wykonania kodu. Na tej podstawie możemy określić liczbę testów niezbędnych do pokrycia wszystkich instrukcji w danym fragmencie kodu.
2.3. Poziomy testowania
Najbardziej szczegółowym rodzajem testów są testy jednostkowe. Dotyczą one kodu systemu i są tworzone bezpośrednio przez programistów go piszących. Rolą testów jednostkowych jest sprawdzenie działania elementarnych składników kodu, np. klas oraz ich metod. Sprawdzana jest logika działania procedury lub funkcji poprzez zadanie danych wejściowych (parametrów) i sprawdzenie, czy dane wyjściowe (wyniki) są zgodne z oczekiwaniami. Dobrze przygotowane testy jednostkowe pozwalają również na przeprowadzanie testów regresyjnych. Są to testy powtarzane w identyczny sposób w kolejnych iteracjach projektu, mające na celu sprawdzenie, czy wprowadzone w kodzie zmiany (np. optymalizacja, refaktoryzacja) nie spowodowały powstania nowych błędów.
Testy jednostkowe dążą do sprawdzania działania rozpatrywanych elementów niezależnie od innych z nimi powiązanymi. Jeśli dany element wymaga do działania innych elementów, stosuje się tzw. zaślepki, które imitują działanie tych elementów. Do tworzenia zaślepek na potrzeby testów jednostkowych również istnieje wiele dedykowanych bibliotek, które ułatwiają ten proces.
Testy kodu w których zaczynamy testować większą liczbę współpracujących ze sobą elementów naraz (np. cały komponent) możemy nazwać testami modułowymi, które stanowią wyższy poziom testów jednostkowych. Wykonywane są one również przez programistów, najczęściej z wykorzystaniem tych samych narzędzi. Rozpoczynają jednak już one kolejną kategorię testów, nazywanych testami integracyjnymi, których rolą jest sprawdzanie poprawnej współpracy wielu różnych elementów. W skład tej kategorii wchodzą również testy współdziałania i testy systemowe. Pierwsze z nich sprawdzają współdziałanie par współpracujących ze sobą elementów. Nacisk kładziony jest na sprawdzenie poprawności komunikacji poprzez wcześniej ustalone interfejsy. Drugie skupiają się na testowaniu poprawnej współpracy wszystkich elementów systemu koniecznych do dostarczenia poszczególnych funkcjonalności.
Ostatni rodzaj testów stanowią testy akceptacyjne, które mają dowieść zgodności systemu z wymaganiami, co pozwoli na jego ostateczny odbiór przez klienta. Typowo dokonywane są one w oparciu o scenariusze przypadków użycia uzupełnione o odpowiednie dane testowe. W testach akceptacyjnych biorą często udział przedstawiciele klienta lub przyszli użytkownicy systemu.
3. Narzędzia i metody automatyzacji inżynierii oprogramowania
W celu usprawnienia pracy zespołów konstruujących systemy oprogramowania powstały różnego rodzaju narzędzia, które nazywamy narzędziami komputerowego wsparcia inżynierii oprogramowania CASE (ang. Computer Aided Software Engineering). Narzędzia te pozwalają usprawnić czynności związane z wieloma aspektami rozwoju produktów systemowych: od zarządzania projektami informatycznymi, przez integrację powstających modułów i zarządzanie zmianami, po wsparcie dla modelowania systemów na różnych poziomach i ułatwianie implementacji.
3.1. Narzędzia automatyzacji analizy i projektowania oprogramowania
Narzędzia wspierające modelowanie obiektowe spełniają bardzo istotną rolę w „warsztacie” twórców oprogramowania. Modelowanie oprogramowania dotyczy praktycznie wszystkich faz rozwoju produktów software’owych. Podstawową funkcjonalnością typowego narzędzia służącego do modelowania obiektowego jest wsparcie dla rysowania diagramów w wybranej notacji, szczególnie – języka UML, ale często również innych, takich jak BPMN czy ERD. Podstawowe wsparcie narzędzia polega na udostępnieniu użytkownikowi możliwości łatwego tworzenia diagramów, modyfikacji elementów diagramów oraz ich przeglądania.
Zaletą narzędzi do modelowania oprogramowania jest to, że „pilnują” poprawności notacji nie pozwalając użytkownikowi na umieszczenie na diagramie danego typu, niewłaściwych elementów czy na nieprawidłowe zapisanie konstrukcji języka. Istotną funkcją narzędzia modelowania jest także umożliwienie zarządzania modelami: odpowiedniego porządkowania ich struktury (np. w formie pakietów), a także wygodnego przechodzenia między poziomami abstrakcji i śledzenia zależności między fragmentami systemów opisanych na różnych poziomach szczegółowości. Cecha ta jest niezmiernie istotna, ponieważ systemy reprezentowane są przez modele na wielu poziomach abstrakcji: poczynając od wymagań, a kończąc na „mapach kodu”, czyli modelach projektowych.
Istotnym elementem funkcjonalności narzędzi modelowania jest inżynieria kodu. Korzystając z funkcji z nią związanych można generować szkielet kodu odzwierciedlający wiedzę zawartą w modelu („inżynieria w przód”), tworzyć modele w celu zrozumienia istniejącego kodu („inżynieria odwrotna”), a także wspierać proces ciągłej synchronizacji kodu z modelem. Ważnym zagadnieniem związanym z tworzeniem modeli jest udostępnianie efektów pracy pozostałym osobom uczestniczącym w projekcie w dogodnej dla nich formie. Większość narzędzi pozwala na generację dokumentacji modeli.
Modelowanie w języku UML dotyczy przede wszystkim logiki systemu i jego kodu. Równie istotnym aspektem jest modelowanie oraz implementacja i utrzymywanie baz danych. Do tego celu służą narzędzia do zarządzania bazami danych. Samo modelowanie struktury bazy danych odbywać się może w sposób podobny do modelowania obiektowego – przy wykorzystaniu notacji ERD lub UML. Narzędzia CASE dedykowane bazom danych dostarczają wielu funkcji ułatwiających budowę systemów bazodanowych. Narzędzia takie pozwalają na wygodne tworzenie kopii zapasowych, importowanie lub eksportowanie danych, kreację raportów dotyczących danych i ich schematów, ustalanie opcji wydajności, a także tzw. „strojenie” (ang. tunning), czyli optymalizację wydajności bazy danych. Niektóre posiadają także funkcje podobne do tych dostarczanych przez narzędzia typu IDE (patrz niżej). Umożliwiają np. uruchamianie poleceń administracyjnych albo związanych z danymi czy odpluskwianie (ang. debugging) przetwarzanych przez silnik bazy skryptów. Często dostępne w tego typu narzędziach są opcje analizy danych pozwalające na wizualne tworzenie zapytań (odpowiadających zapytaniom w języku SQL).
Często używaną grupą narzędzi są narzędzia do modelowania interfejsu użytkownika. Narzędzia takie pozwalają na tworzenie szkiców interfejsu użytkownika, nazywanych interfejsami szkieletowymi (ang. wireframe). W podstawowej swej funkcjonalności zastępują one kartkę papieru i ołówek – pozwalają przede wszystkim na zobrazowanie rozmieszczenia elementów interfejsu użytkownika. Interfejs szkieletowy nie oddaje ostatecznego wyglądu produktu, lecz jedynie odzwierciedla jego kontury. Główną zaletą takiego podejścia do modelowania interfejsu użytkownika jest możliwość koncentracji na meritum, czyli właściwej treści prezentowanej użytkownikom. Pozwala to zidentyfikować ograniczenia struktury interfejsu użytkownika i odpowiednio rozplanować wyświetlanie różnych typów informacji.
Na dalszych etapach modelowania interfejsu użytkownika możemy użyć narzędzia do tworzenia makiet (ang. mockup). Narzędzia takie mogą być zintegrowane z narzędziami do tworzenia interfejsów szkieletowych. Wystarczy wtedy po prostu przełączyć tryb modelowania. Od rzeczywistego interfejsu użytkownika makieta różni się tym, że jest statyczna – nie posiada funkcjonalności, a wyświetlane elementy są tylko przykładowe. Niektóre narzędzia do makietowania pozwalają na symulację nawigacji między poszczególnymi ekranami.
3.2. Narzędzia wsparcia implementacji i testowania oprogramowania
Klasą narzędzi CASE używaną w praktycznie wszystkich projektach są narzędzia wspierające tworzenie kodu. Podstawowym zadaniem takich narzędzi jest zwiększenie produktywności przez zintegrowanie wszystkich funkcjonalności używanych w typowym cyklu życia kodu w jedną spójną całość. Narzędzia takie nazywamy zintegrowanymi środowiskami programistycznymi (ang. IDE – Integrated Development Environment).
Podstawowym elementem IDE jest edytor kodu. Współczesne edytory tego typu posiadają wiele funkcji pomagających w pisaniu kodu poprawnego składniowo. Typowo pozwalają one kolorować kod (rozróżniać różne elementy składni kolorami), dokonywać automatycznego formatowania (np. wcinanie tekstu), wykonywać autouzupełnianie (np. podpowiadanie nazw zmiennych) oraz oferują inne podobne funkcje edytorskie. Część środowisk zintegrowanych pozwala traktować kod nie tylko jako tekst, ale pewną strukturę. Wiele spośród IDE posiada opcję wstawiania często wykorzystywanych fragmentów programów (ang. snippets), które można parametryzować. Takie fragmenty zawierają konstrukcje programistyczne, takie jak pętle, polecenia sterujące czy konstrukcje językowe odpowiedzialne za obsługę wyjątków. Do kategorii automatycznego przetwarzania struktury kodu należą też opcje refektoryzacji kodu (ang. code refactoring), pozwalające na zmianę jego organizacji w celu poprawy czytelności i łatwiejszej późniejszej pielęgnacji. Dotyczy to takich operacji jak przemianowanie klas (odniesienia do refaktoryzowanej klasy są automatycznie zmieniane w całym zawierającym je kodzie), czy też aktualizacja struktury pakietów lub hierarchii klas. Inną użyteczną operacją dostępną w popularnych IDE jest generowanie szkieletów kodu np. dla klas implementujących określone interfejsy.
Prawdziwa siła wsparcia, jakie IDE udzielają programiście leży jednak w tym, w jaki sposób łączą się one z narzędziami zewnętrznymi. Ścisła integracja z kompilatorami pozwala na natychmiastowe wskazywanie błędów w kodzie, a często nawet automatyczne ich poprawianie. Popularne narzędzia do modelowania (omówione w poprzedniej sekcji) umożliwiają współpracę z IDE, czy to przez udostępnienie funkcjonalności związanych z modelowaniem w samych IDE, czy przez możliwość edycji kodu modelowanych elementów w środowisku modelowania. Inną, standardową już dzisiaj funkcjonalnością, jest wygodna współpraca z różnymi repozytoriami kodu i systemami wersjonowania. Środowiska programistyczne ułatwiają także tworzenie środowisk testowych przez automatyczną generację szkieletu skryptów weryfikujących aplikację oraz możliwość analizy i kontroli uruchomienia już zaimplementowanych testów.
Ważnym narzędziem w obrębie IDE jest tzw. odpluskwiacz (ang. debugger) pozwalający na analizę programów podczas ich wykonywania. Uruchomiony w ramach odpluskwiacza proces może być zatrzymywany w czasie wykonywania wybranych przez programistę instrukcji czy też wykonywany krokowo. Debugger pozwala na obejrzenie stanu pamięci przypisanej do tworzonego programu. Sam proces odpluskwiania pozwala na rozwiązanie problemów, których przezwyciężenie tradycyjnymi metodami (np. poprzez analizę kodu) jest bardzo pracochłonne.
Praca z kodem skutkuje powstaniem odpowiednim modułów wykonywalnych, które wspólnie tworzą gotowy system. Istotnym problemem, szczególnie w większych projektach konstrukcji oprogramowania jest integracja, czyli procesu kombinacji systemu ze stale aktualizowanych modułów. Aby wyeliminować problemy z integracją lokalną wprowadzono zcentralizowane systemy ciągłej integracji (ang. continuous integration). Są one najczęściej ściśle powiązane z systemami ciągłego wdrażania (ang. constant deployment). Centrum takich systemów są odpowiednie narzędzia, które potrafią automatycznie – na bazie przygotowanych wcześniej modułów - stworzyć działające wersje rozwijanego produktu. Takie działające wersje (wydania) systemu mogą być następnie w sposób automatyczny zainstalowane (wdrożone) w środowisku wykonawczym (testowym lub produkcyjnym). Przed instalacją przeprowadzane są – również automatycznie – zestawy testów mających na celu sprawdzenie, czy system działa prawidłowo.
Warto zauważyć, że proces ciągłej integracji i wdrażania powinien być realizowany z poziomu środowisk IDE. Oznacza to konieczność integracji IDE ze środowiskiem wykonawczym (np. serwery aplikacyjne), na jakim uruchamiany jest tworzony produkt. Współpraca IDE z docelowymi bądź testowymi środowiskami uruchomieniowymi polega na wsparciu dla łatwej kontroli serwera aplikacji z poziomu narzędzi programistycznych.
Jedną z podstawowych funkcjonalności narzędzi wspierających testowanie jest możliwość testowania interfejsu użytkownika (ang. UI testing). Tego typu testowanie pozwala na zbadanie reakcji interfejsu użytkownika, poprawności jego struktury (zachowanie pozycji elementów na ekranie), a także przejść między stanami aplikacji (np. kolejność pokazywanych ekranów). Podstawą jest tutaj zapisywanie (nagrywanie) typowych przebiegów interakcji użytkowników z badanym systemem. Proces rejestracji dialogu użytkownik-aplikacja polega na zapisie decyzji użytkownika (naciśniętych przez niego przycisków, wybranych opcji menu, wprowadzonych danych itd.). Taki zapis (akcje użytkownika oraz ich parametry) może być później modyfikowany.
Bardzo popularną grupą narzędzi wspomagających testowanie są narzędzia dla testów jednostkowych. Pozwalają one na generację szkieletów testów, kontrolowane uruchamianie skryptów testowych, analizę wyników działania oraz raportowanie. Testy jednostkowe uruchamiane poprzez odpowiednie oprogramowanie pracują w odpowiednio spreparowanym środowisku. Możliwe jest np. określanie danych testowych oddzielnie dla każdego uruchomienia, a także reprezentowane innych modułów przy pomocy zaślepek. Uruchomienie testów jest kontrolowane – kroki przypadków testowych mogą być realizowane w określonej kolejności. Wyniki testów jednostkowych pozwalają na stwierdzenie, który z warunków zapisanych w testach nie został spełniony oraz jaki był rezultat takiego sztucznie wytworzonego błędu. Dla przeprowadzonego zestawu testów narzędzia generują raporty zawierające statystykę znalezionych błędów, ich rodzaj, zakres kodu jaki został objęty testami itd. Narzędzia wspierające testy jednostkowe łatwo integrują się z popularnymi zintegrowanymi środowiskami programistycznymi (IDE).
O ile powyżej opisane narzędzia działają na zasadzie testów metodą „czarnej skrzynki”, to istnieje także wsparcie narzędziowe dla testów przezroczystej skrzynki. Służą do tego różnego rodzaju analizatory kodu. Narzędzia tego rodzaju pozwalają na weryfikację zgodności efektów pracy programistów z przyjętymi w ramach danej organizacji dobrymi praktykami tworzenia kodu. Badanie kodu pozwala także na zlokalizowanie możliwych przeoczeń programistów (np. puste lub nieosiągalne bloki programów, nieużywane zmienne, duplikowany kod). Narzędzia tej kategorii pozwalają na przejrzysty zapis reguł opisujących poprawny kod, a następnie analizę wybranych plików i tworzenie raportów opisujących wyniki analizy. Większość środowisk IDE posiada wbudowane w edytory kodu elementarne mechanizmy analizy kodu. Na przykład, pozwalają one kontrolować styl identyfikatorów, czy sprawdzać ich poprawność ortograficzną.
3.3. Metody automatyzacji wytwarzania i eksploatacji
Wszystkie omówione narzędzia można połączyć w cykl pełnej automatyzacji wytwarzania oraz eksploatacji oprogramowania. Na cykl ten składają się dwie podstawowe metody: wytwarzanie oprogramowania sterowane modelami oraz tzw. DevOps.
Wytwarzanie oprogramowania sterowane modelami (WOSM, ang. Model-Driven Software Development) dotyczy przede wszystkim tych dyscyplin inżynierii oprogramowania, które opierają się na wykonywaniu modeli: dyscyplinie wymagań, a także analizie i projektowaniu. Podstawą WOSM jest automatyzacja procesu przejścia między wymaganiami, projektem i kodem poprzez definiowanie i wykonywanie automatycznych transformacji między modelami. Elementem WOSM jest również automatyczna generacja kodu z modeli, która przenosi nas do dyscypliny implementacji systemu.
WOSM dostarcza technik w dwóch obszarach: definiowania języków modelowania w sposób formalny oraz definiowania przekształceń między modelami zdefiniowanymi w tych językach modelowania. Najczęstszym sposobem formalnego zdefiniowania graficznego języka modelowania jest tzw. metamodel. Metamodel to „model modelu”, który wyrażamy również w języku graficznym. Najczęściej jest to wariant modelu klas języka UML. Każda meta-klasa w metamodelu wyraża jeden element składni języka modelowania. Przykład bardzo prostego metamodelu widzimy na rysunku 3.1. Po lewej stronie rysunku widzimy diagram klas, który definiuje elementarny język modelowania składający się z kropek, kółek i strzałek. Jak wynika z metamodelu, język dopuszcza tworzenie modeli, w których kółka są połączone strzałkami. Z każdego kółka może wychodzić oraz wychodzić co najwyżej jedna strzałka. W kółkach mogą być zawarte kropki, przy czym może ich być maksymalnie dwie. Metamodel nie definiuje wyglądu elementów języka modelowania, a jedynie ich wzajemne relacje. Mówimy, że metamodel definiuje składnię abstrakcyjną języka. Po prawej stronie rysunku 13.1 widzimy przykład składni konkretnej, czyli składni widocznej dla użytkowników języka. Jak można się domyślić, na rysunku widzimy dwa kółka połączone dwoma strzałkami. W kółkach znajdują się odpowiednio – jedna oraz dwie kropki.

Rysunek 3.1: Przykład metamodelu prostego języka graficznego
Definicję swojej składni wyrażoną w postaci metamodelu posiadają praktycznie wszystkie języki modelowania, takie jak UML, BPMN czy ERD. Pozwala to na automatyczne przetwarzanie modeli. Każdy model jest przechowywany w odpowiednim repozytorium zgodnym z metamodelem. Taki model możemy odczytać przy pomocy odpowiedniego programu, a następnie dokonać automatycznej transformacji w inny model. Przykładem praktycznego zastosowania takiej automatyzacji jest automatyczna generacja struktury relacyjnej bazy danych (język ERD) z modelu dziedzinowego wyrażonego w języku UML.
Aby móc wykonywać transformacje modeli, należy napisać odpowiedni program transformujący. Programy takie możemy pisać w standardowych językach programowania, takich jak Java czy C#. Często jednak stosuje się języki dedykowane dla transformacji modeli. Wynika to z tego, że języki te posiadają specjalne konstrukcje, które ułatwiają deklarowanie przetwarzania składni języka wyrażonej za pomocą metamodelu. Języki te pozwalają na formułowanie „zapytań” do modeli, na podstawie których można znajdować fragmenty odpowiadające zadanym wzorcom (grafom wzorcowym). Takie fragmenty następnie podlegają przekształceniu poprzez np. transformacje tekstowe (konkatenacje słów, zmiana wielkości znaków itp.), dodawanie lub usuwanie elementów, czy też zmianę relacji między elementami.
Drugą metodą w cyklu automatyzacji inżynierii oprogramowania jest metoda nazywana DevOps (ang. Development and Operations), czyli – Rozwój i Obsługa. O ile metoda WOSM dotyczyła dyscyplin związanych z modelowaniem, o tyle DevOps dotyczy przede wszystkim dyscyplin związanych z kodowaniem (implementacja, testowanie, wdrożenie i utrzymanie). Podstawową zasadą metody DevOps jest stworzenie spójnego zestawu narzędzi, które w jak największym stopniu zautomatyzują powtarzalne i rutynowe czynności w cyklu życia kodu. Co jest szczególnie istotne – nacisk jest położony na zintegrowanie czynności związanych z wytworzeniem oprogramowania (rozwój) z czynnościami związanych z eksploatacją (obsługa). Zależność ta jest zilustrowana na rysunku 3.2.
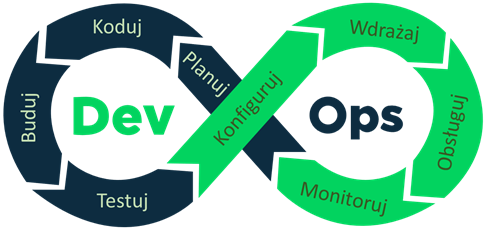
Rysunek 3.2: Schemat cyklu automatyzacji metodą DevOps
Cykl DevOps rozpoczyna się od etapu planowania. Etap ten jest wspierany przez narzędzia do zarządzania projektami dedykowane projektom konstrukcji oprogramowania. W szczególności, narzędzia te wspierają planowanie oraz kontrolę realizacji czynności w procesie implementacji systemu. Istotna jest również integracja tych narzędzi z narzędziami do śledzenia błędów i problemów. Każde zgłoszenie problemu może być dzięki temu w łatwy sposób zamienione na odpowiednie cechy systemu (np. historie użytkownika lub przypadki użycia) w planie projektu oraz czynności w planie odpowiednich iteracji.
Następny etap to kodowanie. Na pierwszy plan wchodzą tutaj oczywiście narzędzia IDE wraz z centralnymi repozytoriami kodu oraz narzędziami do kontroli wersji. Jest to typowe środowisko pracy programistów. Bardzo ważna jest jednak integracja tego środowiska z innymi narzędziami. W pierwszej kolejności, integracja dotyczy narzędzi z etapu planowania. Dzięki integracji, programista wie na bieżąco, jakie czynności są konieczne do wykonania oraz bardzo szybko może zgłosić podjęcie czynności i jej wykonanie. W niektórych rozwiązaniach dzieje się to bezpośrednio podczas wykonywania typowych czynności związanych z zarządzaniem kodem i jego wersjonowaniem. Nie wymaga zatem dodatkowej pracy, a znacznie usprawnia komunikację w zespole.
Drugi obszar integracji narzędzi do kodowania jest związany z etapem budowy. Na tym etapie wykorzystywane są narzędzia do ciągłej integracji systemu. Integracja polega głównie na bezpośrednim uruchamianiu narzędzi integrujących z poziomu środowiska programistycznego IDE. Programista jednym przyciskiem jest w stanie skompilować i zintegrować cały system uzyskując bardzo szybko i automatycznie – gotowe do zainstalowania wydanie sytemu.
Kolejny obszar integracji dotyczy etapu testowania. Wykorzystując odpowiednie narzędzia możemy uruchamiać testy jednostkowe, automatycznie wykonywane podczas integracji systemu. Taka integracja jest szczególnie istotna dla testów regresyjnych. Programista ma możliwość szybkiego i automatycznego zweryfikowania, czy nie pojawiły się błędy dotyczące kodu już wcześniej sprawdzonego. Podobnie, możliwa jest automatyzacja wykonania testów akceptacyjnych. Po zintegrowaniu systemu uruchamiane są wtedy odpowiednie skrypty testowe sprawdzające działanie systemu z punktu widzenia jego użytkownika końcowego.
Na etapie testowania kończy się obszar rozwoju (Dev) i przechodzimy do obszaru obsługi (Ops). Ważne jest to, że przejście to jest automatyczne i ściśle zintegrowane. Obsługa rozpoczyna się od etapów konfiguracji oraz wdrożenia. Wykorzystywane są tu narzędzia do zarządzania konfiguracją oraz do ciągłego wdrażania. Wykorzystują one produkty narzędzi do ciągłej integracji. Często wykorzystywane są tutaj środowiska do konteneryzacji. Konfiguracja polega wtedy na stworzeniu odpowiedniego opisu kontenerów, które zawierają wszystkie moduły niezbędne do ich uruchomienia (kod wykonywalny, system bazy danych, system kolejkowania itd.). Kontenery te są budowane na etapie integracji. Na etapie konfiguracji z odpowiednich wersji kontenerów tworzony jest pakiet instalacyjny dla całego systemu. Następnie, odpowiednie wersje kontenerów są instalowane przy pomocy narzędzi do ciągłej instalacji. Instalacja odbywa się poprzez umieszczenie kontenerów w odpowiednich środowiskach kontenerowych.
Po zainstalowaniu systemu w środowisku wykonywalnym przechodzimy do etapu obsługi. Obsługa polega na uruchamianiu zainstalowanego systemu oraz utrzymywaniu uruchomionego systemu w ruchu. Tak jak już wspomnieliśmy, najlepszymi środowiskami wspierającymi te działania – w kontekście metody DevOps – są środowiska kontenerowe. Środowiska te pozwalają na ciągłą kontrolę działania uruchomionych kontenerów. Jednocześnie, bardzo łatwe jest dokonywanie serwisowania systemu poprzez zatrzymywanie kontenerów oraz szybkie uruchamianie kolejnych ich wersji. W łatwy sposób można również zarządzać obciążeniem systemu poprzez automatyzację uruchamiania wielu instancji kontenerów.
Ostatni etap cyklu DevOps to monitorowanie. Na tym etapie zbierane są różne informacje na temat działającego systemu. Informacje te są następnie przekazywane do zespołu deweloperskiego (Dev) w celu podjęcia dalszych działań rozwojowych. Zbierane informacje mogą dotyczyć zauważonych niedogodności w działaniu systemu, niewystarczającej wydajności czy też postulowanych rozszerzeń lub zmian funkcjonalności. Informacje te zbierane są przez odpowiednie narzędzia analityczne i przekazywane do systemów planowania projektu. W ten sposób zamyka się cykl DevOps.