Podręcznik
| Strona: | SEZAM - System Edukacyjnych Zasobów Akademickich i Multimedialnych |
| Kurs: | 1. Metoda podziału i oszacowań, techniki restrykcyjne i relaksacyjne |
| Książka: | Podręcznik |
| Wydrukowane przez użytkownika: | Gość |
| Data: | niedziela, 26 października 2025, 01:17 |
Opis
Wersja podręcznika: 1.0
Data publikacji: 01.01.2022 r.
Wykłady
W1…WN, odpowiadające w sumie ok. 10-12 godz. standardowego wykładu
1. Klasy problemów i pakiety optymalizujące
Rozdział ten stanowi wprowadzenie do podstawowych koncepcji wykorzystywanych w ramach kursu.
1.1. Wprowadzenie do problemów optymalizacji dyskretnej
Problemy całkowitoliczbowe optymalizacji są powszechnie spotykane w praktyce funkcjonowania przedsiębiorstw, w odniesieniu do takich obszarów jak problemy logistyczne, inwestycyjne, lokalizacyjne, szeregowania, ale też leżą u podstaw wielu dziedzin nauki, szczególnie matematyki stosowanej, informatyki, ekonomii, techniki, biologii, i in. Wyróżniającą cechą tych zadań, jest to, że natura zmiennych decyzyjnych jest dyskretna. Ten fakt, w powiązaniu z wymogiem skali rzeczywistej operowania na dużej ilości danych powoduje, że problemy optymalizacji dyskretnej mogą być bardzo trudne do rozwiązywania.
Badania operacyjne, inaczej mówiąc optymalizacja, to dziedzina nauki dostarczająca wiarygodnych metod, dających pewność co do optymalności wyniku. Uwaga - optymalny, to synonim 'najlepszy', czyli nie stopniuje się! Optymalny wynik uzyskuje się poprzez rozwiązanie formalnego, dobrze zdefiniowanego problemu matematycznego ↔ modelu optymalizacji, którego celem jest wybór programu działania (planu). Takie zadanie programowania matematycznego formalnie jest definiowane przez:
- funkcję celu
- warunki ograniczające plan działania, czyli przestrzeń dopuszczalną rozwiązań (zmiennych decyzyjnych)
W zależności od matematycznych właściwości zmiennych i relacji między nimi można mówić o zadaniach programowania liniowego, nieliniowego, kwadratowego, mieszanego, całkowitoliczbowego, i in. Modele i algorytmy w ramach tego kursu są omawiane w odniesieniu do modeli optymalizacji formułowanych w postaci zadania programowania mieszanego/ całkowitoliczbowego.
1.2. Modele najważniejszych klas problemów
Różnorodność problemów dyskretnych jest w zasadzie nieskończona. Wynika ona m.in. z niezwykle szerokiej gamy dziedzin, w której problemy optymalizacji dyskretnej mają zastosowanie. Jednocześnie, na najbardziej ogólnym poziomie problemy te łączy podobny cel: zwiększenie efektywności przy zachowaniu wymagań i ograniczeń na zasoby. Co więcej, często okazuje się, że problemy z różnych dziedzin wykorzystują podobne zestawy zmiennych decyzyjnych i ograniczeń, czyli dzielą podobną strukturę. Pomocne jest zatem przestudiowanie reprezentatywnych przykładów, które mogą służyć jako paradygmaty podczas modelowania i rozwiązywania innych problemów o podobnej strukturze.
Przypomnijmy przy tym, że w przypadku rozwiązywania problemów dyskretnych gotowymi solwerami duże znaczenie może mieć sformułowanie modelu, w szczególności nierzadkie są przypadki niepotrzebnie złożonego sformułowania, wprowadzającego np. nieliniowości do modelu. Tym samym, zapoznanie się z klasycznymi problemami pomoże wypracować dobre praktyki tworzenia modeli optymalizacyjnych programowania matematycznego.
Klasy problemów
Wiele problemów dyskretnych może być przedstawianych jako zadania wyznaczania przepływów w sieci, należą do nich klasyczne problemy grafowe, takie jak:
- Najkrótsze i najtańsze ścieżki, przepływy w grafach,
- Cykl komiwojażera: Traveling Salesperson Problem (TSP),
- Przydziały i skojarzenia: Assignment Problem,
- Minimalne drzewo rozpinające: Minimum spanning tree.
W tym rozdziale przedstawiamy jedynie kilka wybranych, klasycznych problemów alokacji zasobów.
Problem plecakowy: Knapsack problem
Problem plecakowy/ zadanie załadunku polega na jak najlepszym wykorzystaniu zasobu (plecaka), w którym należy upakować jak najwięcej przedmiotów.
Oznaczenia:
 zbiór typów przedmiotów o wartości
zbiór typów przedmiotów o wartości  i wielkości
i wielkości  ,
, pojemność plecaka (zasobu)
pojemność plecaka (zasobu) zmienna decyzyjna ile przedmiotów typu
zmienna decyzyjna ile przedmiotów typu  zapakować.
zapakować.
Funkcja celu: 
Ograniczenia dotyczą dostępności zasobu, oraz przedmiotów:

Warianty problemu plecakowego
Problem typu plecakowego ma szerokie zastosowania w różnych dziedzinach, np. do tej kategorii zaliczamy problemy inwestycyjne i zadania alokacjai budżetu. Dodatkowe uwarunkowania prowadzą do wariantów podstawowego problemu, wyróżniamy np.:
- 0-1 Knapsack - tylko po jednej sztuce każdego towaru jest dostępne,
- Bounded knapsack - dostępna jest ograniczona liczba sztuk każdego towaru,
- Change-making - pojemność plecaka musi być w pełni wykorzystana (czyli ograniczenia na zasób w postaci równości),
- Multiple Knapsack - wiele różnych plecaków, inaczej problemy typu bin-packing, które dalej mogą być rozważane wraz z ograniczeniami kolejnościowymi, oknami czasowymi, itd.
Problem bin-packing
Problemy pakowania (i rozkroju, czyli w wariancie Cutting stock problem) najczęściej skupiają się na wykorzystaniu jak najmniejszej liczby zasobów.
Oznaczenia:
 pojemność pojemnika
pojemność pojemnika  ,
, zmienna decyzyjna ile przedmiotów typu zapakować do pojemnika
zmienna decyzyjna ile przedmiotów typu zapakować do pojemnika  ,
, zmienna decyzyjna czy wykorzystać pojemnik .
zmienna decyzyjna czy wykorzystać pojemnik .
Funkcja celu: 
Ograniczenia:

zostanie zapakowany do 1 pojemnika.Przydział zadań do procesorów/dostawców do odbiorców
Szeroka klasa problemów przydziału może być postrzegana jako wariant bin-packingu. W problemie takim zasoby to np. maszyny, dostawcy, itp. Natomiast zbiór reprezentuje zbiór zdań do realizacji/obsłużenia.
Oznaczenia:
 jest zapotrzebowaniem zadania , w wersji
jest zapotrzebowaniem zadania , w wersji  zróżnicowanym ze względu na zasoby, np. odpowiada czasowi wykonania zadania na maszynie ,
zróżnicowanym ze względu na zasoby, np. odpowiada czasowi wykonania zadania na maszynie , jest kosztem wykonania zadania na maszynie .
jest kosztem wykonania zadania na maszynie .
Funkcja celu minimalizuje koszty: 
Przy ograniczeniach jak w zadaniu bin-packingu, przy czym o ile w zadaniu nie ma kosztów stałych powiązanych z wykorzystaniem maszyny to nie podrzebujemy zmiennej binarnej  :
:

Problemy lokalizacyjne/dystrybucyjne
Klasycznym rozszerzenime problemu przydziału zadań do procesorów jest dodatkowe uwzględnie stałego kosztu użycia procesora. Problem tego typu jest określany jako problem lokalizacyjny, gdyż ma naturalne odzwierciedlenie w sytuacji wyboru punktów obsługi (klientów, pacjentów, mieszkańców, etc.). Problem ten posłuży nam do omówienia sposobu implementacji modeli w środowisku IBM Ilog Cplex w kolejnych rozdziałach.
Oznaczenia dodatkowe:
 jest stałym kosztem wykorzystania zasobu (ustanowienia zasobu w lokalizacji )
jest stałym kosztem wykorzystania zasobu (ustanowienia zasobu w lokalizacji )

Przy ograniczeniach jak w zadaniu bin-packingu:

1.3. Rozwiązywanie przy pomocy solwerów
Gwarancja optymalności planów i decyzji jest możliwa tylko wtedy, gdy problemy decyzyjne są rozwiązywane przy użyciu odpowiednich algorytmów. Wykorzystanie algorytmów optymalizacji, dostarczanych przez pakiety optymalizacyjne - tzw. solwery, daje pewność optymalności wyniku, ale wymaga odpowiedniego opisania tych problemów. Modelowanie matematyczne, wprowadzone we wcześniejszych rozdziałach, to sposób na opis problemów, który umożliwia zastosowanie efektywnych solwerów do ich rozwiązania. Znalezienie rozwiązania dla trudnych problemów decyzyjnych przy użyciu solwerów optymalizacji obejmuje zatem następujące działania, które można pogrupować w powiązanych ze sobą obszarach:
- model: formułowanie problemu w postaci matematycznej zadania programowania liniowego/mieszanego/całkowitoliczbowego/etc;
- dane: przygotowanie wartości liczbowych dla zbiorów i parametrów zdefiniowanych w modelu;
-
solwer:
- implementacja modelu, przygotowanie struktur danych, wczytanie danych i wygenerowanie konkretnej instancji problemu do rozwiązania;
- wywołanie programu, który obliczy najlepsze wartości zmiennych decyzyjnych i kryteriów dla wygenerowanej instancji problemu;
- wynik: przeanalizowanie rezultatów, wdrożenie planu lub poprawa założeń/ powrót do wcześniejszych kroków.
Gotowe solwery na wejściu oczekują modelu problemu w określonej strukturze, a do rozwiązywania wykorzystują gotowe, zaimplementowane algorytmy. Dobre solwery powinny wspierać separację danych od modelu, ale przede wszystkim oczekuje się od nich efektywności w rozwiązywaniu. Zwróćmy tu uwagę, że jakość/optymalność wyniku może zależeć od użytego solwera, ale też od sformułowania modelu -- użycie odpowiednich technik matematycznych może też mieć wpływ na efektywność rozwiązywania.
Podstawowym algorytmem dostępnym we wszystkich solwerach, również bezpłatnych, jest algorytm sympleksowy przeznaczony do rozwiązywania zadań programowania liniowego PL. Często występuje w wielu wersjach, np.: prymalnej, zrewidowanej, sieciowej, dualnej, w różnych modyfikacjach dualno-prymalnych, etc.. Solwery open-source oferujące efektywne algorytmy do zadań PL to m.in GLPK, lpsolve, GLOP (Google), OpenSolver (dodatek do arkuszy kalkulacyjnych), COIN-OR Optimization Suite, i wiele innych.
Solwery komercyjne, często udostępniane w ramach zintegrowanych pakietów optymalizacji stosuje się przede wszystkim do zadań ze zmiennymi binarnymi i całkowitoliczbowymi (MILP), jak też do wielkoskalowych zadań PL. Algorytmy, które są zaimplementowane w solwerach komercyjnych bazują na wariantach metody podziału i oszacowań, a ich siła leży w złożonych metodach tzw. presolvingu. Najlepsze popularne solwery to m.in.: IBM Ilog Cplex, Gurobi, Baron, COPT, minos...
Solwery są najczęściej wzbogacone o narzędzia komunikacji z użytkownikiem, w różnych trybach pracy:
- poprzez API wystawiane do popularnych języków programowania (C, C++, Python, Java, C\#, Matlab, R, Pyomo, ...)
- udostępniając dedykowane biblioteki modelowania, np.: PuLP (Python), COPT (C++), ...
- w najprostszym przypadku poprzez interaktywne komunikaty z linii poleceń
- poprzez zintegrowane środowiska, stosujące własne języki modelowania, np.: Ampl, Aimms, Matlab, Ilog CPLEX Studio, Gams, Pyomo, ...
W tym kursie proponujemy implementację modeli w środowisku modelowania ILOG CPLEX Optimization Studio, udostępnianym bezpłatnie w ramach programu Inicjatywy Akademickiej (Academic Initiative) IBM, jako w pełni funkcjonalna wersja, bez ograniczeń rozmiaru problemu. Dostęp do aktualnej wersji można uzyskać poprzez stronę http://ibm.biz/CPLEXonAI, po kliknięciu na 'Software'. Poprzez kartę ILOG CPLEX Optimization Studio zostaniesz przekierowany/a do rejestracji. Po zaakceptowaniu rejestracji będzie możliwe pobranie oprogramowania.
Na stronie IBM ILOG CPLEX Optimization Studio można znaleźć wiele materiałów wspomagających i szkoleniowych oferowanych bezpłatnie, w tym dokumentację z odnośnikami do samouczków, przykładów, itd. W tym materiale przedstawimy sformułowanie modelu i jego implementację w języku OPL, analizując przykładowy projekt.
1.4. Analiza modelu do implementacji
Rozważmy problem lokalizacji, którego opis oparty jest na materiale szkoleniowym [CPLEX Optimization Studio Fundamentals Tutorial](https://www.ibm.com/cloud/garage/dte/tutorial/cplex-optimization-studio-fundamentals-tutorial).
Opis. Firma rozważa kilka lokalizacji pod budowę magazynów, które wspomagałyby obsługę jej sklepów. Dany jest stały koszt otwarcia magazynu, a także koszt związany z zaopatrzeniem sklepu z każdej z potencjalnych lokalizacji. Warunki:
- Każdy sklep może być zaopatrywany tylko przez jeden magazyn.
- W każdej lokalizacji można postawić magazyn o określonej pojemności, wskazującej ile maksymalnie sklepów możne on obsłużyć.
Decyzje. Problemem jest podjęcie decyzji, ile magazynów i w których lokalizacjach otworzyć, aby jak najtaniej obsłużyć wszystkie sklepy.
Przykładową ilustrację zadania przedstawia poniższy rysunek z artykułu J. de Armas, et. al (2017) 'Solving the deterministic and stochastic uncapacitated facility location problem: from a heuristic to a simheuristic', Journal of the Operational Research Society, 68:10, 1161-1176, DOI: 10.1057/s41274-016-0155-6
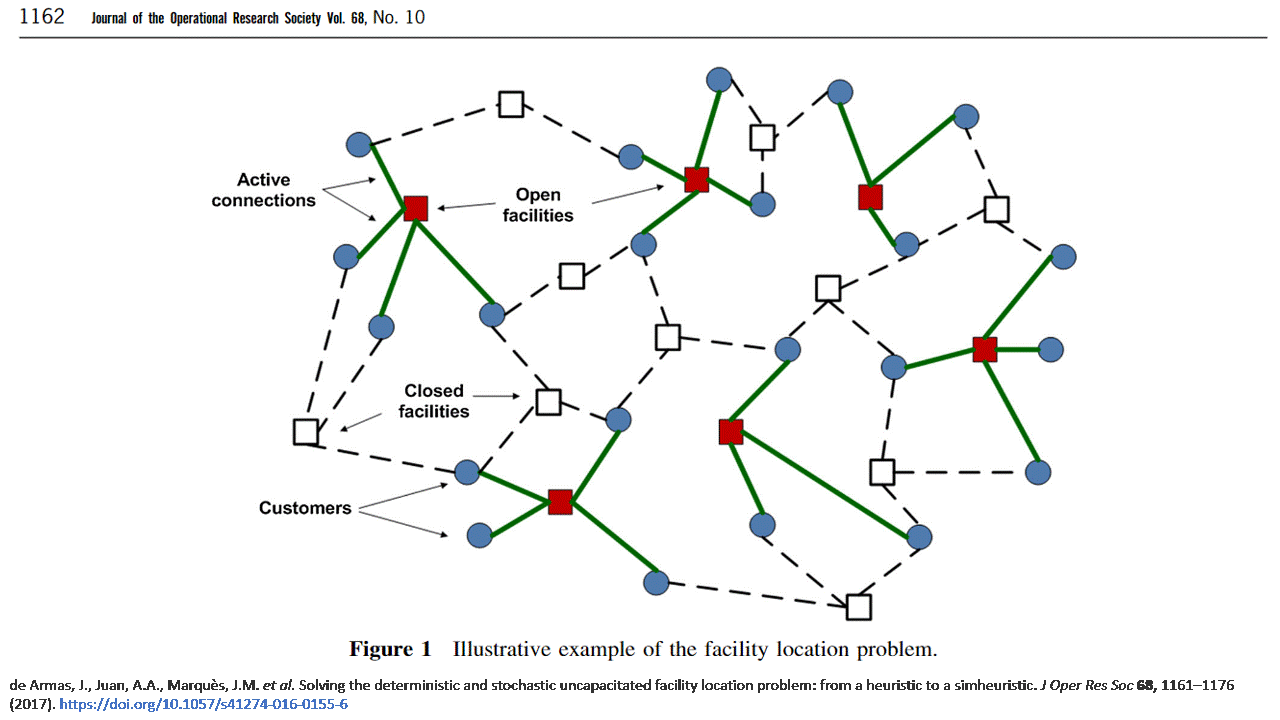
Dla ustalenia uwagi, może przyjąć następujące dane dla naszego problemu.
- Jest 5 potencjalnych lokalizacji magazynów - Bonn, Bordeaux, London, Paris, Rome oraz 10 sklepów.
- Koszty stałe otwarcia magazynu są takie same dla wszystkich lokacji i wynoszą 30.
- Poniższa tabela zawiera dopuszczalne pojemności magazynów i koszty zaopatrzenia sklepów.
| Bonn | Bordeaux | London | Paris | Rome | |
|---|---|---|---|---|---|
| max. pojemność | 1 | 4 | 2 | 1 | 3 |
| sklep 1 | 20 | 24 | 11 | 25 | 30 |
| sklep 2 | 28 | 27 | 82 | 83 | 74 |
| sklep 3 | 74 | 97 | 71 | 96 | 70 |
| sklep 4 | 2 | 55 | 73 | 69 | 61 |
| sklep 5 | 46 | 96 | 59 | 83 | 4 |
| sklep 6 | 42 | 22 | 29 | 67 | 59 |
| sklep 7 | 1 | 5 | 73 | 59 | 56 |
| sklep 8 | 10 | 73 | 13 | 43 | 96 |
| sklep 9 | 93 | 35 | 63 | 85 | 46 |
| sklep 10 | 47 | 65 | 55 | 71 | 95 |
Mogą być różne metody rozwiązywania przedstawionego problemu lokalizacji, który należy do jednego z klasycznych zadań optymalizacji. Jedną z metod jest sformułowanie problemu w postaci zadania programowania matematycznego i rozwiązanie przy użyciu solwera, co prezentujemy w tym rozdziale.
Formalnie, każdy model programowania matematycnego składa się z 3 części: oznaczeń, funkcji celu i ograniczeń. Zaczynamy od oznaczeń, które również składają się z 3 części: zbiorów, parametrów i zmiennych decyzyjnych. Parametry to wszelkie wartości liczbowe pojawiające się w sformułowaniu konkretnego przypadku liczbowego, tzw. case study. W naszym zadaniu najważniejsze dane zawiera przedstawiona powyżej tabela. Warto zwrócić uwagę, że wszelkie tabele pojawiające się w opisie zadania wskazują w naturalny sposób kandydatów do zbiorów: najczęściej znajdują się w pierwszej kolumnie, oraz/lub w pierwszym wierszu. W naszym przykładzie, dla danych przedstawionych w tabeli powyżej widzimy zbiór lokalizacji, oraz zbiór sklepów. W komórkach tabeli są parametry opisujące poszczególne lokalizacje oraz pary lokalizacja-sklep.
Uwaga - w modelach matematycznych najczęściej używamy jednoliterowych oznaczeń, a indeks dolny jest zarezerwowany dla wskazania elementu zbioru, do którego dane oznaczenie się odnosi.
Oznaczenia w analizowanym problemie:
Zbiory:
-
 lokalizacje dla magazynów (warehouses)
lokalizacje dla magazynów (warehouses)
 sklepy (stores)
sklepy (stores)
Parametry:
 stały koszt otwarcia magazynu (fixed cost)
stały koszt otwarcia magazynu (fixed cost) koszt zaopatrzenia sklepu
koszt zaopatrzenia sklepu  z magazynu
z magazynu  (supply cost)
(supply cost) max. pojemność magazynu (capacity)
max. pojemność magazynu (capacity)
Zmienne decyzyjne:
 czy sklep zaopatrzany z magazynu
czy sklep zaopatrzany z magazynu  czy magazyn otwarty
czy magazyn otwarty
Funkcja celu:
Kolejny element to zdefiniowanie funkcji celu, pozwalającej na ocenę rozwiązania, czyli konkretnych wartości zmiennych decyzyjnych. W rozważanym przykładzie chcemy jak najtaniej otwierać magazyny, oraz przydzielać do nich obsługiwane sklepy, czyli w funkcji celu minimalizujemy koszty:
")
Ograniczenia:
Ostatni element modelu, to wskazanie zależności, które muszą spełniać zmienne decyzyjne, aby rozwiązanie było dopuszczalne. W rozważanym problemie opisano dwa warunki, które przekładają się na matematyczny zapis trzech rodzajów ograniczeń:
(1) każdy sklep jest obsłużony przez dokładnie jeden magazyn :
(2) sklep
może być zaopatrzany z magazynu , o ile został on otwarty:
(3) liczba sklepów obsługiwanych przez otwarty magazyn
nie może przekroczyć jego pojemności: .
.W dalszej części przedstawiamy implementację modelu w środowisku CPLEX Studio.
1.5. Implementacja modelu
OPL to język modelowania problemów optymalizacyjnych, która ułatwia implementację modeli matematycznych w pakiecie ILOG CPLEX Optimization Studio. W tym rozdziale podajemy najważniejsze informacje, podczas pracy warto korzystać z udostępnionych narzędzi pomocy, czyli poprzez ”Help->Search”, np. dla przejrzenia słów kluczowych należy wpisać 'OPLkeywords', a do wglądu w dostępne funkcje należy wpisać 'OPLfunctions'.
Projekt
W Cplex Studio operuje się na projektach, odpowiadających konkretnym problemom. Każdy projekt musi zawierać przynajmniej jeden plik z modelem, jak też przynajmniej jedną specyfikację konfiguracji. Elementów tych może być więcej w projekcie, a formalnie można w nim definiować następujące składowe:
- plik z modelem ( .mod)
- plik z danymi ( .dat)
- konfiguracja uruchomienia "run configuration" wiążąca model z danymi
- plik z ustawieniami (.ops)
Wbudowane typy danych
Opl posługuje się standardowymi podstawowymi typami danych, które mogą być typu:
- int
- float
- string (napisy "w cudzysłowie")
Struktury danych
- zbiory (set): nawiasy klamrowe, w nich typ elementów zbioru np. {string} Warehouses = ...;
- tablice (array) 1- i wielowymiarowe: nawiasy kwadratowe, w nich rozmiar tablicy lub po prostu nazwy zbiorów - dla elementów tych zbiorów przechowywane są wartości w tablicy; typ wartości w tablicy trzeba podać, np. int SupplyCost[Stores][Warehouses] = ...;
- skalary: po prostu wartości danego typu wbudowanego, np. int Fixed = ...;
- zakres range: liczby całkowite (int) w pewnym zakresie podanym w definicji typu, np. range Stores = 0..NbStores-1;
- krotka tuple: odpowiednik wiersza tabeli, czyli powiązanie kilku typów danych ze sobą, np. tuple daneProduktu {string nazwa; int minZapas; float zapotrzebowanie}
Typy zmiennych decyzyjnych
Dla zmiennych decyzyjnych, które są deklarowane przy użyciu słowo kluczowe dvar (decision variable) dostępne są wbudowane typy liczbowe, jak też dodatkowo typ binarny, czyli zmienna 0-1. Pogrubieniem zaznaczyliśmy zmienne całkowitoliczbowe, których użycie w modelu powoduje, że problem staje się zadniem optymalizacji dyskretnej:
- int
- float
- boolean
Projekt warehouse
Implementacja problemu przedstawionego w poprzednim rozdziale jest już przygotowana w CPLEX Studio, należy ją otworzyć wchodząc poprzez menu 'File > New > Example menu' i wpisać nazwę 'warehouse'.
Widok okienka poniżej pokazuje katalog otwrtych projektów, w tym interesujący nas projekt 'warehouse', w którym są cztery pliki z modelami, cztery instancje konfiguracji uruchomienia oraz jeden plik z danymi. Uwaga - model, który przedstawiliśmy w poprzednim rozdziale jest zaimplementowany w pliku 'warehouse.mod'.
Rozwiązanie problemu
Aby rozwiązać problem musimy wygenerować jego konkretną instancję, czyli zapis modelu dla konkretnych danych - temu służy konfiguracja uruchomienia. Dla rozważanego przykładu przeznaczona jest tzw. konfiguracja domyślna, czyli 'Basic Configuration'. Gdy ją rozwiniemy, widzimy, że przekierowuje ona do naszego pliku z modelem, oraz pliku z danymi. W projekcie można mieć dowolną liczbę konfiguracji, w każdej z nich można mieć różne zestawy model+dane (+ustawienia solwera).Rozwiązanie problemu polega na uruchomieniu konfiguracji, co wykonujemy np. klikając prawym przyciskiem myszki na wybraną konfigurację i wybierając 'Run this'.
- Jeśli model zawiera błędy, to są one wyświetlane na karcie 'Problems'. Warto zwrócić uwagę, że IDE nie uruchamia w takiej sytuacji solwera, ponieważ najpierw należy poprawić błędy - kierując się opisem błędu i ew. poszukując dalszych wskazówek, np. na forum ibm.com;
- Gdy składnia modelu jest poprawna, IDE zaczyna rozwiązywać problem. Aktualizowane są wtedy zakładki obszaru 'Output Area', w szczególności można podejrzeć przebieg procesu rozwiązywania w 'Status Bar', a wyniki w zakładce 'Solutions'.
- Może się zdarzyć, że składniowo poprawny model zawiera błędy logiczne, lub występuje niespójność w danych. W takiej sytuacji solwer cplex wskazuje, że rozwiązanie jest sprzeczne, niedopuszczalne lub że problem jest nieograniczony (Infeasible, Unbounded). Dodatkowo, udostępniane są wspomagające narzędzia:
- Conflict refinement: w zakładce 'Conflicts' znajdziemy podpowiedź, które ograniczenia są wzajemnie sprzeczne, nie mogą być spełnione jednocześnie;
- Minimal relaxation: jeśli nie jest możliwe uzyskanie rozwiązania, to cplex stara się wyznaczyć rozwiązanie zadania zrelaksowanego (wynikowe okienko wyświetla wtedy Relaxed solution, przyjmując jak najmniejsze zmiany w definicji problemu) a wynik można obejrzeć w zakładce 'Relaxations'.
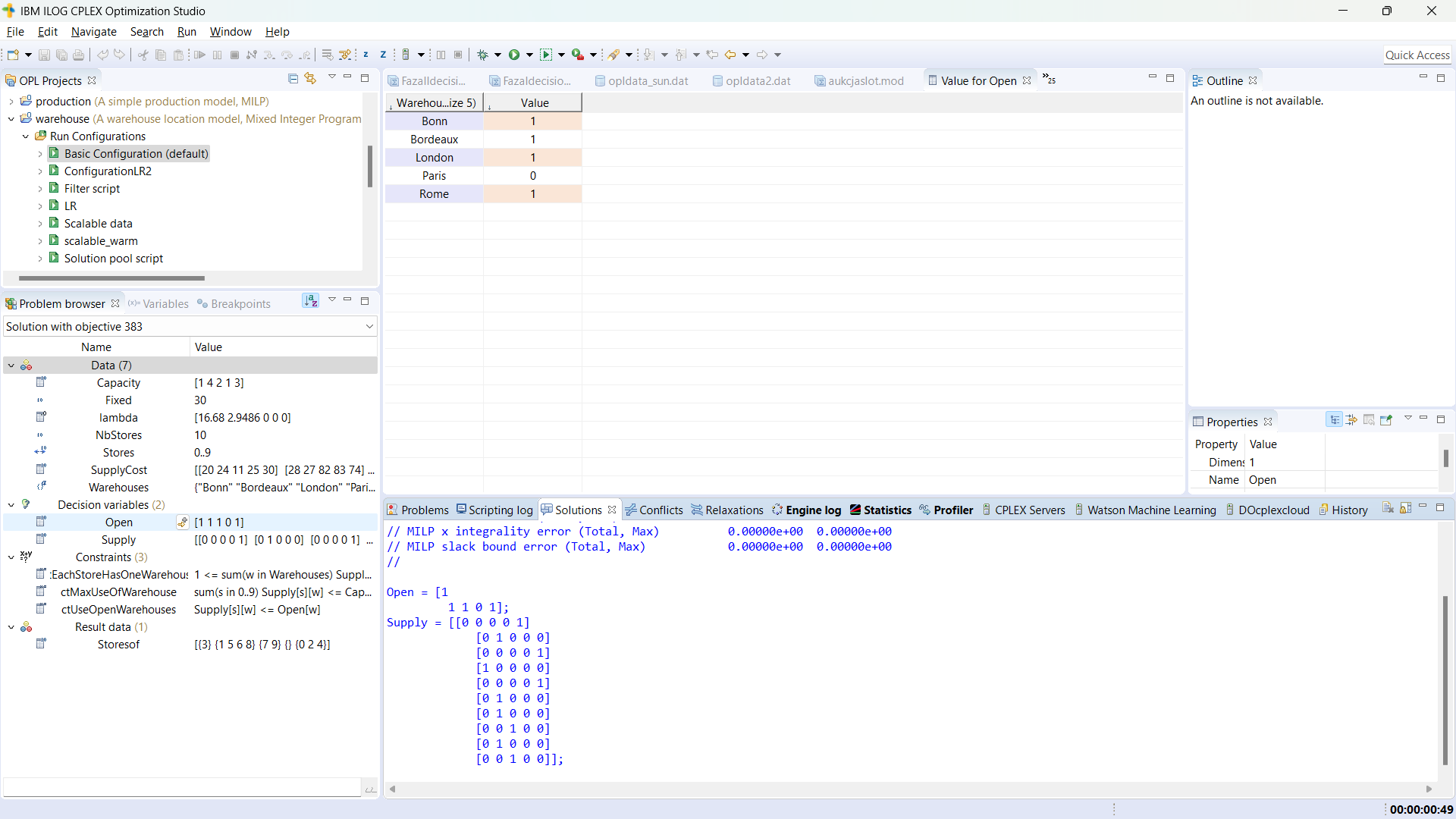
Ustawienia solwera
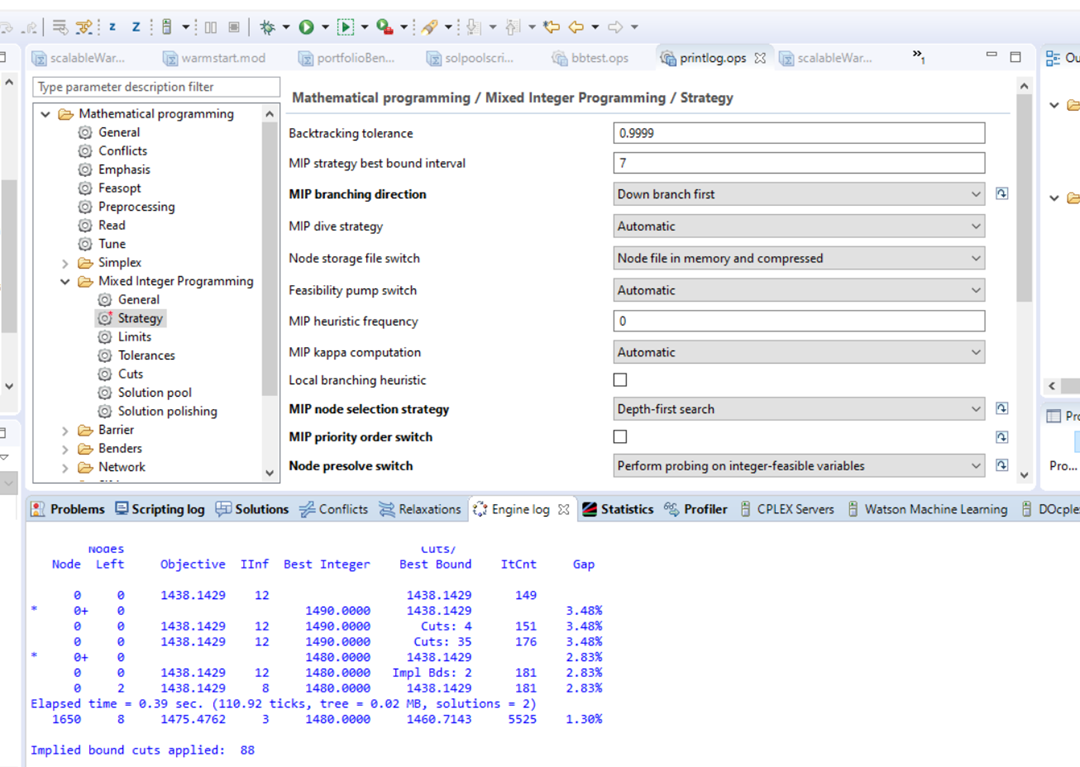
Wybór algorytmu oraz specyficznych dla niego parametrów przeprowadzamy w pliku .ops. W standardowym wykorzystaniu solwera nie ma potrzeby zmieniać domyślych ustawień, jednak w bardziej wymagających przypadkach wiedza o takich możliwościach bywa przydatna. Najłatwiej będzie zaobserwować zmiany w pracy solwera, gdy prześledzimy szczegóły rozwiązywania bardzo dużego problemu, zdefiniowanego w konfiguracji scalableWarehouse. Jest to wersja modelu lokalizacji magazynów, która nie ma powiązanego pliku danych. Liczby magazynów i sklepów oraz koszty są deklarowane w pliku modelu z danymi wewnętrznymi. Tym samym, problem można skalować poprzez zmianę liczby magazynów i sklepów - w przykładzie możemy ustawić np. 1000 sklepów i 100 lokalizacji magazynów. W konfiguracji przebiegu scalableWarehouse proponujemy zdefiniować plik ustawienia.ops (Prawy przycisk myszy New->Settings) i przeciągnąć go do konfiguracji.
Po otwarciu ustawienia.ops ustawmy MIP gap tolerancję względną na 1%:
- Klikamy na Mixed Integer Programming->Tolerances
- Wpisujemy wartość 0.01 dla Relative MIP gap tolerance Zmieniony parametr widać poprzez pogrubienie.
- Rozwiąż problem i porównaj czas i wyniki z modelem pierwotnym.
Poniższy rysunek pokazuje odpowiedni widok.

Uwaga. Ogólne wskazówki dla poprawy obliczania przy wykorzystaniu Cplexa, w tym dla ustawiania parametrów obliczania znaleźć można np. w artykule Practical guidelines for solving difficult mixed integer linear programs. W skrócie, do najważniejszych technik należy:
- wykonanie preprocessingu,
- dostarczenie dobrego rozwiązania dopuszczalnego (skorzystanie z opcji 'cplex mip start'),
- dopasowanie dokładności rozwiązania optymalnego (parametr 'mipgap'),
- skorzystanie z narzędzia 'tunning tool',
- dodanie własnych odcięć, przeformułowanie modelu.
2. Metoda podziału i oszacowań
Metoda podziału i oszacowań (B&B ang. branch and bound) stanowi podstawowy paradygmat rozwiązywania NP-trudnych problemów optymalizacji dyskretnej. Dla ustalenia uwagi problem (IP) zapiszmy jako: , p.o.:
, p.o.:  , tj.:
, tj.:


Metoda podziału i oszacowań zakłada:
- przegląd obszaru rozwiązań dopuszczalnych
 poprzez iteracyjny podział (branch) tego obszaru, czyli wydzielanie podproblemów dzięki dodaniu ograniczeń odcinających część rozwiązań,
poprzez iteracyjny podział (branch) tego obszaru, czyli wydzielanie podproblemów dzięki dodaniu ograniczeń odcinających część rozwiązań, - iteracyjne szacowanie (bound) rozwiązania w każdym podproblemie w sposób przybliżony, niedokładny, co uzyskiwane jest dzięki relaksacji podproblemu - najczęściej jest stosowana relaksacja warunku całkowitoliczbowości, ale też np. relaksacja Lagrange'a, i in..
Podproblemy (podziały) są organizowane w postaci drzewa. Metoda B&B pozwala na systematyczne i efektywne zawężanie zakresu dla optimum globalnego, gdyż w każdej iteracji wyznaczane jest:
- dolne oszacowanie LB (Lower Bound), czyli wartości f. celu podproblemu wskazująca na jego potencjalną atrakcyjność i potrzebę dalszej eksploracji (lub pominięcia),
- górne oszacowanie UB (Upper Bound), czyli najlepsza do-tej-pory wartość f. celu podproblemu, w którym osiągnięto rozwiązanie globalnie dopuszczalne, tzw. incumbent solution (np. całkowitoliczbowe, lub ogólnie, takie że ).
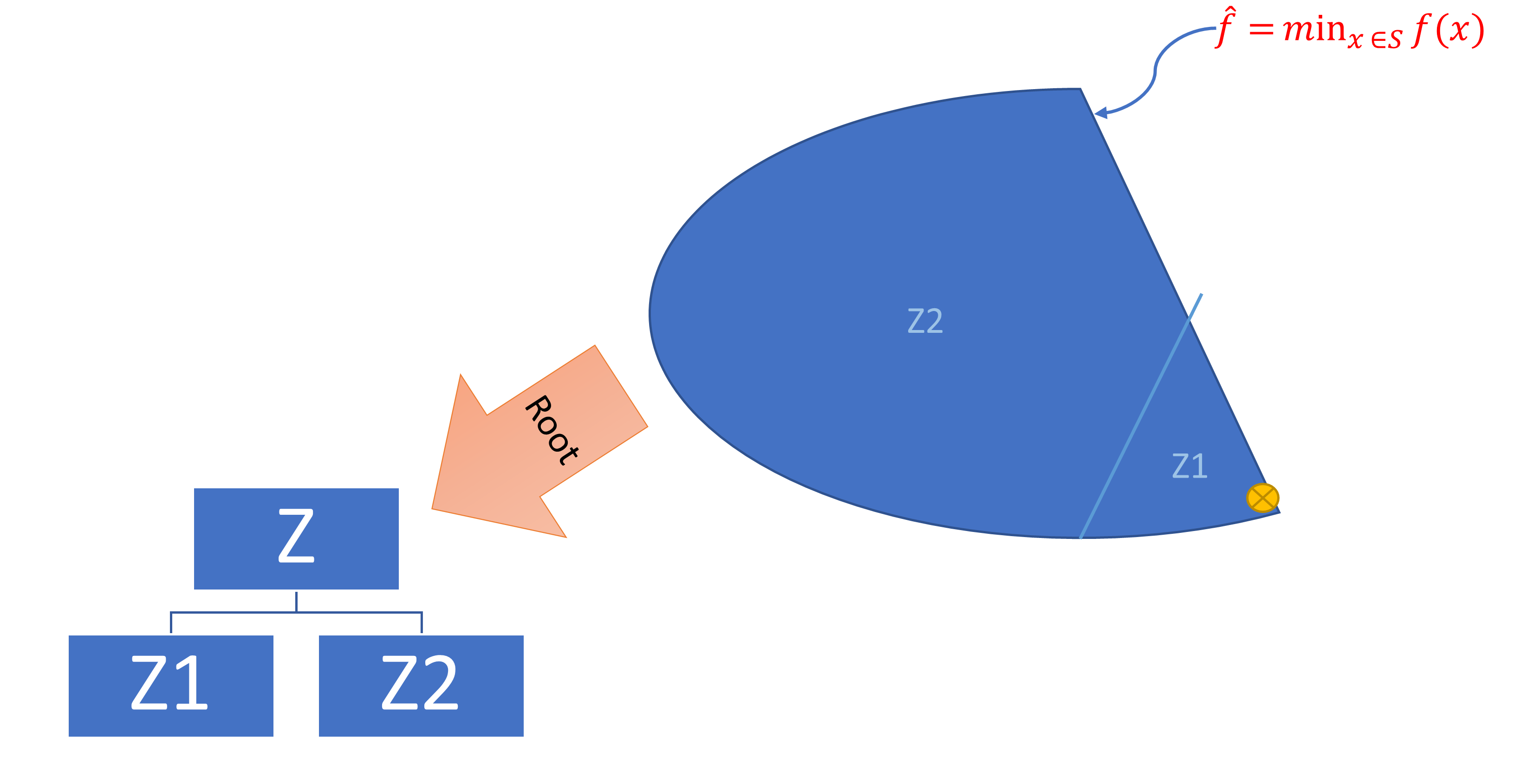
2.1. Iteracyjny proces poszukiwania rozwiązania: zawężanie oszacowań
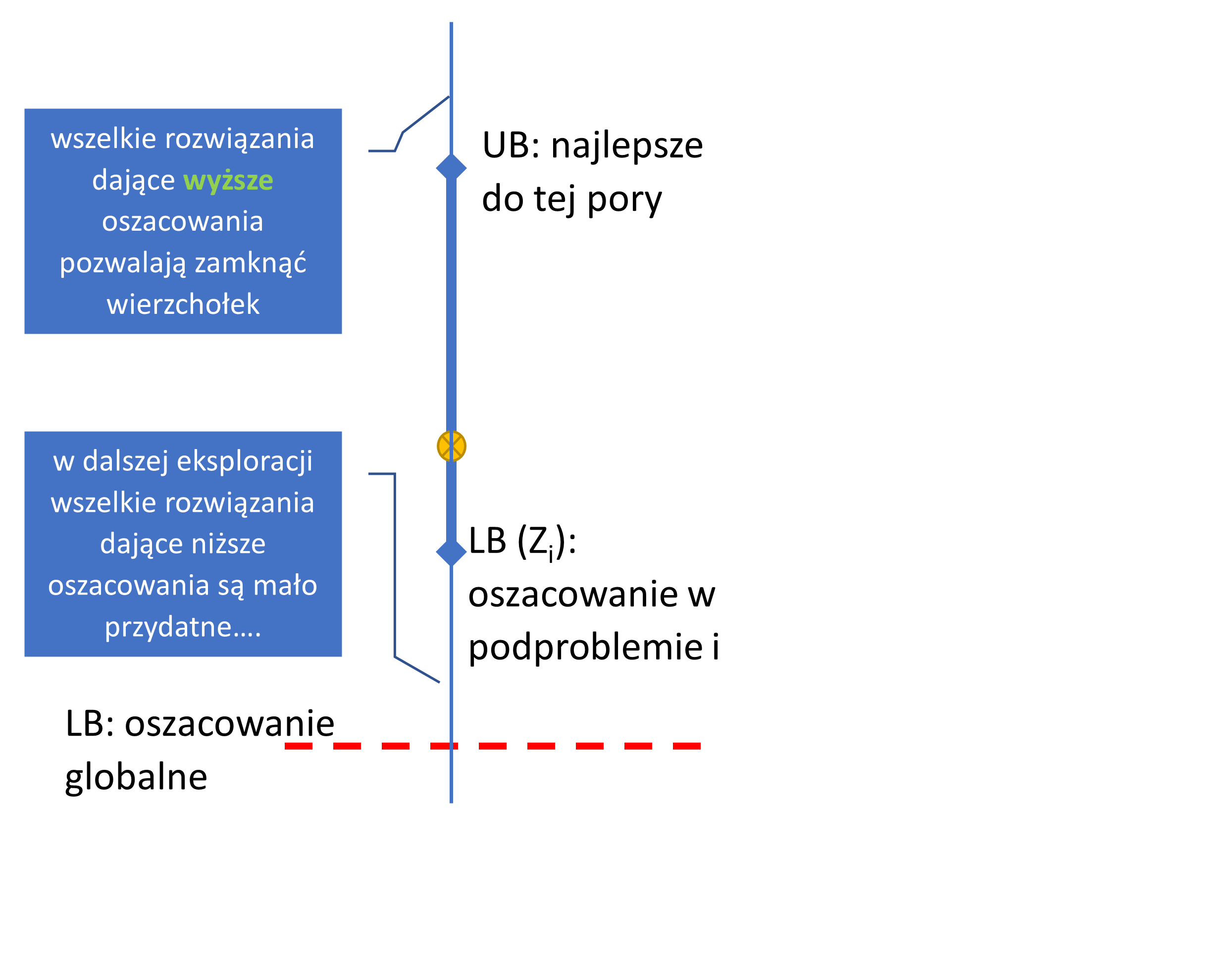
W pojedynczej iteracji znajdujemy się w konkretnym węźle drzewa B&B, gdzie rozwiązujemy zrelaksowane zadanie z dodatkowym ograniczeniem obszaru dopuszczalnego po to, aby uzyskać lokalne oszacowanie LB. Analizując LB oraz UB mamy dwie możliwości:
- podzielenie węzła, czyli dodanie ograniczeń, gdy aktualne, lokalne LB < globalne UB (jest szansa, że w danym obszarze znajdziemy lepsze rozwiązanie od tego, które mamy do tej pory), a następnie wybór części (węzła) do eksploracji;
- zamknięcie węzła i powrót poziom wyżej, co następuje w 3 przypadkach:
- rozwiązanie sprzeczne -- ograniczenie w tym węźle powoduje, że obszar dopuszczalny staje się pusty;
- rozwiązanie całkowitoliczbowe -- staje się nowym UB jeśli wartość lokalnego LB< globalne UB dotychczasowe;
- aktualne, lokalne LB > globalne UB -- zrelaksowane rozwiązanie w podproblemie gorsze niż najlepsze rozwiązanie do-tej-pory (nie ma szans, aby w danym obszarze znaleźć lepsze rozwiązanie od tego, które mamy do tej pory).
Zależności między LB i UB przedstawia poniższy rysunek.
x

-
Węzeł 0
Pierwszy węzeł (root node) jest relaksacją LP problemu.- UB ma wartość nieskończoność (de facto mogłoby by być np. 39*31= 1209 = 39*max{93/3; 64/17; 28/8})
- LB ma wartość minus nieskończoność (de facto mogłoby być 0)
Rozwiązanie, tj. wartości zmiennych decyzyjnych, nie są całkowitoliczbowe, dzielimy wierzchołek, a LB=209 (wszystkie współczynniki f. celu są całkowitoliczbowe, więc bezpiecznie można zaokrąglić wynik). Zauważmy, że zaokrąglając wartości zmiennych w górę moglibyśmy zaktualizować też UB=258=39*2+30*4+12*5.
Wybieramy zmienną do podziału, w najprostszym przypadku może być to pierwsza zmienna o wartości rzeczywistej, czyli w naszym przykładzie. Otrzymujemy dwa nowe podproblemy, wybieramy do dalszej eksploracji pierwszy z lewej.
w naszym przykładzie. Otrzymujemy dwa nowe podproblemy, wybieramy do dalszej eksploracji pierwszy z lewej.
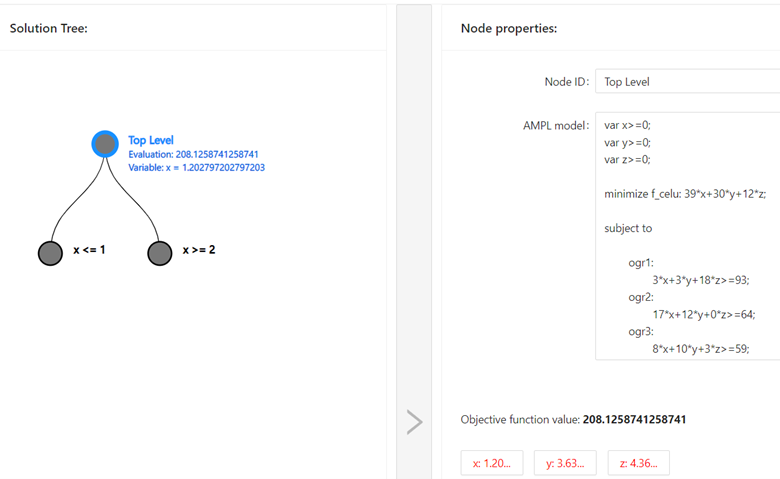
- Węzeł 1
Dzielimy kolejny wierzchołek ze względu na zmienną , co dla ograniczenia
, co dla ograniczenia  prowadzi do problemu sprzecznego. Wracamy poziom wyżej i eksplorujemy teraz prawą gałąź.
prowadzi do problemu sprzecznego. Wracamy poziom wyżej i eksplorujemy teraz prawą gałąź.
- Węzły 3--7
Kontynuujemy rozgałęzianie, aż w iteracji 7 (dla ) otrzymujemy rozwiązanie całkowitoliczbowe, które daje wartość UB=258.
) otrzymujemy rozwiązanie całkowitoliczbowe, które daje wartość UB=258.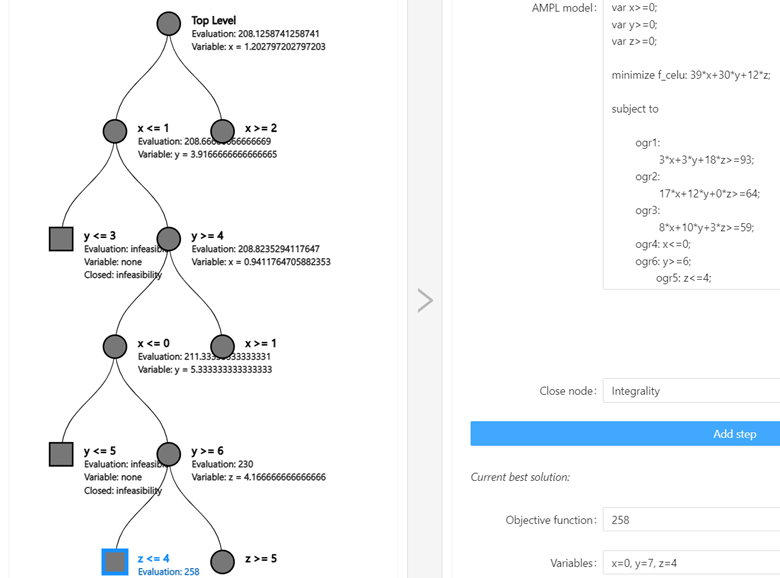
- Węzeł 8
Okazuje się, że w kolejnej iteracji (dla ) otrzymujemy lepsze rozwiązanie całkowitoliczbowe, więc UB=240.
) otrzymujemy lepsze rozwiązanie całkowitoliczbowe, więc UB=240.
- Koniec
Kolejne rozwiązanie całkowitoliczbowe uzyskujemy w kolejnych krokach. To poprawia aktualny UB z 240 na 219. Po rozwiązaniu problemu w prawej gałęzi, wychodzącej z wierzchołka 0 uzyskujemy LB=220, co pozwala nam zamknąć poszukiwania, gdyż LB>UB.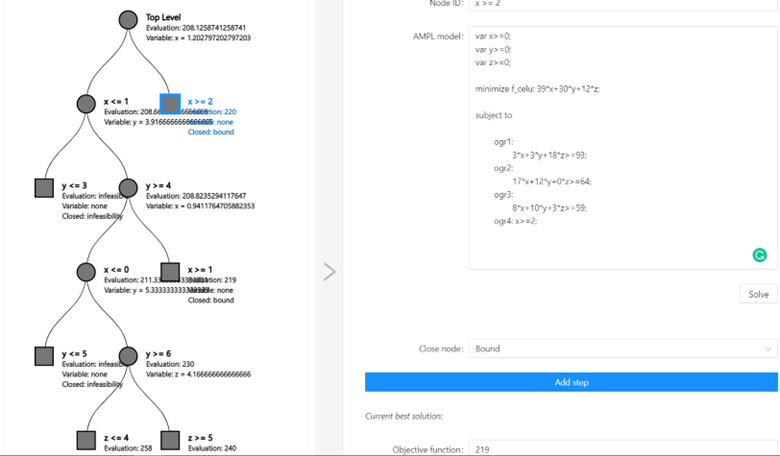
 .
.2.2. Formalna konstrukcja algorytmu
Formalnie, algorytm metody B&B dla zadania minimalizacji można zapisać następująco:- (Inicjalizacja): Przyjmij
 ={
={ }, UB=
}, UB= ,
,  .
. - (Zakończenie): Jeżeli ={
 }, to
}, to  dla którego osiągnięto UB jest rozwiązaniem optymalnym. Jeśli nie ma takiego rozwiązania, tj. UB=, to problem
dla którego osiągnięto UB jest rozwiązaniem optymalnym. Jeśli nie ma takiego rozwiązania, tj. UB=, to problem  jest sprzeczny lub nieograniczony.
jest sprzeczny lub nieograniczony. - (Wybór problemu i relaksacja): Wybierz oraz usuń z problem
 , rozwiąż jego relaksację. Jeśli rozwiązanie istnieje, przyjmij za
, rozwiąż jego relaksację. Jeśli rozwiązanie istnieje, przyjmij za  wartość f. celu, oraz za wartość zmiennych decyzyjnych. W przeciwnym przypadku
wartość f. celu, oraz za wartość zmiennych decyzyjnych. W przeciwnym przypadku  .
. - (Zamykanie wierzchołka):
- Jeżeli
 UB idź do Kroku 2.
UB idź do Kroku 2. - Jeżeli
 (rozw. całkowitoliczbowe) zaktualizuj UB= i
(rozw. całkowitoliczbowe) zaktualizuj UB= i  , oraz usuń z te problemy
, oraz usuń z te problemy  , dla których
, dla których  UB. Idź do Kroku 2.
UB. Idź do Kroku 2.
- Jeżeli
- (Podział wierzchołka): Przyjmij
 jako podział zbioru
jako podział zbioru  problemu na
problemu na  rozłącznych podzbiorów. Dodaj do wszystkie problemy
rozłącznych podzbiorów. Dodaj do wszystkie problemy  , gdzie
, gdzie  to problem z obszarem dopuszczalnym ograniczonym do
to problem z obszarem dopuszczalnym ograniczonym do  , oraz
, oraz  . Idź do Kroku 2.
. Idź do Kroku 2.
Kwestie wymagające inteligentnego podjęcia decyzji:
- pkt. 3 - wybór problemu (wierzchołka do eksploracji)
- pkt. 5 - sposób podziału problemu oraz
- pkt. 5 - wybór zmiennej do ograniczenia; Plus wybór sposobu relaksacji.
2.3. Rola funkcji szacującej jakość rozwiązań w podproblemie
Funkcją szacującą (ang. bounding function) nazywamy metodę pozwalającą wyznaczyć jakość rozwiązań w podproblemie zrelaksowanym.
Liczba wierzchołków drzewa B&B może rosnąć wykładniczo, dlatego ważne jest:
- Wyznaczenie oszacowania LB możliwie dużej wartości, blisko wartości optymalnej co pozwala na szybkie zamykanie podproblemów;
- Wyznaczenie oszacowania możliwie mało czasochłonne;
- Idealnie jeśli w podproblemie oprócz oszacowania LB potrafimy stosunkowo łatwo wyznaczyć rozwiązanie dopuszczalne;
- Dwie ogólne metody szacowania optymalnej f. celu:
- relaksacja części ograniczeń, optymalizacja w łatwiejszym (szerszym) zbiorze
 , takim że
, takim że  ;
; - modyfikacja f. celu tak, że
≤f(x)") , np. poprzez zastąpienie sumą kosztów implikowanych aktualnym ograniczeniem na zmienne.
, np. poprzez zastąpienie sumą kosztów implikowanych aktualnym ograniczeniem na zmienne.
- Relaksacja Lagrange’a: połączenie tych strategii – silne, ale czasochłonne,
- Najczęściej stosowana relaksacja liniowa, czyli odrzucenie warunku całkowitoliczbowości.
- relaksacja części ograniczeń, optymalizacja w łatwiejszym (szerszym) zbiorze
- Zastosowanie metody płaszczyzn tnących (cutting planes) przed rozpoczęciem algorytmu B&B - Zacieśnienie sformułowania LP w węźle 0;
- Duże znaczenie ma też stosowanie algorytmów obliczeń współbieżnych.
2.4. Reguły podziału węzła
Wyróżniamy następujące reguły podziału podproblemów.
Podział na 2 części (dytochomiczny)
- przy stosowaniu relaksacji liniowej wprowadzane są dwa ograniczenia na zmienną , której wartość nie jest całkowitoliczbowa: jeśli zapiszemy wartość
 , gdzie
, gdzie  jest częścią ułamkową, to warunki podziału mają postać:
jest częścią ułamkową, to warunki podziału mają postać: - generalizacja podziału, tzw. ograniczenie GUB (generalized upper bound): w zadaniach przydziału, w których wymagamy aby tylko jedna zmienna miała wartość niezerową, czyli z ograniczeniami postaci
 można dzielić węzeł, ze względu na sumaryczną wartość zmiennych, których wartości są zbliżone, czyli dzielimy
można dzielić węzeł, ze względu na sumaryczną wartość zmiennych, których wartości są zbliżone, czyli dzielimy  i wymagamy aby
i wymagamy aby  lub
lub  (w orginalnym zbiorze te dwie sumy są ułamkowe i mają zbliżone wartości)
(w orginalnym zbiorze te dwie sumy są ułamkowe i mają zbliżone wartości)


- wg największej/najmniejszej niedopuszczalności - wybierana zmienna, której wartość jest najdalej/najbliżej od jej wartości zaokrąglenia
- na podstawie szacowanej wartości zmiennej: różne sposoby szacowania pogorszenia funkcji celu, aby ocenić opłacalność wymuszenia ograniczenia danej zmiennej
- wyliczanie kar (penalty) na podstawie kosztów zredukowanych zmiennej, dla której sprawdzamy koszty wyjścia z bazy (w metodzie dual simplex),
- szacowanie pseudokosztów zredukowanych na podstawie wartości f. celu, w której zmienna wymuszona na wartość całkowitoliczbową,
- szacowanie pseudocen dualnych - j.w. tylko w odniesieniu do cen dualnych, a nie kosztów zredukowanych,
- silny podział (strong branching) - wyliczenie wartości f. celu w kilku iteracjach algorytmu simplex, przy ustalonej (całkowitoliczbowej) wartości zmiennej;
- użycie priorytetów podanych przez użytkownika.
Użycie hiperpłaszczyzn (branch and cut)
- Na podstawie znajomości struktury problemu dodajemy odcięcia angażujące większą liczbę zmiennych, uzyskane np. poprzez agregację niektórych ograniczeń.
Podział na wiele części (politochomiczny)
- Przykładowo, w problemie komiwojażera (TSP), dla relaksacji opartej na drzewie rozpinającym możemy wybierać wiele restrykcji dla konkretnego podproblemu, gdyż sprowadzają się one do usunięcia konkretnych krawędzi z aktualnej drogi TSP; przykład można znaleźć w książce W. L. Winstona „Operations research - Applications and Algorithms" Thomson Learning (2004);
- priorytet zmiennej do wyboru na podst. znajomości problemu: w najprostszym przypadku wg wektora cen.
| A | B | C | D | E | |
|---|---|---|---|---|---|
| A | - | 132 | 217 | 164 | 58 |
| B | 132 | - | 290 | 201 | 79 |
| C | 217 | 290 | - | 113 | 303 |
| D | 164 | 201 | 113 | - | 196 |
| E | 58 | 79 | 303 | 196 | - |
Jako LB przyjmij rozwiązanie zadania minimalnego drzewa rozpinającego (minimum spanning tree). Wskazówka - zastosuj podział politochomiczny w następujący sposób. W każdej iteracji metody B&B wybierz z aktualnego rozwiązania drzewa rozpinającego to miasto, które jest połączone z więcej niż dwoma innymi miastami, tj. miasto reprezentowane przez wierzchołek o stopniu większym niż dwa. Wydziel nowe podproblemy odrzucając kolejno możliwość użycia każdego z owych połączeń przy konstrukcji nowego drzewa rozpinającego.
2.5. Strategia przeszukiwania: wybór węzła do eksploracji
W ostatniej części tego rozdziału przedstawiamy najpopularniejsze strategie przeszukiwania drzewa BB, gdzie kluczową trudnością jest zachowanie odpowiedniego kompromisu między szybkością znalezienia rozwiązania dopuszczalnego i optymalnego.
Wyróżniamy strategie:
- BeFS (best first search): wybierany wierzchołek o najlepszym oszacowaniu (inaczej best bound)
- modyfikacja: best estimate z wykorzystaniem pseudokosztów, lub pseudocen dualnych,
- wierzchołki krytyczne – takie, dla których oszacowania b. bliskie optimum; nie da się ich prosto wyeliminować i muszą być rozpatrzone aby udowodnić optymalność rozwiązania – możliwy problem z pamięcią, gdy dużo takich wierzchołków;
- BFS (breadth first search): wszerz
- z każdym poziomem liczba wierzchołków rośnie wykładniczo;
- DFS (deapth first search): wgłąb, można użyć rekurencji
- jeśli rozwiązanie dopuszczalne jest daleko od optimum to drzewo b. głębokie;
- Selekcja: DFS i BeFS – gdy wybór między gałęziami o dużych różnicach w oszacowaniach;
3. Techniki restrykcyjne i relaksacyjne
Wiele trudnych obliczeniowo problemów optymalizacji dyskretnej ma strukturę, która poddaje się dekompozycji, czyli może być rozbita na stosunkowo łatwe do rozwiązania podproblemy. Podproblemy te można wydzielać dla grupy ograniczeń, bądź zmiennych. Pozwala to na pominięcie pewnych sprawiających trudność ograniczeń lub zmiennych całkowitoliczbowych, które są następnie ujmowane w procesie poszukiwania rozwiązywania, najczęściej w iteracyjny sposób. W pierwszym przypadku, tj. wydzielania trudnych ograniczeń, szczególnie użyteczne są metody relaksacji Lagrange‘a, w drugim zaś techniki restrykcyjne, np. metoda dekompozycji Bendersa.
3.1. Relaksacja Lagrange'a
Relaksacja Lagrange'a (Lagrangian Relaxation) to jedna z najważniejszych technik relaksacji, czyli metod aproksymacji trudnego zadania optymalizacji przy pomocy zadania prostszego. Rozwiązanie prostszego, zrelaksowanego problemu daje przybliżenie, aproksymację optymalnego rozwiązania oryginalnego problemu. Dla zadań optymalizacji dyskretnej najprostszą relaksacją jest odrzucenie warunku całkowitoliczbowości (stosowane np. w metodzie podziału i oszacowań), czyli tzw. relaksacja liniowa. Stosowanie relaksacji Lagrange'a daje lepsze efekty, w sensie wartości funkcji celu.
Zapiszmy problem minimalizacji jako zadanie:
, p.o.:
\geq d")
\leq b")

gdzie zbiór ograniczeń definiowanych funkcją ") ma stosunkowo prostą strukturę i można je uznać za łatwe, natomiast zbiór ograniczeń
ma stosunkowo prostą strukturę i można je uznać za łatwe, natomiast zbiór ograniczeń ") jest uznawany za trudny. Wtedy uproszczenie problemu, czyli jego relaksacja będzie polegać na pominięciu trudnych ograniczeń. Dla zadania minimalizacji, rozwiązanie problemu zrelaksowanego pozwala uzyskać oszacowanie dolne (lower bound).
jest uznawany za trudny. Wtedy uproszczenie problemu, czyli jego relaksacja będzie polegać na pominięciu trudnych ograniczeń. Dla zadania minimalizacji, rozwiązanie problemu zrelaksowanego pozwala uzyskać oszacowanie dolne (lower bound).
W relaksacji Lagrange‘a nie pomija się całkowicie ograniczeń, lecz zamiast tego tworzy się tzw. funkcję Lagrange‘a dodając do funkcji celu liniową funkcję ”kary” za ewentualne przekroczenie ograniczeń. Uzyskana dzięki temu relaksacja jest znacznie silniejsza.
 nazywane mnożnikami Lagrange'a. Funkcję tę, dla zadań MILP zapisujemy jako:
nazywane mnożnikami Lagrange'a. Funkcję tę, dla zadań MILP zapisujemy jako:=\min \; c^T x + \lambda\cdot(g(x)-b),\;\;") p.o.:
p.o.:
Wektor mnożników Lagrange'a ma wyceniać wartości pominiętych ograniczeń, czyli musi być określony w taki sposób, że wartości funkcji Lagrange'a są zgodne z wartościami funkcji celu pierwotnego problemu. Można też wykazać silny związek między mnożnikami Lagrange'a a zmiennymi zadania dualnego, wykracza to jednak poza zakres tego wykładu.
 miastami jak najniższym kosztem, znając zapotrzebowania tych miast. W tym celu musimy zaplanować umiejscowienie magazynów, z których będziemy pobierać towar. W zależności od lokalizacji magazynów będziemy dysponować różnymi pojemnościami.
miastami jak najniższym kosztem, znając zapotrzebowania tych miast. W tym celu musimy zaplanować umiejscowienie magazynów, z których będziemy pobierać towar. W zależności od lokalizacji magazynów będziemy dysponować różnymi pojemnościami.Oznaczenia, parametry:
cities - zbiór miast oznaczanych indeksami

 - koszt zaopatrzenia klientów w mieście z magazynu w mieście
- koszt zaopatrzenia klientów w mieście z magazynu w mieście  - pojemność magazynu w mieście
- pojemność magazynu w mieście  - zapotrzebowanie miasta
- zapotrzebowanie miasta  - koszt budowy magazynu w mieście
- koszt budowy magazynu w mieście Zmienne:
 - czy w danym mieście wybudować magazyn (zm. binarna) - procent zapotrzebowania w mieście pokrywanego towarem z miasta , zmienna ciągła z zakresu
- czy w danym mieście wybudować magazyn (zm. binarna) - procent zapotrzebowania w mieście pokrywanego towarem z miasta , zmienna ciągła z zakresu 
Model matematyczny zadania:

p.o.:
(1)

(2)

(3)

(4)

Jedną z możliwych relaksacji jest usunięcie ograniczeń wymuszających zaopatrzenie każdego miasta, czyli ograniczeń (2). Taki zabieg pozwoli na dekompozycję rozważanego problemu na
zadań rozpatrywanych niezależnie dla każdego miasta. W tym celu wprowadzamy mnożnik  dla -tego ograniczenia (2), pomocniczo definiujemy też
dla -tego ograniczenia (2), pomocniczo definiujemy też  .
.
Funkcja Lagrange'a wyznaczająca dolne oszacowanie pierwotnego problemu jest wtedy postaci:
 L(x,\lambda) = \min_x \sum_{ij} \bar{c}_{ij}x_{ij} +\sum_i f_iy_i\\
\mathrm{po.}\\
(6) \sum_j d_jx_{ij} \leq M_iy_i\;\;\;\forall i\in \mathrm{cities}\\
(7) x_{ij}\leq y_i\;\;\;\forall i,j\in \mathrm{cities}\\ (8) x_{ij}\geq 0,\;\; y_i\in\{0,1\}\;\;\;\forall i,j\in \mathrm{cities}.")
Dekompozycja problemu. Aby rozwiązać powyższy problem relaksacji Lagrange'a niezależnie dla każdego z miast
sformułujemy zdekompowany problem postaci: \sum_j d_jx_{j} \leq M_iy_i\\
(10) x_{j}\leq y_i\;\;\;\forall j\in \mathrm{cities}\\
(11) x_{j}\geq 0,\;\; y_i\in\{0,1\}\;\;\;.") Zadanie
Zadanie  dla konkretnego miasta bardzo łatwo rozwiązać:
dla konkretnego miasta bardzo łatwo rozwiązać: -
gdy
 wtedy należy przyjąć
wtedy należy przyjąć  , co oznacza, że -te miasto nie będzie zaopatrywane z lokalizacji ;
, co oznacza, że -te miasto nie będzie zaopatrywane z lokalizacji ; - w p.p. sprawdzamy warunek, czy warto otworzyć magazyn w lokalizacji w następujący sposób:
- szeregujemy pozostałe zmienne
 w takiej kolejności, aby
w takiej kolejności, aby  ;
; - następnie przez przez oznaczamy najwyższy indeks, dla którego suma kolejnych zapotrzebowań nie przekracza pojemności magazynu , tj., dla którego jest spełnione ograniczenie
 ; ewentualny zapas pojemności magazynu dzielimy przez zapotrzebowanie miasta następnego w kolejności, czyli wyznaczamy parametr
; ewentualny zapas pojemności magazynu dzielimy przez zapotrzebowanie miasta następnego w kolejności, czyli wyznaczamy parametr  jako ułamek:
jako ułamek:  ;
; - podejmujemy decyzję o otwarciu magazynu w mieście , czyli przyjmujemy
 jeśli koszt
jeśli koszt  , w p.p.
, w p.p.  ;
; - jeśli to
 , dla
, dla  , natomiast
, natomiast  .
.
- szeregujemy pozostałe zmienne
łatwo wyznaczyć odnosząc się do sumarycznego zapotrzebowania we wszystkich miastach (sumaryczna pojemność największych magazynów musi pokrywać całkowite zapotrzebowanie). Analizowana metoda pozwala wyznaczyć dolne oszacowanie optymalnego rozwiązania, należy w tym podejściu tak dobierać wektor mnożników , aby uzyskane oszacowanie miało jak najwyższą wartość.Szczegółowe omówienie przedstawionego tu problemu lokalizacyjnego można znaleźć w pracy Alenezy, Eiman J. "Solving capacitated facility location problem using Lagrangian decomposition and volume algorithm." Advances in Operations Research 2020. Ostatecznie autorzy stosują subgradientową technikę do iteracyjnego wyznaczania mnożników Lagrange'a, w dalszej części tego rozdziału przedstawiamy teoretyczne podstawy tego podejścia.
 , która dla dowolnie dużych mnożników λ osiąga wartość pierwotnej funkcji celu:
, która dla dowolnie dużych mnożników λ osiąga wartość pierwotnej funkcji celu:

 jest zbiorem rozszerzonym, uzyskanym przez relaksację ograniczeń wprowadzonych do funkcji Lagrange'a.
jest zbiorem rozszerzonym, uzyskanym przez relaksację ograniczeń wprowadzonych do funkcji Lagrange'a. :
:

-
 dla ograniczeń równościowych, czyli np.
dla ograniczeń równościowych, czyli np. 
 dla ograniczeń typu ≤ , czyli np.
dla ograniczeń typu ≤ , czyli np. 
 dla ograniczeń typu ≥, czyli np.
dla ograniczeń typu ≥, czyli np.  .
.
 jest relaksacją pierwotnego problemu optymalizacji, pozwala na oszacowanie od dołu minimalizowanej funkcji celu:
jest relaksacją pierwotnego problemu optymalizacji, pozwala na oszacowanie od dołu minimalizowanej funkcji celu: i w szczególności
i w szczególności  .
. . W punkcie optymalnym
. W punkcie optymalnym 
- Można udowodnić, że wartość funkcji nie zmieni się, jeżeli dopuszczalny zbiór X problemu pierwotnego zastąpimy jego uwypukleniem
 . Zauważmy, że
. Zauważmy, że  , co jest zgodne z obserwacją o przewadze relaksacji Lagrange'a nad relaksacją liniową.
, co jest zgodne z obserwacją o przewadze relaksacji Lagrange'a nad relaksacją liniową. - Funkcja jest wklęsła względem λ, czyli wystarczy znaleźć maksimum lokalne i można je wyznaczyć metodami subgradientowymi.
- Rozwiązanie optymalne funkcji spełnia warunek komplementarności, czyli jeśli pewne
 to odpowiadające im ograniczenia
to odpowiadające im ograniczenia  są spełnione.
są spełnione. - Do wyznaczenia oszacowania wystaczy znaleźć rozwiązanie dopuszczalne zadania dualnego, nie trzeb szukać jego optimum.
 jest realizowane metodami optymalizacji bez ograniczeń, w szczególności tzw. metodą subgradientową. Mnożniki Lagrange'a wyznacza się iteracyjnie, zgodnie ze schematem:
jest realizowane metodami optymalizacji bez ograniczeń, w szczególności tzw. metodą subgradientową. Mnożniki Lagrange'a wyznacza się iteracyjnie, zgodnie ze schematem:
 (relaksowane ograniczenie ma postać ).
(relaksowane ograniczenie ma postać ).
 a
a Formalna konstrukcja algorytmu wyznaczania mnożników Lagrange'a:
- Krok 0. Dane: zbiór otrzymany ze zbioru X przez relaksację ograniczeń, wprowadzonych do funkcji Lagrange'a. Parametry:
- maksymalna liczba iteracji

- maksymalny odstęp dualności

- początkowe wartości mnożników Lagrange'a

- oszacowanie od góry dualnej funkcji Lagrange'a

- metoda aktualizacji mnożników
- k=0
- maksymalna liczba iteracji
- Krok 1. Oblicz
 oraz
oraz  rozwiązując zrelaksowane zadanie Lagrange'a
rozwiązując zrelaksowane zadanie Lagrange'a 
- Krok 2. Sprawdź, czy jest prymalnie dopuszczalne, jeśli tak, oblicz
 . Jeśli
. Jeśli  to STOP
to STOP - Krok 3. Wyznacz rozmiar kroku
 , jeśli
, jeśli  to STOP
to STOP - Krok 4. Zaktualizuj
 ,
,  , jeśli
, jeśli  to STOP, w p.p. wróć do kroku 1
to STOP, w p.p. wróć do kroku 1

Problemy z metodą RL
 uzyskanego w wyniku rozwiązania zadania zrelaksowanego, gdyż może ono przekraczać ograniczenia zrelaksowane.
uzyskanego w wyniku rozwiązania zadania zrelaksowanego, gdyż może ono przekraczać ograniczenia zrelaksowane.Znajdowanie rozwiązań dopuszczalnych
Obszary badań
- algorytmy wyznaczania parametrów początkowych (
 )
) - algorytmy aktualizacji mnożników
- algorytmy wyznaczania rozwiązania dopuszczalnego
- algorytmy specjalizowane dla konkretnych problemów.
3.2. Restrykcja - dekompozycja Bendersa
W tym rozdziale pokażemy możliwości wykorzystania dekomponowalnej struktury zadania lokalizacji, stosując zamiast relaksacji techniki restrykcji. Restrykcja to technika polegająca na dodatkowym ograniczaniu zbioru dopuszczalnego problemu optymalizacji. W omawianej we wcześniejszych rozdziałach metodzie podziału i oszacowań restrykcja była wykorzystywana do wydzielania części obszaru dopuszczalnego poprzez narzucenie ograniczeń typu nierównościowego na zmienne. W metodzie opracowanej przez Bendersa w 1962r. restrykcja polega na narzuceniu konkretnych wartości wybranym zmiennym całkowitoliczbowym, podczas gdy pozostałe zmienne są optymalizowane. Metoda Bendersa ma zatem zastosowanie do rozwiązywania tylko pewnych klas problemów optymalizacji, dla których w możliwy jest rozdział zmiennych, w szczególności prowadzący do wyodrębnienia zadania programowania liniowego oraz zadania programowania dyskretnego, które jest łatwiejsze do rozwiązywania od pierwotnego problemu dyskretno-ciągłego.
Przypomnijmy, ze w zadaniu lokalizacji rozważanym w poprzednim podrozdziale poświęconym relaksacji Lagrange'a problem pierwotny polega na określeniu, w których miastach otworzyć magazyny (zmienna binarna ) oraz w jakich proporcjach zaspokoić zapotrzebowanie klientów w miastach zaopatrywanych przez magazyny (zmienna ciągła z zakresu ). Dla uproszczenia, analizujemy łatwieszą wersję problemu, w którym pomijamy ograniczone pojemności magazynów.
Sformułowanie matematyczne problemu pierwotnego P:

p.o.:
(1)
(2)
(3)
Zdefiniujmy teraz problem operujący tylko na zmiennych ciągłych , w którym jest traktowane jako parametr - zostało poddane restrykcji. Przyjmując, że wartości wektora są ustalone, restrykcja ") zadania (P) jest podproblemem sparametryzowanym przez y. W takiej sytuacji jest zadaniem liniowym względem zmiennej x o następującej postaci:
zadania (P) jest podproblemem sparametryzowanym przez y. W takiej sytuacji jest zadaniem liniowym względem zmiennej x o następującej postaci:
= \min \sum_{ij} c_{ij}x_{ij}")
p.o.:
(4) 
(5) 
(6) 
W powyższym sformułowaniu oznaczyliśmy też zmienne dualne do ograniczeń (4) i (5), które będą wykorzystane w dalszej analizie metody Bendersa. Przypomnijmy, że sformułowanie dualne można rozważać tylko dla problemów ze zmiennymi ciągłymi - a taki właśnie jest problem . Zauważmy przy okazji, że problem może być zdekomponowany na niezależnych podproblemów optymalizacji, podobnie niezależnie można określać odpowiednie zmienne dualne . Podproblem ") :
:
= \min \sum_{i} c_{ij}x_{ij}")
p.o.:
(7) 
(8) 
(9) 
W metodzie dekompozycji Bendersa kolejnym elementem schematu postępowania jest sformułowanie dualne zadania określane jako problem D1. Skorzystamy z możliwości dekompozycji zadania
na podproblemy i dla ułatwienia rozważań sformułujemy podproblem ") :
:
= \max \lambda_j+\sum_{i} y_iv_{ij}")
p.o.:
(10) 
(11)  .
.
Zmienna dualna w zadaniu jest nieograniczonego znaku, przy czym musi być zawsze niezerowa, tj. musi być zmienną bazową (każde miasto musi być zaopatrzone). Ze względu na maksymalizację, oraz ograniczenie (10) będzie przybierać najniższą z wartości , dla których  . Natomiast w pozostałych przypadkach, z tego względu że w bazie nie może być dodatkowych zmiennych
. Natomiast w pozostałych przypadkach, z tego względu że w bazie nie może być dodatkowych zmiennych  (lub zmiennych dopełniających) szczególna postać tego zadania pozwala wyznaczyć rozwiązania zmiennych dualnych jako:
(lub zmiennych dopełniających) szczególna postać tego zadania pozwala wyznaczyć rozwiązania zmiennych dualnych jako:
^+, (c_{2j}-c_{kj})^+,\ldots, (c_{nj}-c_{kj})^+)") .
.
Stąd:
![\hat{r}^j = \max_{k\in \mathrm{cities}} [c_{kj}+ \sum_{i \in \mathrm{cities}}y_i(c_{ij}-c_{kj})^+]](https://esezam.okno.pw.edu.pl/filter/tex/pix.php/26eed7d449f4b246f617be06ddfaf8ed.gif "\hat{r}^j = \max_{k\in \mathrm{cities}} [c_{kj}+ \sum_{i \in \mathrm{cities}}y_i(c_{ij}-c_{kj})^+]") .
.
Najważniejszą cechą zadania dualnego w metodzie Bendersa jest to, że jego zbiór rozwiązań dopuszczalnych nie zależy od wyboru . Dzieje się tak, ponieważ ustalony jest pomijany w funkcji celu zadania pierwotnego, a jak pamiętamy, w ograniczeniach zadania dualnego wykorzystywane są jedynie współczynniki funkcji celu zadania prymalnego. Niezależność zbioru dopuszczalnego ") od wektora pozwala na rozważanie wyłącznie punktów wierzchołkowych tego zbioru, gdyż to w jednym z nich znajduje się optimum, którego wartość zależy od . To pozwala przekształcić problem P do równoważnego zadania D2. W rozważanym tu problemie lokalizacji jest on następującej postaci. Problem
od wektora pozwala na rozważanie wyłącznie punktów wierzchołkowych tego zbioru, gdyż to w jednym z nich znajduje się optimum, którego wartość zależy od . To pozwala przekształcić problem P do równoważnego zadania D2. W rozważanym tu problemie lokalizacji jest on następującej postaci. Problem  :
:

p.o.:
(12) ^+,\;\;\; \forall k,j\in \mathrm{cities}")
(13) 
(13)  .
.
Bezpośrednie rozwiązywanie zadania D2 jest na ogół niepraktyczne, gdyż wymaga wyznaczenia wszystkich punktów wierzchołkowych zbioru dualnego, co może być szczególnie kłopotliwe w przypadku dużej liczby wierzchołków. Dlatego Benders opracował iteracyjną procedurę, która pozwala na wyznaczenie optymalnego wierzchołka zbioru dualnego zazwyczaj w niewielkiej liczbie iteracji.
Formalna konstrukcja algorytmu Bendersa:
- Krok 0. Wyznacz wartość wektora zmiennych dualnych
 jako dowolne rozwiązanie dopuszczalne problemu dualnego - uwaga, nie musi to być punkt wierzchołkowy zbioru dopuszczalnego. Jeżeli rozwiązanie dopuszczalne nie istnieje, to STOP. W p. p. przyjmij
jako dowolne rozwiązanie dopuszczalne problemu dualnego - uwaga, nie musi to być punkt wierzchołkowy zbioru dopuszczalnego. Jeżeli rozwiązanie dopuszczalne nie istnieje, to STOP. W p. p. przyjmij  i idź do kroku 1.
i idź do kroku 1. - Krok 1. Rozwiąż zadanie zrelaksowane
 , tzn. zadanie D2, w którym występuje jedynie ograniczeń. W wyniku rozwiązaniu zrelaksowanego zadania uzyskujemy optymalną wartość wektora
, tzn. zadanie D2, w którym występuje jedynie ograniczeń. W wyniku rozwiązaniu zrelaksowanego zadania uzyskujemy optymalną wartość wektora  , i wartość funkcji celu będącą wartością oszacowania górnego
, i wartość funkcji celu będącą wartością oszacowania górnego  .
. - Krok 2. Rozwiąż zadanie restrykcyjne podstawiając . W wyniku rozwiązania restrykcji zadania uzyskujemy optymalną wartość wektora zmiennych dualnych
 . Na jego podstawie oraz wartości
. Na jego podstawie oraz wartości  można obliczyć oszacowanie dolne
można obliczyć oszacowanie dolne  w -tej iteracji.
w -tej iteracji. - Krok 3. Jeżeli
 to jest rozwiązaniem optymalnym problemu (P), idź do kroku 4 w celu wyznaczeniu optymalnej wartości x. W p.p. podstaw
to jest rozwiązaniem optymalnym problemu (P), idź do kroku 4 w celu wyznaczeniu optymalnej wartości x. W p.p. podstaw  i idź do kroku 1.
i idź do kroku 1. - Krok 4. Rozwiąż problem przyjmując . STOP.
 iteracjach, gdzie to liczba punktów wierzchołkowych zadania dualnego Bendersa.
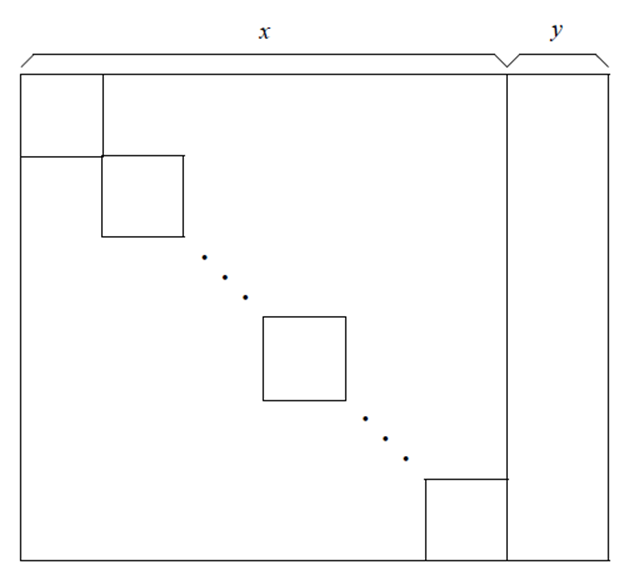
iteracjach, gdzie to liczba punktów wierzchołkowych zadania dualnego Bendersa.Uwaga. Dekompozycja Bendersa może być szczególnie efektywna w przypadku, gdy struktura macierzy ograniczeń jest blokowo-diagonalna z wstęgą pionową, jak pokazano na poniższym rysunku.
Innym przykładem możliwości zastosowania metody dekompozycji Bendersa jest sytuacja, gdy funkcje powiązane ze zmienną
mają szczególną strukturę, np. wynikającą z przepływu w sieciach.