Podręcznik
1. Wprowadzenie do matematyki teorii optymalizacji
1.2. Gładkie zadania optymalizacji
W
punkcie 1.3 Modułu pierwszego wyróżniliśmy gładkie (różniczkowalne) i
niegładkie zadania optymalizacji. Zajmiemy się teraz bliżej własnościami
gładkich zadań optymalizacji.
Najpierw trzeba precyzyjnie ustalić jakie zadania optymalizacji uznajemy za gładkie. Rozważania punktu poprzedniego tego rozdziału, w których posługiwaliśmy się co najwyżej drugimi pochodnymi, sugerują że dwukrotna różniczkowalność wystarczy. Mamy więc definicję.
Zadanie optymalizacji nazywamy gładkim, jeżeli wszystkie funkcje występujące w jego określeniu są klasy \(\mathbf{C}^2\).
Na razie zajmujemy się zadaniami bez ograniczeń, dlatego będziemy się interesować tylko funkcją wyboru f.
Dla funkcji f klasy \(\mathbf{C}^2\) zgodnie z twierdzeniem Taylora mamy
\((∀x ̄,x)f(x)=f(x ̄)+∇f(x ̄)(x-x ̄)+1/2(x-x ̄)^T ∇^2 f(x ̄)(x-x ̄)+ \)
+ nieskończenie mała rzędu 3,gdy \(x-x ̄→0\).
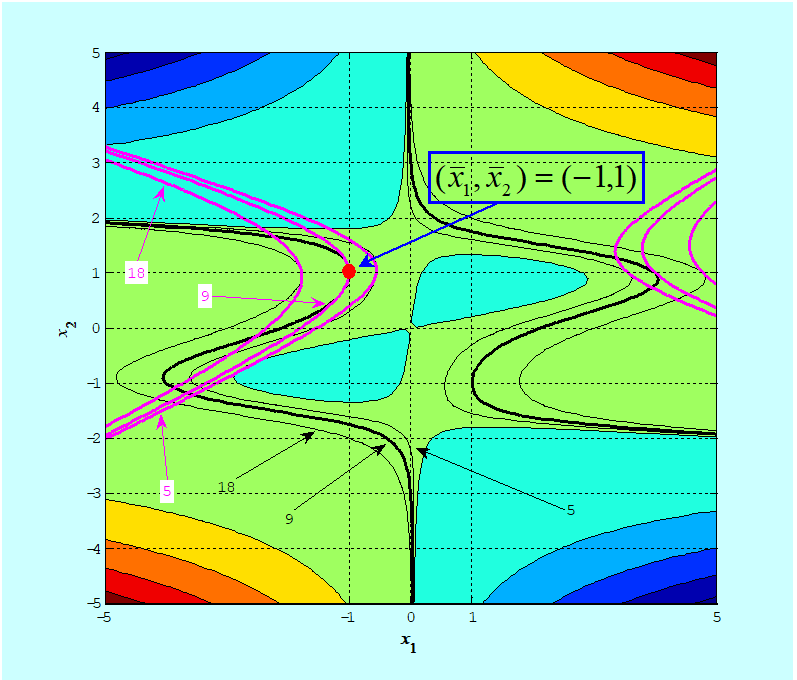
Rozpatrzmy funkcję, której mapę przestawiliśmy w punkcie 1.2.4 Modułu pierwszego, Rys.1.7.
\(=\frac{1}{2}x^T \begin{bmatrix}4 & 2\\2&-22\\\end{bmatrix}x-[-1\,⋮\,1]\begin{bmatrix}4 & 2\\2&-22\\\end{bmatrix}x+[-10\,⋮\,0]x+\)


Rys. 3.13: Aproksymacja: a) trójwymiarowy wykres funkcji f ,
b) trójwymiarowy wykres funkcji aproksymującej f ̃
Podsumujmy nasze dotychczasowe rozważania.
Dla funkcji gładkich (klasy \(\mathbf{C}^2\) ) wzór
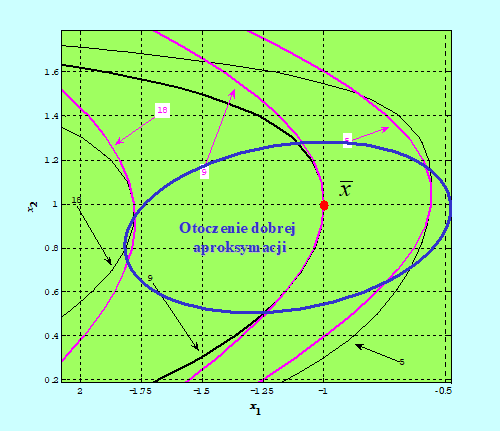
\(x↦\tilde{f} (x;x ̄)=1/2 x^T ∇^2 f(x ̄)x+c^T (x ̄)x+σ(x ̄) \qquad (3.2)\)
- nie daje dobrej aproksymacji funkcji f w całej przestrzeni (nie daje aproksymacji globalnej), natomiast
- istnieje takie otoczenie (konkretne wskazanie go jest bardzo trudne), w którym wzór ten dobrze przybliża tę funkcję – jest dobrą aproksymacją lokalną.
- pesymisty – nie korzystać ze wzoru (3.2),
- optymisty – przyjąć, że otoczenie dobrej aproksymacji to jest na tyle duże, że wykorzystanie gradientu i macierzy Hessego obliczonego w danym punkcie przy konstruowaniu algorytmu zmierzającego do punktu optymalnego nie wyprowadzi na manowce.
Tego rodzaju dylemat jest typowy dla sytuacji, w której znajduje się twórca nowych rozwiązań konstrukcyjnych – magister, a więc mistrz, inżynier – a także twórca nowych teorii naukowych. Za podejściem optymisty opowiedział się Albert Einstein, który w 1921 r. stwierdził, że „Raffiniert ist der Herrgott, aber boshaft ist er nicht”. Co w naszym przypadku przekłada się na przeświadczenie, że nieliniowe zadania optymalizacji związane z rozwiązywaniem zagadnień praktycznych, są takie, że zręczne wykorzystanie możliwości jakie daje posługiwanie się kwadratową aproksymacją (3.2) pozwoli opracować skuteczne algorytmy ich rozwiązywania. Współcześni optymiści mają sławnego poprzednika – Izaaka Newtona, który wymyślił metodę stycznych rozwiązywania równań nieliniowych opartą o jeszcze prostszą aproksymację, bo ograniczoną tylko do składnika afinicznego.