Podręcznik
Warstwa transportowa w modelu TCP/IP pełni kluczową funkcję pośredniczącą między aplikacjami a mechanizmami przesyłu danych w sieci. Jej zadaniem jest zapewnienie sprawnej i niezawodnej komunikacji między procesami działającymi na różnych urządzeniach. Główne protokoły tej warstwy to TCP i UDP. TCP, jako protokół połączeniowy, gwarantuje dostarczenie danych w poprawnej kolejności i bez błędów, realizując mechanizmy kontroli przepływu oraz zarządzania zatorami. UDP natomiast oferuje transmisję bez nawiązywania połączenia, bez kontroli poprawności, co czyni go idealnym dla aplikacji wymagających niskiego opóźnienia, takich jak gry online czy transmisje audio-wideo. Warstwa ta odpowiada również za ustanawianie i zamykanie sesji komunikacyjnych oraz uwzględnia parametry jakości usług (QoS), które są istotne dla różnicowania priorytetów ruchu sieciowego, szczególnie w systemach wymagających niezawodnej i terminowej transmisji danych.
1. Warstwa Transportowa
1.1. Protokoły TCP i UDP
Transport Control Protocol (TCP) oraz User Datagram Protocol (UDP) to dwa główne protokoły warstwy transportowej w modelu TCP/IP, które umożliwiają komunikację pomiędzy aplikacjami działającymi na różnych urządzeniach w sieci. Oba protokoły działają nad warstwą sieciową (najczęściej opartą na IP), ale oferują zupełnie odmienne mechanizmy przesyłania danych, co przekłada się na ich odmienne zastosowania w praktyce.
TCP jest protokołem połączeniowym, co oznacza, że przed wymianą danych musi zostać ustanowione logiczne połączenie pomiędzy nadawcą a odbiorcą. Proces ten nazywany jest trzyetapowym uzgadnianiem połączenia (three-way handshake) i obejmuje wzajemną wymianę pakietów z ustawionymi flagami SYN i ACK. Po zestawieniu połączenia TCP zapewnia gwarancję dostarczenia danych w odpowiedniej kolejności, bez duplikatów i z mechanizmem retransmisji w przypadku zgubienia segmentów. Protokół ten utrzymuje stan połączenia i stale monitoruje jego parametry, takie jak numer sekwencyjny oraz potwierdzenia odbioru. TCP stosuje również mechanizmy kontroli przepływu i zarządzania zatorami, takie jak sliding window czy algorytmy slow start, dzięki czemu potrafi dynamicznie dostosować się do zmiennych warunków w sieci. Każdy segment TCP zawiera rozbudowany nagłówek zawierający m.in. informacje o porcie źródłowym i docelowym, numerze sekwencyjnym, długości danych oraz zestawie flag kontrolnych.
W przeciwieństwie do TCP, protokół UDP jest bezpołączeniowy i nie zapewnia żadnej kontroli nad dostarczaniem danych. Przesyłane pakiety, zwane datagramami, są wysyłane niezależnie od siebie, bez wcześniejszego uzgadniania stanu połączenia i bez mechanizmów potwierdzania odbioru. Odbiorca może otrzymać datagramy w dowolnej kolejności, a niektóre z nich mogą zostać utracone bez powiadomienia nadawcy. Nagłówek UDP jest znacznie prostszy niż w przypadku TCP i składa się jedynie z czterech pól: portu źródłowego, portu docelowego, długości oraz sumy kontrolnej. Dzięki minimalizmowi UDP charakteryzuje się bardzo niskim narzutem i opóźnieniami, co czyni go atrakcyjnym rozwiązaniem w zastosowaniach wymagających dużej szybkości transmisji i tolerancji na utratę danych. Przykładami takich zastosowań są transmisje multimedialne w czasie rzeczywistym, protokoły DNS, VoIP oraz gry online.
Z perspektywy architektury systemów komputerowych TCP i UDP odpowiadają na różne potrzeby aplikacji. TCP wybierany jest tam, gdzie wymagana jest niezawodność, spójność danych i kontrola błędów, natomiast UDP sprawdza się w sytuacjach, gdzie kluczowe są szybkość, prostota i brak narzutu związanego z kontrolą połączenia. Projektanci systemów sieciowych muszą odpowiednio dobrać protokół transportowy do charakterystyki aplikacji, której ma służyć, a sama warstwa transportowa pełni kluczową rolę w zarządzaniu przepływem informacji w nowoczesnych sieciach komputerowych.
Protokół TCP
Protokół TCP (Transmission Control Protocol) jest jednym z podstawowych protokołów warstwy transportowej w modelu TCP/IP. Został zaprojektowany z myślą o zapewnieniu pewnego, uporządkowanego i niezawodnego przesyłania danych między aplikacjami działającymi na różnych hostach. W przeciwieństwie do protokołów bezpołączeniowych, takich jak UDP, TCP jest połączeniowy, co oznacza, że przed rozpoczęciem transmisji danych musi zostać nawiązane logiczne połączenie między nadawcą a odbiorcą.
Protokół TCP zapewnia nawigację strumienia bajtów, co oznacza, że dane są postrzegane jako ciągły ciąg bajtów bez podziału na wiadomości czy pakiety. Każdy bajt jest numerowany, a odbiorca potwierdza odbiór tych bajtów przy pomocy mechanizmu ACK (acknowledgment). Dzięki temu możliwe jest sekwencjonowanie – dane, które dotrą w nieodpowiedniej kolejności, są sortowane u odbiorcy. TCP posiada również mechanizm retransmisji – jeśli odbiorca nie potwierdzi odebrania segmentu w określonym czasie, nadawca ponownie wysyła dane. Dodatkowo stosowane są algorytmy kontroli przepływu (flow control) i zarządzania zatorami (congestion control), dzięki czemu TCP dynamicznie dostosowuje prędkość przesyłu do warunków w sieci.
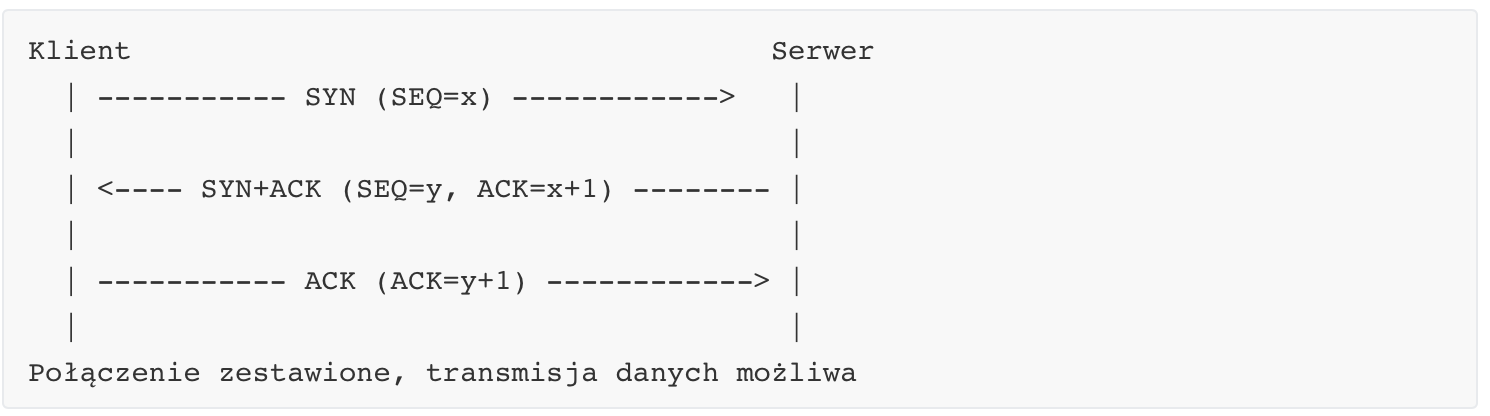
Trójfazowe ustanawianie połączenia (three-way handshake)
Aby rozpocząć komunikację, TCP używa procesu three-way handshake, który obejmuje trzy kroki:

Struktura nagłówka TCP
Nagłówek TCP ma zmienną długość (zazwyczaj 20 bajtów bez opcji), a jego pola zawierają kluczowe informacje sterujące przesyłaniem danych. Poniżej szczegółowe omówienie pól nagłówka:

Opis wybranych pól:
Port źródłowy i docelowy: identyfikują aplikacje końcowe (np. port 80 dla HTTP, port 443 dla HTTPS).
Numer sekwencyjny (SEQ): identyfikuje pierwszy bajt danych w danym segmencie. Pozwala na właściwe ułożenie danych u odbiorcy.
Numer potwierdzenia (ACK): wskazuje numer kolejnego bajtu, którego odbiorca oczekuje (czyli ostatni otrzymany bajt + 1).
Data offset: określa długość nagłówka TCP.
Flagi kontrolne (flags): pojedyncze bity służące do zarządzania połączeniem. Najważniejsze z nich:
SYN: inicjalizacja połączenia.
ACK: potwierdzenie.
FIN: zamknięcie połączenia.
RST: reset połączenia.
PSH: dane mają być natychmiast przekazane aplikacji.
URG: dane pilne.
Rozmiar okna: informuje nadawcę o liczbie bajtów, jakie może jeszcze wysłać bez otrzymania kolejnego potwierdzenia (mechanizm kontroli przepływu).
Suma kontrolna: zapewnia wykrywanie błędów w nagłówku i danych.
Wskaźnik URG: wskazuje, gdzie kończą się dane oznaczone jako pilne.
Opcje TCP: np. okno skalowania, selektywne potwierdzenia (SACK), timestamp – mogą być obecne w nagłówku po podstawowych polach.
TCP jako protokół stanowy przechowuje informacje o aktywnych połączeniach, numerach sekwencyjnych, rozmiarze buforów i czasie życia połączenia. Dzięki temu może zapewniać wysoką jakość transmisji nawet w warunkach niestabilnej sieci.
Kontrola przepływu i zarządzanie zatorami
Sesje i połączenia
Zagadnienia związane z jakością usług (QoS)
Protokół UDP
Protokół UDP (User Datagram Protocol) to jeden z podstawowych protokołów warstwy transportowej w modelu TCP/IP, obok TCP. Jego kluczową cechą jest to, że działa w sposób bezpołączeniowy, co oznacza, że nie ustanawia, nie utrzymuje ani nie kończy połączenia z drugą stroną komunikacji. Z perspektywy systemowej, UDP traktuje przesyłane dane jako oddzielne, niezależne jednostki zwane datagramami. Każdy z nich może być wysłany do odbiorcy bez konieczności uzgadniania jakiegokolwiek stanu połączenia, a nadawca nie otrzymuje informacji, czy dane dotarły, czy zostały zagubione lub odebrane w odpowiedniej kolejności.
UDP zapewnia minimalną funkcjonalność, co czyni go wyjątkowo lekki i szybki. Nie stosuje mechanizmów retransmisji, numeracji pakietów ani buforowania. Odpowiedzialność za ewentualne potwierdzenia dostarczenia, korekcję błędów, czy uporządkowanie danych może być przeniesiona na warstwę aplikacji. Dzięki temu UDP ma bardzo niskie opóźnienia transmisji (latencję), co jest kluczowe w zastosowaniach takich jak transmisja głosu (VoIP), strumieniowanie wideo w czasie rzeczywistym, gry sieciowe, DNS czy NTP, gdzie ważniejsza od niezawodności bywa szybkość.
Struktura nagłówka UDP
Nagłówek UDP ma stałą długość 8 bajtów, co czyni go niezwykle prostym w porównaniu do TCP. Składa się z czterech pól, z których każde ma długość 16 bitów (2 bajty):


Opis pól nagłówka UDP:
Port źródłowy (Source Port): identyfikuje aplikację po stronie nadawcy. Jest to pole opcjonalne – może być ustawione na zero, jeśli port nie jest istotny.
Port docelowy (Destination Port): wskazuje, do której aplikacji na hoście docelowym datagram ma trafić. To pole jest obowiązkowe.
Długość (Length): określa całkowitą długość datagramu UDP, czyli długość nagłówka (zawsze 8 bajtów) plus długość danych.
Suma kontrolna (Checksum): pole służące do wykrywania błędów w przesyłanych danych. W IPv4 jest opcjonalna, ale w IPv6 jej stosowanie jest obowiązkowe. Suma kontrolna obejmuje pseudo-nagłówek (pochodzący z warstwy IP), nagłówek UDP oraz dane. Ma to na celu lepsze wykrywanie błędów spowodowanych np. przez błędne adresowanie.
Przykład przesyłania datagramu UDP
Dzięki swojej prostocie, przesyłanie informacji za pomocą UDP odbywa się bezpośrednio i bez udziału procedur ustalających połączenie:

Nie istnieje żaden mechanizm odpowiedzi, potwierdzenia ani ponownej transmisji. Odbiorca może, ale nie musi, w ogóle odebrać datagram. Może on zostać utracony, zduplikowany, przybyć w niewłaściwej kolejności lub być uszkodzony.
Zaletą UDP jest jego wydajność. Dzięki pominięciu wielu mechanizmów kontrolnych UDP zużywa mniej zasobów systemowych i sieciowych, co jest istotne w środowiskach o ograniczonej przepustowości lub w zastosowaniach czasu rzeczywistego. Jednocześnie jednak wymaga od aplikacji, by same zapewniały potrzebną niezawodność, jeśli jest ona konieczna, np. poprzez ponowne wysyłanie wiadomości czy potwierdzenia na poziomie logiki aplikacji.
W praktyce UDP jest często stosowany tam, gdzie utrata pojedynczych pakietów jest mniej krytyczna niż opóźnienia, oraz tam, gdzie dane są przesyłane cyklicznie lub okresowo, a ciągłość ma większe znaczenie niż integralność całości przesyłu.
Porównanie protokołów
TCP (Transmission Control Protocol) i UDP (User Datagram Protocol) to dwa podstawowe protokoły warstwy transportowej w modelu TCP/IP, które służą do przesyłania danych między aplikacjami działającymi na różnych hostach sieciowych. Pomimo że pełnią tę samą ogólną funkcję, działają według zupełnie innych zasad i są przeznaczone do różnych typów zastosowań.
TCP to protokół połączeniowy i stanowy. Oznacza to, że przed przesłaniem danych między dwoma urządzeniami musi zostać nawiązane połączenie za pomocą procedury „three-way handshake”. TCP zapewnia szereg mechanizmów zwiększających niezawodność transmisji, takich jak numeracja bajtów, potwierdzanie odbioru (ACK), retransmisje zgubionych pakietów, kontrola przepływu (flow control) oraz zarządzanie zatorami (congestion control). Każdy segment TCP niesie nie tylko dane użytkownika, ale także dodatkowe informacje kontrolne, takie jak numery sekwencyjne, potwierdzenia oraz flagi, które określają stan połączenia.
UDP, w odróżnieniu od TCP, działa w trybie bezpołączeniowym i bezstanowym. Nie wymaga uprzedniego zestawienia połączenia ani nie utrzymuje informacji o stanie komunikacji. Datagramy UDP są wysyłane natychmiast, bez gwarancji dostarczenia, bez potwierdzeń i bez retransmisji. To znacząco zmniejsza narzut czasowy i systemowy, umożliwiając szybką transmisję danych w czasie rzeczywistym, ale kosztem braku niezawodności. Odpowiedzialność za ewentualną naprawę błędów lub potwierdzenia spoczywa na aplikacji.
Przykłady zastosowań protokołów TCP oraz UDP
Protokół TCP (Transmission Control Protocol) znajduje zastosowanie wszędzie tam, gdzie konieczne jest zapewnienie pełności, integralności i kolejności danych. TCP nie tylko umożliwia przesłanie pakietów, ale zapewnia także pełną kontrolę nad sesją: od rozpoczęcia po jej zamknięcie. W kontekście aplikacji sieciowych oznacza to, że klient wie, czy dane dotarły, a serwer – że zostały odebrane.
Jednym z najbardziej powszechnych zastosowań TCP jest protokół HTTP, wykorzystywany przez przeglądarki do pobierania stron WWW. Gdy użytkownik wpisuje adres strony, przeglądarka otwiera połączenie TCP z serwerem na porcie 80 (dla HTTP) lub 443 (dla HTTPS). Proces ten zaczyna się od trójfazowego handshake’u (SYN, SYN-ACK, ACK), który synchronizuje sekwencje numerów i umożliwia pełne zestawienie sesji.
Po zestawieniu połączenia klient wysyła zapytanie HTTP (np. GET /index.html), a serwer odpowiada odpowiednim zasobem. Dzięki mechanizmowi okna przesuwnego TCP może kontrolować tempo transmisji, by nie przeciążyć odbiorcy. W razie utraty pakietu TCP wykorzystuje retransmisję oraz numerację sekwencyjną, co zapewnia odbudowanie danych w poprawnej kolejności.
Dla protokołu HTTPS cały ten proces zachodzi wewnątrz bezpiecznego kanału TLS, który sam działa na TCP, wykorzystując jego cechy do zapewnienia bezpiecznej i spójnej transmisji. Nawet najmniejsze odchylenia lub zakłócenia są wykrywane i korygowane, zanim dane dotrą do aplikacji.
Podobnie sytuacja wygląda w przypadku protokołu FTP. Choć jego struktura zakłada dwa połączenia TCP – jedno do sterowania, drugie do danych – zasada pozostaje ta sama: dane muszą zostać przesłane w sposób niezawodny. Klient łączy się z serwerem na porcie 21, ustala parametry sesji, a następnie otwiera połączenie danych, np. na porcie 20. W ten sposób może przesłać plik binarny lub tekstowy bez ryzyka jego uszkodzenia. Mechanizmy TCP dbają, by każde z wysłanych segmentów dotarło i było złożone we właściwej kolejności.
Innym klasycznym przypadkiem wykorzystania TCP jest SSH (Secure Shell). Zapewnia on szyfrowany dostęp do powłoki systemowej zdalnego komputera. Każdy znak, który wpisuje użytkownik, przechodzi przez kanał TCP, a serwer odpowiada znakiem wyjściowym. Gdyby choć jeden segment zniknął lub dotarł w niewłaściwej kolejności, mogłoby to skutkować błędną interpretacją polecenia. TCP eliminuje to ryzyko.
W przeciwieństwie do TCP, UDP (User Datagram Protocol) nie zestawia połączenia ani nie utrzymuje sesji. Każdy pakiet (datagram) jest wysyłany niezależnie, bez gwarancji dostarczenia. To nie wada, ale cecha, pozwalająca osiągnąć ekstremalnie niskie opóźnienia. W aplikacjach czasu rzeczywistego, takich jak VoIP, streaming czy gry online, ważniejsza od kompletności danych jest ich szybkość.
DNS (Domain Name System) to przykład aplikacji wykorzystującej UDP. Gdy przeglądarka potrzebuje przetłumaczyć adres domenowy na IP, wysyła zapytanie UDP do serwera DNS. Ponieważ zapytania są krótkie i często powtarzalne, retransmisje są zbędne. W razie braku odpowiedzi klient po prostu ponawia zapytanie.
VoIP (Voice over IP) wykorzystuje UDP do przesyłania dźwięku. Przykładowo, aplikacja telefoniczna na smartfonie generuje pakiety audio co 20 ms i wysyła je do odbiorcy. Jeśli którykolwiek z nich się zgubi – nie jest retransmitowany. Próbka dźwięku jest po prostu pomijana. Retransmisja zajęłaby zbyt wiele czasu i pogorszyłaby jakość rozmowy.
Wideo streaming – np. przez protokół RTP (Real-time Transport Protocol) – także korzysta z UDP. Każda klatka wideo lub pakiet dźwięku trafia do odbiorcy bez pośrednictwa stanu połączenia. Jeżeli kilka ramek zostanie utraconych – odbiornik kontynuuje odtwarzanie na podstawie bufora i interpolacji.
W grach online UDP służy do przekazywania pozycji gracza, akcji, kolizji. Pakiety są wysyłane np. co 30–60 ms i zawierają stan gry. Serwer nie potwierdza ich odbioru. Silnik gry zakłada, że jeśli pakiet nie dotarł – można go pominąć lub przewidzieć jego wartość. To pozwala zachować niską latencję i płynność.
Choć UDP często kojarzony jest z transmisją o niskiej niezawodności, istnieją sytuacje, gdzie aplikacje tworzą nad nim własne mechanizmy retransmisji lub korekcji błędów. Dobrym przykładem jest QUIC, nowoczesny protokół wykorzystywany przez Google, który działa nad UDP i zapewnia funkcjonalność podobną do TCP: utrzymywanie połączenia, retransmisję, zarządzanie przeciążeniami. QUIC pozwala ominąć niektóre ograniczenia TCP – np. związaną z nim blokadę „head-of-line”, czyli sytuację, gdy brak jednego segmentu wstrzymuje dalsze przetwarzanie.
Z punktu widzenia warstwy OSI, TCP i UDP operują w tej samej – czwartej – warstwie transportowej, ale ich cechy funkcjonalne są skrajnie różne. TCP to protokół stanowy – utrzymuje informacje o numerach sekwencyjnych, czasie ostatniego potwierdzenia, stanie okna odbiorczego. Wymaga to więcej zasobów po stronie serwera, szczególnie przy tysiącach jednoczesnych połączeń.Każda sesja to osobna struktura z danymi o stanie. Dla porównania, UDP nie tworzy żadnej sesji – po odebraniu datagramu po prostu przekazuje go wyżej, niezależnie od tego, czy coś wcześniej było przesłane z danego źródła.
W praktyce często dochodzi do sytuacji, w których protokół domyślnie używa UDP, ale ma możliwość „przełączenia się” na TCP. Dotyczy to choćby DNS, który w razie odpowiedzi większej niż 512 bajtów automatycznie przełącza się na TCP. Zjawisko to określane jest jako fallback.
W dzisiejszych sieciach TCP i UDP nie rywalizują – raczej uzupełniają się. Dla przesyłania dużych plików, długich zapytań REST API, synchronizacji baz danych lub strumieni mediów wysokiej jakości z buforowaniem – TCP będzie wyborem naturalnym. Dla transmisji szybkiej, rozgłoszeniowej, zorientowanej na niskie opóźnienia, ale nie pełną niezawodność – UDP będzie protokołem bardziej odpowiednim.
Dobrym przykładem są serwery gier online. Dane kontrolne i logowania często przesyłane są przez TCP – zapewnia to ich pełność, poprawność i bezpieczeństwo. Dane o pozycji gracza, kolizjach, obrażeniach itp. – przez UDP – umożliwia to działanie z niskim opóźnieniem.
W protokole SSH istotne jest nie tylko to, że korzysta z TCP, ale też w jaki sposób zarządza danymi. Wpisanie znaku przez użytkownika powoduje wysłanie bajtu TCP – a każda operacja ma gwarancję odbioru. To kluczowe przy sterowaniu urządzeniami sieciowymi czy zdalnej administracji.
W przeciwieństwie do tego, komunikacja w stylu multicast (np. protokoły discovery, serwisy IPTV) zwykle oparta jest o UDP. TCP nie obsługuje multicastu. Dlatego transmisje grupowe – np. IPTV – wymagają UDP.
Innym zastosowaniem są systemy monitoringu – kamery IP przesyłają obraz przez UDP/RTP do odbiorników. Retransmisja klatek wideo mijałaby się z celem – ważniejsze, by strumień był ciągły, nawet jeśli kilka ramek zginie.
Aplikacje mobilne (np. komunikatory typu WhatsApp, Signal) często używają UDP do połączeń głosowych i TCP do wiadomości tekstowych. Ich logika zawiera zarówno wymóg niskiej latencji (głos), jak i niezawodności (tekst, multimedia). Pod spodem UDP wykorzystywany jest także do NAT traversal (np. STUN, TURN, ICE) – czyli umożliwienia połączeń między urządzeniami ukrytymi za NAT-em.
W systemach chmurowych, przy integracjach systemów mikroserwisowych, preferowane są połączenia TCP (np. HTTP/REST over TCP, gRPC). Niemniej, dla strumieni audio/wideo czy telemetryki z sensorów – UDP (np. z MQTT lub własnymi frame'ami) jest często lepszym wyborem.
Zastosowania w IoT również są interesujące: wiele sensorów wysyła dane z częstotliwością co kilka sekund – datagram UDP wystarczy, nie trzeba utrzymywać połączenia TCP. Jeśli jeden pakiet zaginie – dane przyjdą za 10 sekund i system nadal będzie działać poprawnie. W takiej architekturze minimalizacja zużycia energii (zwłaszcza w LoRaWAN, NB-IoT) jest kluczowa – a krótkie datagramy UDP idealnie się wpisują.
Na koniec warto wspomnieć, że mimo prostoty UDP, wiele firm stosuje mechanizmy application-layer reliability – własne potwierdzenia, okna, numery sekwencyjne, retransmisje. TCP je zawiera natywnie, ale nie zawsze wystarczy: stąd QUIC, SCTP, lub dostosowane UDP dla specjalnych potrzeb.