Podręcznik
3. Dziedziczenie i polimorfizm
3.1. Dziedziczenie
Jednym z głównych powodów, dla których obiektowe techniki programowania zyskały taką popularność, jest znaczący postęp w kwestii ponownego wykorzystania kodu oraz możliwość jego rozszerzania i dostosowania do indywidualnych potrzeb. Ta cecha leży u samych podstaw programowania zorientowanego obiektowo: program konstruowany jako zbiór współdziałających obiektów przestaje być pojedynczą całością, gdzie dane są ściśle powiązane z operacjami na nich wykonywanymi (jeden z pierwszych szeroko znanych podręczników IT miał tytuł "Algorytmy + struktury danych = programy" ;). Współcześnie dążymy do czegoś innego - program wewnętrznie powinien mieć jak najmniej powiązań o możliwie najlepiej zaprojektowanej semantyce. Staramy się wyodrębniać podsystemy i biblioteki do ponownego wykorzystania w kolejnych projektach. To ułatwia i przyspiesza tworzenie nowych aplikacji.
Sporo tu zależy od umiejętności i doświadczenia programisty - programowanie zorientowane obiektowo nie sprawi, że napisany przy jego użyciu program nie będzie miał wewnętrznych zależności na tyle silnych, iż nie będzie możliwości ponownego wykorzystania jego kodu w innym projekcie.
Elementem, który ułatwia podział odpowiedzialności, jasne definiowanie interfejsów między klasami, czy też dostosowywanie jednego kodu do wielu zastosowań - jest dziedziczenie. Korzyści płynące z jego stosowania nie ograniczają się jednakże tylko do powtórnego wykorzystania istniejącego kodu. - jest ich znacznie więcej. Jeśli dodamy do dziedziczenia polimorfizm - pojawią się nowe możliwości, niezmiernie przydatne przy tworzeniu każdej niebanalnej aplikacji.
Czymże jest więc owo dziedziczenie?
Nasz świat opisujemy stosując różnego rodzaju schematy, ontologie, metodyki. Spośród nich - podejście oparte na hierarchii jest chyba najpopularniejsze i najczęściej spotykane. Wyraźnie to widać w różnych naukach - biologia zbudowała całe wielkie drzewo klasyfikujące wszystkie organizmy żywe. Co ciekawe i charakterystyczne w tym drzewie - to fakt, iż relację łączącą jego elementy określa słowo "jest". Człowiek jest naczelnym, i jest ssakiem, i jest zwierzęciem, i jest organizmem żywym. VW Golf jest samochodem osobowym, a samochód osobowy jest pojazdem, i takich przykładów można podać wiele. Co charakterystyczne - na każdym z poziomów opisu (abstrakcji) możemy wydzielić wspólne cechy i funkcjonalność (wszystkie ssaki są żyworodne i stałocieplne, i w początkowym okresie życia żywią się mlekiem matki - i jest to prawda niezależnie od tego czy mówimy o myszy, słoniu czy człowieku).
Tyle ze w obiektowym podejściu do programowania pojawia nam się problem - jak przygotować taką klasę, która opisze np lwa? Jeśli będzie to tylko jedna klasa - to wszystkie cechy muszą się w niej znaleźć. Jeśli będziemy tylko lwem się zajmowali - to jest rozwiązanie ok. Lecz wprowadzając do programu następne pojęcie - powiedzmy pawiana - jak powinniśmy postąpić? Powtórzyć całość opisu? Przecież większość cech jest wspólna dla wszystkich ssaków - w tym i dla lwa, i dla pawiana. To może warto utworzyć klasę zwierzę gdzie wrzucę te cechy wspólne? Tylko potem nie bardzo wiadomo jak utworzyć obiekt z takiej klasy - musiałby on być tworzony na podstawie dwóch klas - dwóch przepisów. Programowanie obiektowe nie dopuszcza tego - nie może być typ który jest jednocześnie liczbą całkowitą i zmiennoprzecinkową. Pewnym rozwiązaniem jest kompozycja - ale ona nie oddaje w pełni związku który istnieje w realnym świecie. Pawian nie "ma" zwierzę lecz po prostu jest zwierzęciem - jest to część jego tożsamości, a zwierzę w nim - nie ma jej oddzielnej.
I tu rozwiązaniem będzie dziedziczenie.
Za każdym razem definiując klasę pochodną, definiujemy tylko to czym ona się różni od klasy bazowej - człowiek to jest takie zwierzę, które potrafi mówić, czy używać narzędzi, i ma iloraz inteligencji.
Dziedziczenie to główny mechanizm wyróżniający programowanie zorientowane obiektowo od programowania obiektowego. Opieramy się na cechach wspólnych grupy klas – zarówno jeśli chodzi o pola jak i metody. Wspólne cechy lądują w klasie bazowej, cechy szczególne – w klasach pochodnych.
Popatrzmy na pierwszy przykład:
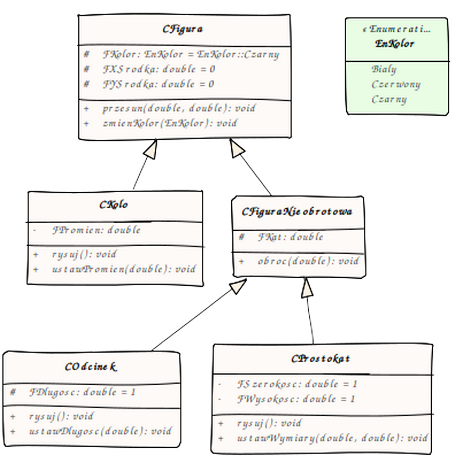
Pokazany powyżej diagram pokazuje nam hierarchię dziedziczenia dla figur. Mamy prostokąt, który jest taką figurą nieobrotową, która ma szerokość i wysokość. Tyle że z faktu, iż jest figurą nieobrotową - wynika to że ma także kont obrotu. A ponieważ figura nieobrotowa jest figurą (dziedziczy po figurze) - to prostokąt ma także jej cechy, w tym kolor czy położenie środka.
W dziedziczeniu istotny jest fakt, iż klasy pochodne jednak powinny różnić się czymś - albo polami, albo zachowaniem - od klasy podstawowej. Złym przykładem dziedziczenia jest klasa "Żółty prostokąt" - bo od prostokąta różni się jedynie wartością koloru - więc stanem. I tworząc obiekt prostokąt możemy polu kolor przypisać wartość żółty - nie musimy do tego definiować klasy. Co gorsza - prostokąt można by było "przemalować" na inny kolor - ale jak powstanie już konkretny obiekt - to w C++ nie da się zmienić klasy z której powstał.
Jeśli natomiast prawidłowo zdefiniujecie hierarchę - to można nie tylko ograniczyć ilość kodu (wyeliminować powtarzające się fragmenty dla różnych klas) - ale także korzystać z różnych typów na ich poziomie abstrakcji. Możemy mieć funkcję która przesuwa figurę o zadany wektor - i do tego nie jest potrzebna wiedza odnośnie tego czy jest to koło, czy prostokąt, czy figura ma promień czy wysokość - każdą figurę można przesunąć, vide- funkcja mogłaby przyjmować jako parametr wskaźnik / referencję na obiekt klasy CFigura.
W C++ mechanizm dziedziczenia jest niezwykle rozbudowany, przewyższając często możliwości dziedziczenia w innych językach wspierających programowanie zorientowane obiektowo. Zapewnia on wiele zaawansowanych funkcji, które mogą być nie zawsze niezbędne, ale pozwalają na dużą elastyczność w definiowaniu hierarchii klas. Znajomość wszystkich tych możliwości nie jest konieczna do efektywnego korzystania z programowania obiektowego - lecz na pewno nie przeszkodzi. W sumie, jak mawiają, dodatkowa wiedza jeszcze nikomu nie zaszkodziła! 😊
Zacznijmy zatem przegląd możliwości od postaw:
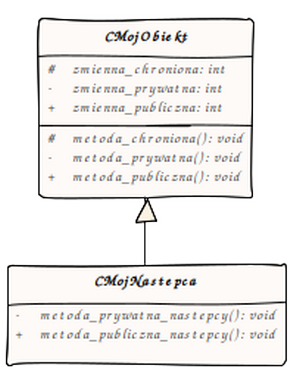
Zasady dostępu do pól i metod w hierarchii
Jak pamiętamy, deklarując klasę podajemy listę jej pól oraz metod, podzielonych na kilka części wedle specyfikatorów praw dostępu. W przypadku dziedziczenia pojawia się nowe określenie – protected. Same zasady dostępu wyglądają następująco:
- Pola prywatne pozostają prywatne
- Pola publiczne nadal są publiczne
- Pola chronione – dostępne dla danej klasy i wszystkich klas pochodnych – dla reszty nie.
- Obowiązują reguły przykrywania nazw
- Nie obowiązują zasady przeciążania nazw funkcji w dziedziczeniu!
Możecie to zobaczyć na poniższym przykładzie:
class CMojObiekt {
public:
int zmienna_publiczna;
void metoda_publiczna();
protected:
int zmienna_chroniona;
void metoda_chroniona();
private:
int zmienna_prywatna;
void metoda_prywatna();
};
class CMojNastepca : public CMojObiekt {
public:
...
void metoda_publiczna_nastepcy();
protected:
...
private:
void metoda_prywatna_nastepcy;
};
void CMojNastepca::metoda_prywatna_nastepcy {
// tak mozna
zmienna_chroniona = 1;
metoda_chroniona();
// tak natomiast nie da rady
zmienna_prywatna = 1;
metoda_prywatna();
};
void CMojObiekt::metoda_publiczna_nastepcy {
// tak mozna
zmienna_chroniona = 1;
metoda_chroniona();
// tak natomiast nie da rady
zmienna_prywatna = 1;
metoda_prywatna();
};
CMojNastepca mn;
...
// ponizszy kod jest nieprawidłowy
mn.zmienna_chroniona = 1;
mn.metoda_chroniona();
Należy używać specyfikatora protected , kiedy chcemy uchronić składowe przed dostępem z zewnątrz, ale jednocześnie mieć je do dyspozycji w klasach pochodnych. Przy czym nie nadużywajcie tego dostępu , wspomniana wcześniej zasada hermetyzacji ciągle obowiązuje. Preferowaną sekcją dla pól zawsze powinna być sekcja private - a umieszczanie pól w sekcji protected powinno mieć jakieś uzasadnienie.
Dopiero posiadając zdefiniowaną klasę bazową możemy przystąpić do określania dziedziczącej z niej klasy pochodnej. Jest to konieczne, bo w przeciwnym wypadku kazalibyśmy kompilatorowi korzystać z czegoś, o czym nie miałby wystarczających informacji.
Samo dziedziczenie może być wykonane wg trzech różnych schematów. Tak więc mamy dziedziczenie:
- Publiczne - Wszystkie odziedziczone pola i metody mają taki zasięg jak zdefiniowano w klasie bazowej. Klasa pochodna i jej pochodne mają dostęp do części chronionej i publicznej, korzystający z obiektów pochodnych mają dostęp do części publicznej.
- Chronione - Odziedziczone pola i metody publiczne i chronione stają się chronione w klasie pochodnej i jej pochodnych. Klasa pochodna i jej pochodne mają dostęp do części chronionej i publicznej, korzystający z obiektów pochodnych nie mają dostępu do żadnych pól i metod klasy bazowej.
- Prywatne - Odziedziczone pola i metody publiczne i chronione stają się prywatne w klasie pochodne. Klasa pochodna ma do nich dostęp, klasy wyprowadzone z pochodnej, oraz korzystający z obiektów pochodnych nie mają dostępu do żadnych pól i metod klasy bazowej. Dziedziczenie prywatne przerywa w zasadzie hierarchię dziedziczenia.
Najczęściej stosowane jest dziedziczenie publiczne -ponieważ w większości przypadków nie ma potrzeby zmiany praw dostępu do składowych odziedziczonych po klasie bazowej. Jeżeli więc któreś z nich zostały tam zadeklarowane jako protected , a inne jako public , to prawie zawsze życzymy sobie, aby w klasie pochodnej zachowały te same prawa. Pozostałe dwa kwalifikatory są stosunkowo rzadko stosowane.
class CMojObiekt {
public:
int zmienna_publiczna;
void metoda_publiczna();
protected:
int zmienna_chroniona;
void metoda_chroniona();
private:
int zmienna_prywatna;
void metoda_prywatna();
};
class CMojNastepca : public CMojObiekt {
public:
...
void metoda_publiczna_nastepcy();
protected:
...
private:
void metoda_prywatna_nastepcy();
};
void CMojNastepca::metoda_prywatna_nastepcy {
// tak mozna
zmienna_chroniona = 1;
metoda_chroniona();
// tak natomiast nie da rady
zmienna_prywatna = 1;
metoda_prywatna();
};
void CMojObiekt::metoda_publiczna_nastepcy {
// tak mozna
zmienna_chroniona = 1;
metoda_chroniona();
// tak natomiast nie da rady
zmienna_prywatna = 1;
metoda_prywatna();
};
CMojNastepca mn;
...
// ponizszy kod jest nieprawid³owy
mn.zmienna_chroniona = 1;
mn.metoda_chroniona();
W przypadku dziedziczenia mamy do dyspozycji ten sam mechanizm co w przypadku przestrzeni nazw - czyli przesłanianie. Jeśli w kodzie klasy pochodnej zdefiniujemy pola o tych samych nazwach co już istniejące pola w klasie bazowej - to nie jest błąd. To co się stanie - to stracimy bezpośredni dostęp od pola odziedziczonego (o ile go w ogóle mieliśmy), w to miejsce uzyskując dostęp do nowego pola. Ilustruje to poniższy przykład:
class CBaza {
public:
CBaza() : a(0), b(0), c(0) {};
int a;
void fa() {cout <<"Baza fa: "<< a <<" "<< b <<" "<< c << endl; }
void fb() {cout <<"Baza fb\n";}
protected:
int b;
private:
int c;
};
class CPoch : public CBaza {
public:
CPoch() : a(1), c(1) {};
int a, c;
void fa() {cout <<"Poch fa: "<< a <<" "<< b <<" "<< c << endl; }
void fb(int i) {cout <<"Poch fb\n";}
void fc() { CBaza::fa(); }
};
int main(int argc, char *argv[])
{
CPoch t;
t.fa();
// t.fb();
t.fb(0);
t.fc();
return EXIT_SUCCESS;
}
Dziedziczenie wielokrotne
Skoro możliwe jest dziedziczenie z wykorzystaniem jednej klasy bazowej, to raczej naturalne jest rozszerzenie tego zjawiska także na przypadki, w której z kilku klas bazowych tworzymy jedną klasę pochodną.
Niestety - wiąże się to z problemem, który może się pojawić - tzw problemem diamentu. Problem diamentu dotyczy głównie konfliktów związanych z polami klas bazowych. Przyjrzyjmy się przykładowi, w którym problem diamentu występuje w kontekście pól:
#include "iostream"
class A {
public:
int value;
A() : value(0) {}
};
class B : public A {
public:
// Dziedziczy pole value z klasy A
};
class C : public A {
public:
// Dziedziczy pole value z klasy A
};
class D : public B, public C {
public:
// Dziedziczy pole value z klas B i C, ale także ma własne pole value
};
int main() {
D d;
// Konflikt, ponieważ D dziedziczy pole value z B i C
// d.value = 10; // To spowoduje błąd kompilacji
// Musimy jawnie określić, z której klasy dziedziczone jest pole value
d.B::value = 5;
d.C::value = 7;
// Wartość pola value w klasie D
std::cout << "D.value: " << d.value << std::endl;
return 0;
}
W tym przykładzie klasa `D` dziedziczy zarówno po klasie `B`, jak i `C`, a obie te klasy dziedziczą po klasie `A`. Problem pojawia się, gdy chcemy korzystać z pola value w klasie `D`, ponieważ istnieją dwie kopie tego pola (jedna z klasy `B`, druga z klasy `C`), co powoduje konflikt nazw. A nawet nie tylko konflikt nazw - zazwyczaj w ogóle nie chcemy by klasa `D` Zawierała dwie kopie pól klasy `A`
Aby rozwiązać ten problem, możemy jawnie określić, z której klasy dziedziczone są pola value, używając operatora zakresu. Jednakże, w przypadku bardziej złożonych hierarchii dziedziczenia, zarządzanie takimi konfliktami może stać się bardziej skomplikowane. Wirtualne dziedziczenie może być jednym ze sposobów radzenia sobie z problemem diamentu w kontekście pól.
Ze względu na ten problem zazwyczaj unika się udostępniania wielodziedziczenia, wprowadzając w to miejsce koncepcję interfejsu - czyli w uproszeniu - klasy która nie ma pól, a wszystkie jej metody są czysto wirtualne Jak nie ma pól - nie ma problemu ... Ale C++ jest jednym z niewielu języków, które udostępniają wielodziedziczenie. Nie świadczy to jednak o jego niebotycznej wyższości nad innymi. Tak naprawdę technika dziedziczenia wielokrotnego nie daje żadnych nadzwyczajnych korzyści, a jej użycie jest przy tym dość skomplikowane. Decydując się na jej wykorzystanie należy więc posiadać całkiem spore doświadczenie w programowaniu, choć w niektórych wzorcach programistycznych jej stosowanie jest wskazane.
Może jeszcze przykład bardziej "źyciowy" - mamy pojazd, po którym dziedziczy samochód i łódka, no i chcemy wyprowadzić klasę amfibia

No i pytanie - jaką prędkość ma amfibia? Problem można rozwiązać korzystając z wirtualnego dziedziczenia:
class CPojazd {
public:
CPojazd() {}
protected:
int m_vMax{200};
};
class CSamochod : virtual public CPojazd {
protected:
int m_iloscKol{4};
};
class CLodz : virtual public CPojazd {
protected:
int m_wypornosc{50};
};
class CAmfibia: public CSamochod, public CLodz {
public:
void jedziemy() {
std::cout << "Zasuwam z prędkością " << m_vMax;
}
};
Teraz jest tylko jedno pole m_vMax. Jest jeszcze problem związany z niejednoznacznością inicjacji tego odziedziczonego pola. Załóżmy że mamy konstruktor, który wymaga podania parametru - pytanie, która wersja tego konstruktora będzie wywołana w klasie CAmfibia?
class CPojazd {
public:
CPojazd(int v) : m_vMax(v) {}
protected:
int m_vMax;
};
class CSamochod : virtual public CPojazd {
public:
CSamochod() : CPojazd(200) {}
protected:
int m_iloscKol{4};
};
class CLodz : virtual public CPojazd {
public:
CLodz() : CPojazd(50) {}
protected:
int m_wypornosc{50};
};
class CAmfibia: public CSamochod, public CLodz {
public:
void jedziemy() {
// 200 czy 50?
std::cout << "Zasuwam z prędkością " << m_vMax;
}
};
Ciężko powiedzieć ... a skoro ciężko powiedzieć - to kompilator się podda i oznajmi że w kodzie jest błąd. Należy jawnie pokazać, którą wersję konstruktora klasy bazowej należy wykorzystać:
class CAmfibia: public CSamochod, public CLodz {
public:
CAmfibia() : CPojazd(150) {}
void jedziemy() {
// moje własne - 150
std::cout << "Zasuwam z prędkością " << m_vMax;
}
};
Pułapki dziedziczenia
Pomimo że idea dziedziczenia może wydawać się prosta, w praktyce jej zastosowanie może przynieść pewne trudności. Problemy te są często specyficzne dla konkretnego języka programowania - w naszym podręczniku skupimy się na aspektach związanych z dziedziczeniem w języku C++. Przykłady takich problemów obejmują m.in. zarządzanie pamięcią dla obiektów dziedziczących, rozstrzyganie konfliktów nazw i przysłanianie / polimorfizm (o którym w następnym rozdziale), czy mechanizm wielokrotnego dziedziczenia (omówiony wyżej).
Napisałem wcześniej, że klasa pochodna ma wszystkie składowe klasy z której dziedziczy. W zasadzie jest to prawda, nie wpadnijcie w pułapkę części prywatnej!. To, że klasie pochodnej tracimy dostęp do pewnych pól i metod - wcale nie oznacza że ich nie ma. Oznacza jedynie, że tracimy dostęp. Jeśli pole prywatne ma getter - to możemy jego wartość odczytać poprzez wywołanie gettera. Podobnie pośrednio możemy wywoływać metody prywatne - jeśli skorzystamy z tych metod w klasie bazowej, które prywatne nie są, ale w swojej implementacji wywołują metody prywatne.
Sposób, w jaki C++ realizuje pomysł dziedziczenia, jest sam w sobie dosyć interesujący. Większość programistów na początku całkiem logicznie przypuszcza, że kompilator tworząc obiekt i mapując jego metody, zwyczajnie pobiera deklaracje z klasy bazowej i wstawia je do pochodnej, ewentualne powtórzenia rozwiązując na korzyść tej drugiej.
W rzeczywistości wewnętrznie używana przez kompilator definicja klasy pochodnej jest identyczna z tą, którą wpisujemy do kodu; nie zawiera żadnych pól i metod pochodzących z klas bazowych. Sztuczka polega na budowaniu z klocków - podczas tworzenia obiektu klasy pochodnej tworzony jest także obiektu klasy bazowej - i łączony z obiektem pochodnym. Mają tą samą tożsamość, lecz tworzone są etapami.
W C++ obowiązuje zasada, iż najpierw wywoływany jest konstruktor klasy najwyższej w hierarchii, a potem następne, zgodnie z kolejnością dziedziczenia. Dlatego sam proces budowy obiektu jest wieloetapowy, i po drodze występuje wiele wywołań różnych konstruktorów. To dodatkowo pokazuje, że konstruktor jest specyficzną metodą - nie może być wirtualny, i nie działają na nim mechanizmy przysłaniania.