Podręcznik
Podstawowym pojęciem inżynierii wymagań jest oczywiście „wymaganie”. Wymaganie to jako własność produktu końcowego (systemu oprogramowania), którą musi on posiadać, aby spełnić oczekiwania zamawiającego. Mówi się, że system spełnia wymagania, jeśli zostało potwierdzone, że posiada wszystkie własności określone tymi wymaganiami.
Na tej podstawie możemy również określić, czym jest inżynieria wymagań. Jest to dyscyplina inżynierii oprogramowania, która obejmuje działania polegające na zbieraniu, analizowaniu, negocjowaniu i specyfikowaniu (zapisywaniu) wymagań. Głównym produktem tej dyscypliny jest specyfikacja wymagań, która jest podstawą efektywnego kosztowo wytworzenia systemu oprogramowania zgodnego z oczekiwaniami zamawiającego.
4. Podstawy projektowania podsystemów
4.1. Projektowanie warstw prezentacji i logiki aplikacji
Komponenty warstw prezentacji i logiki aplikacji tworzą zazwyczaj spójną całość. Zgodnie z tym, co powiedzieliśmy w poprzednim rozdziale, warstwy te składają się na frontend systemu. Bardzo istotne jest wyraźne wydzielenie tych elementów frontendu, które są silnie zależne od technologii interfejsu użytkownika oraz technologii wymiany danych. Technologie te ulegają częstym zmianom, czy wręcz są zastępowane innymi. Dlatego też, projektując frontend bardzo wskazane jest dokonanie podziału na kod „brudny” i kod „czysty”. Kod „brudny” jest podatny na zmiany technologii i podlega istotnym zmianom w trakcie rozwoju całego systemu. Kod „czysty” jest zależny jedynie od logiki aplikacji opisanej scenariuszami interakcji użytkowników z systemem (np. scenariuszami przypadków użycia). Klasy takie nie są zależne od jakiegokolwiek konkretnego szkieletu technologicznego (ang. framework).
Komponenty warstwy frontend
projektujemy na bazie projektu architektonicznego, który został omówiony w
poprzednim rozdziale. Punktem wyjścia do projektowania jest zatem model
komponentów, którego ogólna struktura jest przedstawiona na rysunku 4.1.

Rysunek 4.1: Ogólna struktura komponentów warstwy frontend
Projektując strukturę komponentu warstwy frontend
można skorzystać ze wzorca pokazanego na rysunku 4.2.
Wzorzec ten definiuje klasy implementujące odpowiednie interfejsy z rysunku 4.1,
a także klasy realizujące szczegółową funkcjonalność frontendu.
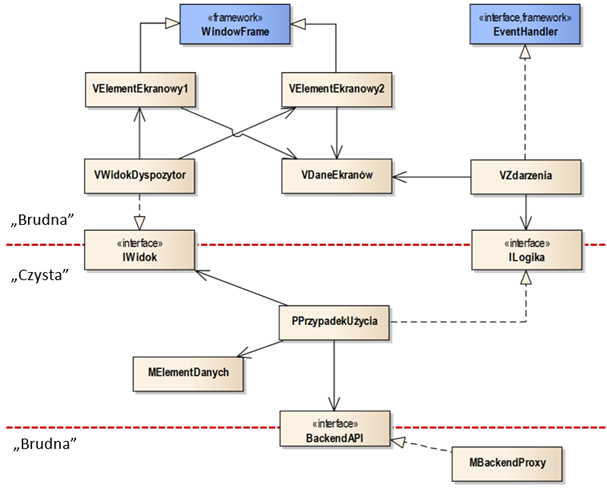
Zwróćmy uwagę na to, że we wzorcu wyraźnie wyróżnione są elementy „czyste” i
„brudne”. Wszystkie klasy warstwy widoku traktowane są jako „brudne”, czyli
zależne od odpowiedniego szkieletu technologicznego (frameworka).
Elementami tego szkieletu są klasa i interfejs opatrzone stereotypem «framework» („WindowForm” i „EventHandler”). Zakładamy tutaj hipotetyczny szkielet
technologiczny, który należy w praktycznym zastosowaniu zamienić na szkielet
rzeczywisty (najpopularniejsze szkielety omawiamy niżej).
Rysunek 4.2: Przykładowa struktura komponentu warstwy frontend
Za wyświetlanie poszczególnych elementów ekranowych odpowiadają klasy specjalizujące od odpowiedniej klasy „okienkowej” zawartej we framework’u (tu: „WindowFrame”). Za przechwytywanie i obsługę zdarzeń pochodzących od użytkownika odpowiada klasa realizująca standardowy interfejs (tu: „EventHandler”). Innym często stosowanym rozwiązaniem jest bezpośrednia realizacja interfejsu obsługi zdarzeń przez klasy wyświetlające elementy ekranowe. W naszej przykładowej strukturze oznaczałoby to, że klasy „VElementEkranowy” oprócz specjalizowania od klasy „WindowFrame” implementowałyby interfejs „EventHandler”.
Komunikacja warstwy widoku z warstwą logiki aplikacji odbywa się za pomocą interfejsów „IWidok” oraz „ILogika”. Pierwszy z tych interfejsów umożliwia sterowanie wyświetlaniem kolejnych widoków (ekranów). W naszym wzorcu, jest on realizowany przez klasę, która spełnia rolę „dyspozytora” („VWidokDyspozytor”). Klasa ta rozdziela polecenia wyświetlenia elementów ekranowych do poszczególnych klas typu „VElementEkranowy”. Drugi z interfejsów służy do przekazywania zdarzeń do realizacji. Każde zdarzenie przechwycone w warstwie widoku jest kierowane do odpowiedniego interfejsu warstwy logiki aplikacji w celu podjęcia odpowiednich działań. Zwróćmy uwagę na to, że warstwa widoku w żadnym wypadku nie realizuje logiki nawigacji między ekranami.
Warstwa logiki aplikacji jest warstwą „czystą” i zawiera klasy implementujące interfejsy typu „ILogika”. Korzystają one również z interfejsów warstwy widoku (tu: „IWidok”) oraz warstwy backend (logiki dziedzinowej, tu: „BackendAPI”). W warstwie tej możemy również umieścić klasy odpowiedzialne za lokalną walidację oraz przetwarzanie danych (tu: „MElementDanych”). Za właściwe przetwarzanie danych odpowiada warstwa backend, do której zazwyczaj odwołujemy się za pomocą API. W naszym wzorcu zastosowaliśmy interfejs („BackendAPI”), który separuje czysty kod od kodu „brudnego”, odpowiedzialnego za komunikację sieciową. Interfejs ten jest realizowany przez tzw. klasę proxy (zastępnik, tu: „MBackendProxy”). Jest to klasa, która dokonuje odpowiednich operacji „zastępczych”, tzn. tłumaczy lokalne wywołania procedur zdefiniowanych przez interfejs, na wywołania zdalne, realizowane np. w technologii REST API. Więcej o działaniu klas proxy mówimy w następnym rozdziale.
Na rysunku 4.3 widzimy fragment przykładowego projektu komponentu zgodnego z podanym wzorcem. Zwróćmy uwagę na to, że pominęliśmy tutaj interfejsy wewnętrzne oraz klasę „dyspozytora”. Jest to rozwiązanie, które można zastosować dla niedużych komponentów o prostej logice w celu zmniejszenia rozmiaru kodu.

Rysunek 4.3: Przykładowy projekt struktury komponentu warstwy frontend
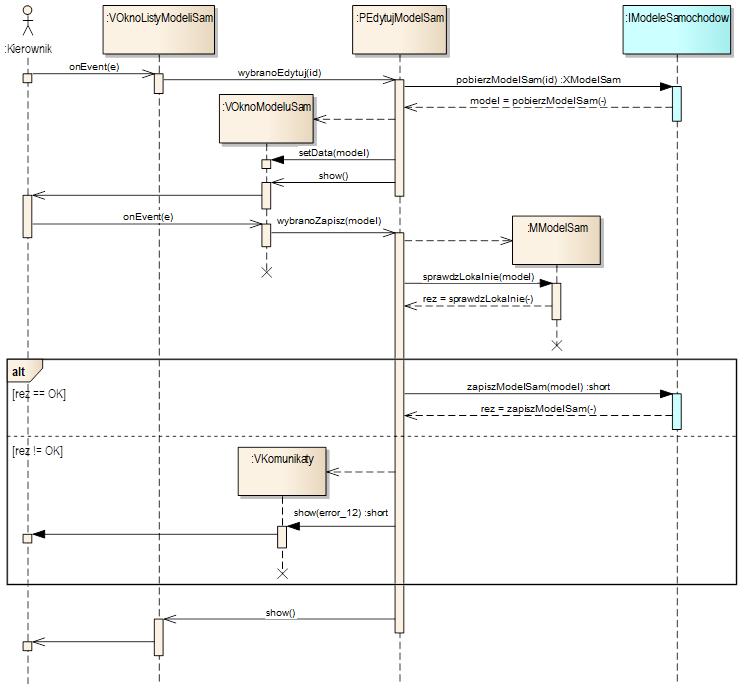
Działanie komponentu z
rysunku 4.3
ilustruje diagram sekwencji pokazany na rysunku 4.4.
Opisuje on wymianę komunikatów między obiektami w warstwie frontend
podczas realizacji przypadku użycia „Edytuj model samochodu”.
Rysunek 4.4: Przykładowy projekt działania komponentu warstwy frontend
4.2. Projektowanie warstwy logiki dziedzinowej
Jak wiemy z poprzedniego rozdziału, komponenty warstwy logiki dziedzinowej odpowiadają za wykonywanie zadań zlecanych przede wszystkim przez warstwę logiki aplikacji. Zadania te dotyczą wszelkiego rodzaju przetwarzania, zapamiętywania oraz odczytu danych. Zasadnicza funkcjonalność logiki dziedzinowej zazwyczaj projektowana jest jako zestaw niezależnych komponentów, często traktowanych jako usługi. Dla każdego takiego komponentu projektowany jest jeden lub więcej interfejsów zawierających odpowiednie zestawy operacji na obiektach dotyczących danej dziedziny problemu. Mamy wtedy do czynienia z wyraźnie wydzieloną warstwą backendu, na którą dodatkowo składa się warstwa przechowywania danych.
Jeśli warstwa frontendu wykonywana
jest po stronie serwera, to komunikacja z warstwą logiki dziedzinowej odbywa
się poprzez zwyczajne, lokalne wywołania procedur klas, realizujących
odpowiednie interfejsy. Znacznie bardziej złożona jest sytuacja, jeśli warstwa frontendu wykonywana jest po stronie klienta, tzn. na
maszynie użytkownika końcowego. W takiej sytuacji, aby wykonać operację logiki
dziedzinowej należy skomunikować się z warstwą backendu
poprzez zdalne wywołania procedur. Typowy mechanizm takiej komunikacji ilustruje
przykład przedstawiony na rysunku 4.5.
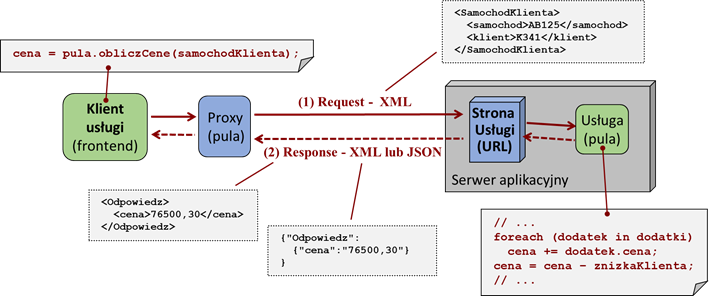
Rysunek 4.5: Zasada działania wywołań zdalnych (RPC, REST)
Obiekt klasy proxy przesyła pod odpowiedni adres (URL) serwera, komunikat żądania (ang. request) z umieszczonym w nim obiektem danych. Taki komunikat jest interpretowany przez serwer, w wyniku czego powinna zostać wywołana odpowiednia procedura obsługi żądania. Procedura ta odpowiada procedurze wywoływanej po stronie klienta i zawiera odpowiedni kod logiki aplikacji (tutaj: kod obliczania ceny samochodu). Po wykonaniu procedury, zwraca ona wynik i przekazuje sterowanie. W rezultacie, odpowiedni kod po stronie serwera powinien wysłać komunikat odpowiedzi (ang. response). Komunikat ten zawiera wynik przetwarzania danych wraz z ew. obiektem danych (tu: obiekt zawierający wyliczoną cenę). Po stronie klienta odpowiedź ta skutkuje powrotem z wywołania procedury i kontynuacją działania przez kod frontendu.
Realizacja powyższego mechanizmu przez komponenty logiki dziedzinowej zależy od zastosowanego szkieletu technologicznego (frameworku), umożliwiającego realizację wywołań zdalnych. Na rysunku 4.6 widzimy przykładową strukturę komponentu logiki dziedzinowej. Za obsługę wywołań zdalnych odpowiada „brudna” część tego komponentu, czyli część zależna od wybranego szkieletu technologicznego. W naszym przykładzie, zaprojektowano tzw. klasę kontrolera API (ang. API controller) o nazwie „ModeleSamochodowController”. Klasa ta specjalizuje standardową klasę „Controller”, która zapewnia obsługę odpowiednich mechanizmów technologicznych. Nasza klasa kontrolera zawiera obsługę wszystkich operacji realizowanego przez komponent interfejsu. Sygnatury tych operacji dostosowane są do wybranego szkieletu technologicznego dla obsługi API REST.

Rysunek 4.6: Przykładowa struktura komponentu backend
W bardziej złożonych
sytuacjach, kiedy logika dziedziny implementuje złożone algorytmy, warto
zastosować rozdzielenie odpowiedzialności na wiele klas. Tego typu podejście
realizuje wzorzec modelu dziedziny (ang. domain
model). We wzorcu tym, logika jest rozproszona między klasy zgodne z modelem
opisującym daną dziedzinę problemu. Przykład zastosowania
wzorca model dziedziny widzimy na rysunku 4.7. Zwróćmy uwagę na to, że dosyć złożona
struktura komponentu przysłonięta jest dla innych komponentów przez wąski
zestaw operacji interfejsu (tu: zaledwie jedna operacja interfejsu „IAnalityka”). Jest to realizacja wzorca projektowego fasada
(ang. facade).
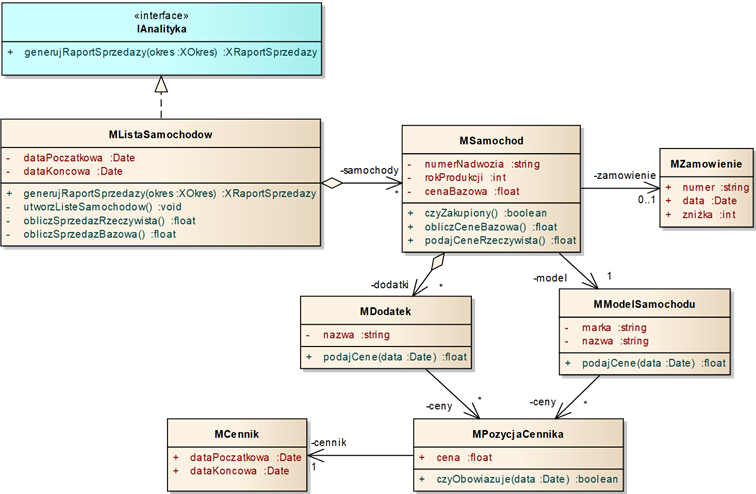
Rysunek 4.7: Komponent backend zaprojektowany zgodnie z modelem dziedziny
4.3. Projektowanie baz danych
Technologia baz danych relacyjnych jest obecnie powszechnie stosowana jako podstawowa metoda przechowywania danych ustrukturalizowanych. Podstawowym językiem umożliwiającym dokonywanie operacji na danych w bazach relacyjnych jest język SQL (Structured Query Language – strukturalny język zapytań). Język ten pozwala na pisanie tzw. zapytań do bazy danych, które pozwalają na wykonywanie złożonych operacji zapisu i odczytu danych. W języku SQL definiujemy również strukturę bazy danych, która oparta jest na czterech podstawowych konstrukcjach – tabelach, kolumnach, wierszach i powiązaniach. Opisując zasady projektowania baz danych relacyjnych zakładamy, że czytelnik jest zaznajomiony z podstawami tej technologii.
Podstawą projektu bazy danych jest definicja jej struktury. W tym celu możemy wykorzystać notację ERD/ERM (Entity Relationship Diagram/Model – diagram/model związków encji). Notacja ta nie jest ustandaryzowana i istnieją różne jej warianty. Jest ona podobna do notacji modelu klas języka UML. Tabele bazodanowe odpowiadają klasom, a kolumny w tabelach odpowiadają atrybutom. Powiązania między tabelami (często mylnie nazywane relacjami) odpowiadają asocjacjom między klasami. Podstawową jednostką przechowywania danych w bazie relacyjnej jest wiersz tabeli. Analogiem wiersza w podejściu obiektowym jest obiekt, zatem wiersze nie są zazwyczaj uwzględniane podczas projektowania bazy danych. Należy podkreślić, że model relacyjny posiada istotne różnice w stosunku do modelu obiektowego. Dlatego też konieczne jest odpowiednie przetłumaczenie modelu dziedziny zapisanego jako model obiektowy w języku UML w model relacyjny. Poniżej przedstawiamy zasady takiej translacji.
Rysunek 4.8 ilustruje podstawowe reguły projektowania tabel relacyjnych. Bierzemy pod uwagę klasy modelu dziedziny, które będą wymagały przechowywania ich obiektów w bazie danych. Dla takich klas tworzymy odpowiadające im tabele. Proste atrybuty klas (typu napisowego, liczbowego itp.) zamieniamy w kolumny tabeli. Dla atrybutów typów złożonych stosujemy zasady opisane poniżej, dotyczące projektowania asocjacji. Na rysunku 10.8 widzimy również zasadę przechowywania obiektów w relacyjnej bazie danych. Obiekty utworzone np. w pamięci ulotnej (tu: obiekt „uzytkownik”) są zapisywane jako wiersze w tabeli, gdzie kolumny tej tabeli odpowiadają atrybutom klas.

Rysunek 4.8: Tworzenie tabel na podstawie klas modelu dziedziny
Na rysunku 4.9
widzimy dwie metody projektowania struktury bazy danych dla asocjacji o
krotności „1” na obydwu końcach (asocjacje „1-1”). W takiej sytuacji,
najprostszym rozwiązaniem (patrz lewa strona rysunku) jest zaprojektowanie
jednej tabeli zawierającej kolumny odpowiadające atrybutom obydwu klas. Innym
rozwiązaniem jest stworzenie dwóch tabel odpowiadających dwóm klasom i ustanowienie
odpowiedniego połączenia między nimi (patrz prawa strona rysunku). Połączenie
tabel oznaczone jest linią, a krotności odpowiednimi symbolami (dwie kreseczki
oznaczają krotność „1”). Zwróćmy uwagę na to, że w tabelach zostały umieszczone
dodatkowe pseudo-kolumny oznaczone jako «PK» i «FK». Są to tzw. klucze główne
(ang. primary key) oraz klucze
obce (ang. foreign key).
Klucz główny stanowi unikalny identyfikator wiersza w danej tabeli. Z kolei
klucz obcy zawiera wartość klucza głównego w innej tabeli, który odpowiada
wierszowi połączonym z danym wierszem. Dzięki mechanizmowi kluczy możliwe jest
łatwe oznaczanie połączeń między wierszami (obiektami).
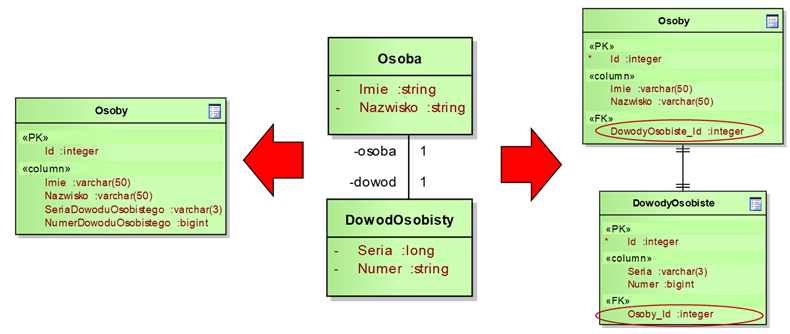
Rysunek 4.9: Tworzenie struktury tabel na podstawie asocjacji o krotności „1-1”
Rysunek 4.10 przedstawia sposób realizacji asocjacji o krotnościach „1” oraz „*” (wiele) – inaczej nazywanymi asocjacjami „1-N”. W naszym przykładzie, osoba może być uczniem co najwyżej jednej klasy szkolnej, natomiast do klasy szkolnej może być zapisanych wielu uczniów (co najmniej dwóch). W takiej sytuacji, podobnie jak w przypadku asocjacji „1-1” tworzymy dwie tabele. Podstawowa różnica polega na tym, że klucz obcy umieszczamy tylko w jednej tabeli – tej, która w powiązaniu posiada krotność „wiele”. Można tutaj zauważyć pewną wadę technologii relacyjnej, gdyż nawet niewielka zmiana krotności może powodować konieczność przebudowy struktury bazy danych (np. zmianę kluczy obcych). Zwróćmy jeszcze uwagę na oznaczenia krotności w notacji ERD – krotność „N” oznaczana jest jako tzw. „kurza łapka”, a krotność „0” lub „1” jako kółko z kreseczką.
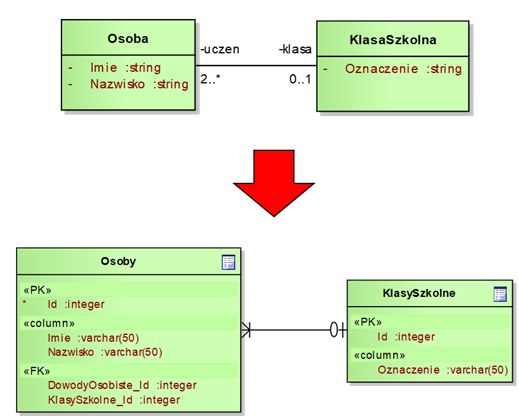
Rysunek 4.10: Tworzenie struktury tabel na podstawie asocjacji o krotności „1-N”
Rysunek 4.11 przedstawia najbardziej złożoną sytuację dotycząca asocjacji, czyli realizację asocjacji „wiele” do „wielu” („N-N”). Mamy tu przykład sytuacji, kiedy osoba może należeć do wielu stowarzyszeń, a stowarzyszenie może liczyć wielu członków będących osobami. W technologii relacyjnej wymaga to ustanowienia dodatkowej tabeli (tu: „OsobyStowarzyszenia”), która zawiera klucze obce wskazujące na dwie tabele utworzone na podstawie klas. Rozwiązanie takie jest konieczne z uwagi na ograniczenia modelu relacyjnego. Tabela nie może np. zawierać listy kluczy obcych, tak jak to jest możliwe w przypadku stosowania paradygmatu obiektowego.
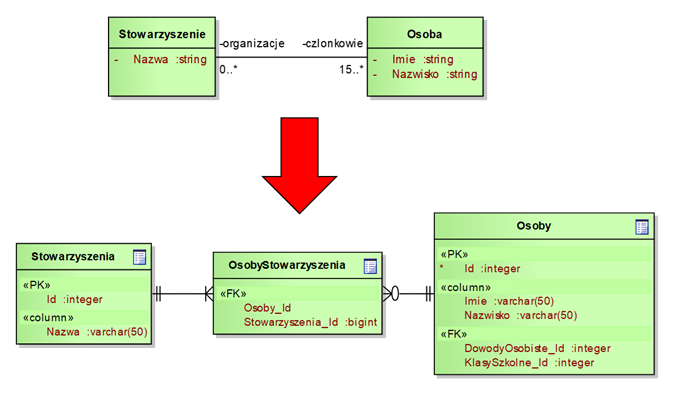
Rysunek 4.11: Tworzenie struktury tabel na podstawie asocjacji o krotności „N-N”
Ostatni przykład dotyczy traktowania relacji generalizacji. Na rysunku 4.12 widzimy dwie klasy („Osoba” i „Firma”), które specjalizują od klasy ogólnej („Klient”). W modelu relacyjnym nie możemy relacji generalizacji zamodelować bezpośrednio. Możemy natomiast zastosować jedno z kilku rozwiązań pokazanych na rysunku. Najprostsze rozwiązanie polega na umieszczeniu wszystkich kolumn w jednej tabeli odpowiadającej klasie ogólnej. To rozwiązanie ma zaletę prostoty oraz niekiedy – lepszej wydajności. Podstawowa wada polega na redundancji danych – dla niektórych wierszy niektóre kolumny będą puste. Drugie rozwiązanie polega na stworzeniu tabel jedynie dla klas szczegółowych. W takiej sytuacji, w tabelach tych dodajemy atrybuty klasy ogólnej. Takie rozwiązanie niej jest jednak polecane dla bardziej złożonych hierarchii generalizacji. Ostatnie rozwiązanie polega na utworzeniu tabel dla każdej klasy występującej w relacji generalizacji. W takiej sytuacji w tabelach odpowiadających klasom specjalizowanym należy umieścić klucze obce wskazujące na wiersze w tabeli odpowiadającej klasie ogólnej.
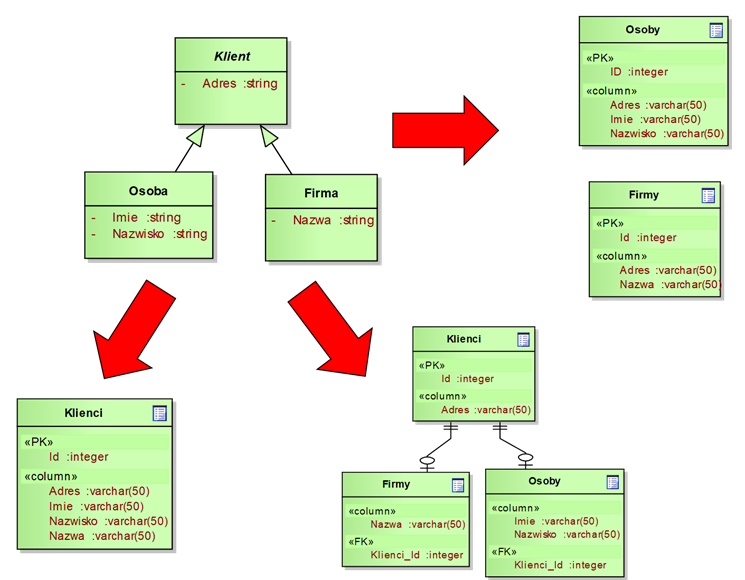
Rysunek 4.12: Tworzenie struktury tabel na podstawie generalizacji