Podręcznik
2. Transformacja i sieci neuronowe PCA
2.3. Zastosowania transformacji PCA
Główne zastosowania transformacji PCA związane są z kompresją danych, która jest nieodłącznym składnikiem każdego przekształcenia PCA. Własność ta może być bezpośrednio wykorzystana do kompresji stratnej informacji – mówimy wtedy o kompresji sygnałów (dane jednowymiarowe) bądź obrazów (dane 2-D). Niezastąpionym zastosowaniem PCA jest ilustracja rozkładu danych wielowymiarowych na płaszczyźnie (układ 2-współrzędnych w postaci 2 najważniejszych składników głównych) lub w przestrzeni 3-D (układ 3-współrzędnych w postaci 3 najważniejszych składników głównych). Ponadto transformacja PCA reprezentująca \(N\)-wymiarowy wektor \(\mathbf{x}\) przez \(K\)-wymiarowy (\(K<N\)) wektor \(\mathbf{y}\) składników głównych pozwala traktować wektor \(\mathbf{y}\) jako wektor cech diagnostycznych procesu reprezentowanego przez zbiór wektorów \(\mathbf{x}\).
8.3.1 PCA w zastosowaniu do kompresji stratnej danych
Kompresja danych z zastosowaniem PCA polega na przekształceniu \(N\)-elementowego wektora wejściowego \(\mathbf{x}\) w wektor \(\mathbf{y}\) o zmniejszonym wymiarze \(K\) (\(K<N\)). Redukcja wymiaru wektora \(\mathbf{x}\) poprzez PCA zapewnia optymalność przekształcenia poprzez zachowanie w wektorze zredukowanym największej możliwie dawki informacji oryginalnej (przy założonej wartości \(K\)).
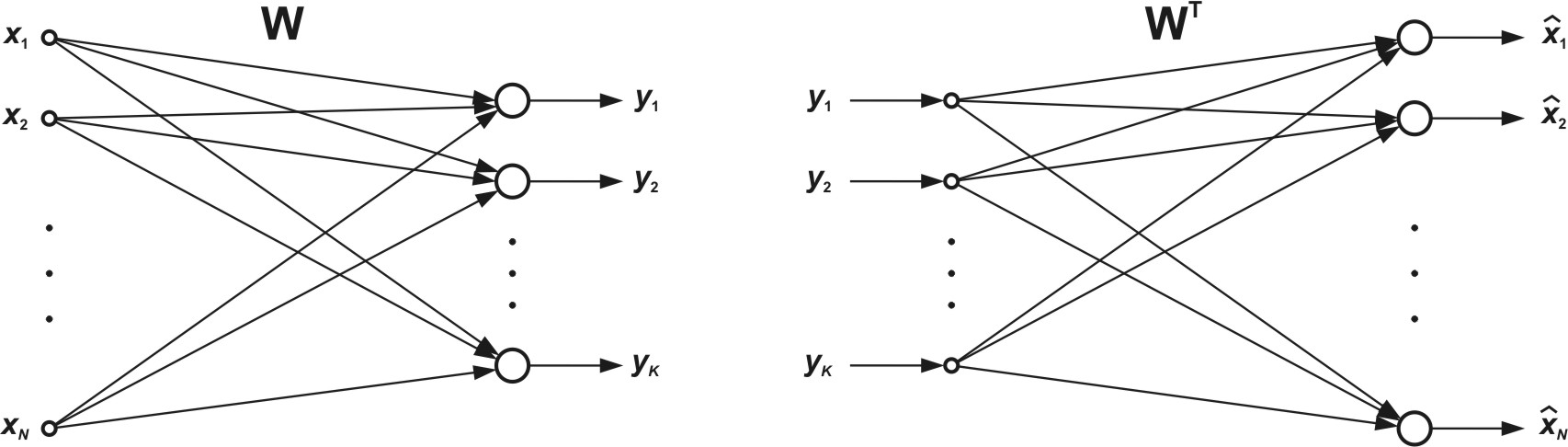
Na rys. 8.4 przedstawiono sieć PCA do kompresji (rys. 8.4a) oraz do rekonstrukcji (dekompresji) danych (rys. 8.4b). W sieci kompresyjnej wektor oryginalny \(\mathbf{x}\) jest transformowany w wektor \(\mathbf{y}\) o zredukowanym wymiarze \(K\), przy czym \(\mathbf{y} = \mathbf{Wx}\). Wektor \(\mathbf{y}\) może podlegać bądź to transmisji na odległość bądź zapisaniu na dysku. W każdym przypadku możliwe jest odtworzenie wektora oryginalnego na podstawie jego zredukowanej formy \(\mathbf{y}\), korzystając z sieci rekonstrukcyjnej z rys. 8.4b, wykonującej operację odwrotną \(\mathbf{\hat{y}} = \mathbf{W^Tx}\). Biorąc pod uwagę pewną utratę informacji spowodowaną obcięciem wymiaru wektora odtworzenie to jest z pewnym przybliżeniem \( \hat{\mathbf{x}} \simeq \mathbf{x} \).
O współczynniku kompresji decyduje liczba składników głównych \(K\) uwzględnionych w przekształceniu PCA. Przy dużej liczbie wektorów \(\mathbf{x}\) podlegających przekształceniu można pominąć liczbę bitów do kodowania wag sieci i współczynnik kompresji wyrazić wzorem przybliżonym
| \(K_r \cong \frac{N}{K}\) | (8.24) |
Im wyższy współczynnik kompresji tym większa oszczędność pamięci, ale gorsza jakość odtworzonego obrazu (większa porcja informacji utracona bezpowrotnie w wyniku redukcji wymiaru wektora oryginalnego).




Na rys. 8.5 przedstawiono obraz oryginalny (rys. 8.5a) oraz trzy obrazy zrekonstruowane na podstawie odpowiednio 1, 3 i 5 składników głównych PCA (rys. 8.5 b,c,d). Obraz poddany kompresji miał wymiar \(512 \times 512 \) pikseli i został podzielony na ramki o wymiarach \(8 \times 8 \) (wymiar wektora \(\mathbf{x}\) równy \(64\)). Jakość odtworzonego obrazu jest ściśle uzależniona od liczby \(K\) składników głównych uwzględnionych w odtwarzaniu. Im więcej jest tych składników, tym lepsza jakość obrazu, ale mniejszy współczynnik kompresji. Przy największym współczynniku kompresji (jeden składnik główny) wyraźnie widoczne są poszczególne ramki w obrazie. Obraz odtworzony na podstawie pięciu składników głównych nie różni się wzrokowo od obrazu oryginalnego. Współczynniki PSNR otrzymane dla poszczególnych obrazów są odpowiednio równe: 18,80 dB, 25,43 dB oraz 27,58 dB, przy czym \(\mathbf{</span><span style="font-size: 0.9375rem; text-align: left;">PSNR}\) określany jest wzorem
| \( PSNR=10 \log \left(\frac{255^2}{MSE}\right) \) | (8.25) |
gdzie \(MSE\) oznacza wartość błędu średniokwadratowego odtworzonego obrazu względem obrazu oryginalnego.
8.3.2 Przykład zastosowania PCA do ilustracji rozkładu danych wielowymiarowych
Oryginalne zastosowanie znalazło PCA w ilustracji graficznej rozkładu danych wielowymiarowych poprzez zrzutowanie ich w przestrzeń 2-D lub 3-D. Wybierając \(K=2\) rzutujemy każdy \(N\)-wymiarowy wektor \(\mathbf{x}\) w przestrzeń dwuwymiarową. W ten sposób każdy wektor \(\mathbf{x}\) jest reprezentowany przez wektor \(\mathbf{y} = [y_1 y_2]\), którego położenie może być bez problemu zilustrowane na płaszczyźnie, której oś poziomą stanowi teraz składnik główny \( y_1 \), a oś pionową składnik główny \( y_2 \). Wektory \(\mathbf{x}\) „podobne” do siebie zajmą wówczas bliskie sobie położenia na płaszczyźnie, a wektory „dalekie” – położenia odległe.
Ta unikalna własność znajduje szerokie zastosowania w problemach klasyfikacyjnych, gdzie służy do badania jednorodności rozkładów danych w ramach poszczególnych klas oraz do określania średnich odległości między klasowych
Przykład takiego zastosowania pokażemy w przestrzeni 2-wymiarowej ilustrującej graficznie położenie poszczególnych województw Polski (na płaszczyźnie reprezentowanej przez 2 najważniejsze składniki główne). Wyniki dotyczą przykładowych danych GUS z jednego roku. Rzutowanie dotyczyło 13-wymiarowych elementów informacji GUS dla każdego województwa. Informacje dotyczą następujących elementów:
-
Procent ludności mieszkających w miastach
-
Odsetek zgonu niemowląt
-
Przyrost naturalny ludności
-
Stopa bezrobocia
-
Wynagrodzenie miesięczne brutto
-
Zasoby mieszkaniowe przypadające na 10000 ludności
-
Liczba osób hospitalizowanych w roku przypadających na 10000 ludności
-
Liczba ciągników rolniczych przypadająca na 100 ha gruntów
-
Produkcja sprzedana przemysłu przypadająca na głowę ludności
-
Produkcja sprzedana budownictwa przypadająca na głowę ludności
-
Liczba kilometrów dróg przypadających na 10km2 w przeliczeniu na głowę ludnosci
-
Wartość PKB per capita
-
Liczba firm zarejestrowanych w bazie REGON przypadająca na głowę ludności
Dla uproszczenia opisów przyjęto numeryczne oznaczenia poszczególnych województw w kolejności jak niżej:
-
Dolnośląskie
-
Kujawsko-pomorskie
-
Lubelskie
-
Lubuskie
-
Łódzkie
-
Małopolskie
-
Mazowieckie
-
Opolskie
-
Podkarpackie
-
Podlaskie
-
Pomorskie
-
Śląskie
-
Świętokrzyskie
-
Warmińsko-mazurskie
-
Wielkopolskie
-
Zachodniopomorskie
Tabela 8.1 przedstawia dane oryginalne dotyczące tych zagadnień. Wektor x dla każdego województwa tworzy wybranych 13 elementów informacji dotyczącej ekonomii, dostępności edukacji i opieki medycznej. Użyto następujących skrótów:
Tabela 8.1 Dane liczbowe GUS dotyczące 13 elementów informacji województw w Polsce. Wiersze reprezentują województwa (od 1 do 16), kolumny elementy uwzględnionej informacji (od 1 do 13)
|
Województwo |
Kolejne 13 elementów informacji |
||||||||||||
|
1 |
70,6 |
6,9 |
-0,8 |
11,8 |
2861 |
357 |
1860 |
6,5 |
72588 |
7161 |
91,2 |
26620 |
308,3 |
|
2 |
61,1 |
6,1 |
0,7 |
15,2 |
2443 |
328 |
1638 |
8,5 |
36918 |
3573 |
78,9 |
22474 |
188,5 |
|
3 |
46,6 |
6,1 |
-0,7 |
13 |
2486 |
328 |
1874 |
11,9 |
23230 |
2851 |
72,7 |
17591 |
151,5 |
|
4 |
63,9 |
6 |
1,3 |
14,2 |
2430 |
337 |
1615 |
4,2 |
17481 |
1370 |
57,8 |
23241 |
106,5 |
|
5 |
64,4 |
4,8 |
-3,2 |
11,5 |
2471 |
374 |
2035 |
12,2 |
40644 |
5209 |
92,2 |
23666 |
240,9 |
|
6 |
49,4 |
6,4 |
1,4 |
8,8 |
2666 |
318 |
1611 |
17,9 |
53890 |
8241 |
145 |
21989 |
293,8 |
|
7 |
64,7 |
4,9 |
0,4 |
9,2 |
3671 |
371 |
1759 |
10,5 |
176121 |
37752 |
84,5 |
40817 |
627,3 |
|
8 |
52,5 |
4,4 |
-1,1 |
12 |
2607 |
325 |
1579 |
7,8 |
19312 |
1857 |
88,9 |
21347 |
94,9 |
|
9 |
40,6 |
6 |
1,5 |
14,4 |
2373 |
291 |
1747 |
16 |
28228 |
3140 |
79,2 |
17789 |
142,1 |
|
10 |
59,5 |
5 |
-0,5 |
10,7 |
2525 |
340 |
1901 |
9 |
14011 |
2836 |
54,6 |
19075 |
88,7 |
|
11 |
66,7 |
6,4 |
2,7 |
10,9 |
2883 |
334 |
1553 |
6,3 |
49272 |
5810 |
63,2 |
25308 |
232,8 |
|
12 |
78,4 |
6,7 |
-0,8 |
9,3 |
2933 |
363 |
1820 |
12,2 |
151323 |
12174 |
164 |
27792 |
427,4 |
|
13 |
45,4 |
5 |
-1,4 |
15,1 |
2467 |
327 |
1903 |
14,3 |
19516 |
2386 |
104 |
19274 |
106,9 |
|
14 |
60 |
5,4 |
1,9 |
19 |
2398 |
328 |
1808 |
5 |
19709 |
2514 |
50,6 |
19709 |
113,1 |
|
15 |
56,6 |
6,7 |
2,1 |
8 |
2611 |
314 |
1869 |
8,8 |
89537 |
12655 |
85,1 |
27553 |
352,2 |
|
16 |
68,9 |
7,4 |
0,8 |
16,6 |
2616 |
346 |
1789 |
3,4 |
23234 |
3044 |
55,8 |
23924 |
210,8 |
Na rys. 8.6 przedstawiono ilustrację dwuwymiarową położenia względnego 16 województw Polski na podstawie danych statystycznych dotyczących rozwoju ekonomicznego, stanu edukacyjnego i opieki medycznej.
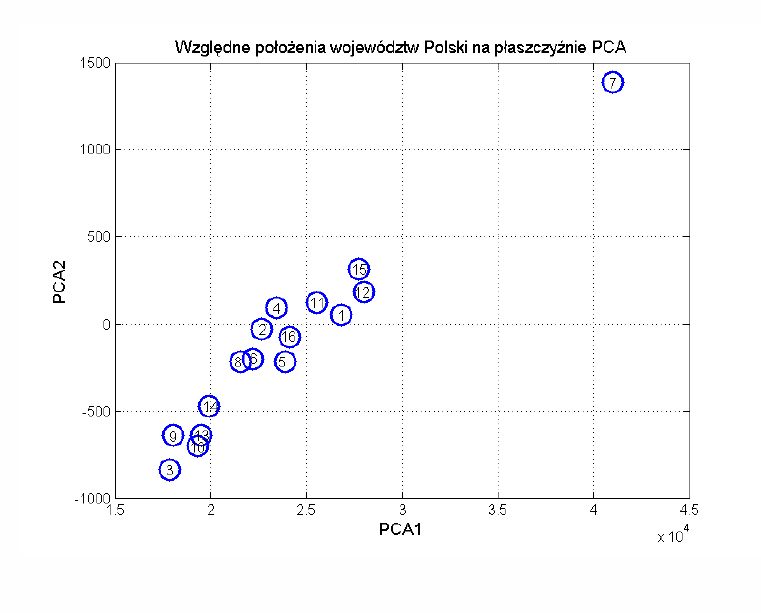
Bliskie położenie na płaszczyźnie oznacza podobieństwo cech charakteryzujących te województwa. Większe odległości miedzy poszczególnymi punktami oznaczają większe różnice w rozwoju tych województw (pod względem uwzględnionych 13 wskaźników ekonomicznych i społecznych). Najbardziej odstającym województwem, wyróżniającym się w grupie analizowanych jednostek okazało się województwo Mazowieckie. Najbardziej odległe od niego są województwa: Lubelskie, Podkarpackie, Podlaskie, Świętokrzyskie i Warmińsko-mazurskie. Najbliższe województwu Mazowieckiemu okazało się województwo Wielkopolskie i Śląskie. Zauważmy, że w tej analizie nie uwzględnia się wartości składników głównych, a jedynie względne odległości między położeniami na płaszczyźnie utworzonej przez dwa najważniejsze składniki główne. Należy dodatkowo zaznaczyć, że powyższy rozkład został uzyskany przy uwzględnieniu jedynie wybranych 13 parametrów, spośród wielu dostępnych w publikacjach GUS i dotyczy danych jednego roku.