Podręcznik
3. Algorytmy genetyczne
3.1. Historia
Badania nad genetyką
Choć same zasady dziedziczności były obserwowane i opisywane znacznie wcześniej – wystarczy wspomnieć prace Grzegorza Mendla z połowy XIX wieku dotyczące krzyżówek grochu – to prawdziwa eksplozja wiedzy na temat genów i mechanizmów dziedziczenia rozpoczęła się dopiero w XX wieku. W 1910 roku po raz pierwszy wprowadzono pojęcie genu, jako najmniejszej, abstrakcyjnej jednostki dziedziczenia, odpowiedzialnej za pojawianie się określonych cech u organizmów. Początkowo nie było wiadomo, z czego ten gen się składa ani jak dokładnie działa – rozumiano go bardziej jako koncepcję niż konkretną strukturę biologiczną.
Tymczasem jeszcze wcześniej, bo w 1869 roku, niemiecki chemik Johann Friedrich Miescher, badając skład chemiczny jąder komórkowych, wyizolował substancję, którą nazwał „nukleiną”. Dziś wiemy, że była to forma DNA. Nie potrafiono jeszcze wtedy przypisać jej roli nośnika informacji genetycznej – dopiero z czasem okazało się, że to właśnie ten „niepozorny kwas” zapisuje wszystko, co dotyczy budowy i działania organizmów.
Punktem zwrotnym dla współczesnej genetyki był rok 1953. Wtedy to James Watson i Francis Crick – bazując m.in. na danych rentgenowskich Rosalind Franklin – opisali strukturę DNA jako podwójną helisę zbudowaną z czterech typów nukleotydów: adeniny (A), tyminy (T), guaniny (G) i cytozyny (C). Dzięki ustaleniu reguł łączenia się tych cząsteczek (A z T, G z C) zrozumiano, jak możliwe jest kopiowanie i przechowywanie informacji genetycznej.
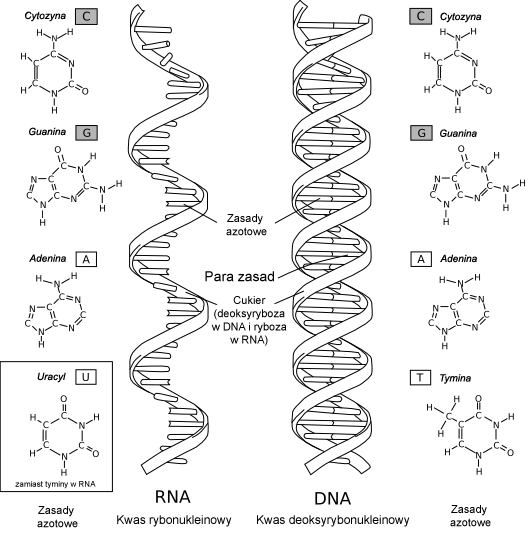
Źródło - wikipedia
Z czasem poznano kolejne etapy „przepływu” informacji w organizmach żywych:
- Replikacja – czyli tworzenie kopii DNA, co umożliwia przekazywanie informacji do komórek potomnych, a więc i dziedziczenie cech.
- Transkrypcja – przepisanie fragmentu DNA na RNA, czyli swoistą roboczą kopię zawierającą instrukcję.
- Translacja – przetworzenie RNA w łańcuch aminokwasów, z których powstają białka, a więc budulec i „narzędzia” komórek.
W skrócie – DNA to nie tylko „kod”, ale raczej cały system zapisu, kompilacji i wykonania. Oczywiście, w genach zaszyte są też inne mechanizmy – jak mutacje (czyli losowe zmiany w zapisie) oraz mechanizmy naprawcze. Wszystko to razem stworzyło bazę wiedzy, która pozwoliła nie tylko lepiej zrozumieć życie, ale też zainspirować informatyków do tworzenia nowych metod optymalizacji – takich jak właśnie algorytmy genetyczne.
Teoria ewolucji
Gdy spojrzymy wstecz na historię biologii, zobaczymy, że jedną z najbardziej rewolucyjnych idei była teoria ewolucji przez dobór naturalny, zaproponowana przez Karola Darwina w połowie XIX wieku. W swoim dziele „O powstawaniu gatunków” Darwin zaproponował odważną myśl: że wszystkie organizmy żywe pochodzą od wspólnego przodka, a zmiany w ich cechach są wynikiem długotrwałego, stopniowego procesu selekcji.

Ewolucja – jak zauważył Darwin – działa trochę jak bardzo powolny, naturalny „algorytm”: losowe zmiany (mutacje) pojawiają się w populacji, a środowisko „ocenia”, które cechy są korzystne, a które nie. Organizmy o korzystniejszych cechach mają większą szansę na przeżycie i rozmnożenie się – czyli przekazanie tych cech dalej. To właśnie nazywamy doborem naturalnym. Główne filary teorii ewolucji to:
- Organizmy są śmiertelne – nie każdy przeżyje, więc istnieje presja selekcyjna.
- Rozmnażają się – ale ich potomstwo nie jest identyczne (istnieje zmienność).
- Cechy są dziedziczone – czyli potomstwo dziedziczy część cech od rodziców.
- Środowisko jest ograniczone – nie wystarczy zasobów dla wszystkich, więc trwa rywalizacja.
Warto podkreślić, że dobór naturalny działa niezależnie od jakiejkolwiek inteligencji czy celu – to czysty mechanizm statystyczny. Ale jego efekty – przystosowania, strategie przetrwania, niezwykłe złożone formy życia – są tak zaskakujące, że aż proszą się o porównania z projektowaniem.
Teoria ewolucji doczekała się wielu potwierdzeń – od badań nad muszką owocową, przez zapis kopalny, aż po symulacje komputerowe. I właśnie to ostatnie stało się punktem wyjścia dla informatyków i inżynierów: skoro natura potrafi znaleźć dobre (czasem zaskakująco dobre!) rozwiązania, to może warto od niej pożyczyć kilka sztuczek?
Syntetyczna teoria ewolucji
Na styku dwóch wielkich teorii – genetyki i darwinowskiej ewolucji – narodziło się podejście znane jako syntetyczna teoria ewolucji. To właśnie ono stanowi bezpośrednią inspirację dla algorytmów genetycznych, które stosujemy dziś w optymalizacji.
Syntetyczna teoria mówi: ewolucja to nie tylko „przetrwają najlepiej dostosowani”, ale cały złożony system oparty na:
- mutacjach – czyli losowych, często niewielkich zmianach w genotypie, które mogą prowadzić do nowych cech,
- rekombinacji – wymieszaniu materiału genetycznego dwóch organizmów (czyli krzyżowaniu),
- selekcji – w tym dobór naturalny, ale też np. seksualny, sztuczny, stabilizujący, itd.,
- dziedziczeniu – czyli transmisji informacji do potomstwa.
To wszystko razem tworzy „algorytm” przyrody, który jest zdolny – bez nadzoru, bez projektanta – tworzyć rozwiązania trudnych problemów przetrwania. Brzmi znajomo?
Takie właśnie podejście zostało zaadaptowane do tworzenia algorytmów genetycznych. Informatycy zrobili to, co najlepiej potrafią: formalizowali obserwacje, zdefiniowali pojęcia (osobnik, populacja, gen, funkcja celu), i zaczęli symulować ten proces. Algorytmy genetyczne tworzą sztuczne populacje rozwiązań, poddają je działaniu krzyżowania, mutacji, selekcji – i patrzą, co z tego wyjdzie.
Z czasem pojawiły się całe rodziny algorytmów ewolucyjnych (np. strategie ewolucyjne, programowanie ewolucyjne, algorytmy rojowe). Ale to właśnie genetyka – z jej strukturą DNA, z jej ideą genotypu i fenotypu – była tą najpierwszą, najbardziej inspirującą bazą.
Dzięki syntetycznej teorii ewolucji mamy dziś nie tylko lepsze zrozumienie przyrody, ale też potężne narzędzia optymalizacyjne, które z powodzeniem stosujemy w inżynierii, robotyce, finansach, a nawet sztuce.