Podręcznik
3. Sieci neuronowe głębokie
3.10. Sieci generatywne GAN
Sieć generatywna GAN (Generative Adversarial Network- GAN) stworzona przez zespół Iana Goodfellow w 2014 roku, jest implementacją koncepcji przeciwstawienia sobie dwu sieci neuronowych, z których jedna reprezentuje dane rzeczywiste, a druga dane generowane sztucznie, "udając" dane rzeczywiste [19]. Obie sieci rywalizują ze sobą. System jest trenowany w taki sposób aby generator nowych danych był w stanie oszukać rzeczywistość, prezentując dane (sygnały bądź obrazy) które są trudne do odróżnienia od rzeczywistych. Generator sztucznych danych ma za zadanie wygenerować je w taki sposób, aby statystyki danych oryginalnych i danych generowanych przez niego były takie same. Przykładowo w przypadku obrazów, obraz wygenerowany sztucznie powinien przypominać obraz oryginalny.

Idea działania sieci GAN jest przedstawiona na rys. 6.33. Blok  reprezentuje dane oryginalne,
reprezentuje dane oryginalne,  – wektor losowy zasilający generator
– wektor losowy zasilający generator  , generujący na tej podstawie dane
, generujący na tej podstawie dane ") „udające” dane oryginalne. Dyskryminator
„udające” dane oryginalne. Dyskryminator  porównuje dane oryginalne z wygenerowanymi przez generator wskazując na prawdopodobieństwo zgodności obu danych i . Proces uczenia sieci polega na takim doborze parametrów, aby oszukać dyskryminator (uznać, że dane wygenerowane sztucznie niczym nie różnią się od danych oryginalnych . W efekcie generator generuje kolejnych kandydatów do porównania, a dyskryminator ocenia ich jakość w stosunku do oryginału.
porównuje dane oryginalne z wygenerowanymi przez generator wskazując na prawdopodobieństwo zgodności obu danych i . Proces uczenia sieci polega na takim doborze parametrów, aby oszukać dyskryminator (uznać, że dane wygenerowane sztucznie niczym nie różnią się od danych oryginalnych . W efekcie generator generuje kolejnych kandydatów do porównania, a dyskryminator ocenia ich jakość w stosunku do oryginału.
Proces uczenia polega na maksymalizacji prawdopodobieństwa, że dyskryminator popełni błąd, przyjmując że obie grupy danych (oryginalne i sztucznie wygenerowane) są identyczne pod względem rozkładu statystycznego (maksymalizacja prawdopodobieństwa zaliczenia obu obrazów: oryginalnego i wygenerowanego sztucznie do tej samej klasy). Można go zapisać jako programowanie minimaksowe zdefiniowane w postaci [19]
![\min _G \max _D V(G, D)=E_{\mathbf{X} \sim p_{\mathbf{x}}}[\log D(\mathbf{X})]+E_{\mathbf{z} \sim p_{\mathbf{z}}}[\log (1-D(G(\mathbf{z})))]](https://esezam.okno.pw.edu.pl/filter/tex/pix.php/ed6196bbee584e2b21f452b809b98383.gif "\min _G \max _D V(G, D)=E_{\mathbf{X} \sim p_{\mathbf{x}}}[\log D(\mathbf{X})]+E_{\mathbf{z} \sim p_{\mathbf{z}}}[\log (1-D(G(\mathbf{z})))]") |
(6.39) |
gdzie symbol  reprezentuje wartość oczekiwaną, natomiast
reprezentuje wartość oczekiwaną, natomiast  i
i  rozkłady statystyczne odpowiednio danych rzeczywistych (oryginalnych) i wygenerowanych sztucznie.
rozkłady statystyczne odpowiednio danych rzeczywistych (oryginalnych) i wygenerowanych sztucznie. ") oraz
oraz ") są wartościami generowanymi odpowiednio przez dyskryminator i generator dla danych . W efekcie proces optymalizacyjny ukierunkowany jest na poszukiwanie minimum względem generatora i maksimum względem dyskryminatora .
są wartościami generowanymi odpowiednio przez dyskryminator i generator dla danych . W efekcie proces optymalizacyjny ukierunkowany jest na poszukiwanie minimum względem generatora i maksimum względem dyskryminatora .
Generator zasilany jest poprzez wektor losowy o określonym wymiarze. Na bazie tego wektora próbuje wygenerować obraz przypominający oryginał . Dyskryminator zasilany jest przez obraz oryginalny i obraz wygenerowany przez generator . W wyniku ich porównania generuje wartość prawdopodobieństwa, że obraz jest nierozpoznawalny od oryginału . Oba modele i mogą być implementowane przy użyciu różnych struktur sieci neuronowych, aczkolwiek aktualnie najlepsze wyniki uzyskuje się przy użyciu sieci głębokich o strukturze CNN.
Proces uczenia sieci GAN przyjmuje formę iteracyjną. Przy aktualnych parametrach generatora wykonuje się  kroków w optymalizacji dyskryminatora a następnie jeden krok optymalizacji generatora. W pętli wewnętrznej adaptacji dyskryminator jest ukierunkowany na rozróżnienie próbek obu obrazów. W kroku drugim dotyczącym adaptacji generatora jego parametry są zmieniane w takim kierunku, aby wynik generatora był bliższy obrazowi oryginalnemu. Po wykonaniu wielu iteracji osiągnięty jest punkt, w którym nie występuje możliwość poprawy wyniku w obu krokach, czyli dyskryminator nie jest w stanie rozróżnić obrazu
kroków w optymalizacji dyskryminatora a następnie jeden krok optymalizacji generatora. W pętli wewnętrznej adaptacji dyskryminator jest ukierunkowany na rozróżnienie próbek obu obrazów. W kroku drugim dotyczącym adaptacji generatora jego parametry są zmieniane w takim kierunku, aby wynik generatora był bliższy obrazowi oryginalnemu. Po wykonaniu wielu iteracji osiągnięty jest punkt, w którym nie występuje możliwość poprawy wyniku w obu krokach, czyli dyskryminator nie jest w stanie rozróżnić obrazu ") od oryginalnego .
od oryginalnego .
Powstało wiele modyfikacji podstawowej struktury GAN polepszających sprawność wykrywania „podróbki” od danych oryginalnych. Przykład takiego rozwiązania zwanego BIGAN (BIdirectional Generative Adversarial Networks) przedstawiony jest na rys. 6.34.
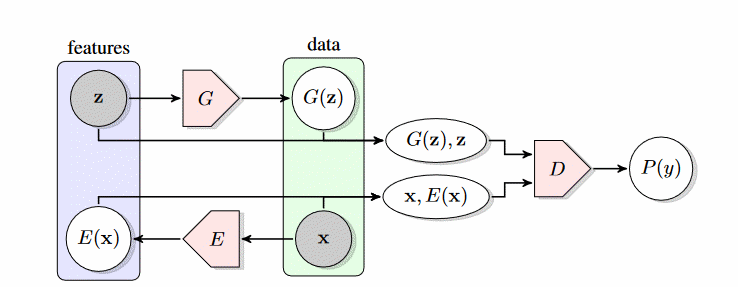
Struktura sieci BIGAN zawiera enkoder który transformuje dane oryginalne do przestrzeni wektorowej ") , generując wektor cech o wymiarach identycznych z wektorem losowym . Dyskryminator sieci BIGAN dokonuje więc rozróżnienia pary danych
, generując wektor cech o wymiarach identycznych z wektorem losowym . Dyskryminator sieci BIGAN dokonuje więc rozróżnienia pary danych )") oraz
oraz , \mathbf{z})") zamiast ( versus ) w klasycznej implementacji GAN. Jest oczywiste, że enkoder próbuje „nauczyć” się inwersji generatora (czyli wektora ), choć nie występuje tu bezpośrednia komunikacja. Zwiększona informacja (w stosunku do wersji oryginalnej GAN) dostarczona do dyskryminatora umożliwia polepszenie dokładności rozpoznania „podróbki” od oryginału.
zamiast ( versus ) w klasycznej implementacji GAN. Jest oczywiste, że enkoder próbuje „nauczyć” się inwersji generatora (czyli wektora ), choć nie występuje tu bezpośrednia komunikacja. Zwiększona informacja (w stosunku do wersji oryginalnej GAN) dostarczona do dyskryminatora umożliwia polepszenie dokładności rozpoznania „podróbki” od oryginału.
Sieci generatywne (GAN i jego różne modyfikacje) znajdują różne zastosowania. Jednym z nich jest wzbogacanie zbioru danych oryginalnych (tak zwana augmentacja zbioru) użytych w uczeniu sieci CNN. Dane wygenerowane przez GAN są podobne statystycznie do danych oryginalnych, ale nie tożsame, co jest warunkiem polepszenia zdolności generalizacyjnych trenowanych sieci. Innym zastosowaniem sieci GAN jest wykrywanie różnic między oryginałami i podróbkami. Dotyczy to zarówno obrazów jak i sygnałów. Sieci te wykazują się zwiększoną czułością w stosunku do innych rozwiązań.