Podręcznik
Wersja podręcznika: 1.0
Data publikacji: 01.01.2022 r.
Wykłady
W1…WN, odpowiadające w sumie ok. 10-12 godz. standardowego wykładu
1. Klasy problemów i pakiety optymalizujące
1.5. Implementacja modelu
OPL to język modelowania problemów optymalizacyjnych, która ułatwia implementację modeli matematycznych w pakiecie ILOG CPLEX Optimization Studio. W tym rozdziale podajemy najważniejsze informacje, podczas pracy warto korzystać z udostępnionych narzędzi pomocy, czyli poprzez ”Help->Search”, np. dla przejrzenia słów kluczowych należy wpisać 'OPLkeywords', a do wglądu w dostępne funkcje należy wpisać 'OPLfunctions'.
Projekt
W Cplex Studio operuje się na projektach, odpowiadających konkretnym problemom. Każdy projekt musi zawierać przynajmniej jeden plik z modelem, jak też przynajmniej jedną specyfikację konfiguracji. Elementów tych może być więcej w projekcie, a formalnie można w nim definiować następujące składowe:
- plik z modelem ( .mod)
- plik z danymi ( .dat)
- konfiguracja uruchomienia "run configuration" wiążąca model z danymi
- plik z ustawieniami (.ops)
Wbudowane typy danych
Opl posługuje się standardowymi podstawowymi typami danych, które mogą być typu:
- int
- float
- string (napisy "w cudzysłowie")
Struktury danych
- zbiory (set): nawiasy klamrowe, w nich typ elementów zbioru np. {string} Warehouses = ...;
- tablice (array) 1- i wielowymiarowe: nawiasy kwadratowe, w nich rozmiar tablicy lub po prostu nazwy zbiorów - dla elementów tych zbiorów przechowywane są wartości w tablicy; typ wartości w tablicy trzeba podać, np. int SupplyCost[Stores][Warehouses] = ...;
- skalary: po prostu wartości danego typu wbudowanego, np. int Fixed = ...;
- zakres range: liczby całkowite (int) w pewnym zakresie podanym w definicji typu, np. range Stores = 0..NbStores-1;
- krotka tuple: odpowiednik wiersza tabeli, czyli powiązanie kilku typów danych ze sobą, np. tuple daneProduktu {string nazwa; int minZapas; float zapotrzebowanie}
Typy zmiennych decyzyjnych
Dla zmiennych decyzyjnych, które są deklarowane przy użyciu słowo kluczowe dvar (decision variable) dostępne są wbudowane typy liczbowe, jak też dodatkowo typ binarny, czyli zmienna 0-1. Pogrubieniem zaznaczyliśmy zmienne całkowitoliczbowe, których użycie w modelu powoduje, że problem staje się zadniem optymalizacji dyskretnej:
- int
- float
- boolean
Projekt warehouse
Implementacja problemu przedstawionego w poprzednim rozdziale jest już przygotowana w CPLEX Studio, należy ją otworzyć wchodząc poprzez menu 'File > New > Example menu' i wpisać nazwę 'warehouse'.
Widok okienka poniżej pokazuje katalog otwrtych projektów, w tym interesujący nas projekt 'warehouse', w którym są cztery pliki z modelami, cztery instancje konfiguracji uruchomienia oraz jeden plik z danymi. Uwaga - model, który przedstawiliśmy w poprzednim rozdziale jest zaimplementowany w pliku 'warehouse.mod'.
Rozwiązanie problemu
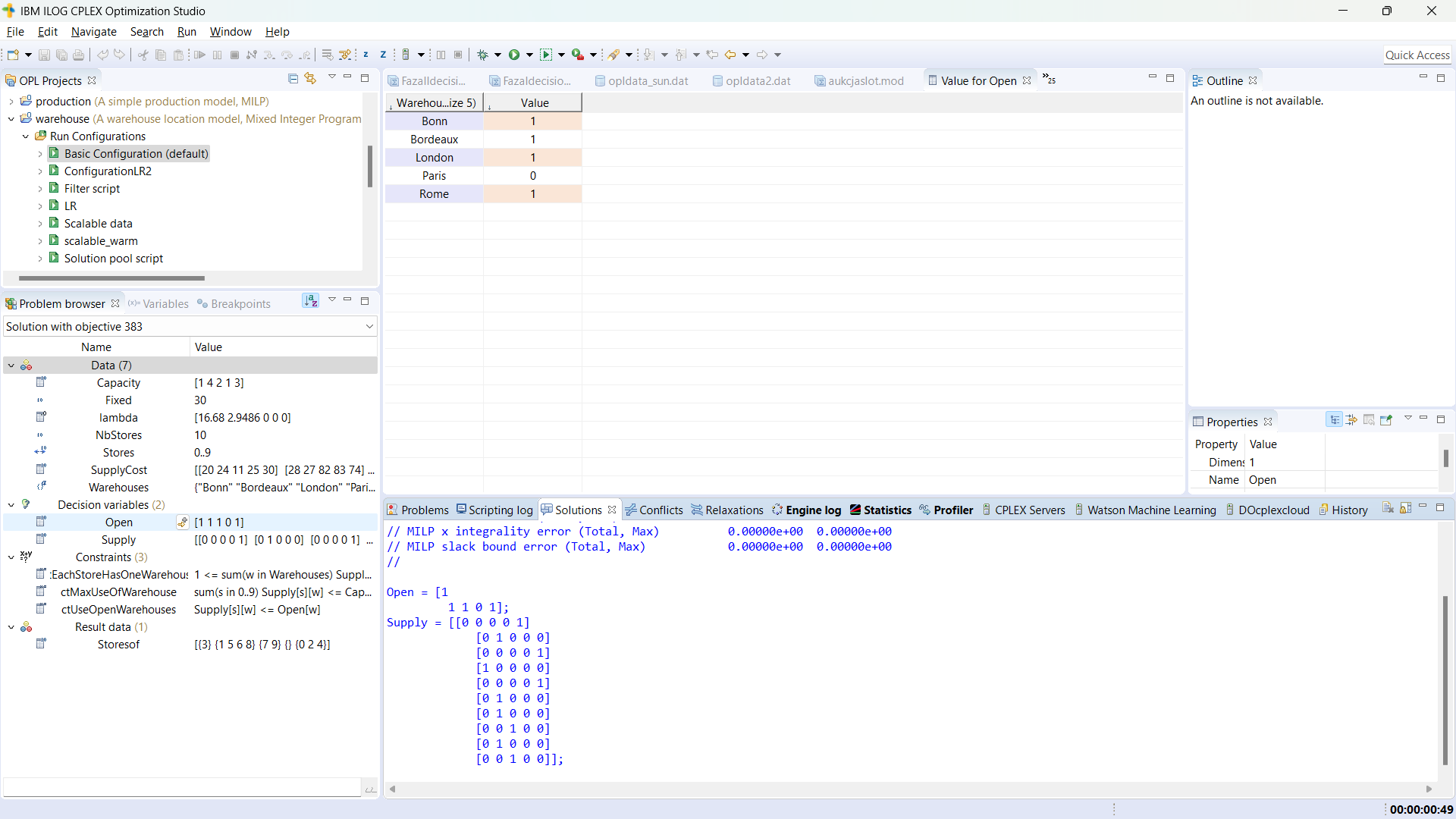
Aby rozwiązać problem musimy wygenerować jego konkretną instancję, czyli zapis modelu dla konkretnych danych - temu służy konfiguracja uruchomienia. Dla rozważanego przykładu przeznaczona jest tzw. konfiguracja domyślna, czyli 'Basic Configuration'. Gdy ją rozwiniemy, widzimy, że przekierowuje ona do naszego pliku z modelem, oraz pliku z danymi. W projekcie można mieć dowolną liczbę konfiguracji, w każdej z nich można mieć różne zestawy model+dane (+ustawienia solwera).Rozwiązanie problemu polega na uruchomieniu konfiguracji, co wykonujemy np. klikając prawym przyciskiem myszki na wybraną konfigurację i wybierając 'Run this'.
- Jeśli model zawiera błędy, to są one wyświetlane na karcie 'Problems'. Warto zwrócić uwagę, że IDE nie uruchamia w takiej sytuacji solwera, ponieważ najpierw należy poprawić błędy - kierując się opisem błędu i ew. poszukując dalszych wskazówek, np. na forum ibm.com;
- Gdy składnia modelu jest poprawna, IDE zaczyna rozwiązywać problem. Aktualizowane są wtedy zakładki obszaru 'Output Area', w szczególności można podejrzeć przebieg procesu rozwiązywania w 'Status Bar', a wyniki w zakładce 'Solutions'.
- Może się zdarzyć, że składniowo poprawny model zawiera błędy logiczne, lub występuje niespójność w danych. W takiej sytuacji solwer cplex wskazuje, że rozwiązanie jest sprzeczne, niedopuszczalne lub że problem jest nieograniczony (Infeasible, Unbounded). Dodatkowo, udostępniane są wspomagające narzędzia:
- Conflict refinement: w zakładce 'Conflicts' znajdziemy podpowiedź, które ograniczenia są wzajemnie sprzeczne, nie mogą być spełnione jednocześnie;
- Minimal relaxation: jeśli nie jest możliwe uzyskanie rozwiązania, to cplex stara się wyznaczyć rozwiązanie zadania zrelaksowanego (wynikowe okienko wyświetla wtedy Relaxed solution, przyjmując jak najmniejsze zmiany w definicji problemu) a wynik można obejrzeć w zakładce 'Relaxations'.
Ustawienia solwera
Wybór algorytmu oraz specyficznych dla niego parametrów przeprowadzamy w pliku .ops. W standardowym wykorzystaniu solwera nie ma potrzeby zmieniać domyślych ustawień, jednak w bardziej wymagających przypadkach wiedza o takich możliwościach bywa przydatna. Najłatwiej będzie zaobserwować zmiany w pracy solwera, gdy prześledzimy szczegóły rozwiązywania bardzo dużego problemu, zdefiniowanego w konfiguracji scalableWarehouse. Jest to wersja modelu lokalizacji magazynów, która nie ma powiązanego pliku danych. Liczby magazynów i sklepów oraz koszty są deklarowane w pliku modelu z danymi wewnętrznymi. Tym samym, problem można skalować poprzez zmianę liczby magazynów i sklepów - w przykładzie możemy ustawić np. 1000 sklepów i 100 lokalizacji magazynów. W konfiguracji przebiegu scalableWarehouse proponujemy zdefiniować plik ustawienia.ops (Prawy przycisk myszy New->Settings) i przeciągnąć go do konfiguracji.
Po otwarciu ustawienia.ops ustawmy MIP gap tolerancję względną na 1%:
- Klikamy na Mixed Integer Programming->Tolerances
- Wpisujemy wartość 0.01 dla Relative MIP gap tolerance Zmieniony parametr widać poprzez pogrubienie.
- Rozwiąż problem i porównaj czas i wyniki z modelem pierwotnym.
Poniższy rysunek pokazuje odpowiedni widok.

Uwaga. Ogólne wskazówki dla poprawy obliczania przy wykorzystaniu Cplexa, w tym dla ustawiania parametrów obliczania znaleźć można np. w artykule Practical guidelines for solving difficult mixed integer linear programs. W skrócie, do najważniejszych technik należy:
- wykonanie preprocessingu,
- dostarczenie dobrego rozwiązania dopuszczalnego (skorzystanie z opcji 'cplex mip start'),
- dopasowanie dokładności rozwiązania optymalnego (parametr 'mipgap'),
- skorzystanie z narzędzia 'tunning tool',
- dodanie własnych odcięć, przeformułowanie modelu.