Podręcznik
Aplikacje i usługi sieciowe stanowią podstawowy komponent współczesnych systemów informatycznych, umożliwiając komunikację i wymianę danych w rozproszonym środowisku. W centrum ich działania znajdują się protokoły aplikacyjne, takie jak HTTP, SMTP, FTP czy DNS, które definiują zasady interakcji między klientami a serwerami. Większość współczesnych aplikacji opiera się na modelu klient-serwer, zapewniając skalowalność, modularność i łatwość zarządzania. Coraz większe znaczenie zyskuje bezpieczeństwo — zarówno na poziomie transmisji danych, jak i autoryzacji dostępu — co jest kluczowe w kontekście cyberzagrożeń. Równolegle rozwijają się zdecentralizowane modele, jak sieci P2P, oferujące alternatywne podejście do współdzielenia zasobów. Istotnym trendem jest także rosnąca rola chmur obliczeniowych, które umożliwiają elastyczne, skalowalne i zdalne świadczenie usług sieciowych na żądanie, przy zachowaniu wysokiej dostępności i niezawodności.
2. Zabezpieczenia w Sieciach Komputerowych
2.3. Zarządzanie wydajnością i dostępnością
Zarządzanie wydajnością i dostępnością w sieciach to zagadnienie skupiające się na tym, aby usługi działały szybko, stabilnie i były dostępne nawet przy awariach. Pojęcia wydajność i dostępność uzupełniają się – wydajność określa, jak szybko zapytania są obsługiwane, jaką przepustowość osiąga usługa, jak niskie opóźnienia i jitter można zapewnić; dostępność dotyczy tego, że usługa działa nieprzerwanie, że użytkownik zawsze może się z nią połączyć nawet przy awariach sprzętu, oprogramowania czy łącza. Realizuje się to poprzez monitorowanie, skalowanie, redundancję, load balancing, odporność na błędy, przywracanie po awarii (DR/BCP), konteneryzację, replikację danych, backup, testy wydajności i planowanie pojemności. W efektywnym środowisku sieciowym działania te są zautomatyzowane, powiązane z narzędziami DevOps i ciągłym dostarczaniem usprawnień.
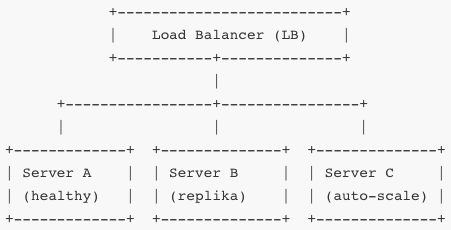
Monitorujesz czas odpowiedzi, CPU, pamięć, ruch sieci, błędy. Jeśli Server B osiąga pewien próg, automatycznie dodaje się Server C (autoscaling). Load balancer dzieli ruch między aktywne serwery. Jeśli któryś padnie, inne przejmują jego część (failover).
Monitorowanie to jedna podstawa – tracery czasów odpowiedzi (RTT), liczba żądań na sekundę (RPS), procent utraconych pakietów, błędów 5xx, średnie opóźnienia, zużycie zasobów. Realizuje się to przez SNMP, NetFlow, logi aplikacji, metryki Prometheus, ELK, Grafana, alerty PagerDuty/SMS/email. Dane te analizujesz w czasie rzeczywistym, definiujesz progi, DPI sygnalizuje anomalie (np. przyrost opóźnień, retransmisji).
Skalowanie dzielisz na poziome (dodajesz kolejne instancje) i pionowe (dodajesz CPU/pamięci do istniejących). Poziome jest bardziej odporne na awarie i efekt skały – nawet wiele równoczesnych żądań obsłuży się przez kilka serwerów. Pionowe bywa tańsze, ale najmniejsza awaria zatrzymuje cały węzeł. W środowisku kontenerowym (np. Kubernetes) definiujesz Deployment i Horizontal Pod Autoscaler – wzór: jeżeli CPU > 70% przez 2 minuty i RPS rośnie, HPA tworzy nowy Pod.
Redundancja dotyczy nie tylko serwerów, ale wszystkich warstw: zapis baz danych w master-read replica lub multi-master; pamięć klient-side cache w lokalnym węźle; strefy dostępności (Availability Zones), regiony. Backup odbywa się codziennie, ale także co godzinę snapshoty, okresowe przywrócenie w środowisku testowym potwierdza zdolności DR. Redis ma replikację synchroniczną; bazy SQL cluster; NoSQL – replikacyjny quorum; pliki obiektowe S3 z wersjonowaniem.
Dostępność mierzysz w procentach: SLA 99,9% to ~8,8 godzin przestoju rocznie; 99,99% to ~52 minuty. Tolerancja ustalana przez biznes, bo redundancja i monitoring kosztują. Planwork of Business Continuity/Disaster Recovery ustala RPO (ile danych można stracić) i RTO (ile czasu można przetrwać bez usług).
Do przywracania usług używasz mechanizmów failover: serwery stand-by, baze z repliką, sieci podłączone multi-path (BGP, Anycast), load balancer, Health Check TCP/HTTP by LB automatycznie przerzucał traffic. W kontenerach Probe Liveness i Readiness w Kubernetesie odznaczają zaburzone Pody i restartuje je.
Zarządzanie pojemnością polega na analizie trendów: różnice w ruchu porannym, weekendowym, sezonowym. Pomiar obciążenia w określonych dniach pozwala planować testy obciążeniowe (load tests) i zapas zasobów. Generujesz testy np. przy 2x oczekiwanym szczycie, aby ocenić zachowanie systemu, jego opóźnienia, throughput.
W otwartym środowisku konteneryzowanym ruch musi być sterowany politykami, QoS, limitami zasobów w cgroup. Dzięki temu jeden kontener nie zawojuje całej CPU lub pamięci DNS. Monitorując i skalując, kontrolujesz, że inne zasoby usługi nie wpadają w „noisy neighbor” – wąskie gardło np. IOPS dysku, EBS, bandwidth.
Observability oznacza nie tylko metryki, ale także trace'y – request distributed tracing (OpenTelemetry), gdzie całość requestu ma identyfikator trace‑id, a usługi raportują czasy request→response; możesz powiązać spadek wydajności z daną ścieżką. Jeśli PageA wyświetla się 200 ms wolniej, możesz sprawdzić którego mikroserwisu to dotyczy i czy może to wynik przeciążenia, snapshotu GC, braku replikcache, wolnej bazy.
Automatyką zarządzasz politykami – np. jeśli błąd 5xx > 1% i CPU > 90% to trigger alert i add pod; jeśli CPU < 10% i RPS zmaleje, scale down. To zapobiega przestojom i niskiej wydajności. Stabilizacja następuje poprzez tweak planów retry/backoff (exponential backoff z jitterem).
Dostępność wpływa na routing – stosujesz Anycast, BGP, Global Load Balancers, traffic steering. Globalna architektura kieruje użytkownika do najbliższego regionu zdrowego, Prober sprawdza zdrowie regionalne i usuwa region z puli, aż wróci. To minimalizuje opóźnienia i zapobiega awarii.
Wszystkie te mechanizmy muszą być przetestowane – chaos engineering (Netflix Simian Army Chaos Monkey), grid tests, awarie regionów, opóźnienia między regionami, snapshot bazy, failover load balancer back to default. Testy te muszą powtarzalnie ignorować awarie i potwierdzać z góry zadane SLA.
Scentralizowane logowanie (ELK/Graylog) agreguje błędy, metryki, trace. Anomaly detection na logach alertuje wzrost czasu requestów, błędów, timeoutów. Wykorzystujesz retry + circuit breaker (limit błędnych połączeń) + fallback.
Zarządzanie wydajnością i dostępnością wymaga współdziałania programistów, DevOps inżynierów, sieciowców i SRE; to ciągły proces – planowanie, implementacja, monitorowanie, analiza, poprawianie. Praktyka w labach i eksperymenty pozwalają zrozumieć jak elementy systemu współdziałają pod obciążeniem, jak awarie zepsują ścieżkę zapytania i jak odbudować system.