Podręcznik
3. Sieci neuronowe głębokie
3.6. Sieci CNN do detekcji obiektów w obrazie
6.6.1 Sieć YOLO
Struktury sieci CNN przedstawione wcześniej stosowane są bezpośrednio w rozwiązywaniu zadań klasyfikacji i regresji, gdzie sieć pracuje w trybie z nauczycielem (na etapie uczenia dane są stowarzyszone ze sobą pary \((\mathbf{</span><span lang="pl-PL"><span>x},\mathbf{d})\)). Oryginalnym obszarem takich zastosowań jest detekcja obiektów, w której poszukuje się konkretnych obiektów występujących w analizowanych obrazach. Jest ona połączona ze wskazaniem współrzędnych tych obszarów (zadanie regresji). W takim rozwiązaniu sieć pracuje więc jednocześnie jako klasyfikator i układ regresyjny. Jest trenowana na zbiorze obrazów w których występują poszukiwane obiekty traktowane jako „destination”. Po zamrożeniu parametrów wytrenowana sieć jest gotowa do wydobycia nauczonych obiektów z serii obrazów nie uczestniczących w uczeniu.
Ważnym rozwiązaniem w tej dziedzinie jest sieć YOLO (skrót od "You Only Look Once"), wykonująca jednocześnie funkcje klasyfikatora i systemu regresyjnego [52,72]. Służy do wykrywania określonych obiektów w obrazie (zadanie klasyfikacji) oraz ich umiejscowienia (zadanie regresji). Obiektami mogą być różne przedmioty występujące na obrazie. Zadanie regresji polega na określeniu współrzędnych wykrytych obiektów. Opracowany system dzieli analizowany obraz na siatkę komórek o wymiarach \(S\times S\). Każda komórka jest odpowiedzialna za wykrycie obiektów, które znajdują się w jej obrębie. Jeśli centrum poszukiwanego obiektu znajdzie się wewnątrz komórki siatki, wówczas ta komórka jest odpowiedzialna za wykryty obiekt. Komórka może być odpowiedzialna za wykrycie jednoczesne \(B\) obiektów, wskazując na współczynnik ufności co do wystąpienia każdego z nich w obrębie danej komórki.
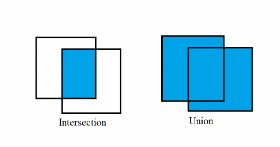
Ważnym elementem rozwiązania jest tu współczynnik ufności IOU (ang. Intersection Over Union), określający w jakim stopniu w danej komórce występuje pokrywanie się rzeczywistego pola obwiedni obiektu z polem prognozowanym obwiedni (tzw. bounding box) dla wszystkich\(B\) badanych obwiedni. Współczynnik ufności \(C\) dla danej komórki reprezentuje prawdopodobieństwo, że określony obiekt znajduje się w obrębie określonej obwiedni (bounding box). Opisuje się go wzorem
| \( C=\operatorname{Pr}(\text { obiekt }) I O U_{\text {pred }}^{\text {truth }} \) | (6.17) |
gdzie \(Pr(obiekt)\) oznacza prawdopodobieństwo wystąpienia obiektu w danej obwiedni a \( I O U_{\text {pred }}^{\text {truth }}\) przyjmuje procentową wartość części wspólnej \( \mathrm{S}_{\text {intersection }} \) powierzchni rzeczywistej i prognozowanej obwiedni do ich całkowitej powierzchni \( \mathrm{S}_{\text {union }} \)
| \( I O U=\frac{\mathrm{S}_{\text {intersection }}}{\mathrm{S}_{\text {union }}} \) | (6.18) |
Rys. 6.18 ilustruje interpretację obu powierzchni. Jeśli określony obiekt nie pojawia się w danej obwiedni współczynnik ufności jest z definicji równy zeru.
Równolegle z analizą pokrywania się obu obwiedni w komórce obliczane jest warunkowe prawdopodobieństwo klasy obiektu. Jest ono wyrażone wzorem
| \( \operatorname{Pr}\left(\text { klasa }_i \mid \text { obiekt }\right)=\operatorname{Pr}\left(\text { klasa }_i\right) I O U_{\text {pred }}^{\text {truth }} \) | (6.19) |
Każdy „bounding box” skojarzony z komórką jest charakteryzowany w systemie poprzez kilka parametrów: \((x,y)\) – współrzędne centrum obiektu mierzone względem danej komórki, \((w,h)\) – szerokość i wysokość obwiedni (traktowanej jako prostokąt) mierzone względem całego obrazu oraz współczynnik ufności reprezentujący wartość IOU przewidywanej aktualnie obwiedni obiektu względem prawdziwej (tzw. ground truth). Każda komórka jest dodatkowo odpowiedzialna za wykrycie klasy każdego z obiektów i określenia prawdopodobieństwa przynależności klasowej \(Pr(klasa_i|obiekt)\).
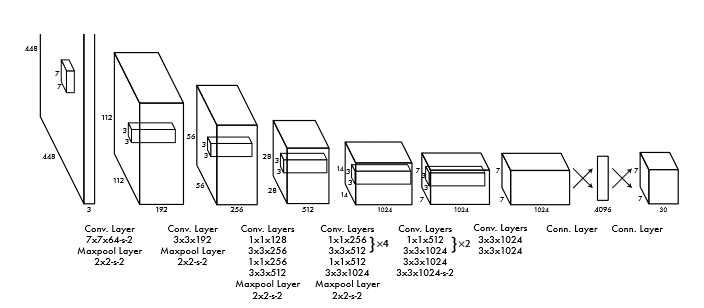
Struktura pierwotnie zaproponowanej sieci YOLO [52] przedstawiona jest na rys. 6.19. Zawiera 24 warstwy konwolucyjne lokalnie połączone do generacji cech diagnostycznych i dwie w pełni połączone warstwy odpowiedzialne jednocześnie za zadanie klasyfikacji (rozpoznanie klasy obiektów) oraz zadanie regresji (określenie współrzędnych wystąpienia poszczególnych obiektów). Zastosowany wymiar komórki \(S=7\). Wyjściowa warstwa sieci generuje jednocześnie prawdopodobieństwo przynależności określonej komórki do klasy obiektu (klasyfikacja) oraz współrzędne obwiedni poszczególnych obiektów (regresja). Sieć używa funkcje aktywacji typu Leaky ReLU. Uczenie sprowadza się do odpowiednio zdefiniowanej funkcji celu w postaci błędu średniokwadratowego. Funkcja taka jest złożeniem składników odpowiedzialnych za klasyfikację oraz składników odpowiedzialnych za regresję. W jego procesie przyjmuje się, że każda obwiednia (bounding box) skojarzona jest jedynie z jednym obiektem na podstawie największej wartości IOU.
W międzyczasie powstały różne udoskonalone rozwiązania struktury sieci, charakteryzujące się większą szybkością przy mniejszej liczbie parametrów podlegających adaptacji w procesie uczenia. Takim przykładem jest rozwiązanie znane pod nazwą YOLOX [72].
Innym rozwiązaniem segmentacji wykorzystującym sieci CNN jest R-CNN (ang. Region based CNN). Istnieje kilka wersji rozwiązań tego typu. W tym punkcie ograniczymy się do tzw. Faster R-CNN. Ogólna struktura tej sieci przedstawiona jest na rys. 6.20 [53].
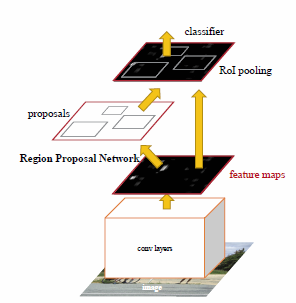
Rozwiązanie bazuje na zastosowaniu dwu podstruktur CNN. Pierwsza z nich, tzw. Region Proposal Network (RPN) jest odpowiedzialna za generację cech diagnostycznych i znajduje rejony obrazu zawierające propozycję ewentualnych obszarów obiektów, które w drugiej części rozwiązania sieciowego zwanej RoI pooling (RoI - region of interest) podlegają weryfikacji, stwierdzającej rzeczywiste istnienie bądź negację określonego obiektu (detekcję). Obie części sieci wykorzystują strukturę wielowarstwową CNN i współpracują ze sobą, zarówno w trybie uczenia jak i testowania.
Ważną rolę odgrywa w rozwiązaniu warstwa RoI pooling. Warstwa ta stosuje max pooling do przetworzenia cech zawartych w każdym istotnym RoI obrazu w niewielkich wymiarów mapę cech (zwykle \(7\times 7\)) na podstawie których definiuje prawdopodobieństwo przynależności badanego RoI obrazu do obiektu i parametry określające jego wymiar.
RPN przyjmuje na wejściu surowe obrazy podlegające analizie i przekazuje na wyjście (do warstwy RoI pooling) propozycje prostokątnych rejonów z estymowanym stopniem przynależności do klas poszukiwanych obiektów. Ma strukturę i zasadę działania sieci CNN. W każdej warstwie używa przesuwającego się filtru (typowy wymiar \(3\times 3\)) działającego na mapie cech ostatniej warstwy konwolucyjnej. Sygnał wyjściowy filtru (po operacji ReLU) odpowiadający każdej pozycji na obrazie jest rzutowany na małowymiarowy wektor cech (typowa wartość 256). Cechy te stanowią wejście dla dwu w pełni połączonych warstw RoI pooling działających równolegle:
-
warstwa regresyjna - generująca na wyjściu współrzędne bloków reprezentujących proponowane rejony odpowiadające pozycji filtru na obrazie,
-
warstwa klasyfikacyjna – estymująca przynależność bloków do określonego obiektu.
Każdej pozycji przesuwającego się okna filtrującego przypisuje się wiele propozycji rejonów, zwanych kotwicami. Ich liczba \(k\) jest ustalana z góry. Stąd warstwa regresyjna generuje \(4k\) wartości (pozycje \(x, y\) lewego górnego piksela rejonu, szerokość \(w\) oraz wysokość \(h\)). Warstwa klasyfikacyjna generuje \(2k\) wartości estymujących prawdopodobieństwo przynależności oraz braku przynależności \(k\)-tego rejonu do poszukiwanego obiektu, reprezentowanego przez ROI. Każdy obraz analizowany jest w 3 skalach i dla 3 wartości współczynników kształtu kotwic (1:1, 1:2 oraz 2:1), co daje 9 kotwic dla każdej pozycji filtru. W przypadku obrazu o wymiarach \(W\times H\) liczba kotwic jest równa \(W ×H×k\).
Uczenie RPN w funkcji klasyfikatora generuje wynik binarny (\(\pm1\)). Znak dodatni (kotwica pozytywna) przypisany jest kotwicy w dwu przypadkach: gdy jej powierzchnia pokrywa się z obiektem poszukiwanym w stopniu powyżej 70% lub w przypadku skrajnym, gdy nie ma żadnego takiego przypadku. Przyjmuje się wówczas kotwice o jak największej wartości współczynnika pokrycia. Wartość negatywna klasyfikatora (kotwica negatywna) jest generowana gdy współczynnik pokrycia kotwicy z obiektem poszukiwanym jest poniżej 30%. Kotwice nie zaliczone ani do pozytywnych ani negatywnych nie biorą udziału w dalszej procedurze uczenia. Uczenie RPN polega na minimalizacji funkcji kosztu definiowanej w postaci [42]
| \( \min L\left(p_i, t_i\right)=\frac{1}{N_{c l}} \sum_i L_{c l}\left(p_i, p_i^*\right)+\lambda \frac{1}{N_{r e g}} \sum_i p_i^* L_{r e g}\left(t_i, t_i^*\right) \) | (6.20) |
W wyrażeniu tym indeksy i reprezentują kotwice, \( p_i \) prawdopodobieństwo, że kotwica należy do obiektu i-tego; \(p_i^{*}\) przyjmuje wartość \(1\) gdy kotwica jest pozytywna lub wartość \(0\) w przypadku gdy kotwica jest negatywna. Parametr \(t_i\) reprezentuje 4 wartości charakteryzujące rejon kotwicy \( (x, y, w, h)\) a \( t_i^{*} \) te same wartości przypisane współrzędnym poszukiwanego obiektu (ground true box) skojarzonego z dodatnią kotwicą. Składnik klasyfikacyjny funkcji kosztu \( L_{c l}(p_i, p_i^*) \) przyjmuje się w postaci logarytmicznej \( L_{c l}(p_i, p_i^*)=-\log p_i \) gdzie \( p_i \) reprezentuje estymowaną wartość prawdopodobieństwa przynależności kotwicy do \(i\)-tego obiektu podlegającego wykryciu. Drugi składnik odpowiada regresji \( L_{r e g}\left(t_i, t_i^*\right)=R\left(t_i-t_i^*\right) \), gdzie funkcja \(R\) reprezentuje przyjętą miarę różnic między wartościami parametrów \((x, y, w, h)\) przypisanych kotwicy i obiektu poszukiwanego [53]. Może ona przyjmować różne postacie. Parametr \( \lambda \) stanowi współczynnik regularyzacji części klasyfikacyjnej i regresyjnej we wzorze (5.6). Przy znormalizowanych wartościach reprezentujących obiekt przyjmuje się zwykle \( \lambda=1\).
W uczeniu gradientowym RPN stosuje się metodę SGDM (przy użyciu tzw. mini-zbiorów generowanych z określonych losowo obszarów obrazów ROI (typowa populacja mini-batches jest równa na przykład 128 a jej skład wynika z losowego wyboru ROI z wielu obrazów). Zakłada się przy tym, że przynajmniej 25% ROI pokrywa się w stopniu 50% z obiektem podlegającym wykryciu. W uczeniu SGD stosuje się zwykle technikę wspomagającą, wykorzystującą metodę momentu rozpędowego.
Sieć RPN generuje propozycje obszarów podlegających dalszej detekcji obiektów reprezentowanych w postaci określonych cech diagnostycznych. Funkcję detektora pełni sieć Fast R-CNN, pełniąca rolę końcowego dostrajania. Dla przyspieszenia uczenia i unifikacji rozwiązania obie części systemu (RPN i Fast R_CNN) współpracują ze sobą w kolejnych cyklach obliczeniowych (tzw. alternative training). Fast R-CNN wykorzystuje jako wejście rejony wskazane przez RPN, inicjalizując z kolei RPN swoimi wynikami w następnych cyklach obliczeniowych. Dzięki temu proces detekcji poszukiwanych obiektów w obrazie jest bardzo szybki [53].
Przykład programu Matlaba wykorzystującego sieć R-CNN do detekcji znaku STOP na obrazach przedstawiony jest poniżej. W uczeniu zastosowano 27 obrazów zawierających znak STOP-u i jeden obraz testowy.
% RCNN do dtekcji znaku STOP
load('rcnnStopSigns.mat', 'stopSigns', 'layers')
imDir = fullfile(matlabroot, 'toolbox', 'vision', 'visiondata',...
'stopSignImages');
addpath(imDir);
options = trainingOptions('sgdm', ...
'MiniBatchSize', 32, ...
'InitialLearnRate', 1e-6, ...
'MaxEpochs', 10);
% Train the R-CNN detector. Training can take a few minutes to complete.
rcnn = trainRCNNObjectDetector(stopSigns, layers, options, 'NegativeOverlapRange', [0 0.3]);
% Test the R-CNN detector on a test image.
img = imread('stopSignTest.jpg');
[bbox, score, label] = detect(rcnn, img, 'MiniBatchSize', 32);
% Display strongest detection result.
[score, idx] = max(score);
bbox = bbox(idx, :);
annotation = sprintf('%s: (Confidence = %f)', label(idx), score);
detectedImg = insertObjectAnnotation(img, 'rectangle', bbox, annotation);
figure
imshow(detectedImg)
Wynik testowania programu na nowym obrazie nie uczestniczącym w uczeniu przedstawiony jest poniżej na rys. 6.21.
